Puppeteer监听网络请求、爬取网页图片(二)
Puppeteer监听网络请求、爬取网页图片(二)

-
- Puppeteer监听网络请求、爬取网页图片(二)
-
-
- 一、爬取需求
- 二、实现讲解
- 三、效果查看
-
一、爬取需求
- 首先打开浏览器,打开指定网站
- 监听网站发出的所有请求,记录请求,将请求存储到文件中
- 屏蔽网页中出现的所有的弹窗
- 截取网页的首页屏幕图片,获取网页的title属性,并且以titile命名截图文件
- 获取页面中的所有图片,将图片地址保存到文件中
- 最后关闭浏览器
二、实现讲解
从上一节 Puppeteer基础知识(一)我们学习的一些基础知识来看,需求中的要求步骤大部分都有对应的指令去做,很多步骤我们也是清楚的,我们将上一步骤学习的指令合并起来就可以实现这个需求了,对于缺少的部分,我们也会在本次进行添加。
废话不多说,我们开始实现脚本命令吧。
- 定义page并打开网站
这里,定义网页属性调用的page对象,打开整个浏览器窗口,准备开始下面的操作。我们打开网址 https://blog.csdn.net/suwu150 进行实践。
// headless 控制显示还是不显示
const browser = await puppeteer.launch({
headless: false,
devtools: false, // 打开开发者模式
defaultViewport: null, // 不使用默认的固定大小,直接填满浏览器
slowMo: 50, // slow down by 250ms
});
...
await page.goto("https://blog.csdn.net/suwu150", { waitUntil: "networkidle2" });
- 监听网站发出的所有请求,将请求存储到文件中
- 屏蔽所有的弹窗
下面就是监听网络请求、监听日志打印和监听对话框的方式
在Puppeteer中对于事件的监听,需要采用语法 page.on 的形式去实现,我们可以在回调中响应对应的事件,这里分别监听了事件 console、request、dialog 三个事件,分别表示日志打印,请求发送和对话框弹窗事件,当然还有其他的事件,有兴趣的可以去官网看看,这里就不再说明了。戳我看看event api的详细说明:https://puppeteer.bootcss.com/api
page.on('console', msg => console.log('PAGE LOG:', msg.text()));
page.on('request', logRequest);
page.on('dialog', async dialog => {
console.log('dialog', await dialog.message());
await dialog.dismiss();
await dialog.dismiss();
await dialog.dismiss();
});
let list = [];
function logRequest(interceptedRequest) {
console.log('A request was made:', interceptedRequest.url());
list.push(interceptedRequest.url())
}
当然,不仅仅能够监听网络请求去做记录保留,也能够在捕获到请求的时候,决定是否去发送真实的请求到后台获取数据,这就是去分析是否继续爬取下级页面的关键。如果我们判断后发现没必要再去深入了,就可以停止请求了。
举个例子,来看看如何阻止:
page.on('request', request => {
if (request.resourceType() === 'image') {
request.abort();
} else {
request.continue();
}
});
对于文件保存,我们定义了单独的方法 writeFile,方法内容如下:
async function writeFile(path, content) {
await new Promise((resolve, reject) => {
fs.writeFile(path, content, () => {
resolve();
})
});
};
也是一个异步方法,通过 Promise 控制 fs 对文件 io 的操作,将需要保存的内容保存到本地,需要做的是传入当前保存的路径 path 以及需要保存的内容 content 即可。
- 截取网页的首页屏幕图片,以titile命名
通过page.title()获取title内容,然后定义作为名称保存。
const title = await page.title()
console.log('title', title)
await page.screenshot({ path: `../images/${title}.png`, fullPage: true });
- 获取页面中的所有图片,将图片地址保存到文件中
下面是获取所有的图片,通过选择器page.$$eval拿到所有的img标签,获取到src属性,然后将图片 src 保存到指定的 csdn_images.json 文件中。这里所使用的保存文件的方式就是上面定义的writeFile方法。
const imgArray =
await page.$$eval('img', els => Array.from(els).map(el => el.getAttribute('src')));
await writeFile('../json/csdn_images.json', JSON.stringify({ imgArray }, null, 2))
- 关闭浏览器
await browser.close();
以下是完整的实现,在项目中新增js文件,命名为 csdnImg.js ,增加以下内容:
const puppeteer = require('puppeteer');
const fs = require('fs');
(async () => {
// headless 控制显示还是不显示
const browser = await puppeteer.launch({
headless: false,
devtools: false, // 打开开发者模式
defaultViewport: null, // 不使用默认的固定大小,直接填满浏览器
slowMo: 50, // slow down by 250ms
});
let page = await browser.newPage();
// 监听网站的console,发出的所有请求,dialog
page.on('console', msg => console.log('PAGE LOG:', msg.text()));
page.on('request', logRequest);
page.on('dialog', async dialog => {
console.log('dialog', await dialog.message());
await dialog.dismiss();
await dialog.dismiss();
await dialog.dismiss();
});
let list = [];
function logRequest(interceptedRequest) {
console.log('A request was made:', interceptedRequest.url());
list.push(interceptedRequest.url())
}
// 以模拟器的形式打开
await page.emulate({
viewport: {
width: 375,
height: 667,
isMobile: true
},
userAgent: '"Mozilla/5.0 (iPhone; CPU iPhone OS 9_1 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Version/9.0 Mobile/13B143 Safari/601.1"'
});
//打开页面
await page.goto("https://blog.csdn.net/suwu150", { waitUntil: "networkidle2" });
await page.waitForTimeout(2600);
await page.reload()
// 截取屏幕,以titile形式保存
const title = await page.title()
console.log('title', title)
await page.screenshot({ path: `../images/${title}.png`, fullPage: true });
// 保存request请求
await writeFile('../json/csdn.json', JSON.stringify({ list }, null, 2))
// 保存图片src地址
const imgArray = await page.$$eval('img', els => Array.from(els).map(el => el.getAttribute('src')));
await writeFile('../json/csdn_images.json', JSON.stringify({ imgArray }, null, 2))
// 关闭浏览器
await browser.close();
// 保存文件公共方法
async function writeFile(path, content) {
await new Promise((resolve, reject) => {
fs.writeFile(path, content, () => {
resolve();
})
});
};
})();
三、效果查看
接下来,我们只需要在终端运行命令,执行文件
node csdnImg.js
就能够看到会自动打开浏览器进行按照我们页面代码中指定的命令操作。
同时,在项目文件系统中能够看到新增了以下内容
-
在images下看到首页的截图:
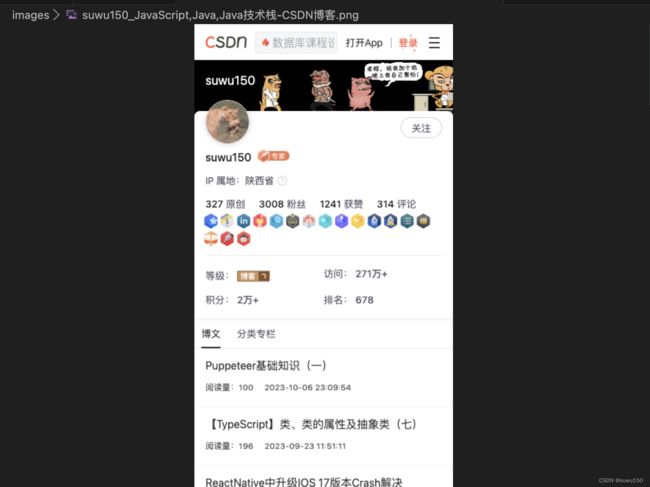
-
在路径
../json/csdn.json下保存请求历史路径
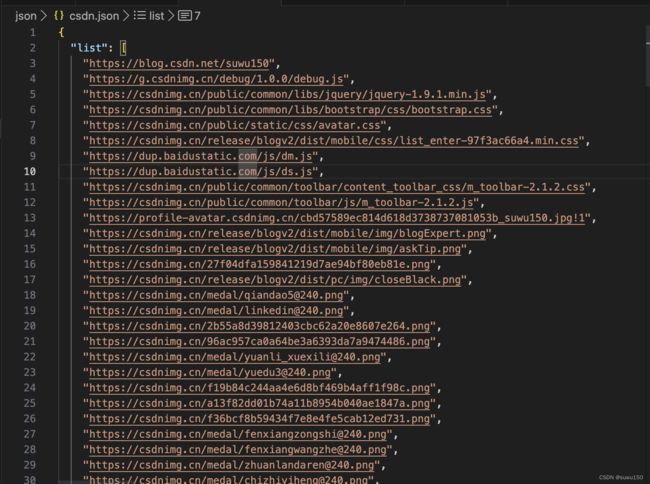
-
在
../json/csdn_images.json下,看到网页中图片的地址
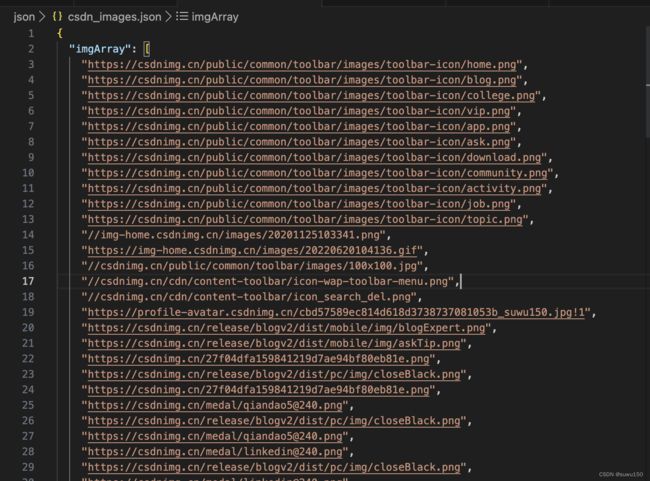
以上就是整个的爬取过程。有兴趣的小伙吧感觉尝试下吧!!!