iMAP——论文解析
iMAP: Implicit Mapping and Positioning in Real-Time
iMAP 是第一个提出用 MLP 作为场景表征的实时 RGB-D SLAM。iMAP 采用关键帧结构和多进程,通过动态信息引导的像素采样来提高速度,跟踪频率为 10 Hz,全局地图更新频率为 2 Hz。隐式 MLP 的优势在于高效的几何表示法和自动细节控制,以及对物体背面等未观察区域进行平滑、合理的填充。
一、简介
理想的 3D 表征应该具备高效性(内存方面)、可预测性(未观察区域)、灵活性(复用性)。隐式神经表征(implict neural representation, INR)之前大多数用于离线重建,它使用 MLP 将 3D 点映射为空间中的颜色和不透明度,并从头开始进行优化,以适应特定场景。MLP 能对为观察到的区域进行重建。
iMAP 的网络权重不需要 pre-train,追踪上用 MLP 渲染的深度和颜色调整相机的观察结果,建图上用一组关键帧训练和改进 MLP,并优化关键帧的位姿。采样上只采样信息量最大的像素来减少不确定性。
iMAP 把 SLAM 理解为一个持续学习的问题,拥有连续自适应分辨率,能进行平滑插值,自动选择关键帧。
二、相关
Visual SLAM Systems
实时视觉 SLAM 通常采用分层方法来构建,用低语义的特征来定位。 iMAP 则是用于重建稠密图,一些用于稠密图的 SLAM 只会重建表面信息,但是对体素的直接表征具有更大的应用空间。占有格栅或者 SDF(signed distance function)是构建稠密图的标准方法,但是很费内存。分层方法效率更高,但实现起来比较复杂,通常只能提供很小范围的细节。这些方法由于使用了大量参数,其表示方法都相当僵化,无法与相机位姿进行联合优化。
机器学习方法则可以发掘低维特征,从而提高效率。
Implicit Scene Representation with MLPs
隐式神经表征(implict neural representation, INR)之前大多数用于离线重建。我们的研究表明,当深度图像可用,并在渲染和训练中使用引导稀疏采样时,这些方法适用于实时 SLAM。
Continual Learning
通过使用单个 MLP 作为主场景模型,iMAP 将实时 SLAM 定义为在线持续学习。一个有效的持续学习系统应同时具备可塑性(获取新知识的能力)和稳定性(保存旧知识)。灾难性遗忘是神经网络的一个众所周知的特性,即新的经验覆盖了记忆。
减轻灾难性遗忘的一种方法是利用相对加权来保护表征免受新数据的影响。这让人联想到 SLAM 中的经典过滤方法,如 EKF(扩展卡尔曼滤波)。在对每个任务进行训练后冻结或巩固子网络的方法对于 SLAM 来说可能过于简单和离散。
replay-based 的持续学习方法中,先前的知识要么直接存储在缓冲区中,要么压缩在生成模型中。iMAP 自动选择关键帧来存储和压缩过去的记忆。在地图更新过程中,使用损失引导随机采样这些关键帧,定期 replay 并强化先前观察到的场景,同时通过新的关键帧继续添加信息。这种方法类似于 PTAM ,其中历史关键帧集和重复的 BA 可作为长期的场景表示。
三、方法
3.1. System Overview

Fθ 表示全连接神经网络,用于将 3D 点表示为颜色和不透明度(volume density ρ(x) 的严谨解释是:光射线在位置 x 处的无穷小粒子处终止的微分概率)。
3.2. Implicit Scene Neural Network
按照 NeRF 的网络结构,iMAP 使用了一个具有大小为 256 的 4 层 MLP,以及两个将三维坐标 p = (x, y, z) 映射到颜色和不透明度的输出头,即 Fθ§ = (c, ρ)。与 NeRF 不同,iMAP 不考虑观察方向,因为不关注镜面反射建模。
iMAP 应用傅立叶特征网络中提出的高斯位置编码,将输入的 3D 坐标提升到 n 维空间:sin(Bp),其中 B 是一个 [n×3] 矩阵,从标准差为 σ 的正态分布中采样。该编码作为 MLP 的输入,同时也连接到网络的第二个激活层。受 SIREN 的启发,iMAP 允许对矩阵 B 进行优化,这用具有正弦激活函数的单个全连接层来实现。
3.3. Depth and Colour Rendering
受 NeRF 和 NodeSLAM 的启发,iMAP 通过查询场景网络来从给定视图中获取深度和色彩图像。 给定相机位姿变换矩阵 TWC 、像素坐标 [u, v]、相机内参 K,将其转换为世界坐标:r = TWCK-1[u, v]。我们沿光线采集 N 个样本 pi = dir ,d是相应的深度值,然后向网络查询颜色和不透明度 (ci, ρi) = Fθ(pi)。遵循 NeRF 的分层和分级体积采样策略(NeRF中用于计算积分)。
Volume density 乘以样本间距离 δi = di+1 - di转化为占用概率,并通过激活函数 oi = 1 - exp(-ρiδi),那么每个样本的射线终止概率计算公式为 wi = oi ∏(1 − oj),最后,深度和颜色将作为期望值呈现:
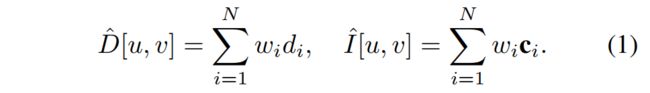
计算沿光线的深度方差为:

3.4. Joint optimisation
iMAP 共同优化了隐式场景网络参数 θ 和不断增加的 W 个关键帧的相机位姿,每个关键帧都有相关的颜色和深度测量值以及初始姿态估计值:I、D、T。
渲染函数相对于这些变量是可微分的,因此可以进行迭代优化,以最小化每个关键帧中选定的渲染像素 si 的几何loss和光度loss。 光度loss是 M 个像素样本的渲染值和测量值之间的 L1-norm:
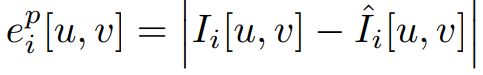
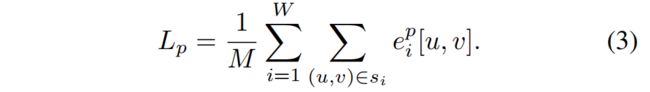
几何loss测量深度差值 eg,同ep,并使用深度方差作为归一化因子,从而在物体边界等不确定区域降低损失权重:
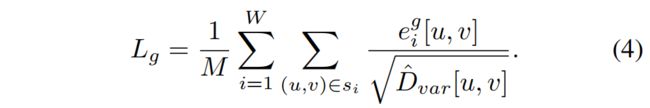
对这两种损失的加权总和使用 ADAM 优化器:

在 online SLAM 中,接近帧速率的相机跟踪非常重要,因为对较小位移的优化更加稳健。iMAP 采用并行跟踪流程,相对于固定场景网络,以比联合优化高得多的帧速率持续优化最新帧的位姿。在选定关键帧的映射过程中,对跟踪位姿初始化进行改进。
3.5. Keyframe Selection
使用所有图像来联合优化网络参数和位姿是不可能的,得益于冗余性,可以选择关键帧来表示场景。利用第一帧来初始化网络并且固定世界坐标系,每当一个新的关键帧被添加时,都会 copy 网络形成在该点的 snapshot,随后的帧将根据这个 copy 选择是否作为关键帧。
为此,iMAP 渲染了一组统一的像素样本 s,并计算了归一化深度误差小于阈值 tD = 0.1 的比例 P,以衡量 snapshot 已经覆盖的帧的比例:
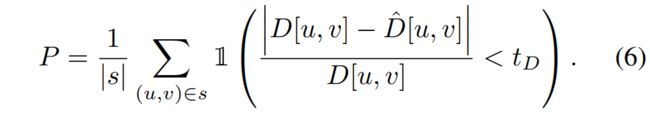
当 P < tP 时(tP = 0.65),该帧就会被添加到关键帧集中。归一化深度误差会产生自适应关键帧选择,当相机更接近物体时,需要更高的精度,因此关键帧的间距也会更近。
每一个关键帧都会在联合优化中使用几次(10 到 20 次),因此关键帧集总是由选定的集合和最新帧组成。
3.6. Active Sampling
Image Active Sampling
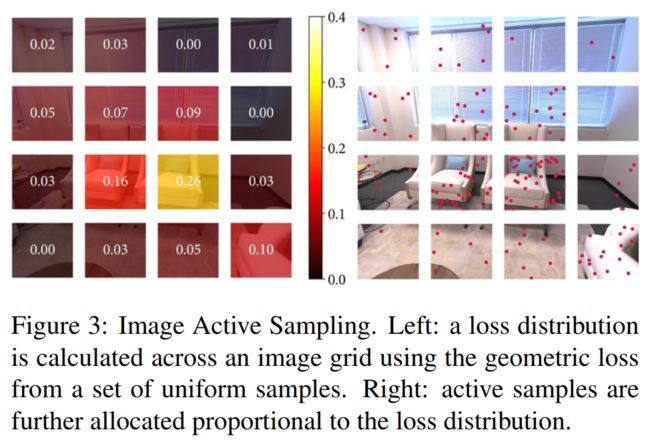
渲染和优化所有像素会耗费大量计算和内存。iMAP 利用图像的规律性,每次迭代只渲染和优化非常稀疏的随机像素集(每幅图像 200 个,记为 ni)。此外还利用渲染损失来指导在细节较多或重建尚不精确的信息区域进行主动采样。
每次迭代联合优化分为两个阶段。首先,采样一组像素 si,它们均匀分布在每个关键帧的深度和彩色图像中。这些像素用于更新网络和相机位姿,并计算损失:将每幅图像划分为 [8×8] 个网格,并计算每个正方形区域内的平均损失 Rj,j = 1,2,…,64:

其中 rj 是在 Rj 中的 si 集合。
将这些数据归一化为概率分布:
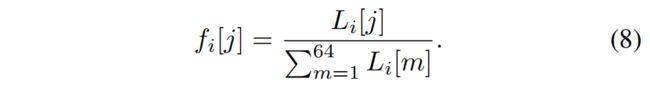
即损失越大,重采样过程中区域 j 中被采样到的点越多。
Keyframe Active Sampling
iMAP 通过一组选定的关键帧不断优化地图,避免网络遗忘。iMAP 希望为损失较高的关键帧分配更多的点样本,因为这些关键帧与新探索区域、高细节区域或网络开始遗忘的区域有关。 采用类似于图像主动采样的方法,为每个关键帧分配 ni 个样本,与关键帧间的损失分布成比例。

Bounded Keyframe Selection
当相机移动到新的区域,关键帧集也会不断增加。为了约束联合优化计算,我们在每次迭代时选择固定数量(实时系统中为 3)的关键帧,并根据损失分布随机取样。在联合优化中,总是包含最后一个关键帧和当前的实时帧,并维护一个 W = 5 的滑动窗口,如上图。
四、实验
数据集:replica 和 真实场景
metrics:Accuracy(cm,重建点与最近gt的距离)、Completion(cm,gt与最近重建点的距离)、Completion Ration(<5cm %)
在 filling 方面、内存方面较 TSDF fusion 要好,归因于重建过程中的光度损失与网络的插值能力相结合。
更多的关键帧对 Completion Ration 提升较小(几个百分点)。
隐式场景网络具有先快速收敛到低频形状,然后再添加高频场景细节的特性。
主动采样增加准确率的同时减少训练时间。
五、结论
iMAP 之所以能够实现实时、长期的 SLAM 性能,关键在于:并行跟踪和建图、用于快速优化的损失导向像素采样,以及作为 replay 以避免网络遗忘的自动关键帧选择。
iMAP 的未来发展方向包括:采用更多结构化的组合表征,来准确推理场景中的自我相似性。
参考:
[1] iMAP:https://arxiv.org/pdf/2103.12352.pdf
[2] NeRF写的很好:https://zhuanlan.zhihu.com/p/390848839
[3] iMAP的实现可以参考vMAP仓库