Flink1.11.0 SQL与hive整合
一、前言
此次flink sql 整合 hive 主要是能在flink sql中读写hive数据,为flink实时写数据进入hive 构建实时数仓做准备工作。
flink 1.11.0 hive 2.3.4 hadoop 2.7.2
主要步骤主要是参考官方文档:https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/table/hive/hive_catalog.html
二、主要步骤
1.开启Hive Metastore 及 添加 hive-site.xml
参照官网如下:

step 1: set up a Hive Metastore
hive 安装好后 启动 Hive Metastore
hive --service metastore

hive-site.xml 配置文件
javax.jdo.option.ConnectionURL
jdbc:mysql://localhost/metastore?createDatabaseIfNotExist=true
metadata is stored in a MySQL server
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
MySQL JDBC driver class
javax.jdo.option.ConnectionUserName
...
user name for connecting to mysql server
javax.jdo.option.ConnectionPassword
...
password for connecting to mysql server
hive.metastore.uris
thrift://localhost:9083
IP address (or fully-qualified domain name) and port of the metastore host
hive.metastore.schema.verification
true
2.Flink 集群添加依赖包及修改Flink SQL 配置文件
参照官网如下

2.1 集群添加hadoop和flinksql依赖包
主要参考:https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/table/hive/
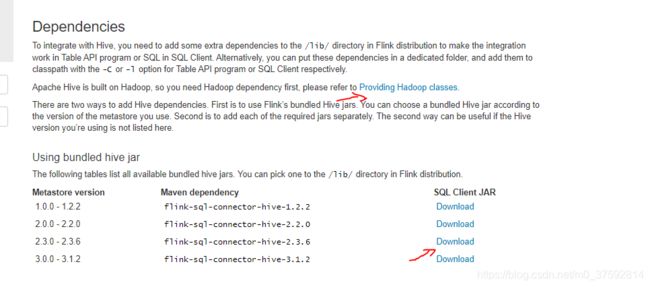
(1)添加 hadoop 依赖包和flink-sql依赖包
官方介绍说可以添加环境变量 export HADOOP_CLASSPATH='hadoop classpath' 定义hadoop 包,我这里没加
我是把hadoop 安装包放到flink 的lib目录下 :/usr/local/apps/flink1.11/lib
flink-sql-connector-hive-2.3.6 是通过flink官方下载下来 这里要根据各自的hive版本不同下载,同样放到flink 的lib包下
2.2 修改Flink SQL 配置文件
修改为 sql-client-defaults.yaml
主要修改如下两个地方
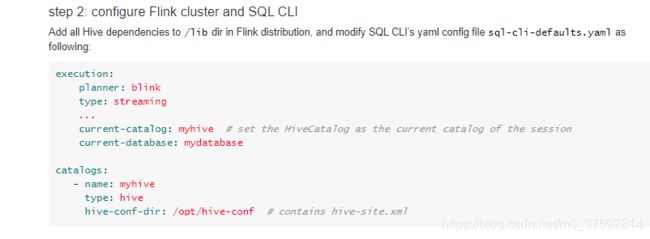
2.3 重新启动集群、Flink SQL
./start-cluster.sh
查看集群是否起来:http://ELK05:8081
./sql-client.sh embedded
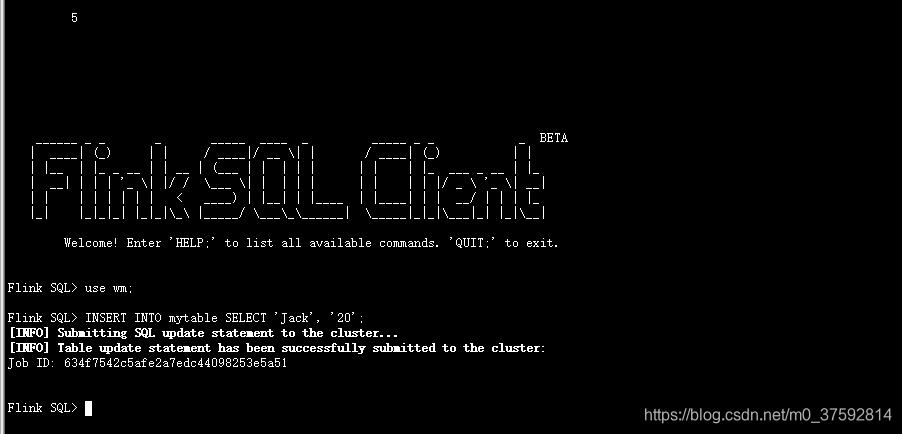
三、验证读写hive数据
CREATE TABLE test_hive(name string, age double);
INSERT INTO test_hive SELECT 'Jack', 20;
select * from test_hive;
flink 提交任务到集群上是成功的


完整的flink1.11.0实时读取kafka数据写入hive中参考上一文章:
https://blog.csdn.net/m0_37592814/article/details/108044830