【yolov8系列】yolov8的目标检测、实例分割、关节点估计的原理解析
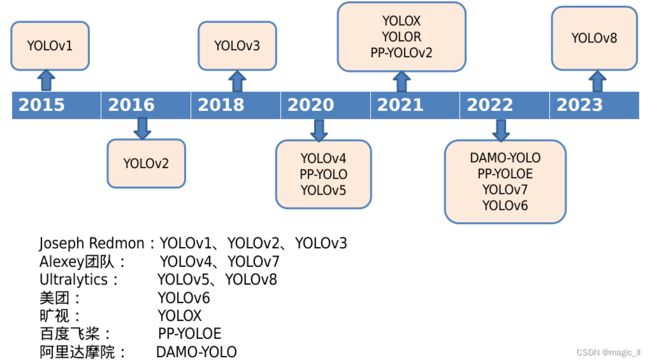
1 YOLO时间线
这里简单列下yolo的发展时间线,对每个版本的提出有个时间概念。
2 yolov8 的简介
工程链接:https://github.com/ultralytics/ultralytics
2.1 yolov8的特点
- 采用了anchor free方式,去除了先验设置可能不佳带来的影响
- 借鉴Generalized Focal Loss,使用任务解耦,分别学习box,class。并将box边框的学习,从回归的形式更换成交叉熵的形式
- 增加了实例分割的功能,该模块借鉴了 YOLACT 的思想
2.2 yolov8 的相关参数
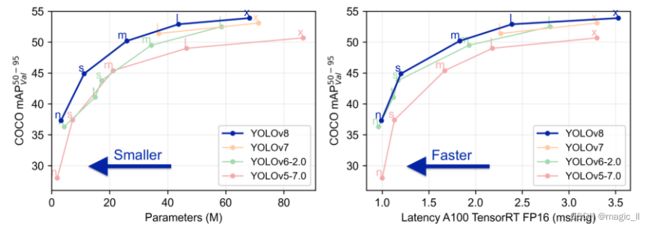
以上为官方视图:
- YOLOv8 相比 YOLOv5,mAP提升较多
- 左图可得: N/S/M 模型相应的参数量和 FLOPs 都增加了不少
- 右图可得:相比 YOLOV5,YOLOv8 大部分模型推理速度变慢
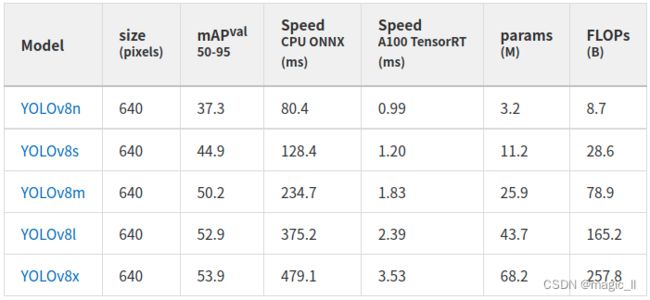
其中目标检测模型的相关参数如下图,更多的看查阅工github的官方工程:
以下章节分别对yolov8的目标检测、实例分割、关键点估计、目标跟踪进行介绍
3 yolov8 目标检测
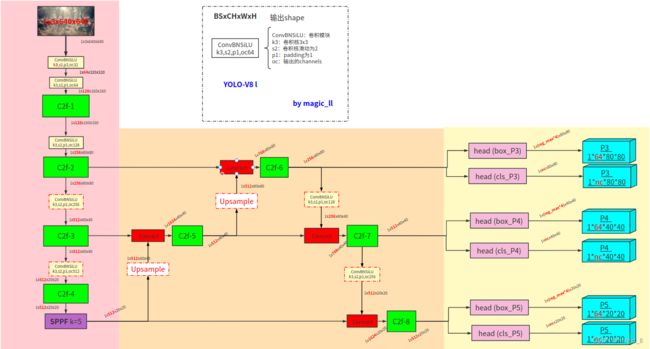
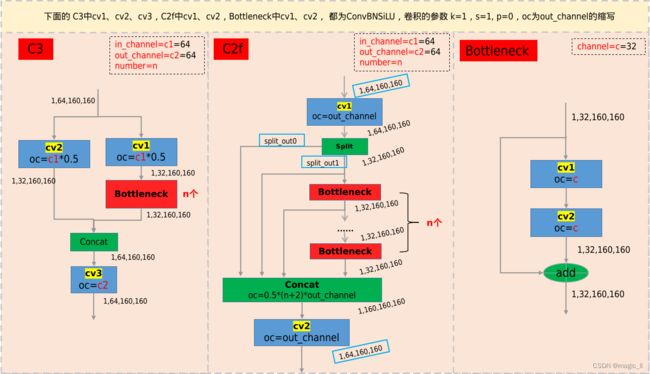
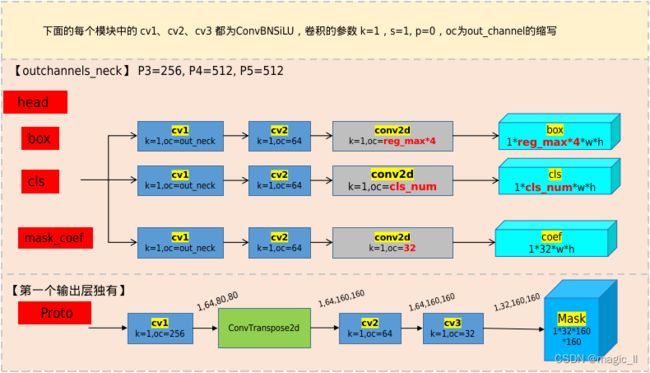
3.1 网络结构
3.1.1 网络结构
- 【backbone】C2f、SPPF、Conv_BN_SiLU(strides=2,用于下采样)
- 【neck】FPN(特征金字塔网络)、PAN(路径聚合网络)
- 【head】Conv_BN_SiLU的堆叠分别输出:box、cls
- 【backbone】
第一个Conv的kernel:6*6 --> 3*3;
C3模块替换了C2f,其数量从3-6-9-3,变成了3-6-6-3。- 【neck】
FPN中去除第一个的卷积;
yolov8中的N/S、M、L/X 三组网络中最后的C2f输出通道不同,分别为1024,768,512。- 【head】
yolov5中单个Conv_BN_SiLU,同时输出三个信息:obj、cls、box
yolov8中使用Conv_BN_SiLU的堆叠,并分支输出两个信息:box、cls。3.1.2 C3 & C2f
C2f相较于C3,有更多的跳层连接,与更多的特征的concat,梯度流更丰富。有助于更为丰富的特征的融合和提取
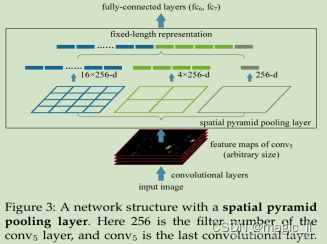
3.1.3 SPP & SPPF 空间金字塔池化
- 上图是SPPNET原论文中提出的:提取并融合更多尺度的特征,使用fc_layer的同时并能够适应不同尺寸的输入
- 下左图是YOLOV5、YOLOV8中使用的SPP:继承了原SPP的提取更多尺度的特征,但结构上已更新
- 下右图是fast SPP,对SPP进行了改进,减小参数的、增加运算速度,但不改变计算结果
3.1.4 head
yolov5的head 的每层中分别为一个分支,同时预测3个内容:检测框质量( 1 是否为目标 ∗ i o u p r e d , l a b e l 1_{是否为目标}*iou_{pred,label} 1是否为目标∗ioupred,label)、类别的onehot、box的xywh。
与yolov5不同,yolov8的目标检测解耦了目标框和类别的预测,每层有两个分支,分别预测:类别的 o n e h o t ∗ i o u p r e d , l a b e l onehot*iou_{pred,label} onehot∗ioupred,label、box的xywh。
3.2 目标检测的head输出
yolov8 的目标检测头,采用了Generalized Focal Loss,详细的内容可以看链接中的论文阅读,这里说明下关键点
3.2.1 定位质量与类别
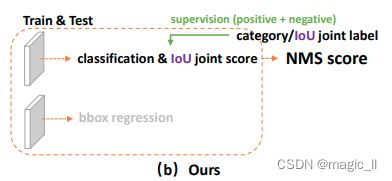
- 已有工作问题:训练和测试之间的差距,并可能会降低检测性能
- GFL工作解决:分类IoU联合表示
分类onehot向量的标签 在真实类别位置上的是其相应的定位质量(预测box与标签box的iou)。也就是:类别的 o n e h o t ∗ i o u p r e d , l a b e l onehot*iou_{pred,label} onehot∗ioupred,label。
训练时和测试时使用相同的规则,它消除了训练-测试的不一致性,并使定位质量和分类之间具有最强的相关性。
- 举例子:
左边为已有工作,右边为GFL,针对分类项目可称为QFL3.2.1 box的预测
- 已有工作:
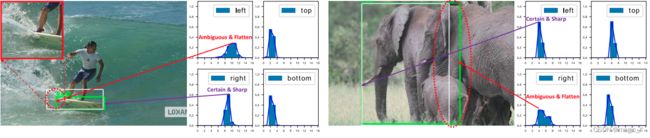
边界框表示是唯一确定的位置,为一个简单的狄拉克分布,并采用回归方式进行训练。
问题:但是,它没有考虑到数据集的模糊性和不确定性。如下图中的边界不清晰,因此真实标签(白色框)有时不可信,狄拉克分布无法很好的表示这些问题。- GFL工作:
对于边界框表示,直接学习box位置上的离散概率分布,而不引入任何其他更强的先验(比如统计出来的anchor)。因此,我们可以获得更可靠和准确的边界框估计,同时了解它们的各种潜在分布。
给定标签y的范围为 y 0 ≤ y ≤ y n , n ∈ N + y_0≤y≤y_n,n∈N^+ y0≤y≤yn,n∈N+,我们可以从模型中得到估计值 y ^ \hat{y} y^, 也满足 y 0 ≤ y ^ ≤ y n y_0≤\hat{y}≤y_n y0≤y^≤yn: y ^ = ∫ − ∞ + ∞ P ( x ) x d x = ∫ y 0 y n P ( x ) x d x \hat{y}=\int_{-\infty }^{+\infty }P(x)xdx=\int_{y_0}^{y_n}P(x)xdx y^=∫−∞+∞P(x)xdx=∫y0ynP(x)xdx为了与卷积神经网络保持一致,我们将连续域上的积分转换为离散表示,从离散范围[y0,yn]到一个集合 { y 0 , y 1 , . . . , y i , y i + 1 . . . , y n − 1 , y n } \{y0,y1,...,y_i,y_{i+1}...,y_{n−1},y_n\} {y0,y1,...,yi,yi+1...,yn−1,yn},其间隔∆=1。因此,给定离散分布性质 ∑ i = 0 n P ( y i ) = 1 \sum_{i=0}^{n}P(y_i)=1 ∑i=0nP(yi)=1,估计的回归值 y ^ \hat{y} y^可以表示为: y ^ = ∑ i = 0 n P ( y i ) y i \hat{y}=\sum_{i=0}^{n}P(y_i)y_i y^=i=0∑nP(yi)yi
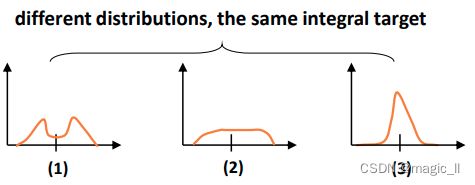
尝试多种分布,最终发现下图第三种效果最好
- 举例子:
左边为已有工作,右边为GFL,针对分类项目可称为DFL
- 算法具体实现:
主要的公式为: ∑ i = 0 n P ( y i ) = 1 \sum_{i=0}^{n}P(y_i)=1 ∑i=0nP(yi)=1、 y ^ = ∑ i = 0 n P ( y i ) y i \hat{y}=\sum_{i=0}^{n}P(y_i)y_i y^=∑i=0nP(yi)yi。然后我们仅使用边界的浮点型位置,使用项链的两个整形表达。
假设第三个输出层的尺寸上的标签(6.25, 4.75, 18.375, 12.875),此时框的中心设为(11,9),左边框距离anchor为5.75= 11-6.25。则用长度为16的向量表示该距离 d l d_l dl:[0,0,0,0,0.25, 0.75,0,0,0,0, 0,0,0,0,0, 0]。该向量满足内容为: ∑ i n d e x ∗ v a l u e = 5.75 \sum index*value=5.75 ∑index∗value=5.75, ∑ v a l u e = 1 \sum value=1 ∑value=1。
长度为16的向量最大可表达像素距离为15,那么这种表达方式,像素级最大可表达30*30的框。当模型共有5层,在第三个输出层是下采样了32倍,则30*30的框,在原尺寸上的大小为960*960。
所以只要网络输入尺寸<= 960,用四个长度为16的向量来表示框的四个边距离base点的距离,都可正确表达。若图片>960,理论上就需要增加向量的长度,但实际情况会现将图片先进行切割,然后多次预测,结果再转换到原图尺寸上。
3.3 正样本分配
yolov5中的正样本分配 是在训练之前已经完全确定了。
yolov8 中的正样本分配 TaskAlignedAssigner,属于动态分配,会根据当前网络输出的信息动态匹配 需要监督的标签。
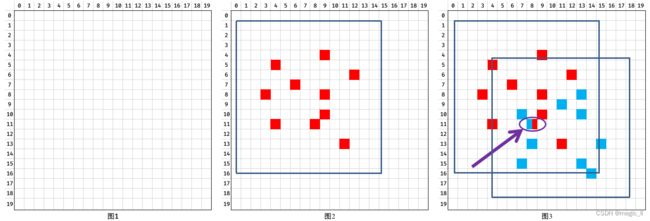
- 计算box在每一层的每个grid ceil上的iou、对齐衡量指标(匹配得分)。 a l i g n _ m e t r i c = s α ∗ u β align\_metric =s^{\alpha }*u^{\beta} align_metric=sα∗uβ 其中 s 和 u 分别表示分类得分和IoU,α 和 β 是权重系数用来控制两个任务对匹配得分的影响大小
- 获取box内top10的 align_metric 的位置的mask,如图2。
- 一个预测框与多个真实框匹配测情况进行处理,保留ciou值最大的真实框。如图3。
- 得到 target_bboxes, target_scores, fg_mask
3.4 损失函数
分类的gt_class --> target_class
target_class的转换(分类IoU联合表示):分类的onehot * iou(pred_box, label_box)。pred_class为长度为分类数量的向量。
则分类IoU联合表示的损失函数:sigmoid交叉熵。在代码中为:nn.BCEWithLogitsLossself.bce = nn.BCEWithLogitsLoss(reduction='none') loss[1] = self.bce(pred_scores, target_scores.to(dtype)).sum() / target_scores_sum # BCE这里补充下在pytorch中的损失函数的一些api
nn接口 function接口 nn.NLLLossF.nll_loss nn.BCELossF.binary_cross_entropy nn.BCEWithLogitsLossF.binary_cross_entropy_with_logits nn.CrossEntropyLoss= softmax + log + NLLlossF.cross_entropy 我们使用 ℓ ( x , y ) \ell(x,y) ℓ(x,y)来表示损失函数,则有 ℓ ( x , y ) = L = { l 1 , … , l N } ⊤ \ell(x, y) = L = \{l_1,\dots,l_N\}^\top ℓ(x,y)=L={l1,…,lN}⊤其中【N】batch、【x】input(在使用中一般为网络输出的内容)、【y】target、【 x n , y n x_{n,y_n} xn,yn】表示对应target那一类的概率。
- -
nn.NLLLoss():
l n = − w y n x n , y n l_n = - w_{y_n} x_{n,y_n} ln=−wynxn,ynnn.BCELoss中:
l n = − w n [ y n ⋅ log ( x n ) + ( 1 − y n ) ⋅ log ( 1 − x n ) ] l_n = - w_n \left[ y_n \cdot \log (x_n) + (1 - y_n) \cdot \log (1 - x_n) \right] ln=−wn[yn⋅log(xn)+(1−yn)⋅log(1−xn)]nn.BCEWithLogitsLoss = sigmoid + BCELoss
l n = − w n [ y n ⋅ log 1 1 + exp ( − x n ) + ( 1 − y n ) ⋅ log ( 1 − 1 1 + exp ( − x n ) ) ] l_n = - w_n \left[ y_n \cdot \log \frac{1}{1+\exp(-x_n)} + (1 - y_n) \cdot \log (1 - \frac{1}{1+\exp(-x_n)}) \right] ln=−wn[yn⋅log1+exp(−xn)1+(1−yn)⋅log(1−1+exp(−xn)1)]CrossEntropyLoss = softmax + log + NLLloss
l n = − ∑ c = 1 C w c log exp ( x n , c ) exp ( ∑ i = 1 C x n , i ) y n , c l_n = - \sum_{c=1}^C w_c \log \frac{\exp(x_{n,c})}{\exp(\sum_{i=1}^C x_{n,i})} y_{n,c} ln=−c=1∑Cwclogexp(∑i=1Cxn,i)exp(xn,c)yn,c
N L L ( l o g ( s o f t m a x ( i n p u t ) ) , t a r g e t ) = − Σ i = 1 n O n e H o t ( t a r g e t ) i × l o g ( s o f t m a x ( i n p u t ) i ) ( i n p u t ∈ R m × n ) \large \mathbf{NLL(log(softmax(input)),target) = -\Sigma_{i=1}^n OneHot(target)_i\times log(softmax(input)_i)} (input∈Rm×n) NLL(log(softmax(input)),target)=−Σi=1nOneHot(target)i×log(softmax(input)i)(input∈Rm×n)box 的 gt_class --> target_class
- CIOU:以往box检测框的损失函数都会使用的一项。
考虑三种几何参数:重叠面积、中心点距离、长宽比。CIoU就是在DIoU的基础上增加了检测框尺度的loss,增加了长和宽的loss,这样预测框就会更加的符合真实框。- Distribution Focal Loss (DFL):使用向量表达边界与基准点的距离,然后结合softmax交叉熵计算得DFL项的loss
将边界距离基准点的距离记为y,则可将基准点转换为(tl, tr),两者对应的权重为(wl, wr)。y.shape = tl.shape = tr.shape= [batch, n, 4]。
tl.view(-1).shape = tr.view(-1).shape = [batc*n*4](假设左边界距离y=5.6,则 t l = 5 tl=5 tl=5, t r = 6 tr=6 tr=6, t l = 0.4 tl=0.4 tl=0.4, w r = 0.6 wr=0.6 wr=0.6)
此时网络输出的边界为pred_dist,pred_dist.shape=[batc*n*4,16]。则损失函数如下,:loss = (F.cross_entropy(pred_dist, tl.view(-1), reduction='none').view(tl.shape) * wl + F.cross_entropy(pred_dist, tr.view(-1), reduction='none').view(tl.shape) * wr).mean(-1, keepdim=True)







4 yolov8 实例分割
4.1 网络结构
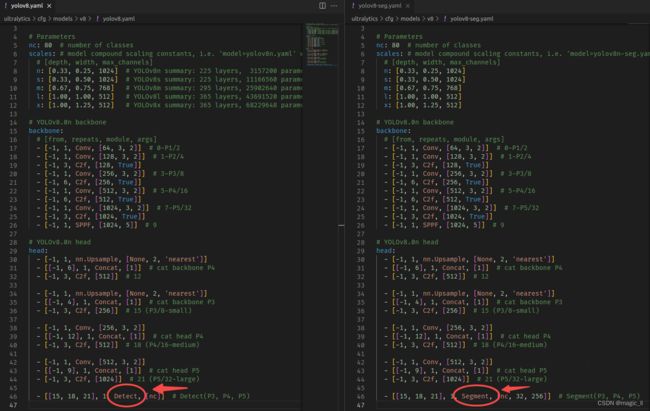
从工程实现中可以看到,分割的网络结构与目标检测的网络结构,主干网络、neck模块都是完全一致的,只有在任务侧 有所差异。
分割的head(coef) 与目标检测的head是基本一致的,仅最后一层的输出维度有所差异。
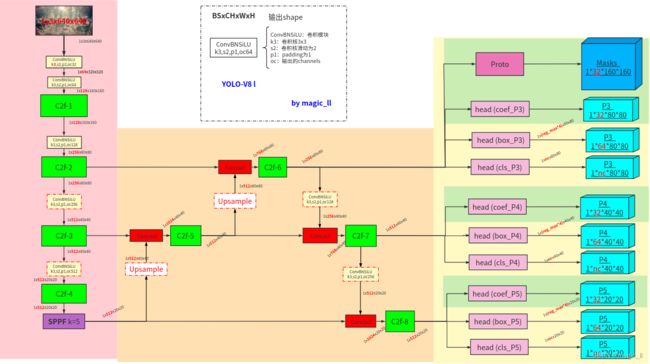
阅读源码并绘制网络结构图如上,可发现 在目标检测的head模块基础上,额外添加了segment的分支:掩码系数分支、原型分支。接下来会介绍该分割分支的具体使用。
3.2 分割的head输出
该部分内容借鉴了论文 YOLACT Real-time Instance Segmentation。
- 【Proto的输出】
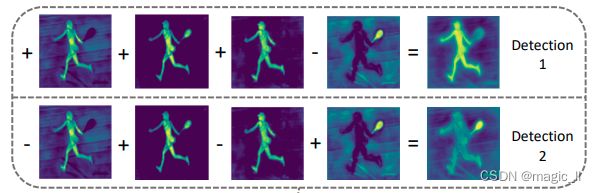
网络会在第一个输出层中,输出一组mask原型,其数量工程中设置为32。不同mask为网络学习到不同的掩码信息,值得注意的是单张mask并不意味着mask中只有一个目标的mask。将mask可视化如下图,第一张mask仅人体,第二张为人体+羽毛球拍,第三张为另一张人体mask,第四张为球拍。
需将所有的mask线性叠加然后得到当前目标的最终掩码信息。下图当中示意了默认系数为1的线性叠加,但实际该掩码系数不可能同时为1。则安排了神经网络预测该系数,也就是mask_coef分支。
- 【mask_coef】
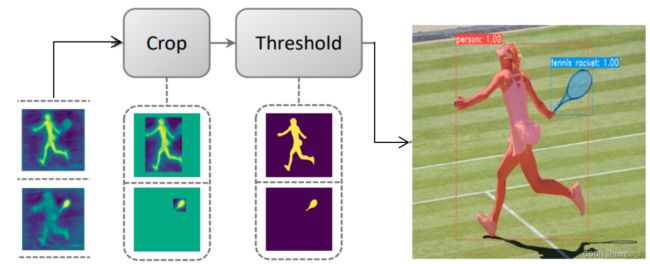
网络每个gridceil都有3个输出信息:cls + box + mask_coef。对前两者进行解析可得到,有效的gridceil预测出了目标的类别 和 目标的box,此时可以很容易获取该gridceil中的目标的mask_coef,维度为32,刚好与Proto输出的channel维度32相一致。- 【gridceil中目标的mask的计算】
1 通过mask_coef 和 Proto的线性叠加求出mask,其中 n 为 第n个检出结果: m a s k n = ∑ i = 0 32 m a s k _ c o e f i ∗ P r o t o i mask_n = \sum_{i=0}^{32}mask\_coef_{i}*Proto_{i} maskn=i=0∑32mask_coefi∗Protoi2 仅保留该gridceil检测出的box内的mask,然后再对mask框内的mask的每个像素进行阈值过滤(工程中阈值设为0.5),即得到该目标的最终的mask。
3.3 mask的损失函数
网络的输出经过 3.2 章节的处理后,得到解析后的mask信息
- 训练时,mask与标签进行计算损失函数。也就是并不会对 Proto 和 mask_coef 直接进行监督;仅对每个box内有效的处理后的mask做损失函数的计算。
- 预测时,mask通过阈值处理为2值图,像素=0为背景,像素=1为目标。不包含类别信息,类别信息由head_cls分支的输出提供。
训练时候的损失函数为
def single_mask_loss(self, gt_mask, pred, proto, xyxy, area): """Mask loss for one image.""" ## gt_mask: mask的标签 ## pred: 预测的mask_coef ## proto:预测的32个原型mask ## xyxy:目标检测框标签,用于选中有效区域的mask ## area:目标检测框标签的面积,计算了box内的mask损失,要除以面积以为了平衡大小目标对最终损失的影响。 pred_mask = (pred @ proto.view(self.nm, -1)).view(-1, *proto.shape[1:]) # (n, 32) @ (32,80,80) -> (n,80,80) loss = F.binary_cross_entropy_with_logits(pred_mask, gt_mask, reduction='none') return (crop_mask(loss, xyxy).mean(dim=(1, 2)) / area).mean()

5 关节点估计
有待补充完善。。。