LSTM模型的讲解与运用
实验目的:
循环神经网络(RNN)是一类以序列数据为输入,在序列的演进方向进行循环且所有循环单元按链式连接的神经网络。目前RNN已经广泛应用于语音识别、文本分类等自然语言处理任务中。本实验通过采用循环神经网络的变体长短期记忆网络(LSTM),合理设计网络结构和算法来实现自动写诗和藏头诗的功能。
环境配置:
利用pytcharm配置pytroch和opencv;
参数:
epoches = 8
Lr=0.001
Batch=575
实验步骤:(以自动写诗为例)
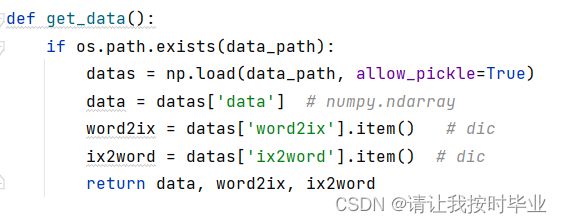
图 5 加载数据
由图5加载诗的数据,返回标签。
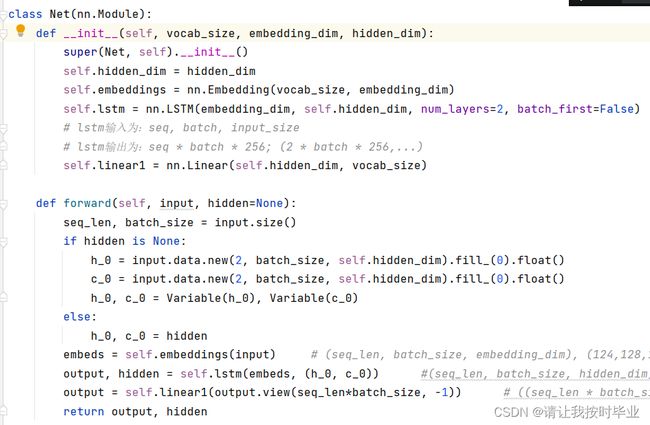
图 6 lstm网络
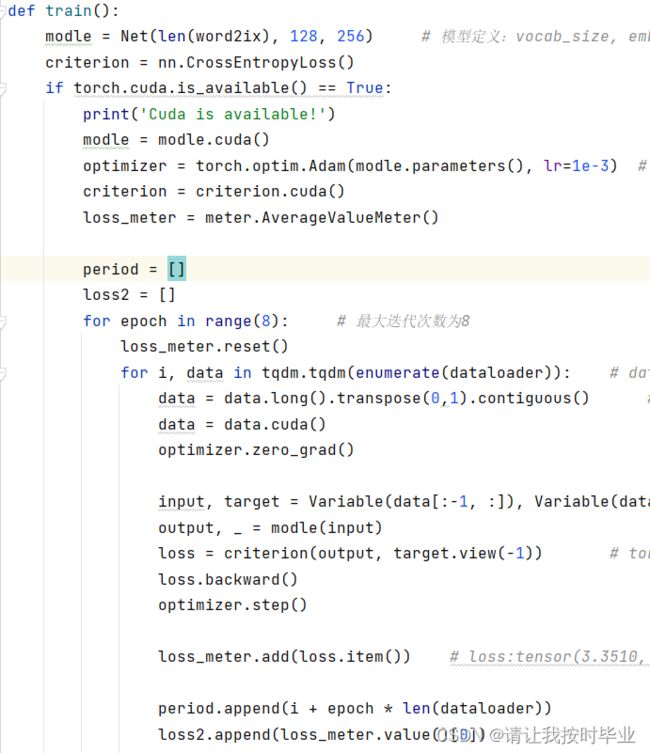
图 7 训练过程
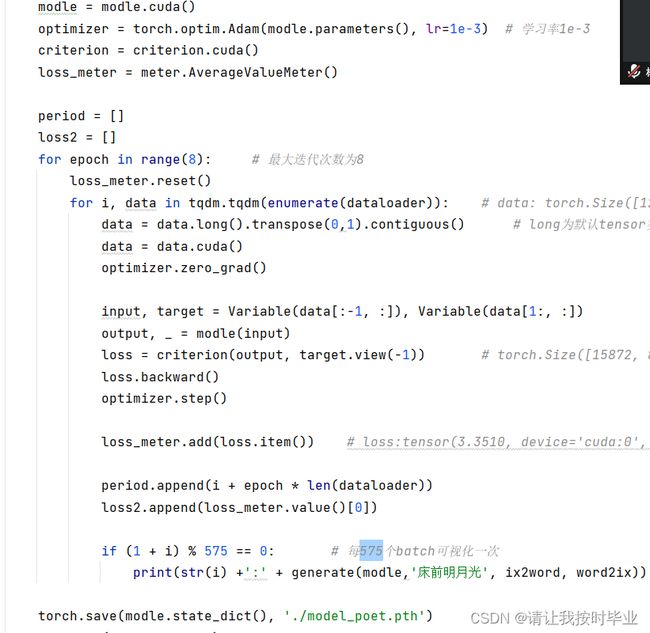
图 8 自动写诗代码

图 9 根据首字母生成诗句代码
图5到图9分别从加载图片,训练神经网络,到生成诗句的过程。
准确率:

图 10 训练结果
结果分析:

图 11 自动写诗的过程
由该图可以看出,对床前明月光的自动续写结果。

图 12 根据首字生成诗
由test函数可以生成龙碧和弦四个字开头的诗句。效果如图12。
源代码:
import numpy as np # tang.npz的压缩格式处理
import os # 打开文件
import torch
import torch.nn as nn
from torch.autograd import Variable
import torch.nn.functional as F
import matplotlib.pyplot as plt
from torchnet import meter
import tqdm
def get_data():
if os.path.exists(data_path):
datas = np.load(data_path, allow_pickle=True) # 加载数据
data = datas['data'] # numpy.ndarray
word2ix = datas['word2ix'].item() # dic
ix2word = datas['ix2word'].item() # dic
return data, word2ix, ix2word
class Net(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim):
super(Net, self).__init__()
self.hidden_dim = hidden_dim
self.embeddings = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, self.hidden_dim, num_layers=2, batch_first=False)
# lstm输入为:seq, batch, input_size
# lstm输出为:seq * batch * 256; (2 * batch * 256,...)
self.linear1 = nn.Linear(self.hidden_dim, vocab_size)
def forward(self, input, hidden=None):
seq_len, batch_size = input.size()
if hidden is None:
h_0 = input.data.new(2, batch_size, self.hidden_dim).fill_(0).float()
c_0 = input.data.new(2, batch_size, self.hidden_dim).fill_(0).float()
h_0, c_0 = Variable(h_0), Variable(c_0)
else:
h_0, c_0 = hidden
embeds = self.embeddings(input) # (seq_len, batch_size, embedding_dim), (124,128,128)
output, hidden = self.lstm(embeds, (h_0, c_0)) #(seq_len, batch_size, hidden_dim), (124,128,256)
output = self.linear1(output.view(seq_len*batch_size, -1)) # ((seq_len * batch_size),hidden_dim), (15872,256) → (15872,8293)
return output, hidden
def train():
modle = Net(len(word2ix), 128, 256) # 模型定义:vocab_size, embedding_dim, hidden_dim —— 8293 * 128 * 256
criterion = nn.CrossEntropyLoss()
if torch.cuda.is_available() == True:
print('Cuda is available!')
modle = modle.cuda()
optimizer = torch.optim.Adam(modle.parameters(), lr=1e-3) # 学习率1e-3
criterion = criterion.cuda()
loss_meter = meter.AverageValueMeter()
period = []
loss2 = []
for epoch in range(8): # 最大迭代次数为8
loss_meter.reset()
for i, data in tqdm.tqdm(enumerate(dataloader)): # data: torch.Size([128, 125]), dtype=torch.int32
data = data.long().transpose(0,1).contiguous() # long为默认tensor类型,并转置, [125, 128]
data = data.cuda()
optimizer.zero_grad()
input, target = Variable(data[:-1, :]), Variable(data[1:, :])
output, _ = modle(input)
loss = criterion(output, target.view(-1)) # torch.Size([15872, 8293]), torch.Size([15872])
loss.backward()
optimizer.step()
loss_meter.add(loss.item()) # loss:tensor(3.3510, device='cuda:0', grad_fn=)loss.data:tensor(3.0183, device='cuda:0')
period.append(i + epoch * len(dataloader))
loss2.append(loss_meter.value()[0])
if (1 + i) % 575 == 0: # 每575个batch可视化一次
print(str(i) +':' + generate(modle,'床前明月光', ix2word, word2ix))
torch.save(modle.state_dict(), './model_poet.pth')
plt.plot(period, loss2)
plt.show()
def generate(model, start_words, ix2word, word2ix): # 给定几个词,根据这几个词生成一首完整的诗歌
txt = []
for word in start_words:
txt.append(word)
input = Variable(torch.Tensor([word2ix['']]).view(1,1).long()) # tensor([8291.]) → tensor([[8291.]]) → tensor([[8291]])
input = input.cuda()
hidden = None
num = len(txt)
for i in range(48): # 最大生成长度
output, hidden = model(input, hidden)
if i < num:
w = txt[i]
input = Variable(input.data.new([word2ix[w]])).view(1, 1)
else:
top_index = output.data[0].topk(1)[1][0]
w = ix2word[top_index.item()]
txt.append(w)
input = Variable(input.data.new([top_index])).view(1, 1)
if w == '':
break
return ''.join(txt)
def gen_acrostic(model, start_words, ix2word, word2ix):
result = []
txt = []
for word in start_words:
txt.append(word)
input = Variable(
torch.Tensor([word2ix['']]).view(1, 1).long()) # tensor([8291.]) → tensor([[8291.]]) → tensor([[8291]])
input = input.cuda()
hidden = None
num = len(txt)
index = 0
pre_word = ''
for i in range(48):
output, hidden = model(input, hidden)
top_index = output.data[0].topk(1)[1][0]
w = ix2word[top_index.item()]
if (pre_word in {'。', '!', ''}):
if index == num:
break
else:
w = txt[index]
index += 1
input = Variable(input.data.new([word2ix[w]])).view(1,1)
else:
input = Variable(input.data.new([word2ix[w]])).view(1,1)
result.append(w)
pre_word = w
return ''.join(result)
def test():
modle = Net(len(word2ix), 128, 256) # 模型定义:vocab_size, embedding_dim, hidden_dim —— 8293 * 128 * 256
if torch.cuda.is_available() == True:
modle.cuda()
modle.load_state_dict(torch.load('./model_poet.pth'))
modle.eval()
# txt = generate(modle, '床前明月光', ix2word, word2ix)
# print(txt)
txt = gen_acrostic(modle, '龙碧和弦', ix2word, word2ix)
print(txt)
if __name__ == '__main__':
data_path = './tang.npz'
data, word2ix, ix2word = get_data()
data = torch.from_numpy(data)
dataloader = torch.utils.data.DataLoader(data, batch_size=10, shuffle=True, num_workers=1) # shuffle=True随机打乱
#train()
test()