【链表习题集1】整体和局部反转链表&同频和快慢指针&合并链表
前言: 刷题和面试兼顾还得看你啊-牛客网
近几年互联网受疫情影响,许多互联网都使用牛客网在线笔试招人
很多同学因为不熟悉牛客网的环境和使用,最后在线笔试面试中屡屡受挫
牛客网提供了语言巩固,算法提高等在线OJ题,更有面试真题,大厂内推!
链接附上点击链接注册牛客网
牛客网这么好用,但是下面几个关于牛客网的知识你了解过吗?
- 你知道你OJ过不了,牛客网几种经典的英文报错提示的含义吗?
- 你知道牛客网的OJ分为IO型和接口型吗?
- 你使用过牛客网的调试功能吗?
目录
1.移除链表元素
2.反转链表
方法一:箭头逆置法
方法二:头插newhead法
方法3:不断后插cur法
3.链表的中间结点
另外1:链表判环问题编辑
另外2:求环入口点问题
4.链表中倒数第k个节点
5.合并两个排序的链表
6. 链表内指定区间反转
7.链表中的节点每k个一组翻转
1.移除链表元素
以1->2->6->3->4->5->6->NULL为例,首先要用一个指针遍历找到值为6的结点,然后要移除第一个值为6的结点,就是使得2的指针域指向3,所以要用一个指针记录2这个结点,共两个结点; 一直遍历直到cur==NULL.
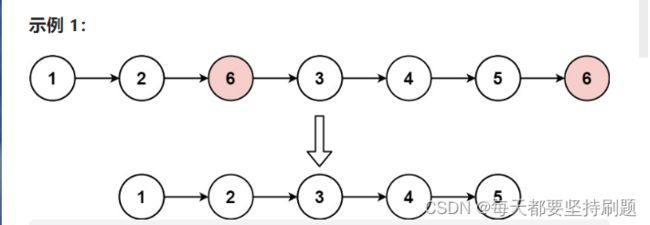
题目要求:题目的要求也很好理解,就是把单链表中所有值为val的全部删除,然后返回新的链表的头指针
整体思路分析:推荐就是从普通情况来开始分析,然后考虑特殊情况,把能想到的所有情况全部考虑清楚后,先写出普通情况的代码,然后对特殊情况考虑,有时特殊情况在一些情况上有所包含,有时特殊情况是要在原来普通情况上加上一个if,有极少数的是需要单独分析。
普通情况分析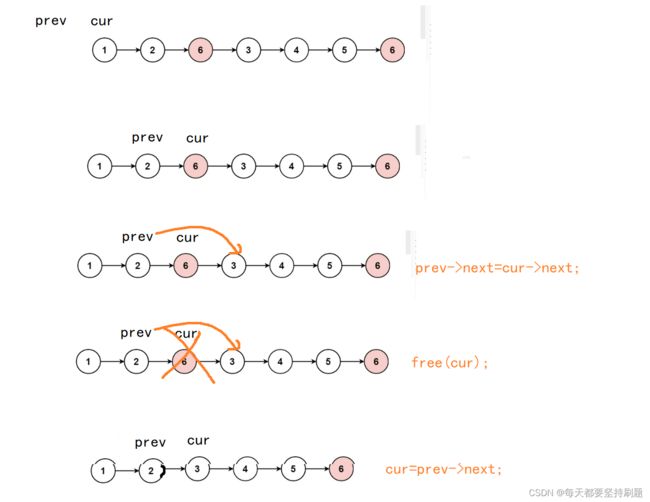 :
:
代码书写:(普通情况)
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* removeElements(struct ListNode* head, int val) {
struct ListNode* prev = NULL;
struct ListNode* cur = head;
while (cur)
{
if (cur->val == val)
{
prev->next = cur->next;
free(cur);
cur = prev->next;
}
else
{
prev = cur;
cur = cur->next;
}
}
return head;
}写到这里,或许很多人都能想到当head为NULL的时候,但是再看一眼我们的代码,这个情况已经在普通情况中解决了(压根就进不了循环),返回NULL,不用额外考虑了。于是你认为一切都妥当后,提交!
普通情况写完提交,我们还可以通过提交时哪些案例不能通过来分析特殊情况

通过这个我们发现就是当第一个结点就是需要我们删除的时候,我们再看一看我们的代码,prev此时为空,prev->next=cur->next这里出现了问题。因为当prev为空的时候是不能prev->next的。
也就是说在while循环里面即使cur->val==val我们还需要对prev是否为空分类讨论:
当prev为空,也就是第一个节点就是所需要删除的结点时:

最终的代码就是这样了:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* removeElements(struct ListNode* head, int val) {
struct ListNode* prev = NULL;
struct ListNode* cur = head;
while (cur)
{
if (cur->val == val)
{
if (prev == NULL)
{
head = cur->next;
free(cur);
cur = head;
}
else
{
prev->next = cur->next;//跳过要删除的那个结点
free(cur);//释放掉用删除的那个结点
cur = prev->next;//让cur重新站到prev前面
}
}
else
{
prev = cur;
cur = cur->next;
}
}//end of while
return head;
}等等,老师好像还和我们讲过如果自己在题目中设置一个哨兵位的头结点可以避免讨论一些特殊情况,让我们试试吧! (其实设置了带哨兵位的头结点就可以避免prev不能为空的时候prev->next,此时prev指向的是GuardHead,而不是空!!!)
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* removeElements(struct ListNode* head, int val) {
struct ListNode* GuardHead=(struct ListNode*)malloc(sizeof(struct ListNode));//malloc出一个头结点
GuardHead->next=head;//将头结点和首元结点连接起来
struct ListNode* prev=GuardHead;
struct ListNode* cur=head;
while(cur)
{
if(cur->val==val)
{
prev->next=cur->next;
free(cur);
cur=prev->next;
}
else
{
prev=cur;
cur=cur->next;
}
}//end of while
head=GuardHead->next;//因为原来head指向的那个结点可能已经被删除,所以这里更新一下指向头结点的指针
free(GuardHead);
return head;
}方法2:本题还可以将非val的结点连接到新的链表,再返回新链表的头。
注意将最后的非val结点的next置空。
2.反转链表
方法一:箭头逆置法
不断地将箭头的方向掰过来..
NULL 1->2->3->4->5->NULL
NULL<-1->2->3->4->5->NULL
NULL<-1<-2->3->4->5->NULL
NULL<-1<-2<-3->4->5->NULL
...

题目的意思也很简答,就是把1->2->3->4->5变成5->4->3->2->1
那么我们可以简单的想成把箭头的指向全部反过来就可以了
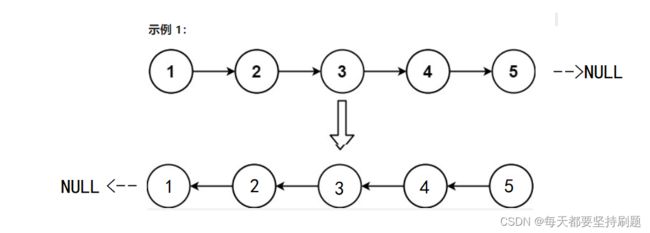
刚刚开始我们的思路或许是使用两个指针,n1和n2,然后把n2指向n1,那么n2原来的指向自然就断了,也就是像画图化的那样:

但是这样就会有一个问题就是在上图的第一个链表中n2指向了n1(NULL),那么n2的下一个(也就是数据域为2的结点)就和n2指向的那个结点断开 了后就找不到值为2的结点了,所以这里我们还需要一个指针n3用于n2指向n1的操作前,及时地保留值为2的结点,方便后续迭代。
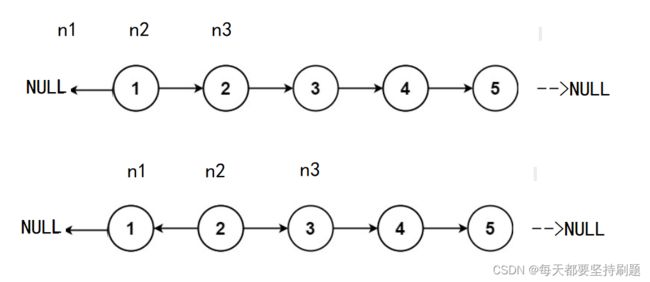
牢牢地抓住开始,迭代和结束,我们不难写出下面的代码:
n2所在的结点就是需要反转指向的结点,而结束标志就是没有需要反转指向的结点,也就是n2==NULL时结束。
代码实现:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* reverseList(struct ListNode* head){
struct ListNode* n1=NULL,*n2=head;
while(n2)
{
struct ListNode* n3=n2->next;
n2->next=n1;
n1=n2;
n2=n3;
}
return n1;
}写到这里,我们发现到现在我们也还没遇到需要特殊考虑的情况,这或许就是意味着使用头结点可能反而会更麻烦:
下面是使用创建一个新的头结点的方法:
struct ListNode* ReverseList(struct ListNode* pHead ) {
// write code here
struct ListNode* GuardHead=(struct ListNode*)malloc(sizeof(struct ListNode));
GuardHead->next=pHead;//
struct ListNode* prev=GuardHead;
struct ListNode* cur=pHead;//null
while(cur)
{
struct ListNode* next=cur->next;
cur->next=prev;
prev=cur;
cur=next;
}
free(GuardHead);
if(pHead!=NULL)
{
pHead->next=NULL;
return prev;
}
else
{
return NULL;
}
}整体上差不多,反而是最后释放GuardHead的时候,还要对pHead是否为空进行讨论。(因为我们刚开始的时候,并没有使得pHead为空,返回的时候,当遇到链表为空的情况,返回的prev此时为头结点,但是头结点已经被释放了,所以如果还是返回prev就会出问题)
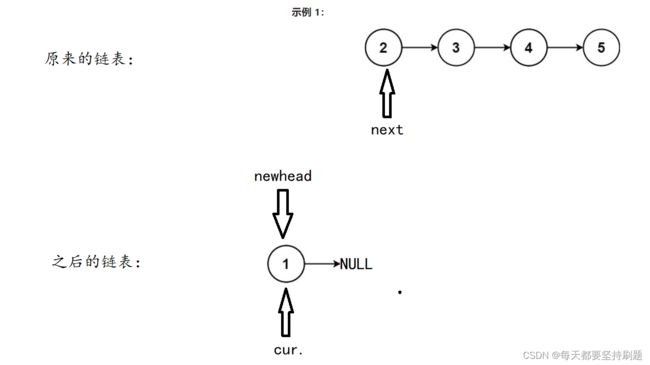
方法二:头插newhead法
在newhead(头指针)和NULL之间不断取出结点1,2,3,4,5进行头插
newhead->NULL;
newhead->1->NULL;
newhead->1->2->NULL;
......
开始:考虑只定义两个指针,第一个指针cur,指向原单链表的首元结点;再定义一个指针,作为记录新单链表的首元结点;
迭代:然后不断将cur头插到新单链表中...,等等,原单链表的下一个结点还没有保存,cur就改变了指向,后面cur->next肯定就不是原单链表中原来cur的下一个结点了呀,所以还要一个临时的指针临时的保存原cur的下一个结点...
结束:因为cur所指向的原单链表的结点是需要头插到新单链表的,所以当cur为NULL的时候,就是循环迭代结束。
步骤1:

步骤2:
步骤....:
代码实现:
struct ListNode* reverseList(struct ListNode* head){
struct ListNode* newhead=NULL;
struct ListNode* cur=head;
while(cur)
{
struct ListNode* next=cur->next;
cur->next=newhead;
newhead=cur;
cur=next;
}
return newhead;
}方法3:不断后插cur法
方法3和方法2类似,好像都是头插,但是方法3是更广义的头插,就是把GuardHead头结点当成头指针,而且在GuardHead->1-2->3->4->5->NULL
GuardHead->2->1->3->4->5->NULL
GuardHead->3->2->1->4->5->NULL
GuardHead->4->3->2->1->5->NULL
...
备注:该解法更精彩的用处在题单6.7
struct ListNode* ReverseList(struct ListNode* pHead ) {
// write code here
struct ListNode* GuardHead=(struct ListNode*)malloc(sizeof(struct ListNode));
GuardHead->next=pHead;
struct ListNode* cur=GuardHead;
struct ListNode* tail=pHead;
int n=0;
while(tail)
{
tail=tail->next;
n++;
}
struct ListNode* next=pHead;
for(int i=0;inext;
next->next=nnext->next;
nnext->next=cur->next;
cur->next=nnext;
}
pHead=GuardHead->next;
free(GuardHead);
GuardHead=NULL;
return pHead;
} 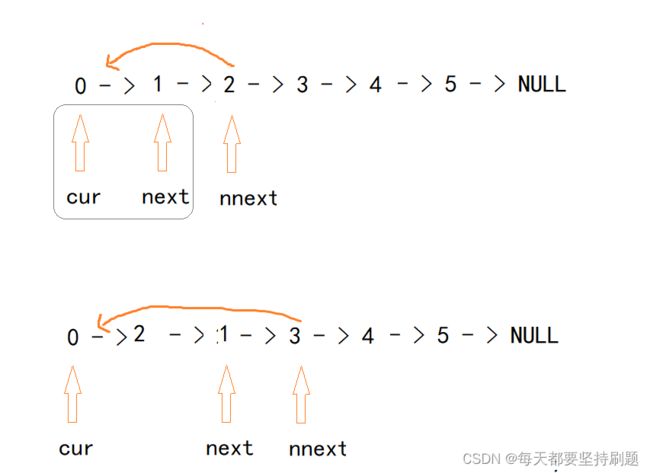
特点:cur和next指针指向的结点始终是不变的,由于cur和next之间不断插入元素,只是nnext指针指向的结点在每插入后都要重新更新为next的下一个结点的位置。
3.链表的中间结点
定义两个指针,一个快指针,一次走两步;一个慢指针,一次走一步。由于天然的2倍关系,快指针走到尾的时候,慢指针就自然到了中间结点的位置。

开始:定义两个指针:一个快指针,一个慢指针,都指向首元结点
迭代:快指针一次跨越两个结点,慢指针一次跨越一个结点
结束:快指针指向空或者快指针指向的结点的下一个结点为空
下面以奇数个结点为例:
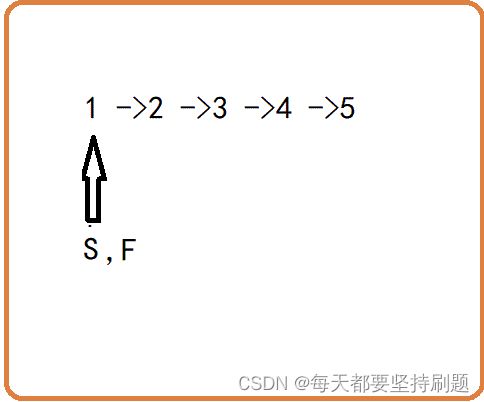


通过这里我们可以看到当fast->next==NULL时,循环迭代结束,slow指针指向的那个结点就是中间结点。
但是当单链表中有偶数个结点时,两个结点都是中间结点,但是题目规定说返回第2个中间结点。
所以当我们通过画图演示后发现,偶数个结点时,当我们让slow处于第1个中间结点的位置的时候,fast此时满足fast==NULL;因此便有了结束循环的判断条件:
只要fast->next==NULL||fast==NULL就可以终止,因为循环判断里写的是继续的条件,只需要对上面这个做命题的否定就行了!
struct ListNode* middleNode(struct ListNode* head){
struct ListNode* fast=head;
struct ListNode* slow=head;
while(fast->next!=NULL&&fast!=NULL)
{
fast=fast->next->next;
slow=slow->next;
}
return slow;
}备注:while里面的是fast=fast->next->next,前提就是fast!=NULL&&fast->next!=NULL;
另外1:链表判环问题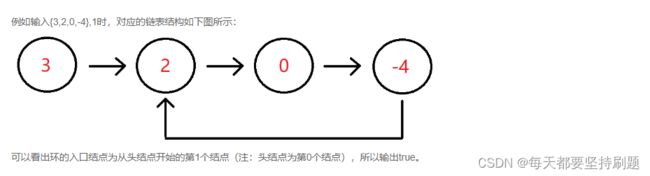
判断链表中是否有环
通过定义slow和fast指针,slow每走一步,fast走两步,若是有环,则一定会在环的某个结点处相遇(slow == fast)判断链表中是否有环
bool hasCycle(struct ListNode* head ) {
// write code here
struct ListNode* fast=head;
struct ListNode* slow=head;
while(fast&&fast->next)
{
fast=fast->next->next;
slow=slow->next;
if(fast==slow) return true;
}
return false;
}另外2:求环入口点问题


struct ListNode* EntryNodeOfLoop(struct ListNode* pHead ) {
// write code here
struct ListNode* fast=pHead;
struct ListNode* slow=pHead;
while(fast&&fast->next)
{
fast=fast->next->next;
slow=slow->next;
if(fast==slow) break;
}
if(fast==NULL||fast->next==NULL) return NULL;
if(fast==slow)
{
fast=pHead;
while(fast!=slow)
{
fast=fast->next;
slow=slow->next;
}
//下一次相遇就是环的入口点,直接返回
return fast;
}
return pHead;
}备注一个牛客网的错误:
我就是说有一个while循环,然后循环里有两种跳出情况,然后跳出后,我用来两个if都合理判断了,就是说没有其他情况,牛客网就是要我再main函数的末尾加上一个符合函数原型的返回值,害的我想了半天.
错误信息:
4.链表中倒数第k个节点
定义一个结点让他先走到第k个结点的位置,然后再定义一个结点,让它从头开始,然后两个都一次走一步,当前面那个指针走到尾的时候,后面那个指针自然就走到倒数第k个结点的位置。(注意K的两个边界的判断)

k=2,返回指向倒数第2个结点的指针,
k=n,返回指向倒数第n个结点的指针。
题目要求肯定不是要你遍历一遍求出单链表总共有多少个结点sum,然后再遍历sum-k次找到倒数第k个结点。
那我们的做法就是定义两个指针,让其中一个指针node1先走k步,然后两个指针(node1和node2)再同时走,直到node1==NULL,那么node2就是指向倒数第k个结点的指针。
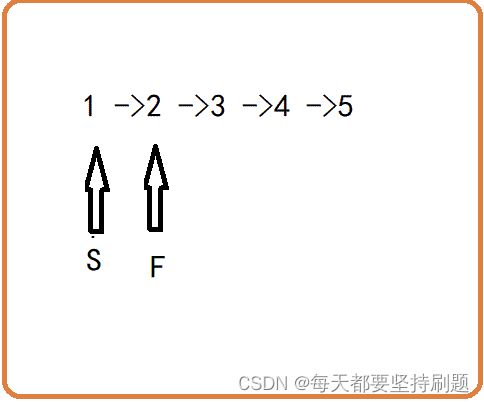
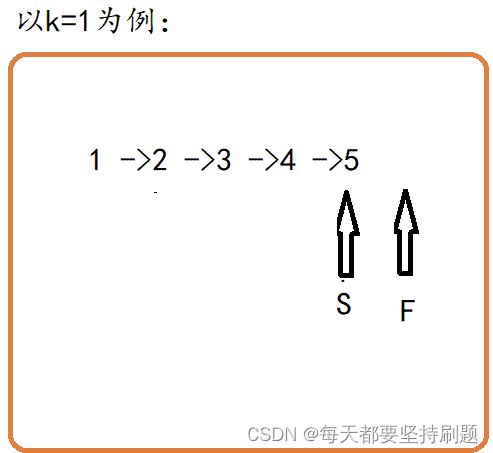
或者让其中一个指针node1先走k-1步,然后两个指针(node1和node2)再同时走,直到node1-》next==NULL,那么node2就是指向倒数第k个结点的指针。


struct ListNode* FindKthToTail(struct ListNode* pHead, int k ) {
//如果k<=0或链表为空则返回空指针
if(pHead ==NULL||k<=0) return NULL;
//fast边走边判断k是否超过链表长度n
struct ListNode* fast=pHead;
for(int i=1;i<=k-1&&fast!=NULL;i++)
{
fast=fast->next;
}
//跳出循环的两种可能:
//情况1:k符合k<=n,fast!=NULL,就从inext!=NULL)
{
fast=fast->next;
slow=slow->next;
}
return slow;
} 5.合并两个排序的链表
如果有一个链表为空,则返回另一个链表的头
否则就老老实实比大小,小的取下来接到新链表的尾部
直到其中某一个链表先为空,最后把另一个链表的剩余部分直接接到新链表的尾部。
备注:val值相同的两个结点都要合并到新的链表中
小小题外话:
数组合并:因为两个数组物理上是不连续的,但是要合并数组的特性就是需要物理上是连续的,所以要合并两个有序的数组,就得重新开辟一个新的空间。
链表合并:尽管链表在物理上也是不连续的,但是链表特性上本来就是不需要物理上是连续的,所以只用把结点连接起来即可,并不需要开辟一个新的空间。
整体思路:两个链表中取小然后尾插到新链表的尾
开始:定义新链表的两个指针,第一个是新链表的头指针为newhead,第二个是新链表的尾指针为tail(为了防止遍历找尾),另外为了方便迭代统一化,先提前将l1和l2中一个val值小的结点插入到新链表中。
struct ListNode* mergeTwoLists(struct ListNode* l1, struct ListNode* l2){
if(l1==NULL) return l2;
if(l2==NULL) return l1;
struct ListNode* s1=l1->next;
struct ListNode* s2=l2->next;
struct ListNode* newhead=NULL;
struct ListNode* tail=NULL;
if(l1->val>=l2->val)
{
newhead=tail=l2;
l2 = l2->next;
}
else if(l1->valval)
{
newhead=tail=l1;
l1 = l1->next;
}
while(l1&&l2)
{
if(l1->val>=l2->val)
{
tail->next=l2;
tail=tail->next;
l2 = l2->next;
}
else if(l1->valval)
{
tail->next=l1;
tail=tail->next;
l1 = l1->next;
}
}
if(l1==NULL)
{
tail->next=l2;
}
else if(l2==NULL)
{
tail->next=l1;
}
return newhead;
} 6.链表内指定区间反转
6. 链表内指定区间反转
先定义一个指针走到指定反转的区间的前一个结点的位置,然后指向题单2-方法3的方法。


题目的意思很简单就是在题目给定的m-n区间的结点进行反转。(这就是题单2-整体反转,变式来的题单6-局部反转)
下面以1->2->3->4->5->NULL为例
注:0号结点是我们自己额外创建的头结点,至于在这题创建头结点的优点,稍后我会讲解。

我们想要反转,那我们就先想一想逻辑(脑子里先不要有指针),2->3->4我们要变成4->3->2,我们首先想到的肯定是把将3插到2前面:3->2->4,然后是把4插到3前面:4->3->2,也就是将要反转的补
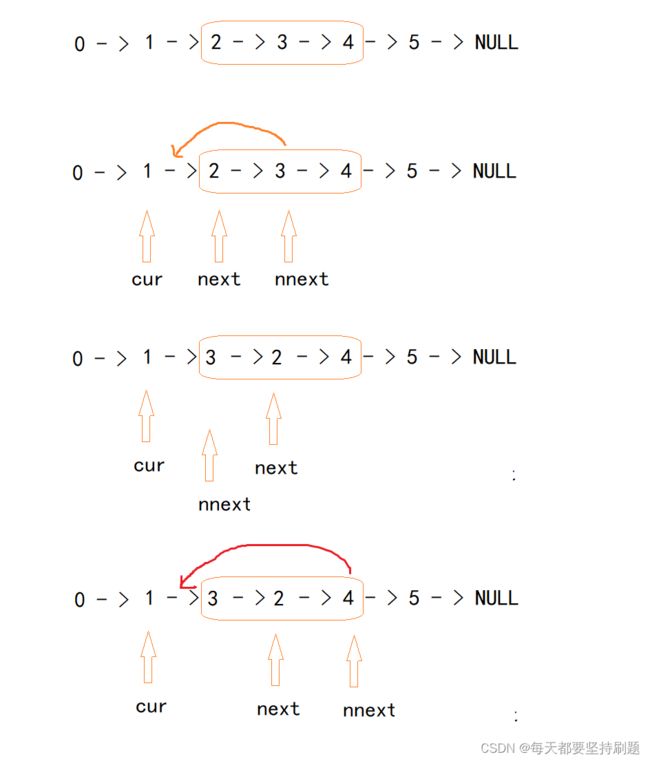
struct ListNode* reverseBetween(struct ListNode* head, int m, int n ) {
// write code here
struct ListNode* GuardHead=(struct ListNode*)malloc(sizeof(struct ListNode));
GuardHead->next=head;
struct ListNode* cur=GuardHead;
for(int i=0;inext;
}
struct ListNode* next=cur->next;
for(int i=0;inext;
next->next=nnext->next;
nnext->next=cur->next;
cur->next=nnext;
}
head=GuardHead->next;
free(GuardHead);
GuardHead=NULL;
return head;
} 7.链表中的节点每k个一组翻转
7.链表中的节点每k个一组翻转
先遍历一遍找到共有多少个结点,记录为n,然后用count记录有多少个区间需要反转。
然后外部的for循环是指有多少个区间要反转,
内部的第1个循环是反转的过程,执行题单2-方法3,进行反转
内部的第2个循环是重新定位下一个cur的位置,然后进行迭代,
特别的,我自己加了一个头结点,对cur刚刚开始在NULL的尴尬位置(没有头结点就cur必须为NULL,但是为空就没办法cur->next),所以我觉得头结点是必须的,还有头结点可以使得返回的时候返回的直接是GuardHead->next,有一个记录新的头指针的功能。
struct ListNode* reverseKGroup(struct ListNode* head, int k ) {
// write code here
if(head==NULL)
{
return NULL;
}
struct ListNode* GuardHead=(struct ListNode*)malloc(sizeof(struct ListNode));
GuardHead->next=head;
struct ListNode* cur=GuardHead;
struct ListNode* next=head;
struct ListNode* tail=head;
int n=0;
while(tail)
{
n++;
tail=tail->next;
}
int count=n/k;
for(int i=0;inext;
next->next=nnext->next;
nnext->next=cur->next;
cur->next=nnext;
}
for(int j=0;jnext;
}
next=cur->next;
}
head=GuardHead->next;
free(GuardHead);
GuardHead=NULL;
return head;
}