【LLM微调范式1】Prefix-Tuning: Optimizing Continuous Prompts for Generation
论文标题:Prefix-Tuning: Optimizing Continuous Prompts for Generation
论文作者:Xiang Lisa Li, Percy Liang
论文原文:https://arxiv.org/abs/2101.00190
论文出处:ACL 2021
论文被引:1588(2023/10/14)
论文代码:https://github.com/XiangLi1999/PrefixTuning
Summary
传统的预训练+微调范式的问题:下游任务微调时,需要更新和存储模型全量参数,成本过高。
以往的解决方案:轻量级微调(lightweight fine-tuning),即冻结大部分预训练参数,并用小型可训练模块来增强模型。例如,
- 适配器调优(Adapter-Tuning):在预训练语言模型层之间插入额外的特定任务层。其在自然语言理解和生成基准测试中表现良好,只需增加约 2-4% 的特定任务参数,就能达到与微调相媲美的性能。
- GPT-3的上下文学习/语境学习(In-Context Learning,ICL) 或提示(Prompt):用户在任务输入中预置一个自然语言任务指令(例如,用于总结的 TL;DR)和几个示例,然后通过 LM 生成输出。
生成数据表文本描述的任务:如图 1 所示,其中任务输入是线性表格(如 "name: Starbucks | type: coffee shop"),输出是文本描述(如 "Starbucks serves coffee.")。
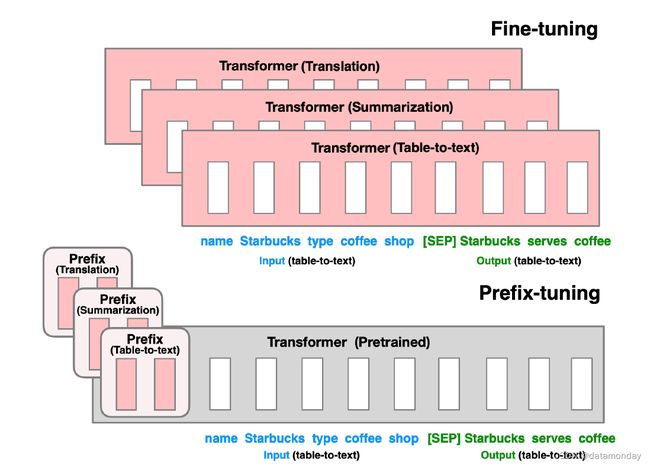
Figure 1: Fine-tuning (top) updates all Transformer parameters (the red Transformer box) and requires storing a full model copy for each task. We propose prefix-tuning (bottom), which freezes the Transformer parameters and only optimizes the prefix (the red prefix blocks). Consequently, we only need to store the prefix for each task, making prefix-tuning modular and space-efficient. Note that each vertical block denote transformer activations at one time step.
本文的贡献:前缀调优(Prefix-Tuning),这是自然语言生成(NLG)任务中微调方法的一种轻量级替代方法,其灵感来源于提示(prompting)。前缀调优将一系列连续的任务特定向量预置到输入中,我们称之为前缀(Prefix),如图 1(底部)中红色块所示。对于后续的标记(tokens),Transformer可以像处理 “虚拟标记” 序列一样处理前缀。
- 但与提示(prompting)不同的是,前缀完全由与真实标记不对应的自由参数组成。图 1(上图)中的微调更新了所有 Transformer 参数,因此需要为每个任务存储一份经过调优的模型副本,而前缀调优则只对前缀进行优化。因此,我们只需存储一份大型 Transformer 和针对特定任务学习的前缀,从而为每项额外任务带来极小的开销(例如,从表格到文本的转换只需 250K 个参数)。
- 与微调不同,前缀调优是模块化的:训练一个上游前缀,该前缀引导下游 LM,而下游 LM 保持不变。
- 前缀调优会保持 LM 不变,并使用前缀和预训练的注意力块来影响后续激活;而适配器调优则会在 LM 层之间插入可训练模块,直接将残差向量添加到激活中。
Abstract
微调(Fine-tuning)是利用大型预训练语言模型执行下游任务的实际方法。然而,它需要修改所有语言模型参数,因此必须为每个任务存储完整的副本。在本文中,我们提出了前缀调优(prefix-tuning)技术,这是自然语言生成任务中微调技术的轻量级替代方案,它可以冻结语言模型参数,但会优化一个小的连续任务特定向量(称为前缀)。前缀调优从提示(prompt)中汲取灵感,允许后续标记(tokens)像 “虚拟标记(virtual tokens)” 一样关注该前缀。我们将前缀调优应用于 GPT-2 的表格到文本生成和 BART 的摘要生成。我们发现,只需学习 0.1% 的参数,前缀调优法就能在全数据环境下获得相当的性能,在低数据环境下的性能优于微调法,并且能更好地推断出训练期间未见过主题的示例(examples with topics)。
Introduction
微调是使用大型预训练语言模型(LMs)(Radford et al., 2019; Devlin et al., 2019) 执行下游任务(如 总结(summarization))的普遍模式,但这需要更新和存储 LM 的所有参数。因此,要构建和部署依赖于大型预训练 LM 的 NLP 系统,目前需要为每个任务存储一份经过修改的 LM 参数副本。考虑到当前 LM 的庞大规模,这样做的成本可能过高;例如,GPT-2 有 7.74 亿个参数,GPT-3 有 1750 亿个参数。
解决这一问题的自然方法是轻量级微调(lightweight fine-tuning),即冻结大部分预训练参数,并用小型可训练模块来增强模型。例如,adapter-tuning (Rebuffi et al., 2017; Houlsby et al., 2019) 在预训练语言模型层之间插入额外的特定任务层。adapter-tuning 在自然语言理解和生成基准测试中表现良好,只需增加约 2-4% 的特定任务参数,就能达到与微调相媲美的性能 (Houlsby et al., 2019; Lin et al., 2020)。
在极端情况下,GPT-3 可以在没有任何特定任务调整的情况下部署。取而代之的是,用户在任务输入中预置一个自然语言任务指令(例如,用于总结的 TL;DR)和几个示例,然后通过 LM 生成输出。这种方法被称为上下文学习(In-Context Learning,ICL) 或提示(Prompt)。
在本文中,我们提出了**前缀调优(Prefix-Tuning)**方法,这是自然语言生成(NLG)任务中微调方法的一种轻量级替代方法,其灵感来源于提示(prompting)。考虑生成数据表文本描述的任务,如图 1 所示,其中任务输入是线性表格(如 "name: Starbucks | type: coffee shop"),输出是文本描述(如 "Starbucks serves coffee.")。前缀调优将一系列连续的任务特定向量预置到输入中,我们称之为前缀(Prefix),如图 1(底部)中红色块所示。对于后续的标记(tokens),Transformer可以像处理 “虚拟标记” 序列一样处理前缀,但与提示(prompting)不同的是,前缀完全由与真实标记不对应的自由参数组成。图 1(上图)中的微调更新了所有 Transformer 参数,因此需要为每个任务存储一份经过调优的模型副本,而前缀调优则只对前缀进行优化。因此,我们只需存储一份大型 Transformer 和针对特定任务学习的前缀,从而为每项额外任务带来极小的开销(例如,从表格到文本的转换只需 250K 个参数)。
与微调不同,前缀调优是模块化的:我们训练一个上游前缀,该前缀引导下游 LM,而下游 LM 保持不变。因此,一个 LM 可以同时支持多项任务。在个性化背景下,任务对应不同的用户,我们可以为每个用户设置一个单独的前缀,只对该用户的数据进行训练,从而避免数据交叉污染。此外,基于前缀的架构使我们甚至可以在一个批次中处理来自多个用户/任务的示例,这是其他轻量级微调方法无法做到的。
我们对使用 GPT-2 生成表到文本和使用 BART 进行抽象摘要的前缀调优进行了评估。在存储方面,前缀调优比微调少存储 1000 倍的参数。就在完整数据集上进行训练时的性能而言,前缀调优和微调优在表格到文本生成方面不相上下(§6.1),而前缀调优在摘要生成方面则略有下降(§6.2)。在低数据设置下,前缀调优在这两项任务中的表现平均优于微调(§6.3)。前缀调优还能更好地推断未见主题的表格(用于表格到文本)和文章(用于摘要)(§6.4)。
2 Related Work
Fine-tuning for natural language generation.
目前最先进的自然语言生成系统都是基于预训练 LM 的微调。
- 对于表格到文本的生成(table-to-text generation),Kale 对序列到序列模型 (T5; Raffel et al., 2020) 进行了微调。
- 对于提取和抽象总结(extractive and abstractive summarization),研究人员分别对屏蔽语言模型 (e.g., BERT; Devlin et al., 2019) 和编码-解码器模型 (e.g., BART; Lewis et al., 2020) 进行了微调 (Zhong et al., 2020; Liu and Lapata, 2019; Raffel et al., 2020)。
- 对于其他有条件的 NLG 任务,如机器翻译和对话生成,微调也是普遍采用的范式 (Zhang et al., 2020c; Stickland et al., 2020; Zhu et al., 2020; Liu et al., 2020)。
在本文中,我们将重点讨论使用 GPT-2 的表到文本和使用 BART 的摘要,但前缀调优也可应用于其他生成任务和预训练模型。
Lightweight fine-tuning.
轻量级微调冻结了大部分预训练参数,并用小型可训练模块修改了预训练模型。关键的挑战在于如何确定高性能的模块架构以及需要调整的预训练参数子集。
- 一种研究思路是删除参数:通过对模型参数进行**二进制掩码(binary mask)**训练,消除部分模型权重 (Zhao et al., 2020; Radiya-Dixit and Wang, 2020)。
- 另一个研究方向是插入参数。例如,Zhang 等人(2020a)训练了一个 “side” 网络,该网络通过求和与预训练模型融合;
- adapter-tuning 则在预训练 LM 的每一层之间插入特定任务层(适配器)(Houlsby 等人,2019;Lin 等人,2020;Rebuffi 等人,2017;Pfeiffer 等人,2020)。
与 adapter-tuning 调整了约 3.6% 的 LM 参数的方法相比,我们的方法在保持可比性能的同时,仅调整了 0.1% 的特定任务参数,进一步减少了 30 倍。
Prompting.
提示是指在任务输入中预设指令和一些示例,并根据 LM 生成输出。GPT-3 使用人工设计的提示来适应不同任务的生成,这种框架被称为上下文中/语境学习(in-context learning)。然而,由于 Transformers 只能以一定长度的上下文为条件(如 GPT3 的 2048 个标记),因此上下文内学习无法充分利用比上下文窗口更长的训练集。
-
Sun 和 Lai(2020 年)还通过关键词提示来控制生成句子的情感或主题。
-
在自然语言理解任务中,先前的研究已经对 BERT 和 RoBERTa 等模型的提示工程进行了探索(Liu 等人,2019 年;Jiang 等人,2020 年;Schick 和 Sch ̈utze,2020 年)。例如,AutoPrompt(Shin 等人,2020 年)会搜索一连串离散的触发词(trigger words),并将其与每条输入信息串联(concatenate)起来,从而从被遮蔽的 LM 中获取情感或事实知识。
-
与 AutoPrompt 不同,我们的方法优化的是连续前缀,因为连续前缀更具表现力(第 7.2 节);此外,我们专注于语言生成任务。
连续向量已被用于引导语言模型;例如,Subramani 等人(2020 年)的研究表明,预训练的 LSTM 语言模型可以通过优化每个句子的连续向量来重构任意句子,从而使向量成为特定于输入的。相比之下,前缀调优优化的是适用于该任务所有实例的特定任务前缀。因此,与应用仅限于句子重构的前述工作不同,前缀调优可应用于 NLG 任务。
Controllable generation.
可控生成的目的是引导预训练的语言模型与句子级别的属性(如积极情绪或体育话题)相匹配。这种控制可以在训练时进行:
- Keskar 等人(2019)对语言模型(CTRL)进行了预训练,使其符合关键词或 URL 等元数据的条件。
- 此外,还可以在解码时通过加权解码(GeDi,Krause 等人,2020 年)或迭代更新过去的激活(PPLM,Dathathri 等人,2020 年)进行控制。
然而,目前还没有直接的方法来应用这些可控生成技术,对生成的内容实施细粒度控制,而这正是表格到文本和摘要等任务所要求的。
3 Problem Statement
考虑一个条件生成任务,其中输入是上下文 x x x,输出 y y y 是一个标记序列。我们重点讨论图 2(右)所示的两项任务: 在从表格到文本的过程中, x x x 对应的是线性化的数据表格, y y y 是文本描述;在生成摘要任务中, x x x 是一篇文章, y y y 是简短摘要。
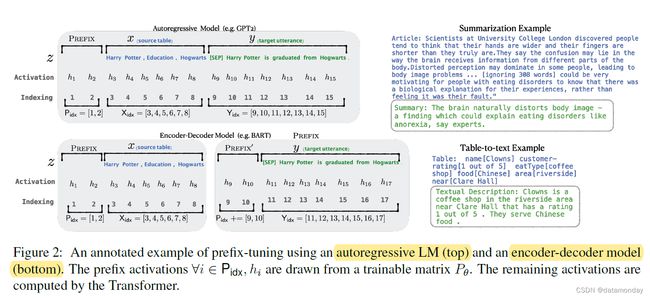
3.1 Autoregressive LM
假设我们有一个基于 Transformer 架构 (e.g., GPT-2; Radford et al., 2019) 的自回归语言模型 p φ ( y ∣ x ) p_φ(y | x) pφ(y∣x),参数为 φ φ φ。如图 2(上图)所示,设 z = [ x ; y ] z = [x; y] z=[x;y] 为 x x x 和 y y y 的连接(concatenation);设 X i d x X_{idx} Xidx 表示与 x x x 相对应的索引序列, Y i d x Y_{idx} Yidx 表示与 y y y 相对应的索引序列。
第 i i i 个时间步的激活为 h i ∈ R d h_i ∈ \mathbb{R}^d hi∈Rd,其中 h i = [ h i ( 1 ) ; . . . ; h i ( n ) ] h_i = [h^{(1)}_i ;...; h^{(n)}_i ] hi=[hi(1);...;hi(n)] 是该时间步骤所有激活层的连接, h i ( j ) h^{(j)}_i hi(j) 是第 i i i 个时间步骤第 j j j 个 Transformer 层的激活。( h i ( n ) h^{(n)}_i hi(n) 由键值对组成。在 GPT-2 中,每个键和值的维度都是 1024。)
自回归 Transformer 模型将 hi 计算为 zi 的函数及其左侧上下文中的过去激活,如下所示:
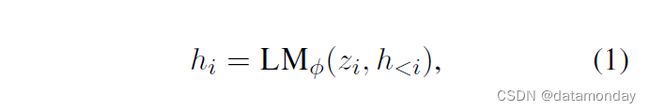
其中,hi 的最后一层用于计算下一个标记的分布:pφ(zi+1 | h≤i) = softmax(Wφ h(n)i ) ,而 Wφ 是一个预训练矩阵,用于将 h(n)i 映射到词汇表的 logits 上。
3.2 Encoder-Decoder Architecture
我们也可以使用编码器-解码器架构(如 BART;2020)来模拟 pφ(y|x),其中 x 由双向编码器编码,解码器自回归地预测 y(以编码的 x 及其左侧的上下文为条件)。
- 所有 i∈Xidx 的 hi 由双向Transformer编码器计算;
- 所有 i∈Yidx 的 hi 由自回归解码器使用相同的公式 (1) 计算。
3.3 Method: Fine-tuning
在微调框架中,我们使用预训练参数 φ 进行初始化。在这里,pφ 是一个可训练的语言模型分布,我们根据以下对数似然目标进行梯度更新:
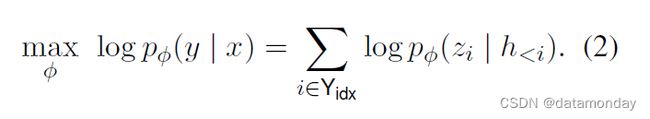
4 Prefix-Tuning
我们提出了前缀调优法,作为条件生成任务微调的替代方法。在第 4.2 节正式定义我们的方法之前,我们首先在第 4.1 节中提供直觉。
4.1 Intuition
根据提示的直觉,我们认为适当的上下文(context)可以在不改变 LM 参数的情况下引导 LM。例如,如果我们希望 LM 生成一个单词(如 Obama),我们可以将其常见搭配作为上下文(如 Barack)的前缀,这样 LM 就会为所需单词分配更高的概率。将这一直觉延伸到生成单个单词或句子之外,我们希望找到一种上下文,引导 LM 解决 NLG 任务。直观地说,上下文可以通过指导从 x 中提取什么来影响 x 的编码;也可以通过指导下一个标记的分布来影响 y 的生成。然而,这样的上下文是否存在并不明显。
- 自然语言任务指令(如 “summarize the following table in one sentence”)可能会指导专家注释者(expert annotator)解决任务,但对于大多数预训练的 LM 而言却不可行。(在我们的初步实验中,GPT-2 和 BART 在这种情况下失败了;唯一的例外是 GPT-3。)
- 对离散指令进行数据驱动优化可能会有所帮助,但离散优化在计算上具有挑战性。
我们可以将指令(instruction)优化为连续的单词嵌入,而不是对离散标记(discrete tokens)进行优化,其效果将向上传播到所有Transformer激活层,并向右传播到后续标记。严格来说,这比需要匹配实词嵌入的离散提示更具表现力。同时,这比介入所有激活层(第 7.2 节)的表现力要差,后者避免了长程依赖性,并包含更多可调参数。因此,前缀调优优化了前缀的所有层。
4.2 Method
如图 2 所示,前缀调优为自回归 LM 预置前缀,得到 z = [PREFIX;x;y],或为编码器和编码器预置前缀,得到 z = [PREFIX;x;PREFIX′;y]。这里,Pidx 表示前缀索引序列,我们用 |Pidx| 表示前缀的长度。
我们遵循公式(1)中的递推关系,只是前缀是自由参数。前缀调优初始化了一个维度为 |Pidx| × dim(hi) 的可训练矩阵 Pθ(参数为 θ),用于存储前缀参数。

训练目标与公式 (2) 相同,但可训练的参数集有所变化:语言模型参数 φ 固定不变,前缀参数 θ 是唯一可训练的参数。
这里, h i h_i hi(对于所有 i)是可训练 Pθ 的函数。当 i ∈ P i d x i \in P_{idx} i∈Pidx 时,这一点很明显,因为 hi 是直接从 Pθ 复制而来的。当 i ∉ P i d x i \notin P_{idx} i∈/Pidx 时, h i h_i hi 仍然取决于 Pθ,因为前缀激活总是在左侧上下文中,因此会影响其右侧的任何激活。
4.3 Parametrization of Pθ
根据经验,直接更新 Pθ 参数会导致优化效果不稳定,性能也会略有下降(我们在初步实验中发现,直接优化前缀对学习率和初始化非常敏感。)。因此,我们将矩阵 P θ [ i , : ] = M L P θ ( P θ ′ [ i , : ] ) P_θ[i,:] = MLP_θ(P'_θ[i,:]) Pθ[i,:]=MLPθ(Pθ′[i,:]) 重新参数化为一个由大型前馈神经网络(MLPθ)组成的较小矩阵( P θ ′ P^′_θ Pθ′)。需要注意的是, P θ P_θ Pθ 和 P θ ′ P^′_θ Pθ′ 的行维度(即前缀长度)相同,但列维度不同(Pθ 的维度为 |Pidx| × dim(hi),而 Pθ 的维度为 |Pidx| × k,我们选择 k = 512 用于表格到文本任务,k = 800 用于生成摘要任务。MLPθ 从维度 k 映射到 dim(hi))。训练完成后,这些重新参数化的参数可以丢弃,只需保存前缀(Pθ)。
5 Experimental Setup
5.1 Datasets and Metrics
我们在三个标准神经生成数据集上对表格到文本任务进行了评估: E2E(Novikova 等人,2017 年)、WebNLG(Gardent 等人,2017 年)和 DART(Radev 等人,2020 年)。这些数据集按照复杂程度和规模的递增顺序排列。E2E 只有一个域(即餐厅评论);WebNLG 有 14 个域,而 DART 是开放域,使用维基百科的开放域表。
E2E 数据集包含 8 个不同字段的约 50K 个示例;它包含一个源表的多个测试引用,平均输出长度为 22.9。我们使用了官方评估脚本,该脚本报告了 BLEU(Papineni 等人,2002 年)、NIST(Belz 和 Reiter,2006 年)、METEOR(Lavie 和 Agarwal,2007 年)、ROUGE-L(Lin,2004 年)和 CIDEr(Vedantam 等人,2015 年)。
WebNLG 数据集(Gardent 等人,2017 年)包含 22K 个示例,输入 x 是(主体、属性、客体)三元组的序列。平均输出长度为 22.5。在训练和验证拆分中,输入描述的实体来自 9 个不同的 DBpedia 类别(如纪念碑)。测试部分由两部分组成:前半部分包含训练数据中出现过的 DB 类别,后半部分包含 5 个未出现过的类别。这些未见类别用于评估外推法。我们使用的是官方评估脚本,该脚本会报告 BLEU、METEOR 和 TER(Snover 等人,2006 年)。
DART (Radev 等人,2020 年)是一个开放领域的从表格到文本的数据集,其输入格式(实体-关系-实体三元组)与 WebNLG 相似。平均输出长度为 21.6。它由来自 WikiSQL、WikiTableQuestions、E2E 和 WebNLG 的 82K 个示例组成,并应用了一些手动或自动转换。我们使用官方评估脚本并报告了 BLEU、METEOR、TER、MoverScore(Zhao 等人,2019 年)、BERTScore(Zhang 等人,2020b)和 BLEURT(Sellam 等人,2020 年)。
在总结任务中,我们使用了 XSUM(Narayan 等人,2018 年)数据集,这是一个新闻文章的抽象总结数据集。该数据集有 225K 个例子。文章的平均长度为 431 个单词,摘要的平均长度为 23.3 个单词。我们报告了 ROUGE-1、ROUGE2 和 ROUGE-L。
5.2 Methods
对于表格到文本的生成,我们将前缀调优与其他三种方法进行了比较:微调(FINE-TUNE)、仅对顶部 2 层进行微调(FT-TOP2)和适配器调优(ADAPTER)5: 在 E2E 数据集上,Shen 等人(2019)使用了无需预训练的实用信息模型。在 WebNLG 上,Kale(2020)对 T5-large 进行了微调。在 DART 上,还没有发布在该数据集版本上训练过的官方模型。6 在总结方面,我们与微调 BART(Lewis 等人,2020 年)进行了比较。
5.3 Architectures and Hyperparameters
对于表格到文本的转换,
- 我们使用 GPT-2MEDIUM 和 GPT2LARGE;
- 源表格经过线性化处理(与自然语言话语相比,线性化表格式不自然,这对于预训练的 LM 来说可能具有挑战性。)。
对于摘要转换,
- 我们使用 BARTLARGE(我们没有包括 GPT-2 的摘要结果,因为在我们的初步实验中,微调 GPT-2 在 XSUM 上的表现明显低于微调 BART),源文章被截断为 512 个 BPE 标记。
我们的实现基于 Hugging Face Transformer 模型。在训练时,我们使用 AdamW 优化器(Loshchilov 和 Hutter,2019 年)和线性学习率调度器,正如 Hugging Face 默认设置所建议的那样。我们调整的超参数包括epoch次数、批量大小、学习率和前缀长度。超参数详情见附录。默认设置是训练 10 个 epoch,使用 5 的批次大小、5x10-5 的学习率和 10 的前缀长度。表到文本模型在 TITAN Xp 或 GeForce GTX TITAN X 机器上进行训练。在 22K 个示例上训练前缀调优每个 epochs 需要 0.2 个小时,而微调大约需要 0.3 个小时。摘要模型在 Tesla V100 机器上进行训练,在 XSUM 数据集上每个历时耗时 1.25 小时。
在解码时,对于三个表对文数据集,我们使用波束搜索,波束大小为 5。对于摘要,我们使用的波束大小为 6,长度归一化为 0.8。表到文本的解码时间为每句 1.2 秒(不分批),摘要的解码时间为每批 2.6 秒(分批大小为 10)。
6 Main Results
6.1 Table-to-text Generation
我们发现,只需添加 0.1% 的特定任务参数,前缀调优就能有效地生成表格到文本,其性能优于其他轻量级基线(ADAPTER 和 FT-TOP2),并且与微调性能相当。这一趋势在所有三个数据集上都是如此: E2E、WebNLG10 和 DART 都是如此。
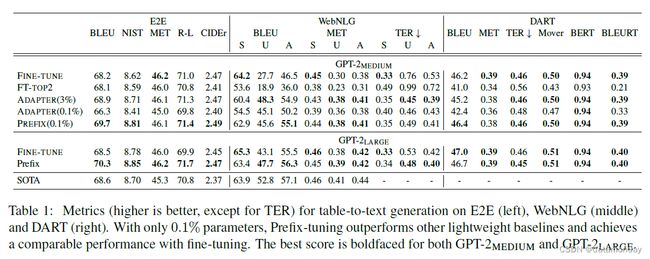
为了进行公平比较,我们将前缀调优和适配器调优的参数数匹配为 0.1%。表 1 显示,前缀调优明显优于 ADAPTER(0.1%),平均每个数据集的 BLEU 提高了 4.1。即使与微调(100%)和适配器调优(3.0%)相比,前缀调优更新的参数明显多于前缀调优,但前缀调优仍然取得了与这两个系统相当甚至更好的结果。这表明,前缀调优比适配器调优更具帕累托效率,在提高生成质量的同时大大减少了参数。
此外,在 DART 上取得的良好性能表明,前缀调优可以适用于具有不同领域和大量关系的表。我们将在第 6.4 节中深入探讨外推性能(即对未见类别或主题的泛化)。
总之,前缀调优是一种有效且节省空间的方法,可使 GPT-2 适应表格到文本的生成。学习到的前缀具有足够的表现力,可以引导 GPT-2 从非自然格式中正确提取内容并生成文本描述。前缀调优还能很好地从 GPT-2MEDIUM 扩展到 GPT-2LARGE,这表明它有潜力扩展到类似架构的更大模型,如 GPT-3。
6.2 Summarization
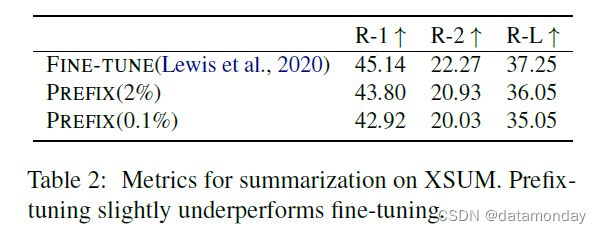
如表 2 所示,在参数为 2% 的情况下,前缀调优的性能略低于微调(在 ROUGE-L 中为 36.05 对 37.25)。在参数仅为 0.1% 的情况下,前缀调优的性能低于完全微调(35.05 对 37.25)。XSUM 与三个表对文本数据集之间存在一些差异,这可能是前缀调优在表对文本中具有相对优势的原因:
- 1)XSUM 包含的示例数平均是三个表对文本数据集的 4 倍;
- 2)输入文章的长度平均是表对文本数据集线性化表格输入长度的 17 倍;
- 3)摘要可能比表对文本更复杂,因为它需要阅读理解和识别文章中的关键内容。
6.3 Low-data Setting
根据表到文(§ 6.1)和摘要化(§ 6.2)的结果,我们发现当训练示例数量较少时,预修正具有相对优势。为了构建低数据设置,我们对全部数据集(表到文本的 E2E 和摘要化的 XSUM)进行子采样,以获得大小为{50, 100, 200, 500}的小数据集。对于每种大小,我们抽取 5 个不同的数据集,并对 2 个训练随机种子进行平均。因此,我们对 10 个模型取平均值,以得到每个低数据设置的估计值。

图 3(右)显示,在低数据量情况下,前缀调优比微调平均高出 2.9 BLEU,而且所需的参数也要少得多,但随着数据集规模的增加,差距也在缩小。
图 3(左)显示了前缀调优和微调模型在不同数据量下生成的 8 个例子。虽然两种方法在低数据量情况下都倾向于生成不足(缺少表格内容),但前缀调优往往比微调更忠实。例如,微调(100,200)12 会错误地声称客户评分较低,而真实评分是平均值,而前缀调优(100,200)生成的描述则忠实于表格。
6.4 Extrapolation
现在,我们将研究从表格到文本和摘要的外推性能。为了构建外推环境,我们拆分了现有的数据集,使训练和测试涵盖不同的主题。对于从表格到文本,WebNLG 数据集标注的是表格主题。有 9 个类别在训练和测试中都会出现,记为 SEEN;有 5 个类别只在测试时出现,记为 UNSEEN。因此,我们通过对 SEEN 类别进行训练和对 UNSEEN 类别进行测试来评估外推法。为了进行总结,我们构建了两种外推数据拆分13: 在 “新闻-体育”(news-to-sports)中,我们对新闻文章进行训练,对体育文章进行测试。在 "新闻内部 "中,我们对{世界、英国、商业}新闻进行训练,并对其余新闻类别(如健康、技术)进行测试。

如表 3 和表 1(中)的 "U "列所示,在表到文本和摘要这两个方面,前缀调优在所有指标下都比微调具有更好的外推性能。
我们还发现,如表 1 所示,适配器调优实现了良好的外推性能,与前缀调优不相上下。这一共同趋势表明,保留 LM 参数确实会对外推(extrapolation)产生积极影响。然而,这种增益的原因是一个悬而未决的问题,我们将在第 8 节中进一步讨论。
7 Intrinsic Evaluation
我们比较了前缀调优的不同变体。§ 7.1 研究了前缀长度的影响。§ 7.2 只研究了嵌入层的调整,这更类似于离散提示的调整。§7.3 比较了前缀化和后缀化,后缀化在 x 和 y 之间插入了可训练的激活。§7.4 研究了各种前缀初始化策略的影响。
7.1 Prefix Length
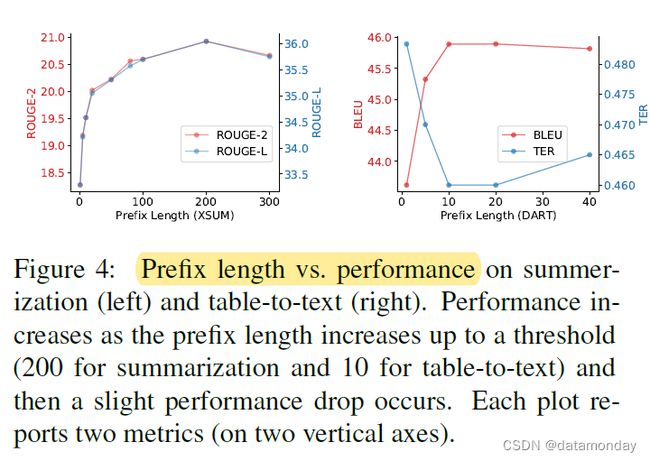
前缀越长,意味着可训练的参数越多,因此表达能力越强。图 4 显示,随着前缀长度增加到一个阈值(总结为 200,表格到文本为 10),性能会有所提高,然后会出现轻微的性能下降。
根据经验,较长的前缀对推理速度的影响可以忽略不计,因为整个前缀的注意力计算在 GPU 上是并行的。
7.2 Full vs Embedding-only
回顾第 4.1 节,我们讨论了优化 "虚拟标记 "连续嵌入的方案。我们将这一想法实例化,并称之为纯嵌入式消融。词嵌入是自由参数,上层激活层由Transformer计算。表 4(上)显示,性能显著下降,这表明只调整嵌入层的表现力不够。
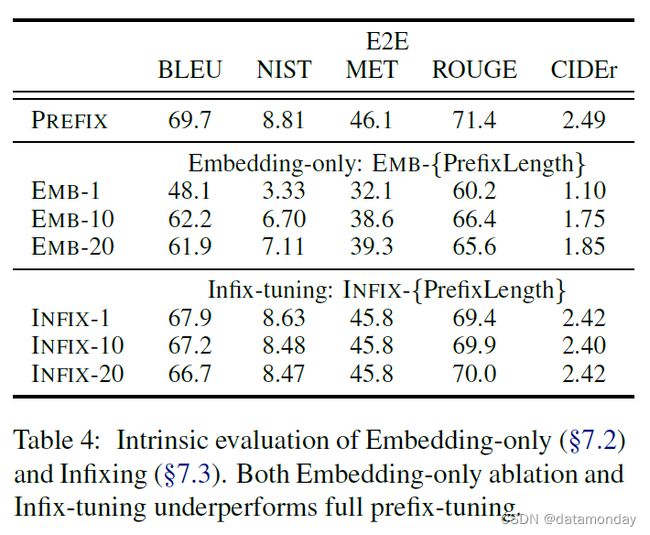
纯嵌入式消融为离散提示(discrete prompt)优化的性能设定了上限 (Shin et al., 2020),因为离散提示限制嵌入层与实词的嵌入完全匹配。因此,我们可以得出这样一个表达能力递增链:discrete prompting< embedding-only ablation < prefix-tuning。
7.3 Prefixing vs Infixing
我们还研究了可训练激活在序列中的位置对性能的影响。在前缀调优中,我们将它们放在开头[PREFIX; x; y]。我们也可以将可训练激活放在 x 和 y 之间(即 [x; INFIX; y]),并将其称为后缀调优(infix-tuning)。表 4(下)显示,infix-tuning 略逊于 prefix-tuning。我们认为这是因为前缀调优可以影响 x 和 y 的激活,而后缀调整只能影响 y 的激活。
7.4 Initialization

我们发现,前缀的初始化方式对低数据设置有很大影响。随机初始化会导致低性能和高方差。如图 5 所示,使用实词激活来初始化前缀可以显著提高生成效率。特别是使用 “summarization” 和 “table-to-text” 等与任务相关的词进行初始化时,性能略好于使用 “elephant” 和 “dividue” 等与任务无关的词,但使用实词的效果仍好于随机初始化。
由于我们使用 LM 计算的实词激活来初始化前缀,因此这种初始化策略与尽可能保留预训练的 LM 是一致的。
8 Discussion
8.1 Personalization
正如我们在第 1 节中所指出的,当有大量任务需要独立训练时,前缀调优就显得非常有利。用户隐私就是一种实用的设置(Shokri 和 Shmatikov,2015;McMahan 等人,2016)。为了保护用户隐私,需要将每个用户的数据分开,并为每个用户独立训练个性化模型。因此,每个用户都可以被视为一个独立的任务。如果用户数量达到数百万,前缀调优技术就能适应这种情况,并保持模块化,通过添加或删除用户的前缀,灵活地添加或删除用户,而不会造成交叉污染。
8.2 Batching Across Users
在相同的个性化设置下,即使不同用户的查询有不同的前缀支持,前缀调优也能对其进行批处理。当多个用户向云 GPU 设备查询其输入时,将这些用户归入同一批次会提高计算效率。前缀调优可保持共享的 LM 不变;因此,批处理只需在用户输入前添加个性化前缀,其余所有计算均保持不变。相比之下,在适配器调优中,我们无法对不同用户进行批处理,因为在共享的Transformer层之间有个性化的适配器。
8.3 Inductive Bias of Prefix-tuning
回想一下,微调会更新所有预训练参数,而前缀调优和适配器调优则会保留这些参数。由于语言模型是在通用语料库上进行预训练的,因此保留 LM 参数可能有助于泛化到训练期间未见过的领域。与这一直觉相一致,我们发现前缀调优和适配器调优在外推法设置中都有显著的性能提升(第 6.4 节);然而,这种提升的原因是一个未决问题。
虽然前缀调优和适配器调优都冻结了预训练参数,但它们调整了不同的参数集来影响Transformer的激活层。回顾一下,前缀调优会保持 LM 不变,并使用前缀和预训练的注意力块来影响后续激活;而适配器调优则会在 LM 层之间插入可训练模块,直接将残差向量添加到激活中。此外,我们还发现,与适配器调优相比,前缀调优所需的参数要少得多,但性能却不相上下。我们认为,这种参数效率的提高是因为前缀调优尽可能保持了预训练 LM 的完整性,因此比适配器调优更能利用 LM。
Aghajanyan 等人(2020 年)同时进行的研究利用本征维度表明,存在一种低维度的重参数化,其微调效果不亚于完整参数空间。这就解释了为什么只需更新少量参数,就能在下游任务中获得很高的精度。我们的工作与这一发现相呼应,表明只需更新很小的前缀,就能获得良好的生成性能。
9 Conclusion
我们提出了前缀调优法,它是微调法的一种轻量级替代方案,可为 NLG 任务预置可训练的连续前缀。我们发现,尽管学习的参数比微调少 1000 倍,前缀调优仍能在全数据环境下保持与微调相当的性能,而且在低数据和外推环境下都优于微调。