ONNX系列一:ONNX的使用,从转化到推理
onnx模型在算法岗位上属于接触到比较多的一款框架,随着接触到的框架越来越多,不免会产生一些遗忘。因此,写下这篇文章,记录下来学习onnx框架的一些心得体会。
1.pytorch转化onnx
这一步属于比较简单的步骤,代码中详细的参数参考下列表格。
import torch
# 模型保存时,只保存了模型的参数,官方推荐
# 必须先实例化你的网络架构,然后再加载模型
model = YourNet()
model.load_state_dict(torch.load("path_to_yourModel.pt"))
# 如果保存pt模型时保存了完成的模型,则直接使用torch.load("path_to_yourModel.pt")
# 模型的输入输出名,有几个就在列表里写几个
input_list = ['input']
output_list=['output1', 'output2']
# 模拟模型的输入
x = torch.randn(1, 3, 256, 256)
with torch.no_grad():
torch.onnx.export(
model,
x,
"./model/srcnn.onnx",
opset_version=11,
input_names=input_list,
output_names=output_list)
# 如果需要动态输入输出,则可以使用dynamic_axes,如:
#torch.onnx.export(
# model,
# x,
# "./model/srcnn.onnx",
# opset_version=11,
# input_names=input_list,
# output_names=output_list,
# dynamic_axes={
# 'output1': [0, 1, 2, 3]
# ' output2': [0, 1, 2, 3]}
#)参数列表如下:
参数 |
用法 |
model |
pytorch模型 |
x |
模型的任意一组输入(模拟实际输入数据的大小,比如三通道的512*512大小的图片,就可以设置为torch.randn(1, 3, 512, 512)) |
opset_version |
onnx算子集的版本 |
input_names |
模型的输入名称(自己定义的),如果不写,默认输出数字类型的名称 |
output_name |
模型的输出名称(自己定义的),如果不写,默认输出数字类型的名称 |
dynamic_axes |
设置动态输入输出,用法:"输入输出名:[支持动态的纬度]",如“支持动态的纬度设置为[0, 2, 3]”则表示第0纬,第2纬,第3维支持动态输入输出。 |
参数讲解:
(1)为什么需要模型的一组输入:
pytorch有两种方式转onnx:一种是trace(跟踪)(不会考虑诸如if-else的控制流),另一种是script(记录)(会记录诸如if-else的控制流)。
torch.onnx.export使用的是trace方法导出onnx,即onnx记录不考虑控制流的静态图。
trace方式的特点是:任意给点一组输入,再运行一遍模型,在模型运行的过程中,把计算图保存下来,导出模型的静态图。
script方式的特点是:通过解析模型来记录所有的控制流。
由于推理引擎对静态图比较友好,所以通常会直接使用torch.onnx.export导出静态模型。
(2)为什么ONNX 模型的每个输入和输出张量都有一个名字。
很多推理引擎在运行 ONNX 文件时,都需要以“名称-张量值”的数据对来输入数据,并根据输出张量的名称来获取输出数据。
在进行跟张量有关的设置(比如添加动态维度)时,也需要知道张量的名字。
2.简化得到的ONNX模型
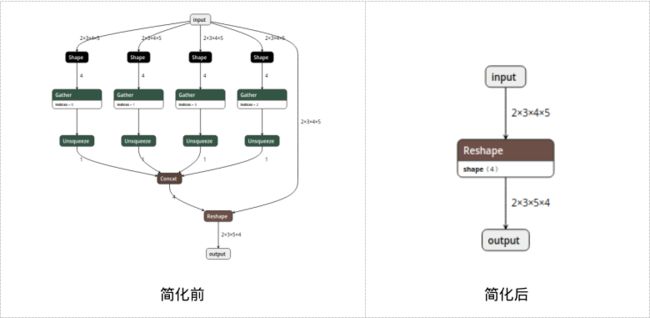
经过上述步骤得到的ONNX模型可能会存在很多冗余的算子,因此对ONNX模型进行简化是非常重要的。用onnx-simplify作者的话说:“ONNX牛逼但啰嗦”,不得不说,“雀食”如此,你瞅。
2.1安装onnx-simplify
pip3 install -U pip && pip3 install onnxsim2.2使用onnx-sim
cd /path_to_your_model.onnx
onnxsim your_origin_model.onnx simplified_model.onnx 3.使用ONNXRuntime进行推理
import numpy as np
import onnx
import onnxruntime as rt
import cv2
input_image_path = 'path_to_test_image'
ONNX_Model_Path = 'path_to_onnx_model'
def onnx_infer(im, onnx_model):
# InferenceSession获取onnxruntime解释器
sess = rt.InferenceSession(onnx_model)
# 模型的输入输出名,必须和onnx的输入输出名相同,可以通过netron查看,如何查看参考下文
input_name = "input"
output_name = ['boxes', 'labels', 'scores', 'masks']
# run方法用于模型推理,run(输出张量名列表,输入值字典)
output = sess.run(output_name, {input_name: im})
boxes = output[0]
labels = output[1]
scores = output[2]
masks = output[3]
if __name__ == '__main__':
# 图片的预处理
img = cv2.imread(input_image_path)
img = cv2.resize(img, (256, 256))
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = img.transpose(2, 0, 1)
img = img.astype(np.float32) / 255
img = np.expand_dims(img, axis=0) # 3维转4维
output = onnx_infer(img, ONNX_Model_Path)转换后的onnx模型可以通过netron查看,其中模型的输入输出名以你的模型上的INPUTS和OUTPUTS为主,如下:

具体模型使用OnnxRuntime进行推理,可以参考我的另一篇博客:Yolov5使用OnnxRuntime进行推理
4.ONNXRuntime 使用多核进行推理
import onnxruntime as rt
import onnx
import numpy as np
import time
ONNX_Model_Path = 'path_to_onnx_model'
img = np.ones((1, 3, 640, 640)).astype(np.float32)
# 加载模型,传入模型路径
model = onnx.load_model(ONNX_Model_Path)
# 创建一个SessionOptions对象
rtconfig = rt.SessionOptions()
# 设置CPU线程数为4
cpu_num_thread = 4
# 设置执行模式为ORT_SEQUENTIAL(即顺序执行)
rtconfig.intra_op_num_threads = cpu_num_thread
rtconfig.execution_mode = rt.ExecutionMode.ORT_SEQUENTIAL
# 设置使用的ExecutionProvider为CPUExecutionProvider
providers = ['CPUExecutionProvider']
# 创建一个InferenceSession对象
sess = rt.InferenceSession(model.SerializeToString(), providers=providers, sess_options=rtconfig)
# 模型的输入和输出节点名,可以通过netron查看
input_name = 'images'
outputs_name = ['output']
# 模型推理:模型输出节点名,模型输入节点名,输入数据(注意节点名的格式!!!!!)
net_outs = sess.run(outputs_name, {input_name: img})
result = np.array(net_outs)