YOLOv5-QAT量化部署
目录
-
- 前言
- 一、QAT量化浅析
- 二、YOLOv5模型训练
-
- 1. 项目的克隆和必要的环境依赖
-
- 1.1 项目克隆
- 1.2 项目代码结构整体介绍
- 1.3 环境安装
- 2. 数据集和预训练权重的准备
-
- 2.1 数据集
- 2.2 预训练权重准备
- 3. 训练模型
-
- 3.1 修改数据配置文件
- 3.2 修改模型配置文件
- 3.3 训练模型
- 3.4 mAP测试
- 三、YOLOv5-QAT准备工作
-
- 1. 项目克隆
- 2. 安装依赖
- 3. 数据集和权重准备
- 4. 代码修改
- 四、YOLOv5-QAT微调导出-方案1
-
- 1. QAT微调
- 2. QAT模型导出
- 3. QAT模型转换
- 五、YOLOv5-QAT微调导出-方案2
-
- 1. QAT微调
- 2. QAT模型导出
- 3. QAT模型转换
- 六、YOLOv5-QAT部署
-
- 1. 源码下载
- 2. 环境配置
-
- 2.1 配置CMakeLists.txt
- 2.2 配置Makefile
- 3. INT8模型生成
- 4. QAT模型mAP测试
- 5. 补充-INT8模型生成
- 七、讨论
-
- 1. 基本概念
- 2. 不同精度模型对比
- 3. QAT方案对比
- 4. PTQ vs. QAT
- 5. INT8模型生成方式对比
- 结语
- 下载链接
- 参考
前言
学习 cuDLA-samples 项目中的 YOLOv5-QAT 量化,本文主要是学习项目中的 YOLOv5 QAT 量化的方法,其他部分如 DLA 博主并未关注,部署使用的 repo 依旧是 tensorRT_Pro,博主在这里简单的过一遍流程,不涉及任何的原理性分析。
博主为初学者,欢迎交流讨论,若有问题欢迎各位看官批评指正!!!
一、QAT量化浅析
在正式开始之前我们先来回顾下关于 QAT 量化的一些知识,具体可参考:TensorRT量化第四课:PTQ与QAT
TensorRT 有两种量化模式,分别是隐式(implicitly)量化和显式(explicitly)量化。前者在 TRT7 版本之前用得比较多,而后者在 TRT8 版本后才完全支持,具体就是可以加载带有 QDQ 信息的模型然后生成对应量化版本的 engine。
这篇文章主要分享显式量化即 QAT 量化,关于隐式量化即 PTQ 量化可以查看上篇文章:YOLOv5-PTQ量化部署。
QAT(Quantization Aware Training)即训练中量化也叫显式量化。它是 tensorRT8 的一个新特性,这个特性其实是指 tensorRT 有直接加载 QAT 模型的能力。而 QAT 模型在这里是指包含 QDQ 操作的量化模型,而 QDQ 操作就是指量化和反量化操作。
实际上 QAT 过程和 tensorRT 没有太大关系,tensorRT 只是一个推理框架,实际的训练中量化即 QAT 操作一般都是在训练框架中去做的,比如我们熟悉的 Pytorch。(当然也不排除之后一些推理框架也会有训练功能,因此同样可以在推理框架中做)
tensorRT8 可以显式地加载包含有 QAT 量化信息的 ONNX 模型,实现一系列优化后,可以生成 INT8 的 engine。
QAT 量化需要插入 QAT 算子且需要训练进行微调,大概流程如下:
- 准备一个预训练模型
- 在模型中添加 QAT 算子
- 微调带有 QAT 算子的模型
- 将微调后模型的量化参数即 q-params 存储下来
- 量化模型执行推理

带有 QAT 量化信息的模型如下图所示:

从上图中我们可以看到带有 QAT 量化信息的模型中有 QuantizeLinear 和 DequantizeLinear 模块,也就是对应的 QDQ 模块,它包含了该层和该激活值的量化 scale 和 zero-point。什么是 QDQ 呢?QDQ 其实就是 Q(量化)和 DQ(反量化)两个 op,在网络中通常作为模拟量化的 op,如下图所示:
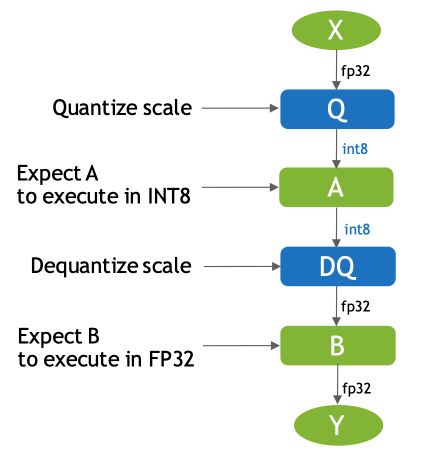
QDQ 模块会参与训练,负责将输入的 FP32 张量量化为 INT8,随后再进行反量化将 INT8 的张量再变为 FP32。值得注意的是,实际网络中训练使用的精度还是 FP32,只不过这个量化算子在训练中可以学习到量化和反量化的尺度信息,这样训练的时候就可以让模型权重和量化参数更好地适应量化过程,量化后地精度也相对更高一些。
QDQ 模块的用途主要体现在两方面:
- 第一个是可以存储量化信息,比如 scale 和 zero_point,这些信息可以放在 Q 和 DQ 操作中
- 第二个是可以当作是显示指定哪一层是量化层,我们可以默认认为包在 QDQ 操作中间的 op 都是 INT8 类型的 op,也就是我们需要量化的 op
因此对比显式量化(即 QAT 量化),tensorRT 的隐式量化(即 PTQ 量化)就没有那么直接,在 tensorRT-8 版本之前我们一般都是借助 tensorRT 的内部量化算法去量化(闭源),在构建 engine 的时候传入图像进行校准,执行的是训练后量化(PTQ)的过程。
而有了 QDQ 信息,tensorRT 在解析模型的时候会根据 QDQ 的位置找到可量化的 op,然后与 QDQ 融合(吸收尺度信息 scale 到 op 中),融合后的算子就是实打实的 INT8 算子,经过一系列的融合优化后,最终生成量化版的 engine。
OK!关于 QAT 量化我们就简单聊下,让我们开始具体的实现吧!!!
二、YOLOv5模型训练
首先我们需要训练一个 YOLOv5 模型,当然拿官方的预训练权重也行,博主这边为了完整性还是整体走一遍流程,熟悉 YOLOv5 模型训练的看官可以跳过直接到量化部分。
1. 项目的克隆和必要的环境依赖
1.1 项目克隆
yolov5 的代码是开源的可直接从 github 官网上下载,源码下载地址是 https://github.com/ultralytics/yolov5/tree/master,由于 yolov5 版本较多,本次采用 yolov5-v7.0 分支进行模型的训练和量化部署工作。
Linux 下代码克隆指令如下:
git clone -b v7.0 https://github.com/ultralytics/yolov5.git
也可以手动点击下载,首先点击左上角切换成 v7.0 分支,如下图所示:

然后点击右上角的 Code 按键将代码下载下来,如下图所示:
至此整个项目就已经准备好了,也可以点击 here【pwd:yolo】下载博主准备好的代码。
1.2 项目代码结构整体介绍
将下载后的 yolov5-7.0 的代码解压,其代码目录如下图:
现在来对代码的整体目录做一个介绍
- |-classify:用于存放使用 yolov5 做分类的一些文件
- |-data:主要是存放一些超参数的配置文件(如yaml文件、sh脚本文件),用来配置训练集和验证集还要测试集的路径的;还要一些官方提供的测试图片,后续我们要训练自己的数据集需要修改其中的 yaml 文件。
- |-models:这里面主要是一些网络构建的配置文件和模块文件,其中包含了 n、s、m、l、x 五个不同的版本,它们的检测速度从快到慢,但精度从低到高。如果训练自己的数据集,需要修改对应的 yaml 文件
- |-segment:用于存放使用 yolov5 做分割的一些文件
- |-utils:主要存放工具类函数,比如 loss 损失函数,plot 绘图函数,metrics 函数等等
- detect.py:该文件主要功能是利用训练好的模型进行推理检测,可以进行图像、视频和摄像头的检测
- export.py:该文件主要功能是将训练好的 pytorch 模型导出为其它格式的模型,如 ONNX、TensorRT、OpenVINO 等等
- train.py:该文件主要功能是利用 yolov5 训练自己的数据集
- val.py:该文件主要功能是测试训练好的 yolov5 模型的 mAP
- requirements.txt:这是一个文本文件,包含使用 yolov5 项目所依赖的第三方库的版本
以上就是 yolov5 项目代码的整体介绍,我们训练和量化部署基本使用上面的代码就够了
1.3 环境安装
关于深度学习的环境安装可参考炮哥的利用Anaconda安装pytorch和paddle深度学习环境+pycharm安装—免额外安装CUDA和cudnn(适合小白的保姆级教学),这里不再赘述。
2. 数据集和预训练权重的准备
2.1 数据集
这里训练采用的数据集是 PASCAL VOC 数据集,但博主并没有使用完整的 VOC 数据集,而是选用了部分数据,具体分布如下:
- 训练集:(VOC2007train + VOC2007val) x 80% = 4013
- 验证集:(VOC2007train + VOC2007val) x 20% = 998
- 测试集:0
这里给出下载链接 Baidu Drive【pwd:yolo】下载解压后整个数据集文件夹内容如下图所示:
其中 images 存放训练集和验证集的图片文件,labels 存放着对应的 YOLO 格式的 .txt 文件。
完整的 VOC 数据集的相关介绍和下载可参考:目标检测:PASCAL VOC 数据集简介
由于大家可能从其它地方拿到的是 XML 格式的标签文件,这里提供一个 XML2YOLO 转换的代码,如下所示:(from chatGPT)
import os
import cv2
import xml.etree.ElementTree as ET
import shutil
from multiprocessing import Pool, cpu_count
from tqdm import tqdm
import numpy as np
from functools import partial
def process_xml(xml_filename, img_path, xml_path, img_save_path, label_save_path, class_dict, ratio):
# 解析 xml 文件
xml_file_path = os.path.join(xml_path, xml_filename)
tree = ET.parse(xml_file_path)
root = tree.getroot()
# 获取图像的宽度和高度
img_filename = os.path.splitext(xml_filename)[0] + ".jpg"
img = cv2.imread(os.path.join(img_path, img_filename))
height, width = img.shape[:2]
# 随机决定当前图像和标签是属于训练集还是验证集
subset = "train" if np.random.random() < ratio else "val"
# 打开对应的标签文件进行写入
label_file = os.path.join(label_save_path, subset, os.path.splitext(xml_filename)[0] + ".txt")
with open(label_file, "w") as file:
for obj in root.iter('object'):
# 获取类别名并转换为类别ID
class_name = obj.find('name').text
class_id = class_dict[class_name]
# 获取并处理边界框的坐标
xmlbox = obj.find('bndbox')
x1 = float(xmlbox.find('xmin').text)
y1 = float(xmlbox.find('ymin').text)
x2 = float(xmlbox.find('xmax').text)
y2 = float(xmlbox.find('ymax').text)
# 计算中心点坐标和宽高,并归一化
x_center = (x1 + x2) / 2 / width
y_center = (y1 + y2) / 2 / height
w = (x2 - x1) / width
h = (y2 - y1) / height
# 写入文件
file.write(f"{class_id} {x_center} {y_center} {w} {h}\n")
# 将图像文件复制到对应的训练集或验证集目录
shutil.copy(os.path.join(img_path, img_filename), os.path.join(img_save_path, subset, img_filename))
def check_and_create_dir(path):
# 检查并创建 train 和 val 目录
for subset in ['train', 'val']:
if not os.path.exists(os.path.join(path, subset)):
os.makedirs(os.path.join(path, subset))
if __name__ == "__main__":
# 1. 定义路径和类别字典,不要使用中文路径
img_path = "D:\\Data\\PASCAL_VOC\\VOCdevkit\\VOC2007\\JPEGImages"
xml_path = "D:\\Data\\PASCAL_VOC\\VOCdevkit\\VOC2007\\Annotations"
img_save_path = "D:\\Data\\PASCAL_VOC\\dataset\\images"
label_save_path = "D:\\Data\\PASCAL_VOC\\dataset\\labels"
class_dict = {
"aeroplane": 0,
"bicycle": 1,
"bird": 2,
"boat": 3,
"bottle": 4,
"bus": 5,
"car": 6,
"cat": 7,
"chair": 8,
"cow": 9,
"diningtable": 10,
"dog": 11,
"horse": 12,
"motorbike": 13,
"person": 14,
"pottedplant": 15,
"sheep": 16,
"sofa": 17,
"train": 18,
"tvmonitor": 19
}
train_val_ratio = 0.8 # 2. 定义训练集和验证集的比例
# 检查并创建必要的目录
check_and_create_dir(img_save_path)
check_and_create_dir(label_save_path)
# 获取 xml 文件列表
xml_filenames = os.listdir(xml_path)
# 创建进程池并执行
with Pool(cpu_count()) as p:
list(tqdm(p.imap(partial(process_xml, img_path=img_path, xml_path=xml_path, img_save_path=img_save_path, label_save_path=label_save_path,
class_dict=class_dict, ratio=train_val_ratio), xml_filenames), total=len(xml_filenames)))
上述代码的功能是将 PASCAL VOC 格式的数据集(包括 JPEG 图像和 XML 格式的标签文件)转换为 YOLO 需要的 .txt 标签格式,同时会将转换后的数据集按照比例随机划分为训练集和验证集。
你需要修改以下几项:
- img_path:需要转换的图像文件路径
- xml_path:需要转换的 xml 标签文件路径
- img_save_path:转换后保存的图像路径
- label_save_path:转换后保存的 txt 标签路径
- class_dict:数据集类别字典
- train_val_ratio:训练集和验证集划分的比例
- 注意:以上路径都不要包含中文,Windows 下路径记得使用
\\或者/防止转义
XML 标签文件中目标框保存的格式是 [xmin, ymin, xmax, ymax] 四个变量,分别代表着未经归一化的左上角和右下角坐标。
YOLO 标签中目标框保存的格式是每一行代表一个目标框信息,每一行共包含 [label_id, x_center, y_center, w, h] 五个变量,分别代表着标签 ID,经过归一化后的中心点坐标和目标框宽高。
关于代码的分析可以参考:tensorRT模型性能测试
至此,数据集的准备工作完毕。
2.2 预训练权重准备
yolov5-7.0 预训练权重可以通过 here 下载,博主也提供了下载好的预训练权重 Baidu Drive【pwd:yolo】,注意这是 yolov5-v7.0 版本的预训练权重,如果你使用的是其它版本,记得替换。本次训练 PASCAL VOC 数据集使用的预训练权重为 yolov5s.pt。

3. 训练模型
将准备好的数据集文件夹即 VOC 复制到 yolov5 项目环境中,将准备好的预训练权重 yolov5s.pt 复制到 yolov5 项目环境中,完整的项目结构如下图所示。训练目标检测模型主要修改 data 文件夹下的数据配置文件 data/VOC.yaml 以及 models 文件夹下的模型配置文件 models/yolov5s.yaml

3.1 修改数据配置文件
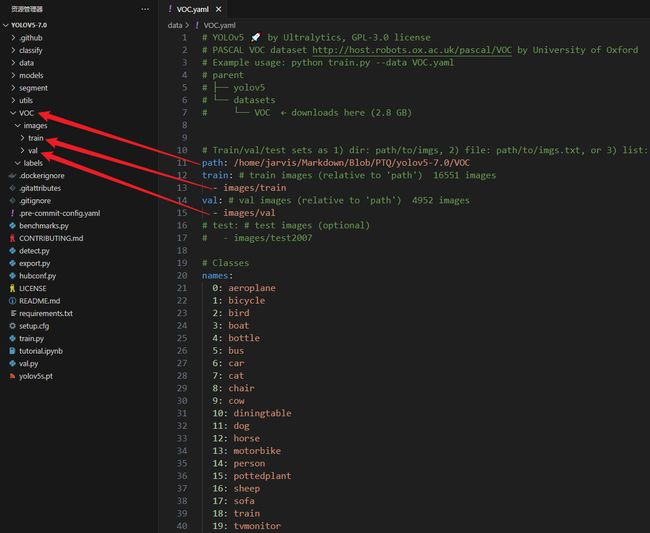
修改 data 目录下相应的 yaml 文件,找到目录下的 VOC.yaml 文件,主要修改如下:
- 1. 修改第 11 行数据集路径
- 2. 修改第 12 行训练集
- 3. 修改第 17 行验证集
- 4. 注释第 19 行测试集,未使用到
- 5. 第 23 行类别数不用修改,如果是其它自定义数据记得修改
- 6. 注释第 47 行自动下载
3.2 修改模型配置文件
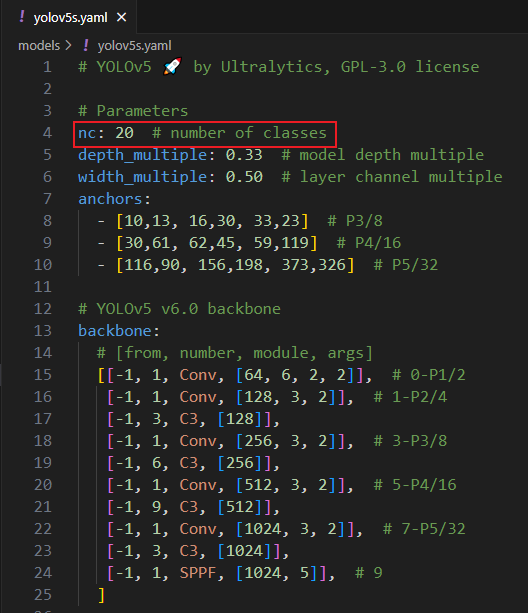
由于该项目使用的是 yolov5s.pt 这个预训练权重,所以需要修改 models/yolov5s.yaml 这个文件(由于不同的预训练权重对应不同的网络结构,所以用错预训练权重会报错)。主要修改 yolov5s.yaml 文件的第 4 行,即需要识别的类别数,由于 PASCAL VOC 数据集识别 20 个类别,故修改为 20 即可,如下所示:
3.3 训练模型
在终端执行如下指令即可开始训练:
python train.py --weights=./yolov5s.pt --cfg=./models/yolov5s.yaml --data=./data/VOC.yaml --epochs=100 --batch-size=16
博主训练的模型为 p5 models 且使用的是单个 GPU 进行训练,显卡为 RTX3060,操作系统为 Ubuntu20.04,pytorch 版本为 1.12.0,训练时长大概 1 小时左右。训练的参数简要解释如下:
- –weights 预训练权重路径
- –cfg 模型配置文件路径
- –data 数据配置文件路径
- –epochs 训练轮数
- –batch_size 每次输入到网络的图片数
还要其它参数博主并未设置,如 –img 图像尺寸 等,大家一定要根据自己的实际情况(如显卡算力)指定不同的参数,如果你之前训练过模型,那我相信这对你来说应该是小 case
训练完成后的模型权重保存在 runs/train/exp/weights 文件夹下,我们使用 best.pt 进行后续模型量化部署即可,这里提供博主训练好的权重文件下载链接 Baidu Drive【pwd:yolo】
3.4 mAP测试
由于后续我们要对模型进行 QAT 量化,需要一些指标来衡量模型的性能,mAP 是一个重要的衡量指标。我们需要对比量化前后模型的 mAP,首先来看量化前原始 pytorch 模型的 mAP,测试的数据集直接选用验证集的 998 张图片。
我们将置信度阈值设置为 0.001,NMS 阈值设置为 0.65,方便与后续 QAT 量化模型对比。
mAP 测试的指令如下:
python val.py --weights runs/train/exp/weights/best.pt --data data/VOC.yaml --img 640 --conf-thres 0.001 --iou-thres 0.65
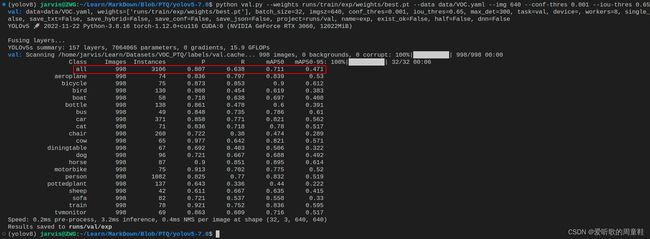
测试完成后的结果会保存在 runs/val/exp 文件夹下,这里总结下原始 pytorch 模型的性能
| Model | Size | mAPval 0.5:0.95 |
mAPval 0.5 |
Params (M) |
FLOPs (G) |
|---|---|---|---|---|---|
| YOLOv5s | 640 | 0.471 | 0.711 | 7.2 | 16.5 |
三、YOLOv5-QAT准备工作
参考自:https://github.com/NVIDIA-AI-IOT/cuDLA-samples/tree/main/export/README.md
描述:在正式开始 QAT 量化之前我们需要做一些准备工作,比如安装一些必要的依赖库,准备好用于量化训练的权重和数据集,以及简单修改部分代码等等。请大家务必熟读对应的 README 文档,将博主实现的流程对照着 README 文档来看可能更方便理解。
1. 项目克隆
克隆 yolov5-v7.0 项目
git clone -b v7.0 https://github.com/ultralytics/yolov5
克隆 cuDLA-samples 项目
git clone --recursive https://github.com/NVIDIA-AI-IOT/cuDLA-samples.git
也可以点击 here【pwd:yolo】 下载博主准备好的代码(注意该代码下载于 2023/10/6 日,若有改动请参考最新)
将 cuDLA-samples 项目中的 yolov5-qat 文件夹和 qdq_translator 文件夹复制到 yolov5 项目中,指令如下:
cp -r cuDLA-samples/export/yolov5-qat/* yolov5-7.0/
cp -r cuDLA-samples/export/qdq_translator yolov5-7.0/
完整的目录如下:
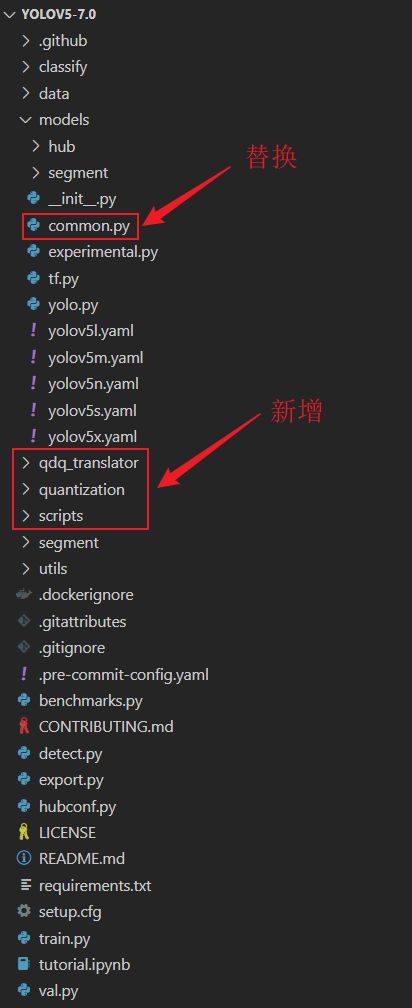
2. 安装依赖
QAT 量化需要使用到 NVIDIA 为 TensorRT 提供的 pytorch-quantization 工具,安装指令如下:
pip install pytorch-quantization --extra-index-url https://pypi.ngc.nvidia.com
此外还需要一些用于 QDQ 节点转换的第三方库,安装指令如下:
cd cuDLA-samples/export/qdq_translator
pip install -r requirements.txt
3. 数据集和权重准备
我们需要准备一个数据集用于 QAT 模型的微调,数据集直接拿之前用于训练的数据集即可,此外我们还需要提供两个 txt 文档,一个是 train2017.txt 里面包含所有训练集图片的完整路径,一个是 val2017.txt 里面包含所有验证集图片的完整路径。
txt 文档生成代码如下:
import os
save_dir = "/home/jarvis/Learn/Datasets/VOC_QAT"
train_dir = "/home/jarvis/Learn/Datasets/VOC_QAT/images/train"
train_txt_path = os.path.join(save_dir, "train2017.txt")
with open(train_txt_path, "w") as f:
for filename in os.listdir(train_dir):
if filename.endswith(".jpg") or filename.endswith(".png"): # 添加你的图像文件扩展名
file_path = os.path.join(train_dir, filename)
f.write(file_path + "\n")
print(f"train2017.txt has been created at {train_txt_path}")
val_dir = "/home/jarvis/Learn/Datasets/VOC_QAT/images/val"
val_txt_path = os.path.join(save_dir, "val2017.txt")
with open(val_txt_path, "w") as f:
for filename in os.listdir(val_dir):
if filename.endswith(".jpg") or filename.endswith(".png"): # 添加你的图像文件扩展名
file_path = os.path.join(val_dir, filename)
f.write(file_path + "\n")
print(f"val2017.txt has been created at {val_txt_path}")
你需要修改以下几项:
- save_dir:txt 文档保存的路径,应该与 images 和 labels 文件夹在同一级目录
- train_dir:训练集图片路径
- val_dir:验证集图片路径
执行完成后会在对应目录下生成 train2017.txt 和 val2017.txt 两个文件。
数据集完整的目录结构如下:
.
├── images
│ ├── train
│ └── val
├── labels
│ ├── train
│ └── val
├── train2017.txt
└── val2017.txt
6 directories, 2 files
除数据集外我们还需要准备一个权重文件用于 QAT 量化训练,权重直接选取之前 yolov5 训练 VOC 数据集的 best.pt 文件即可。可以点击 here【pwd:yolo】下载博主准备好的数据集和权重。
我们可以将准备好的数据集和权重都放在 yolov5 项目下,方便后续操作。
4. 代码修改
由于 QAT 量化过程需要训练,因此我们还需要修改下 yolov5 目录下的配置文件方便后续训练。
主要修改数据配置文件 data/VOC.yaml 以及模型配置文件 models/yolov5s.yaml,我们在之前模型训练中有详细提到过,这边不再赘述。
除此之外还需要修改下 scripts/qat.py 中的数据配置文件指定,具体修改如下:
# scripts/qat.py 121 行
# return val.run(
# check_dataset("data/coco.yaml"),
# save_dir=Path(save_dir),
# dataloader=dataloader, conf_thres=conf_thres,iou_thres=iou_thres,model=model,
# plots=False,save_json=using_cocotools)[0][3]
return val.run(
check_dataset("data/VOC.yaml"),
save_dir=Path(save_dir),
dataloader=dataloader, conf_thres=conf_thres,iou_thres=iou_thres,model=model,
plots=False,save_json=using_cocotools)[0][3]
至此,YOLOv5-QAT 的准备工作到这里就结束了,下面我们正式开始 QAT 量化训练和部署
四、YOLOv5-QAT微调导出-方案1
在正式开始 QAT 量化训练之前,请务必确保完成了三中的准备工作,这对我们后续的量化训练部署非常重要。
cuDLA-samples 这个 repo 为 YOLOv5 QAT 量化的 Q/DQ 节点插入提供了两种可能的方法。这两种方法各有优势,在 cuDLA-samples 项目中实现了对这两种方法的支持。
我们先来看方案一,方案一是按照 TensorRT Processing of Q/DQ Networks 中的建议放置 Q/DQ 节点,这种方法符合 TensorRT 的 D/DQ 层融合策略。下面我们开始方案一的具体实现。
1. QAT微调
将代码、数据集、权重准备好后我们就可以来进行 QAT 量化了,进入 yolov5 主目录执行如下指令:
python scripts/qat.py quantize best.pt --ptq=ptq.pt --qat=qat.pt --cocodir=/home/jarvis/Learn/Datasets/VOC_QAT --eval-ptq --eval-origin
注意将 cocodir 替换成你自己的路径
该指令会利用 best.pt 权重和对应的数据集进行量化,量化过程如下图所示:
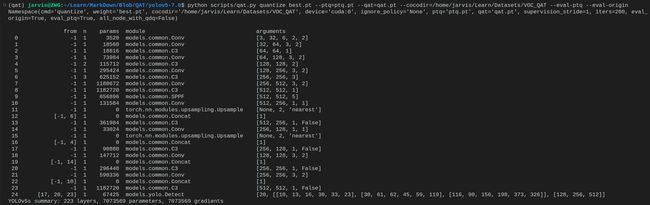
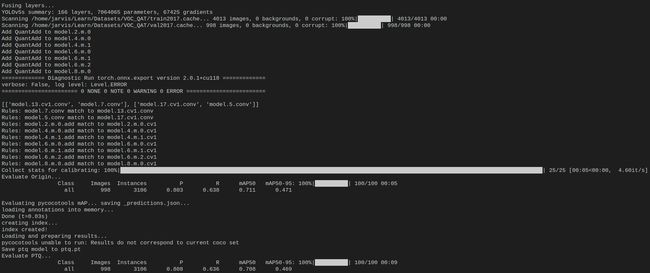

量化完成后在当前目录下会生成 ptq.pt 和 qat.pt 模型文件,分别对应着 PTQ 模型和 QAT 模型,后续我们只需要 qat.pt 模型并将其导出为 ONNX 即可。
2. QAT模型导出
我们需要将上面生成的 qat.pt 导出为 ONNX,在导出之前我们需要修改下源代码让其导出的 ONNX 模型尽可能的简单,并能够适配 tensorRT_Pro。为此我们需要修改 scripts/qat.py 以及 models/yolo.py 两个文件。
1. 修改输出节点名
# srcipts/qat.py第153行,export_onnx函数
# quantize.export_onnx(model, dummy, file, opset_version=13,
# input_names=["images"], output_names=["outputs"],
# dynamic_axes={"images": {0: "batch"}, "outputs": {0: "batch"}} if dynamic_batch else None
# )
# 修改为:
quantize.export_onnx(model, dummy, file, opset_version=13,
input_names=["images"], output_names=["output"],
dynamic_axes={"images": {0: "batch"}, "output": {0: "batch"}} if dynamic_batch else None
)
2. 导出的 ONNX 尽可能简单
# yolov5-7.0/models/yolo.py第60行,forward函数
# bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
# x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
# 修改为:
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
bs = -1
ny = int(ny)
nx = int(nx)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
# yolov5-7.0/models/yolo.py第79行,forward函数
# return x if self.training else (torch.cat(z, 1),) if self.export else (torch.cat(z, 1), x)
# 修改为:
return (torch.cat(z, 1),)
修改完成后我们就可以导出 qat.pt 模型了,指令如下:
python scripts/qat.py export qat.pt --size=640 --save=yolov5_trimmed_qat.onnx --dynamic
输出如下:

值得注意的是与 cuDLA-samples 的 README 做法不同,博主并没有指定 –noanchor 参数,而是将 anchor 节点放到了导出的 ONNX 模型中,此外 README 中有提到如果需要测试模型的 mAP 需要将 size 设置为 672,而在后续 QAT 模型的 mAP 测试中博主均采用的是 size 为 640 的模型。
导出的 onnx 模型如下图所示:

3. QAT模型转换
将导出的 QAT 模型转换为 PTQ 模型和 INT8 Cache 缓存文件,指令如下:
python qdq_translator/qdq_translator.py --input_onnx_models=yolov5_trimmed_qat.onnx --output_dir=./ --infer_concat_scales --infer_mul_scales
你可能会遇到下面的问题:

提示如下错误信息:
RuntimeError: Expected QuantizeLinear operator's scale and zero_point arguments to be parsed as gs.Variables filled by gs.Constant operators, but got ('Constant', 'Identity') operators. This is possibly caused by symbolic variables were not converted to tensors during PyTorch to ONNX exporting.
我们从错误信息中可以分析得出是由于 Pytorch 模型导出 ONNX 模型时出现了符号变量转换的问题,具体是 Identity 算子引起的,这说明我们之前导出的 ONNX 模型是存在问题的。
我们可以利用 Netron 可视化工具查看下之前导出的 ONNX 模型如下所示:

可以发现算子中除了插入 Q/DQ 节点外,还引入了 Identity 节点,这并不是我们希望看到的。
那引起多余 Identity 节点的原因是什么呢?如何正确导出 ONNX 模型呢?
量化训练导出步骤都是正确的,都是按照 README 文档来进行的,但是最终导出的模型却存在差异。经过博主测试发现,主要是由于安装的软件包版本差异引起的,具体是量化工具库 pytorch_quantization 和 pytorch 版本的适配问题导致的多余节点存在。
博主原本的软件版本是:pytorch_quantization==2.1.3, pytorch==1.12.1
发现可能是 pytorch 版本太低的原因,于是重新创建了新的虚拟环境,并安装了高版本的 pytorch
博主修改后的软件版本是:pytorch_quantization==2.1.3, pytorch==2.0.1
修改后重新再去按照第 3 小节中的指令导出 qat.pt 模型,此时导出的 ONNX 模型如下:
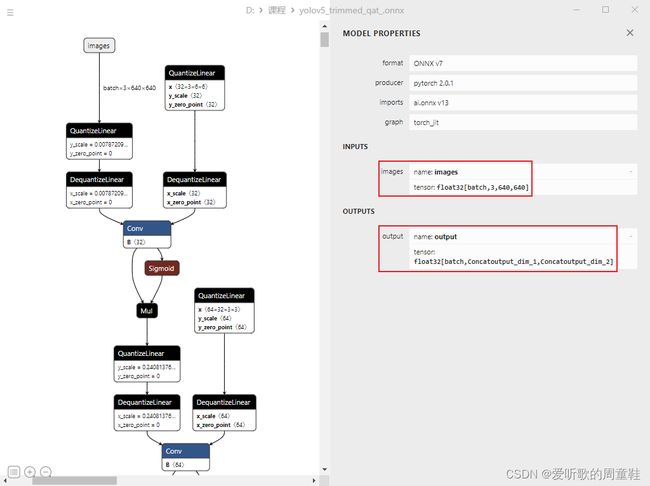
可以看到此时干净了不少,每个节点之间只有 Q/DQ 节点,并没有多余的部分,将正确导出的 ONNX 模型再执行模型转换的指令,正常输入如下:
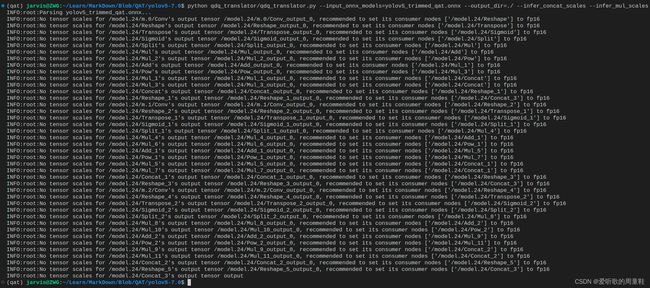
执行成功后在当前目录下会生成几个文件,我们来简单分析下它们各种的用途
1. yolov5_trimmed_qat_noqdq.onnx
- 这个文件是经过优化后的模型,其中 QDQ 节点被移除。QDQ 节点是与量化有关的节点,移除它们意味着模型已准备好进行后量化(PTQ)
- 其实就是普通的 ONNX 模型,没有什么区别,只不过进行了 onnxsim 所以整个模型看起来非常干净
2. yolov5_trimmed_qat_precision_config_calib.cache
- 该文件是由 export_to_trt_calib 函数生成的,它包含了 TensorRT 的校准信息。它使用了从 .json 文件中的 int8_tensor_scales 部分提取的数据。这个文件将被用于 TensorRT 的 INT8 量化。
- 其实就是我们所说的 INT8 Cache 缓存文件,里面存储着每层的量化信息即 scale 和 zero_point
3. yolov5_trimmed_qat_precision_config_layer_arg.txt
- 同样由 export_to_trt_calib 函数生成。它包含了需要以 FP16 格式运行的层的列表。这个文件可以用于指导 TensorRT 在 FP16 精度模式下执行哪些层
- 这个文件中应该是敏感层分析后的结果,具体就是某些层不建议使用 INT8 精度,推荐 FP16,后续在利用 trtexec 工具生成 INT8 模型时需要使用到。
4. yolov5_trimmed_qat_precision_config.json
- 这个文件内容包含了两个主要部分:int8_tensor_scales 和 fp16_nodes。int8_tensor_scales 部分包含了层的名字和对应的缩放因子,而 fp16_node 部分包含了需要以 FP16 格式运行的层的列表。这个文件是量化过程的一个中间产物,用于保存模型中每个层的缩放因子和敏感层的信息
- cache 缓存文件和 txt 敏感层文件的都是由 json 文件生成的
至此,YOLOv5-QAT 微调导出的方案一到这里就结束了。
后续 INT8 模型的生成和部署需要使用到这里生成的 ONNX 模型、量化信息缓存文件以及敏感层信息文件。
可以点击 here【pwd:yolo】下载博主 QAT 量化训练好的模型和中间文件。
五、YOLOv5-QAT微调导出-方案2
接着我们来看下第二种方案,方案二会在每一层都插入 Q/DQ 节点,确保所有的 tensor 都有 INT8 尺度信息。与方案一相比,所有层的 scale 都可以在模型微调时获得。但如果在 GPU 上运行推理,这种方法可能会破坏 TensorRT 中的 Q/DQ 层的融合策略。这也就是为什么在使用方案二导入带有 Q/DQ 节点的 ONNX 模型时在 GPU 上的延迟可能会更高的原因。
1. QAT微调
将代码、数据集、权重准备好后我们就可以来进行 QAT 量化了,进入 yolov5 主目录执行如下指令:
python scripts/qat.py quantize best.pt --ptq=ptq.pt --qat=qat.pt --cocodir=/home/jarvis/Learn/Datasets/VOC_QAT --eval-ptq --eval-origin --all-node-with-qdq
注意将 cocodir 替换成你自己的路径,与方案一不同的是我们加上了 –all-node-with-qdq 参数,意味着在所有节点上都会插入 Q/DQ 节点。
该指令会利用 best.pt 权重和对应的数据集进行量化,量化过程如下图所示:
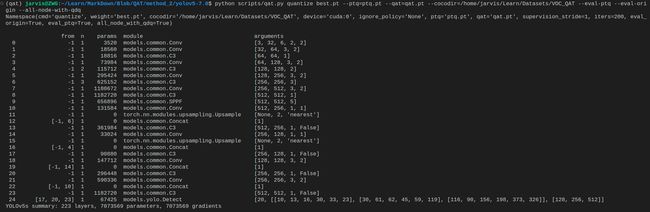


量化完成后在当前目录下会生成 ptq.pt 和 qat.pt 模型文件,分别对应着 PTQ 模型和 QAT 模型,后续我们只需要 qat.pt 模型并将其导出为 ONNX 即可。
2. QAT模型导出
我们需要将上面生成的 qat.pt 导出为 ONNX,在导出之前我们需要修改下源代码让其导出的 ONNX 模型尽可能的简单,并能够适配 tensorRT_Pro。为此我们需要修改 scripts/qat.py 以及 models/yolo.py 两个文件。
1. 修改输出节点名
# srcipts/qat.py第153行,export_onnx函数
# quantize.export_onnx(model, dummy, file, opset_version=13,
# input_names=["images"], output_names=["outputs"],
# dynamic_axes={"images": {0: "batch"}, "outputs": {0: "batch"}} if dynamic_batch else None
# )
# 修改为:
quantize.export_onnx(model, dummy, file, opset_version=13,
input_names=["images"], output_names=["output"],
dynamic_axes={"images": {0: "batch"}, "output": {0: "batch"}} if dynamic_batch else None
)
2. 导出的 ONNX 尽可能简单
# yolov5-7.0/models/yolo.py第60行,forward函数
# bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
# x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
# 修改为:
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
bs = -1
ny = int(ny)
nx = int(nx)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
# yolov5-7.0/models/yolo.py第79行,forward函数
# return x if self.training else (torch.cat(z, 1),) if self.export else (torch.cat(z, 1), x)
# 修改为:
return (torch.cat(z, 1),)
修改完成后我们就可以导出 qat.pt 模型了,指令如下:
python scripts/qat.py export qat.pt --size=640 --save=yolov5_trimmed_qat.onnx --dynamic
输出如下:

值得注意的是与 cuDLA-samples 的 README 做法不同,博主并没有指定 –noanchor 参数,而是将 anchor 节点放到了导出的 ONNX 模型中,此外 README 中有提到如果需要测试模型的 mAP 需要将 size 设置为 672,而在后续 QAT 模型的 mAP 测试中博主均采用的是 size 为 640 的模型。
导出的 onnx 模型如下图所示:

与方案一对比可以发现方案二导出的 ONNX 模型中的每个节点都被插入了 Q/DQ 节点。
注:如果导出的 ONNX 模型包含 Identity 节点,导致后面的 QAT 模型转换失败,可查看方案一中的解决方法,这里不再赘述。
3. QAT模型转换
将导出的 QAT 模型转换为 PTQ 模型和 INT8 Cache 缓存文件,指令如下:
python qdq_translator/qdq_translator.py --input_onnx_models=yolov5_trimmed_qat.onnx --output_dir=./
与方案一相比,少了 –infer_concat_scales 和 –infer_mul_scales 参数的指定。
输入如下:
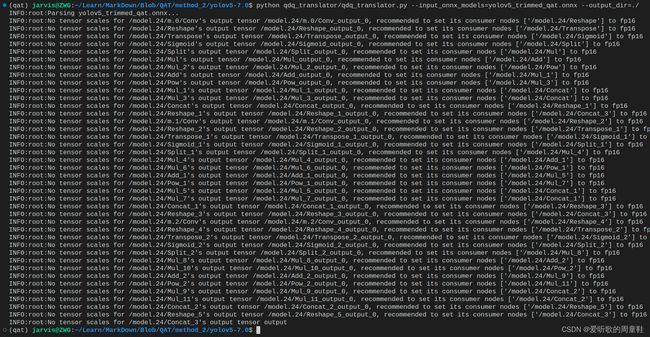
至此,YOLOv5-QAT 微调导出的方案二到这里就结束了。
可以点击 here【pwd:yolo】下载博主 QAT 量化训练好的模型和中间文件。
六、YOLOv5-QAT部署
由于博主手头没有合适的 Jetson 嵌入式设备,因此打算使用自己的主机完成 YOLOv5-QAT 部署工作,部署使用的 repo 是 tensorRT_Pro。
接下来我们主要是针对 tensorRT_Pro 项目中的 YOLOv5 完成 QAT 的模型部署,本次部署的模型是 YOLOv5s.pt,数据集为 VOC,类别数为 20。
1. 源码下载
tensorRT_Pro 的代码可以直接从 GitHub 官网上下载,源码下载地址是 https://github.com/shouxieai/tensorRT_Pro,Linux 下代码克隆指令如下:
$ git clone https://github.com/shouxieai/tensorRT_Pro
也可手动点击下载,点击右上角的 Code 按键,将代码下载下来。至此整个项目就已经准备好了。也可以点击 Baidu Drive【pwd:yolo】 下载博主准备好的源代码(注意该代码下载于 2023/10/6 日,若有改动请参考最新)
2. 环境配置
需要使用的软件环境有 TensorRT、CUDA、cuDNN、OpenCV、Protobuf,所有软件环境的安装可以参考 Ubuntu20.04部署YOLOv5,这里不再赘述,需要各位看官自行配置好相关环境,外网访问较慢,这里提供下博主安装过程中的软件安装包下载链接 Baidu Drive【pwd:yolo】
tensorRT_Pro 提供 CMakeLists.txt 和 Makefile 两种方式编译,二者选一即可
2.1 配置CMakeLists.txt
主要修改六处
1. 修改第 10 行,选择不支持 python (也可选择支持)
set(HAS_PYTHON OFF)
2. 修改第 18 行,修改 OpenCV 路径
set(OpenCV_DIR "/usr/local/include/opencv4/")
3. 修改第 20 行,修改 CUDA 路径
set(CUDA_TOOLKIT_ROOT_DIR "/usr/local/cuda-11.6")
4. 修改第 21 行,修改 cuDNN 路径
set(CUDNN_DIR "/usr/local/cudnn8.4.0.27-cuda11.6")
5. 修改第 22 行,修改 tensorRT 路径
set(TENSORRT_DIR "/opt/TensorRT-8.4.1.5")
6. 修改第 33 行,修改 protobuf 路径
set(PROTOBUF_DIR "/home/jarvis/protobuf")
完整的 CMakeLists.txt 的内容如下:
cmake_minimum_required(VERSION 2.6)
project(pro)
option(CUDA_USE_STATIC_CUDA_RUNTIME OFF)
set(CMAKE_CXX_STANDARD 11)
set(CMAKE_BUILD_TYPE Debug)
set(EXECUTABLE_OUTPUT_PATH ${PROJECT_SOURCE_DIR}/workspace)
# 如果要支持python则设置python路径
set(HAS_PYTHON OFF) # ===== 修改 1 =====
set(PythonRoot "/datav/software/anaconda3")
set(PythonName "python3.9")
# 如果你是不同显卡,请设置为显卡对应的号码参考这里:https://developer.nvidia.com/zh-cn/cuda-gpus#compute
#set(CUDA_GEN_CODE "-gencode=arch=compute_75,code=sm_75")
# 如果你的opencv找不到,可以自己指定目录
set(OpenCV_DIR "/usr/local/include/opencv4/") # ===== 修改 2 =====
set(CUDA_TOOLKIT_ROOT_DIR "/usr/local/cuda-11.6") # ===== 修改 3 =====
set(CUDNN_DIR "/usr/local/cudnn8.4.0.27-cuda11.6") # ===== 修改 4 =====
set(TENSORRT_DIR "/opt/TensorRT-8.4.1.5") # ===== 修改 5 =====
# set(CUDA_TOOLKIT_ROOT_DIR "/data/sxai/lean/cuda-10.2")
# set(CUDNN_DIR "/data/sxai/lean/cudnn7.6.5.32-cuda10.2")
# set(TENSORRT_DIR "/data/sxai/lean/TensorRT-7.0.0.11")
# set(CUDA_TOOLKIT_ROOT_DIR "/data/sxai/lean/cuda-11.1")
# set(CUDNN_DIR "/data/sxai/lean/cudnn8.2.2.26")
# set(TENSORRT_DIR "/data/sxai/lean/TensorRT-7.2.1.6")
# 因为protobuf,需要用特定版本,所以这里指定路径
set(PROTOBUF_DIR "/home/jarvis/protobuf") # ===== 修改 6 ======
find_package(CUDA REQUIRED)
find_package(OpenCV)
include_directories(
${PROJECT_SOURCE_DIR}/src
${PROJECT_SOURCE_DIR}/src/application
${PROJECT_SOURCE_DIR}/src/tensorRT
${PROJECT_SOURCE_DIR}/src/tensorRT/common
${OpenCV_INCLUDE_DIRS}
${CUDA_TOOLKIT_ROOT_DIR}/include
${PROTOBUF_DIR}/include
${TENSORRT_DIR}/include
${CUDNN_DIR}/include
)
# 切记,protobuf的lib目录一定要比tensorRT目录前面,因为tensorRTlib下带有protobuf的so文件
# 这可能带来错误
link_directories(
${PROTOBUF_DIR}/lib
${TENSORRT_DIR}/lib
${CUDA_TOOLKIT_ROOT_DIR}/lib64
${CUDNN_DIR}/lib
)
if("${HAS_PYTHON}" STREQUAL "ON")
message("Usage Python ${PythonRoot}")
include_directories(${PythonRoot}/include/${PythonName})
link_directories(${PythonRoot}/lib)
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -DHAS_PYTHON")
endif()
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -std=c++11 -Wall -O0 -Wfatal-errors -pthread -w -g")
set(CUDA_NVCC_FLAGS "${CUDA_NVCC_FLAGS} -std=c++11 -O0 -Xcompiler -fPIC -g -w ${CUDA_GEN_CODE}")
file(GLOB_RECURSE cpp_srcs ${PROJECT_SOURCE_DIR}/src/*.cpp)
file(GLOB_RECURSE cuda_srcs ${PROJECT_SOURCE_DIR}/src/*.cu)
cuda_add_library(plugin_list SHARED ${cuda_srcs})
target_link_libraries(plugin_list nvinfer nvinfer_plugin)
target_link_libraries(plugin_list cuda cublas cudart cudnn)
target_link_libraries(plugin_list protobuf pthread)
target_link_libraries(plugin_list ${OpenCV_LIBS})
add_executable(pro ${cpp_srcs})
# 如果提示插件找不到,请使用dlopen(xxx.so, NOW)的方式手动加载可以解决插件找不到问题
target_link_libraries(pro nvinfer nvinfer_plugin)
target_link_libraries(pro cuda cublas cudart cudnn)
target_link_libraries(pro protobuf pthread plugin_list)
target_link_libraries(pro ${OpenCV_LIBS})
if("${HAS_PYTHON}" STREQUAL "ON")
set(LIBRARY_OUTPUT_PATH ${PROJECT_SOURCE_DIR}/example-python/pytrt)
add_library(pytrtc SHARED ${cpp_srcs})
target_link_libraries(pytrtc nvinfer nvinfer_plugin)
target_link_libraries(pytrtc cuda cublas cudart cudnn)
target_link_libraries(pytrtc protobuf pthread plugin_list)
target_link_libraries(pytrtc ${OpenCV_LIBS})
target_link_libraries(pytrtc "${PythonName}")
target_link_libraries(pro "${PythonName}")
endif()
add_custom_target(
yolo
DEPENDS pro
WORKING_DIRECTORY ${PROJECT_SOURCE_DIR}/workspace
COMMAND ./pro yolo
)
add_custom_target(
yolo_gpuptr
DEPENDS pro
WORKING_DIRECTORY ${PROJECT_SOURCE_DIR}/workspace
COMMAND ./pro yolo_gpuptr
)
add_custom_target(
yolo_fast
DEPENDS pro
WORKING_DIRECTORY ${PROJECT_SOURCE_DIR}/workspace
COMMAND ./pro yolo_fast
)
add_custom_target(
centernet
DEPENDS pro
WORKING_DIRECTORY ${PROJECT_SOURCE_DIR}/workspace
COMMAND ./pro centernet
)
add_custom_target(
alphapose
DEPENDS pro
WORKING_DIRECTORY ${PROJECT_SOURCE_DIR}/workspace
COMMAND ./pro alphapose
)
add_custom_target(
retinaface
DEPENDS pro
WORKING_DIRECTORY ${PROJECT_SOURCE_DIR}/workspace
COMMAND ./pro retinaface
)
add_custom_target(
dbface
DEPENDS pro
WORKING_DIRECTORY ${PROJECT_SOURCE_DIR}/workspace
COMMAND ./pro dbface
)
add_custom_target(
arcface
DEPENDS pro
WORKING_DIRECTORY ${PROJECT_SOURCE_DIR}/workspace
COMMAND ./pro arcface
)
add_custom_target(
bert
DEPENDS pro
WORKING_DIRECTORY ${PROJECT_SOURCE_DIR}/workspace
COMMAND ./pro bert
)
add_custom_target(
fall
DEPENDS pro
WORKING_DIRECTORY ${PROJECT_SOURCE_DIR}/workspace
COMMAND ./pro fall_recognize
)
add_custom_target(
scrfd
DEPENDS pro
WORKING_DIRECTORY ${PROJECT_SOURCE_DIR}/workspace
COMMAND ./pro scrfd
)
add_custom_target(
lesson
DEPENDS pro
WORKING_DIRECTORY ${PROJECT_SOURCE_DIR}/workspace
COMMAND ./pro lesson
)
add_custom_target(
pyscrfd
DEPENDS pytrtc
WORKING_DIRECTORY ${PROJECT_SOURCE_DIR}/example-python
COMMAND python test_scrfd.py
)
add_custom_target(
pyinstall
DEPENDS pytrtc
WORKING_DIRECTORY ${PROJECT_SOURCE_DIR}/example-python
COMMAND python setup.py install
)
add_custom_target(
pytorch
DEPENDS pytrtc
WORKING_DIRECTORY ${PROJECT_SOURCE_DIR}/example-python
COMMAND python test_torch.py
)
add_custom_target(
pyyolov5
DEPENDS pytrtc
WORKING_DIRECTORY ${PROJECT_SOURCE_DIR}/example-python
COMMAND python test_yolov5.py
)
add_custom_target(
pycenternet
DEPENDS pytrtc
WORKING_DIRECTORY ${PROJECT_SOURCE_DIR}/example-python
COMMAND python test_centernet.py
)
2.2 配置Makefile
主要修改六处
1. 修改第 4 行,修改 protobuf 路径
lean_protobuf := /home/jarvis/protobuf
2. 修改第 5 行,修改 tensorRT 路径
lean_tensor_rt := /opt/TensorRT-8.4.1.5
3. 修改第 6 行,修改 cuDNN 路径
lean_cudnn := /usr/local/cudnn8.4.0.27-cuda11.6
4. 修改第 7 行,修改 OpenCV 路径
lean_opencv := /usr/local
5. 修改第 8 行,修改 CUDA 路径
lean_cuda := /usr/local/cuda-11.6
6. 修改第 9 行,选择不支持 python (也可选择支持)
use_python := false
完整的 Makefile 的内容如下:
cc := g++
nvcc = ${lean_cuda}/bin/nvcc
lean_protobuf := /home/jarvis/protobuf # ===== 修改 1 =====
lean_tensor_rt := /opt/TensorRT-8.4.1.5 # ===== 修改 2 =====
lean_cudnn := /usr/local/cudnn8.4.0.27-cuda11.6 # ===== 修改 3 =====
lean_opencv := /usr/local # ===== 修改 4 =====
lean_cuda := /usr/local/cuda-11.6 # ===== 修改 5 =====
use_python := false # ===== 修改 6 =====
python_root := /datav/software/anaconda3
# python_root指向的lib目录下有个libpython3.9.so,因此这里写python3.9
# 对于有些版本,so名字是libpython3.7m.so,你需要填写python3.7m
# /datav/software/anaconda3/lib/libpython3.9.so
python_name := python3.9
# 如果是其他显卡,请修改-gencode=arch=compute_75,code=sm_75为对应显卡的能力
# 显卡对应的号码参考这里:https://developer.nvidia.com/zh-cn/cuda-gpus#compute
cuda_arch := # -gencode=arch=compute_75,code=sm_75
cpp_srcs := $(shell find src -name "*.cpp")
cpp_objs := $(cpp_srcs:.cpp=.cpp.o)
cpp_objs := $(cpp_objs:src/%=objs/%)
cpp_mk := $(cpp_objs:.cpp.o=.cpp.mk)
cu_srcs := $(shell find src -name "*.cu")
cu_objs := $(cu_srcs:.cu=.cu.o)
cu_objs := $(cu_objs:src/%=objs/%)
cu_mk := $(cu_objs:.cu.o=.cu.mk)
include_paths := src \
src/application \
src/tensorRT \
src/tensorRT/common \
$(lean_protobuf)/include \
$(lean_opencv)/include/opencv4 \
$(lean_tensor_rt)/include \
$(lean_cuda)/include \
$(lean_cudnn)/include
library_paths := $(lean_protobuf)/lib \
$(lean_opencv)/lib \
$(lean_tensor_rt)/lib \
$(lean_cuda)/lib64 \
$(lean_cudnn)/lib
link_librarys := opencv_core opencv_imgproc opencv_videoio opencv_imgcodecs \
nvinfer nvinfer_plugin \
cuda cublas cudart cudnn \
stdc++ protobuf dl
# HAS_PYTHON表示是否编译python支持
support_define :=
ifeq ($(use_python), true)
include_paths += $(python_root)/include/$(python_name)
library_paths += $(python_root)/lib
link_librarys += $(python_name)
support_define += -DHAS_PYTHON
endif
empty :=
export_path := $(subst $(empty) $(empty),:,$(library_paths))
run_paths := $(foreach item,$(library_paths),-Wl,-rpath=$(item))
include_paths := $(foreach item,$(include_paths),-I$(item))
library_paths := $(foreach item,$(library_paths),-L$(item))
link_librarys := $(foreach item,$(link_librarys),-l$(item))
cpp_compile_flags := -std=c++11 -g -w -O0 -fPIC -pthread -fopenmp $(support_define)
cu_compile_flags := -std=c++11 -g -w -O0 -Xcompiler "$(cpp_compile_flags)" $(cuda_arch) $(support_define)
link_flags := -pthread -fopenmp -Wl,-rpath='$$ORIGIN'
cpp_compile_flags += $(include_paths)
cu_compile_flags += $(include_paths)
link_flags += $(library_paths) $(link_librarys) $(run_paths)
ifneq ($(MAKECMDGOALS), clean)
-include $(cpp_mk) $(cu_mk)
endif
pro : workspace/pro
pytrtc : example-python/pytrt/libpytrtc.so
expath : library_path.txt
library_path.txt :
@echo LD_LIBRARY_PATH=$(export_path):"$$"LD_LIBRARY_PATH > $@
workspace/pro : $(cpp_objs) $(cu_objs)
@echo Link $@
@mkdir -p $(dir $@)
@$(cc) $^ -o $@ $(link_flags)
example-python/pytrt/libpytrtc.so : $(cpp_objs) $(cu_objs)
@echo Link $@
@mkdir -p $(dir $@)
@$(cc) -shared $^ -o $@ $(link_flags)
objs/%.cpp.o : src/%.cpp
@echo Compile CXX $<
@mkdir -p $(dir $@)
@$(cc) -c $< -o $@ $(cpp_compile_flags)
objs/%.cu.o : src/%.cu
@echo Compile CUDA $<
@mkdir -p $(dir $@)
@$(nvcc) -c $< -o $@ $(cu_compile_flags)
objs/%.cpp.mk : src/%.cpp
@echo Compile depends CXX $<
@mkdir -p $(dir $@)
@$(cc) -M $< -MF $@ -MT $(@:.cpp.mk=.cpp.o) $(cpp_compile_flags)
objs/%.cu.mk : src/%.cu
@echo Compile depends CUDA $<
@mkdir -p $(dir $@)
@$(nvcc) -M $< -MF $@ -MT $(@:.cu.mk=.cu.o) $(cu_compile_flags)
yolo : workspace/pro
@cd workspace && ./pro yolo
yolo_gpuptr : workspace/pro
@cd workspace && ./pro yolo_gpuptr
dyolo : workspace/pro
@cd workspace && ./pro dyolo
dunet : workspace/pro
@cd workspace && ./pro dunet
dmae : workspace/pro
@cd workspace && ./pro dmae
dclassifier : workspace/pro
@cd workspace && ./pro dclassifier
yolo_fast : workspace/pro
@cd workspace && ./pro yolo_fast
bert : workspace/pro
@cd workspace && ./pro bert
alphapose : workspace/pro
@cd workspace && ./pro alphapose
fall : workspace/pro
@cd workspace && ./pro fall_recognize
retinaface : workspace/pro
@cd workspace && ./pro retinaface
arcface : workspace/pro
@cd workspace && ./pro arcface
test_warpaffine : workspace/pro
@cd workspace && ./pro test_warpaffine
test_yolo_map : workspace/pro
@cd workspace && ./pro test_yolo_map
arcface_video : workspace/pro
@cd workspace && ./pro arcface_video
arcface_tracker : workspace/pro
@cd workspace && ./pro arcface_tracker
test_all : workspace/pro
@cd workspace && ./pro test_all
scrfd : workspace/pro
@cd workspace && ./pro scrfd
centernet : workspace/pro
@cd workspace && ./pro centernet
dbface : workspace/pro
@cd workspace && ./pro dbface
high_perf : workspace/pro
@cd workspace && ./pro high_perf
lesson : workspace/pro
@cd workspace && ./pro lesson
plugin : workspace/pro
@cd workspace && ./pro plugin
pytorch : pytrtc
@cd example-python && python test_torch.py
pyscrfd : pytrtc
@cd example-python && python test_scrfd.py
pyretinaface : pytrtc
@cd example-python && python test_retinaface.py
pycenternet : pytrtc
@cd example-python && python test_centernet.py
pyyolov5 : pytrtc
@cd example-python && python test_yolov5.py
pyyolov7 : pytrtc
@cd example-python && python test_yolov7.py
pyyolox : pytrtc
@cd example-python && python test_yolox.py
pyarcface : pytrtc
@cd example-python && python test_arcface.py
pyinstall : pytrtc
@cd example-python && python setup.py install
clean :
@rm -rf objs workspace/pro example-python/pytrt/libpytrtc.so example-python/build example-python/dist example-python/pytrt.egg-info example-python/pytrt/__pycache__
@rm -rf workspace/single_inference
@rm -rf workspace/scrfd_result workspace/retinaface_result
@rm -rf workspace/YoloV5_result workspace/YoloX_result
@rm -rf workspace/face/library_draw workspace/face/result
@rm -rf build
@rm -rf example-python/pytrt/libplugin_list.so
@rm -rf library_path.txt
.PHONY : clean yolo alphapose fall debug
# 导出符号,使得运行时能够链接上
export LD_LIBRARY_PATH:=$(export_path):$(LD_LIBRARY_PATH)
3. INT8模型生成
参考自:cuDLA-samples/blob/main/data/model/build_dla_standalone_loadable_v2.sh
我们在之前拿到了经过 QAT 量化训练后的 ONNX 模型和对应的量化参数缓存文件,还没有生成具体的 INT8 模型,需要通过 trtexec 工具和对应的指令生成。对于 trtexec 有困惑的可以参考:如何熟练的使用trtexec
由于指令比较复杂,因此我们新建一个 build.sh 脚本文件专门用于生成 engine,其内容如下:
echo "Build FP32 Model"
TRTEXEC=/opt/TensorRT-8.4.1.5/bin/trtexec
${TRTEXEC} --onnx=yolov5_trimmed_qat_noqdq.onnx --minShapes=images:1x3x640x640 --optShapes=images:1x3x640x640 --maxShapes=images:16x3x640x640 --saveEngine=yolov5_trimmed_qat_noqdq.FP32.trtmodel
echo "Build FP16 Model"
TRTEXEC=/opt/TensorRT-8.4.1.5/bin/trtexec
${TRTEXEC} --onnx=yolov5_trimmed_qat_noqdq.onnx --minShapes=images:1x3x640x640 --optShapes=images:1x3x640x640 --maxShapes=images:16x3x640x640 --fp16 --saveEngine=yolov5_trimmed_qat_noqdq.FP16.trtmodel
echo "Build INT8 Model"
TRTEXEC=/opt/TensorRT-8.4.1.5/bin/trtexec
${TRTEXEC} --onnx=yolov5_trimmed_qat_noqdq.onnx --minShapes=images:1x3x640x640 --optShapes=images:1x3x640x640 --maxShapes=images:16x3x640x640 --fp16 --int8 --saveEngine=yolov5_trimmed_qat_noqdq.INT8.trtmodel --calib=yolov5_trimmed_qat_precision_config_calib.cache --precisionConstraints=obey --layerPrecisions="/model.24/Reshape":fp16,"/model.24/Transpose":fp16,"/model.24/Sigmoid":fp16,"/model.24/Split":fp16,"/model.24/Mul":fp16,"/model.24/Add":fp16,"/model.24/Pow":fp16,"/model.24/Mul_1":fp16,"/model.24/Mul_3":fp16,"/model.24/Concat":fp16,"/model.24/Concat":fp16,"/model.24/Reshape_1":fp16,"/model.24/Concat_3":fp16,"/model.24/Reshape_2":fp16,"/model.24/Transpose_1":fp16,"/model.24/Sigmoid_1":fp16,"/model.24/Split_1":fp16,"/model.24/Mul_4":fp16,"/model.24/Add_1":fp16,"/model.24/Pow_1":fp16,"/model.24/Mul_5":fp16,"/model.24/Mul_7":fp16,"/model.24/Concat_1":fp16,"/model.24/Concat_1":fp16,"/model.24/Reshape_3":fp16,"/model.24/Concat_3":fp16,"/model.24/Reshape_4":fp16,"/model.24/Transpose_2":fp16,"/model.24/Sigmoid_2":fp16,"/model.24/Split_2":fp16,"/model.24/Mul_8":fp16,"/model.24/Add_2":fp16,"/model.24/Pow_2":fp16,"/model.24/Mul_9":fp16,"/model.24/Mul_11":fp16,"/model.24/Concat_2":fp16,"/model.24/Concat_2":fp16,"/model.24/Reshape_5":fp16,"/model.24/Concat_3":fp16
注意上述脚本文件可以同时生成 FP32、FP16、INT8 模型,如果只需要其中某一个则单独复制即可
我们主要是来看 INT8 模型生成的指令,分析如下:
1. TRTEXEC 路径:
- TRTEXEC=/opt/TensorRT-8.4.1.5/bin/trtexec 这定义了 trtexec 工具的路径。
- 需要修改为你自己的 trtexec 路径
2. ONNX 模型:
- –onnx=yolov5_trimmed_qat_noqdq.onnx 这指定了要转换的 ONNX 模型。
- 这里指定的 ONNX 模型是我们在之前通过 QAT 模型转换生成的不带 Q/DQ 节点的 ONNX 模型,也就是一个普通的 ONNX 模型。
3. 输入形状定义:
- –minShapes=images:1x3x640x640:定义了模型输入的最小 shape。
- –optShapes=images:1x3x640x640:定义了模型输入的最佳 shape(对于性能优化很有帮助)。
- –maxShapes=images:16x3x640x640:定义了模型输入的最大 shape。
- 这些形状参数允许 TensorRT 构建一个动态 shape 的 engine,这意味着引擎可以处理不同大小的输入批次,但在上述指定的范围内。
- 可以根据自己的需求修改
4. 精度模式:
- –fp16:启用半精度 (FP16) 优化。
- –int8:启用 INT8 量化优化。
- 我们同时启动了 FP16 和 INT8 两种精度模式,这是因为我们在 QAT 量化训练中通过敏感层分析得出需要将某些特定层设置为 FP16 精度,具体的层信息可以通过 yolov5_trimmed_qat_precision_config_layer_arg.txt 文件获得。
5. 保存引擎:
- –saveEngine=yolov5_trimmed_qat_noqdq.INT8.trtmodel 这指定了生成的 TensorRT 引擎的保存路径。
6. 量化校准:
- –calib=yolov5_trimmed_qat_precision_config_calib.cache 为 INT8 量化提供了一个校准缓存文件。
- 该文件存储了模型中各个层的量化信息,用于指导 TensorRT 的 INT8 量化。
7. 精度约束:
- –precisionConstraints=obey 这要求 TensorRT 严格遵循下面指定的每层精度。
8. 每层精度:
- –layerPrecisions=“/model.24/Reshape”:fp16,“/model.24/Transpose”:fp16,… 这为特定的网络层指定了期望的精度。在这里,某些层被设置为 FP16 精度。
在之前 QAT 量化训练过程中生成的 .txt 文件中就包含了哪些层需要指定为 FP16 精度,大家可以直接复制到 –layerPrecisions 参数后面,但注意对应的节点名需要加上 “”,我们可以写个简单的脚本对每个节点自动加上 “” 避免手动加 “” 的繁琐,具体代码如下:
src_path = "yolov5_trimmed_qat_precision_config_layer_arg.txt"
dst_path = "yolov5_trimmed_qat_precision_config_layer_arg_dst.txt"
# Step 1: Reading the .txt file content
with open(src_path, "r") as txt_file:
content = txt_file.read().strip()
# Step 2: Splitting the content by comma to get individual items
items = content.split(',')[:-1]
# Step 3: Adding double quotes to each node in each item
modified_items = []
for item in items:
# Splitting each item at the ':' to separate the node from the precision
node, precision = item.split(':')
# Adding double quotes around the node
modified_item = f'"{node}":{precision}'
modified_items.append(modified_item)
# Step 4: Joining the modified items back to a single string
modified_content = ",".join(modified_items)
# Step 5: Saving the modified content to a new .txt file
with open(dst_path, "w") as output_file:
output_file.write(modified_content)
将 build.sh 脚本文件准备好后,我们可以在终端执行如下指令生成对应的 INT8 模型:
bash build.sh
输出如下图所示:
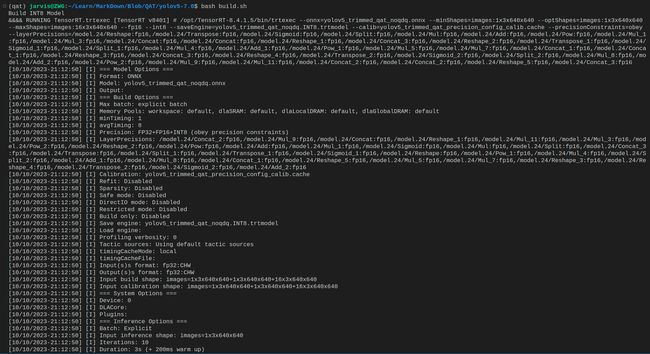
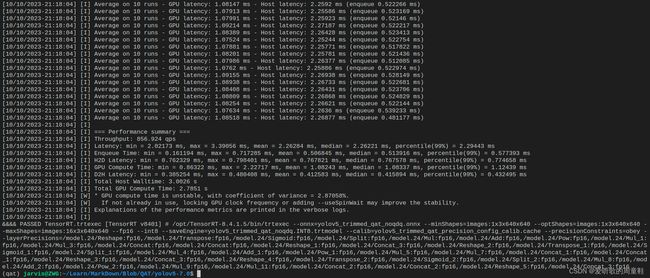
执行成功后会在当前目录下生成 yolov5_trimmed_qat_noqdq.INT8.trtmodel 文件,拿到 INT8 模型文件后我们就可以使用 tensorRT_Pro 完成对应的部署工作了。
注:其实还有另外一种 INT8 模型生成方法,具体可以参考第 5 小节内容
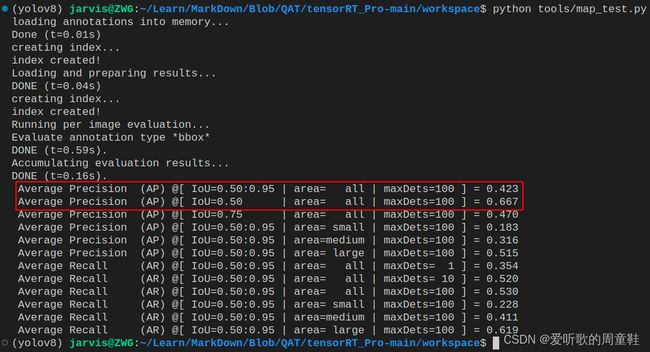
4. QAT模型mAP测试
经过 QAT 量化训练后的模型性能到底怎么样呢?
下面我们来测试下经过 QAT 量化后模型的 mAP,开始之前你需要将两个文件放到 tensorRT_Pro/workspace 文件夹下。这两个文件是 yolov5_trimmed_qat_noqdq.onnx 模型以及 yolov5_trimmed_qat_noqdq.INT8.trtmodel 模型。
将模型准备好后我们还需要适当修改下对应 mAP 测试的代码,在 src/application/test_yolo_map.cpp 文件中,我们就只需要修改这一个文件中的内容即可,源码修改较简单主要有以下几点:
- 1. test_yolo_map.cpp 172 行,修改要测试的验证集文件夹路径
- 2. test_yolo_map.cpp 175 行,修改要测试的 INT8 模型,yolov5s 修改为 yolov5_trimmed_qat_noqdq
- 3. test_yolo_map.cpp 176 行,TRT::Mode 修改为 INT8
- 4. test_yolo_map.cpp 125 行,将 save_to_json 函数简单修改下
修改后完整的 test_yolo_map.cpp 如下所示:
#include 上述代码会将 INT8 模型在验证集中所有图像的检测结果存储到一个 JSON 文件中,每个检测到的物体都被序列化为 JSON 格式信息,包括图像 ID、类别 ID、置信度和边界框坐标。后续我们就可以拿着这个预测结果的 JSON 文件和我们真实标签的 JSON 文件通过 COCO Python API 去计算 mAP 指标。
有以下几点需要注意:
- 博主将 JSON 文件中的 image_id 保存为一个字符串,考虑到图片命名的差异性
- 博主将 JSON 文件中的 category_id 直接保存为类别标签,没有做转换
- mAP 测试使用的 NMS_threshold = 0.65f,Conf_threshold = 0.001f 与 pytorch 保持一致
- 关于 mAP 的相关原理介绍可参考 目标检测mAP计算以及coco评价标准
将源码修改好后,直接在终端执行如下指令即可:
make test_yolo_map
图解如下所示:

运行成功后在 workspace 文件夹下会生成 yolov5_trimmed_qat_noqdq.prediction.json 文件,该 JSON 文件中保存着 INT8 模型在验证集上的推理结果。
我们拿到了模型预测结果的 JSON 文件后,还需要拿到真实标签的 JSON 文件,但是现在我们只有验证集真实的 YOLO 标签文件,因此需要将 YOLO 标签转换为 JSON 文件,转换代码如下:(from chatGPT)
import os
import cv2
import json
import logging
import os.path as osp
from tqdm import tqdm
from functools import partial
from multiprocessing import Pool, cpu_count
def set_logging(name=None):
rank = int(os.getenv('RANK', -1))
logging.basicConfig(format="%(message)s", level=logging.INFO if (rank in (-1, 0)) else logging.WARNING)
return logging.getLogger(name)
LOGGER = set_logging(__name__)
def process_img(image_filename, data_path, label_path):
# Open the image file to get its size
image_path = os.path.join(data_path, image_filename)
img = cv2.imread(image_path)
height, width = img.shape[:2]
# Open the corresponding label file
label_file = os.path.join(label_path, os.path.splitext(image_filename)[0] + ".txt")
with open(label_file, "r") as file:
lines = file.readlines()
# Process the labels
labels = []
for line in lines:
category, x, y, w, h = map(float, line.strip().split())
labels.append((category, x, y, w, h))
return image_filename, {"shape": (height, width), "labels": labels}
def get_img_info(data_path, label_path):
LOGGER.info(f"Get img info")
image_filenames = os.listdir(data_path)
with Pool(cpu_count()) as p:
results = list(tqdm(p.imap(partial(process_img, data_path=data_path, label_path=label_path), image_filenames), total=len(image_filenames)))
img_info = {image_filename: info for image_filename, info in results}
return img_info
def generate_coco_format_labels(img_info, class_names, save_path):
# for evaluation with pycocotools
dataset = {"categories": [], "annotations": [], "images": []}
for i, class_name in enumerate(class_names):
dataset["categories"].append(
{"id": i, "name": class_name, "supercategory": ""}
)
ann_id = 0
LOGGER.info(f"Convert to COCO format")
for i, (img_path, info) in enumerate(tqdm(img_info.items())):
labels = info["labels"] if info["labels"] else []
img_id = osp.splitext(osp.basename(img_path))[0]
img_h, img_w = info["shape"]
dataset["images"].append(
{
"file_name": os.path.basename(img_path),
"id": img_id,
"width": img_w,
"height": img_h,
}
)
if labels:
for label in labels:
c, x, y, w, h = label[:5]
# convert x,y,w,h to x1,y1,x2,y2
x1 = (x - w / 2) * img_w
y1 = (y - h / 2) * img_h
x2 = (x + w / 2) * img_w
y2 = (y + h / 2) * img_h
# cls_id starts from 0
cls_id = int(c)
w = max(0, x2 - x1)
h = max(0, y2 - y1)
dataset["annotations"].append(
{
"area": h * w,
"bbox": [x1, y1, w, h],
"category_id": cls_id,
"id": ann_id,
"image_id": img_id,
"iscrowd": 0,
# mask
"segmentation": [],
}
)
ann_id += 1
with open(save_path, "w") as f:
json.dump(dataset, f)
LOGGER.info(
f"Convert to COCO format finished. Resutls saved in {save_path}"
)
if __name__ == "__main__":
# Define the paths
data_path = "/home/jarvis/Learn/Datasets/VOC_PTQ/images/val"
label_path = "/home/jarvis/Learn/Datasets/VOC_PTQ/labels/val"
class_names = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus",
"car", "cat", "chair", "cow", "diningtable", "dog", "horse",
"motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"] # 类别名称请务必与 YOLO 格式的标签对应
save_path = "./val.json"
img_info = get_img_info(data_path, label_path)
generate_coco_format_labels(img_info, class_names, save_path)
上述代码的功能是将 YOLO 格式的数据集(包括图像文件和对应的 .txt 标签文件)转换成 COCO JSON 格式的标注。转换后的数据包括一个 JSON 标签文件,JSON 标签文件中包含了每个图像的所有物体的类别和边界框信息。
你需要修改以下几项:
- data_path:需要转换的图像文件路径
- label_path:需要转换的 txt 标签文件路径
- class_names:数据集的类别列表,请务必与 YOLO 标签的相对应
- save_path:转换后 JSON 文件保存的路径
- 注意:以上路径都不要包含中文,Windows 下路径记得使用
\\或者/防止转义
YOLO 标签中目标框保存的格式是每一行代表一个目标框信息,每一行共包含 [label_id, x_center, y_center, w, h] 五个变量,分别代表着标签 ID,经过归一化后的中心点坐标和目标框宽高。
JSON 文件中目标框保存的格式是 [x,y,w,h] 四个变量,分别代表着经过归一化的左上角坐标和目标框宽高。
关于代码的分析可以参考:tensorRT模型性能测试
至此,两个 JSON 文件都准备好了,一个是模型推理的预测结果,一个是真实结果。拿到两个 JSON 文件后我们就可以进行 mAP 测试了,具体代码如下:
from pycocotools.coco import COCO
from pycocotools.cocoeval import COCOeval
# Run COCO mAP evaluation
# Reference: https://github.com/cocodataset/cocoapi/blob/master/PythonAPI/pycocoEvalDemo.ipynb
annotations_path = "val.json"
results_file = "yolov5_trimmed_qat_noqdq.prediction.json"
cocoGt = COCO(annotation_file=annotations_path)
cocoDt = cocoGt.loadRes(results_file)
imgIds = sorted(cocoGt.getImgIds())
cocoEval = COCOeval(cocoGt, cocoDt, 'bbox')
cocoEval.params.imgIds = imgIds
cocoEval.evaluate()
cocoEval.accumulate()
cocoEval.summarize()
你需要修改以下几项:
- annotations_path:真实标签的 JSON 文件路径
- results_file:模型预测结果的 JSON 文件路径
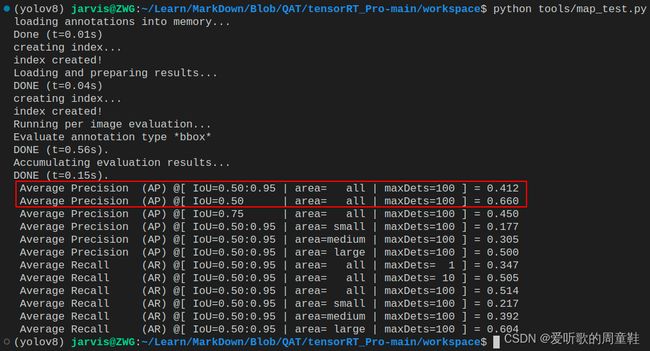
执行后测试结果如下图所示:

我们将它与原始 pytorch 的模型放在一起进行对比下:
| Model | Size | mAPval 0.5:0.95 |
mAPval 0.5 |
Params (M) |
FLOPs (G) |
|---|---|---|---|---|---|
| YOLOv5s | 640 | 0.471 | 0.711 | 7.2 | 16.5 |
| YOLOv5s-INT8 | 640 | 0.412 | 0.660 | - | - |
可以看到相比于原始 pytorch 模型,QAT 量化后的模型 mAP 下降了近 5 个点
OK!至此 YOLOv5 模型的 QAT 量化到这里结束了,各位看官可以在自己的数据集测试下 QAT 量化后模型的性能。
5. 补充-INT8模型生成
除了利用 trxexec 工具生成 INT8 模型外,我们还可以通过 tensorRT_Pro 生成,首先你需要准备两个文件,一个是 yolov5_trimmed_qat_noqdq.onnx 模型,一个是 yolov5_trimmed_qat_precision_config_calib.cache 校准缓存文件,把它们都放到 tensorRT_Pro/workspace 文件夹下。
将上述模型和校准缓存文件准备好后还要修改下源码,yolo 模型的推理代码主要在 src/application/app_yolo.cpp 文件中,我们就只需要修改这一个文件中的内容即可,源码修改较简单主要有以下几点:
-
1. app_yolo.cpp 177 行,Yolo::Type 修改为 V5,TRT::Mode 修改为 INT8,“yolov7” 改成 “yolov5_trimmed_qat_noqdq”
-
2. app_yolo.cpp 25 行,新增 voclabels 数组,添加 voc 数据集的类别名称
-
3. app_yolo.cpp 100 行,cocolabels 修改为 voclabels
-
4. app_yolo.cpp 149 行,TRT::complie 函数新增校准缓存文件参数 yolov5_trimmed_qat_precision_config_calib.cache
具体修改如下:
test(Yolo::Type::V5, TRT::Mode::INT8, "yolov5_trimmed_qat_noqdq") // 修改1 177行 "yolov7"改成"yolov5_trimmed_qat_noqdq"
static const char *voclabels[] = {"aeroplane", "bicycle", "bird", "boat", "bottle",
"bus", "car", "cat", "chair", "cow",
"diningtable", "dog", "horse", "motorbike", "person",
"pottedplant", "sheep", "sofa", "train", "tvmonitor"}; // 修改2 25行新增代码,为自训练模型的类别名称
for(auto& obj : boxes){
...
auto name = voclabels[obj.class_label]; // 修改3 100行cocolabels修改为voclabels
...
}
TRT::compile(
mode, // FP32、FP16、INT8
test_batch_size, // max batch size
onnx_file, // source
model_file, // save to
{},
int8process,
"inference",
"yolov5_trimmed_qat_precision_config_calib.cache" // 修改4 149行,新增校准文件参数
);
修改完成后在终端执行如下指令即可:
make yolo
图解如下所示:

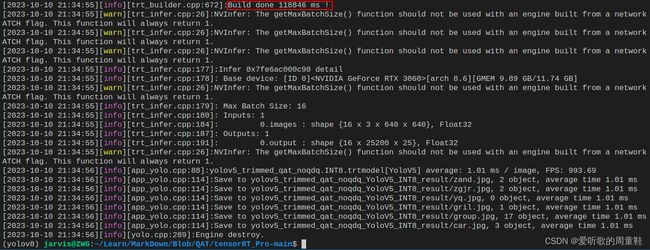
编译运行后在 workspace 文件夹下会生成 INT8 的 engine 模型 yolov5_trimmed_qat_noqdq.INT8.trtmodel 用于模型推理,同时它还会生成 yolov5_trimmed_qat_noqdq_Yolov5_INT8_result 文件夹,该文件夹下保存了推理的图片。
模型推理效果如下图所示:

值得注意的是与上篇文章 PTQ 的 INT8 模型生成不同的是,由于我们之前将 QAT 模型转换成了 PTQ 模型和对应的量化缓存文件,而 tensorRT_Pro 中可以直接加载校准缓存文件生成对应的 INT8 模型,因此不再需要校准图片去统计每一层的 scale 和 zero_point 了。
七、讨论
1. 基本概念
流程虽然说是走通了,但是博主还是有好多概念理不清,这里我们来讨论下,博主主要结合自己的理解和 ChatGPT 来回答一些概念问题,若有错误的地方请各位看官指正!!!
以下内容均来自博主与 ChatGPT 之间的对话。
问题1:带有 QAT 量化信息的 ONNX 模型中有 QDQ 模块,它包含了该层和该激活值的量化 scale 和 zero_point。这是不是意味着从 Float32 到 INT8 只需要乘以 scale 再加上 zero_point,类似于一条直线,是不是可以理解为一种线性量化方式?
回答:
这种理解是正确的。
ONNX 中的 QuantizeLinear 和 DequantizeLinear 操作(也称为 QDQ 操作)确实为模型的线性量化提供了支持。线性量化过程通常涉及将浮点数值转换为整数,这是通过使用一个缩放因子(scale)和一个零点(zero_point)来实现的。
对于给定的浮点数值 f f f,其量化到整数 q q q 的公式为:
q = round ( f scale ) + zero _ point q=\text{round}(\frac{f}{\text{scale}})+\text{zero}\_\text{point} q=round(scalef)+zero_point
同样地,从整数 q q q 反量化回浮点数值 f ′ f' f′ 的公式为:
f ′ = ( scale × ( q − zero_point ) ) f' = (\text{scale} \times (q-\text{zero\_point})) f′=(scale×(q−zero_point))
这里,scale 通常是一个浮点数,而 zero_point 是一个整数。在量化到 int8 的情况下,zero_point 通常是一个介于 -128 和 127 之间的整数。
这种量化方法确实意味着在浮点数值和整数之间的映射可以被看作是一条直线,其中 scale 表示斜率,zero_point 表示截距。
值得注意的是,当使用线性量化从浮点数 f f f 转换为整数 q q q 并从 q q q 反量化回 f ′ f' f′ 时,由于 round 操作和量化本身的离散性, f ′ f' f′ 可能与原始的 f f f 不完全相同。这种差异就被称为量化误差,具体来说,量化误差是 f ′ − f f'-f f′−f
我们的目的当然就是希望量化误差尽可能地小,这样,当我们运行量化模型时,它的输出与未量化模型的输出会非常的接近,从而保持了模型的性能。
为了最小化这种误差,我们需要为每一层找到合适的 scale 和 zero_point 来确保原始浮点数据的大部分信息在量化后仍然得以保留,因此如何选择合适的 scale 和 zero_point 成为了我们急需解决的问题。
问题2:PTQ 量化中的校准算法如 Entropy Calibration 的目的是什么?Entropy Calibration 过程是进行了量化吗?
回答:
Entropy Calibration 是一种校准方法,目的是确定 scale 和 zero_point 的最佳值,它通过最大化量化数据的熵来最小化量化误差。熵是一个信息论的概念,它表示随机变量的不确定性。通过最大化熵,我们可以确保量化后的数据尽可能多地保留原始数据的信息。
Entropy Calibration 本身并不进行量化,它只是一个为量化准备的步骤,用于确定量化的参数(即 scale 和 zero_point)。这些参数随后可用于线性量化。
有一个比较形象的比喻,假设现在你有一个音响系统,量化就像是调整音量的旋钮,它实际地改变音量。而 Entropy Calibration 就像是一个专家,告诉你应该将音量设置为多少以获得最佳的听觉体验。
所以,Entropy Calibration 和量化的工作是不同的:
Entropy Calibration
- 校准步骤
- 它的目的是确定最佳的 scale 和 zero_point 这些参数
- 使用数据集的子集(通常是验证集)来确定这些参数的最佳值,以便在量化时最小化信息损失
量化
- 实际的量化步骤
- 使用从 Entropy Calibration(或其他校准方法)中得到的 scale 和 zero_point 参数将浮点值转换为整数
问题3:我懂了 Entropy Calibration 校准的目的是确定 scale 和 zero_point,为了后面的量化。那这个 scale 和 zero_point 是每一层的 scale 和 zero_point 还是所有层统一的 scale 和 zero_point 呢?
回答:
在进行量化时,scale 和 zero_point 的选择可以是针对每一层的,也可以是全局的,这取决于量化策略和具体的量化工具。但在实际的深度学习模型量化中,通常每一层或每一组层都有其自己的 scale 和 zero_point,因为这样可以更好地适应每一层的数据分布,从而减少量化误差。
问题4:我还有个问题,既然 PTQ 量化是通过 Entropy Calibration 确定 scale 和 zero_point 的,那 QAT 量化是如何确定每一层的 scale 和 zero_point 的呢?
回答:
很好的问题。PTQ(Post-training Quantization)和 QAT(Quantization Aware Training)是两种主要的量化方法,它们确定 scale 和 zero_point 的方式是不同的。
1. PTQ(Post-training Quantization)
- 正如之前所提到的,PTQ 是在模型训练完成后进行的量化。在这种方法中,scale 和 zero_point 通常是通过某种校准方法(如 Entropy Calibration)确定的。
- 校准过程使用一个数据子集(通常是验证集)来确定这些参数的最佳值。
2. QAT(Quantization Aware Training)
- QAT 在模型训练过程中考虑量化效果。也就是说,量化操作(和它可能引入的误差)在训练过程中就被模拟和纳入考虑。
- 为了模拟量化效果,scale 和 zero_point 是动态计算的。具体的策略可能因不同的实现而异,但常见的做法是使用移动平均来跟踪权重和激活的数据分布,并据此动态调整 scale 和 zero_point
- 另一种常见的方法是使用某种形式的直方图或统计数据来确定最佳的量化参数。
- 由于量化误差是在训练过程中模拟的,因此模型可以学习适应这些误差,并可能获得更好的量化后的性能。
总的来说,QAT 与 PTQ 的主要区别在于其训练过程中就模拟了量化效果,而 PTQ 是在训练完成后进行的。这也意味着 QAT 需要更多的计算资源,因为它需要进行额外的前向和反向传播考虑量化误差,但通常可以获得更好的量化后的模型性能。
问题5:那对称量化和非对称量化在这其中又扮演了什么角色,它和 PTQ 量化和 QAT 量化这种又有什么联系?
回答:
对称量化和非对称量化是描述量化方式的术语,而 PTQ(Post-training Quantization)和 QAT(Quantization Aware Training)描述的是量化时机。这两组概念是正交的,也就是说,你可以在 PTQ 或 QAT 的情境下使用对称或非对称量化。
1. 对称量化 (Symmetric Quantization):
- 在对称量化中,量化的范围是对称的,也就是说,它以 0 为中心。
- 对于 int8 量化,范围是 [-127, 127](注意,-128 通常不被使用以保持对称性)
- zero_point 在对称量化中总是 0。
- 由于这种对称性,对称量化有时可以简化某些硬件上的计算,从而提高性能。
2. 非对称量化 (Asymmetric Quantization):
- 在非对称量化中,量化的范围不一定是对称的。
- zero_point 可以是任意值,因此可以更好地适应数据的实际分布。
- 非对称量化可能为某些数据分布提供更好的量化精度,但在硬件上可能不如对称量化高效。
与 PTQ 和 QAT 的关系:
1. PTQ:
- 在训练后量化中,你可以选择使用对称量化或非对称量化。选择哪种量化方式取决于您的目标:是追求更高的性能还是更低的量化误差。
- 校准步骤(例如 Entropy Calibration)可以为每种量化方式确定最佳的 scale 和 zero_point。
2. QAT:
- 在训练中,你同样可以选择模拟对称或非对称量化的效果。
- 例如,对于对称量化,您可以在训练过程中固定 zero_point 为 0,我们上面采用的 YOLOv5-QAT 方案貌似都是使用的对称量化方式。
- 而对于非对称量化,您可能会动态地调整 zero_point,以便更好地适应每个 mini-batch 的数据分布。
总的来说,对称和非对称量化描述的是量化方式,而 PTQ 和 QAT 描述的是量化时机。这两组概念是独立的,你可以根据需求和目标选择合适的组合。
问题6:在之前的 QAT 量化中的 QDQ 操作中,从 f f f 到 q q q 再从 q q q 到 f ′ f' f′ 的过程中由于 round 操作会存在一定的误差,这个误差是不是我们所说的量化误差?我们的目的是不是使得量化误差最小?最终的目的是不是要找到合适的 scale 和 zero-point 使得它最小?
回答:
是的,你完全正确。
1. 量化误差:
- 当你使用线性量化从浮点数 f f f 转换为整数 q q q 并从 q q q 反量化回 f ′ f' f′ 时,由于 round 操作和量化本身的离散性, f ′ f' f′ 可能与原始的 f f f 不完全相同。这种差异被称为量化误差。
- 具体地说,量化误差是 f ′ − f f'-f f′−f。
2. 目标:
- 我们的确希望使量化误差尽可能小。这样,当我们运行量化模型时,它的输出与未量化模型的输出会非常接近,从而保持了模型的性能。
- 为了最小化这种误差,我们需要为每一层(或每个张量)找到合适的 scale 和 zero_point。这是校准步骤的主要目的,无论是在 PTQ 的上下文中还是在 QAT 的上下文中。
3. 如何选择 scale 和 zero_point:
- 选择合适的 scale 和 zero_point 可以确保原始浮点数据的大部分信息在量化后仍然得以保留。
- 对于非对称量化,选择 scale 和 zero_point 的目标是使浮点数据的范围尽可能地映射到整数的范围。
- 对于对称量化,只需选择合适的 scale,因为 zero_point 总是 0。
总之,量化误差是由于量化操作引入的误差,我们的目标确实是尽量减小这种误差。为此,我们需要为每个待量化的张量选择合适的 scale 和 zero_point。
问题7:之前我有学习过动态范围的常用计算方法,包括 Max 方法,Histogram 直方图统计方法,Entropy 方法,这些方法的目的是什么?它们是不是用来最小化量化误差的方法?还是说它们只是统计量化误差?它们在量化过程中又扮演了什么角色?
回答:
这些您提到的方法(Max、Histogram、Entropy)都是用于校准的方法,它们的主要目的是确定合适的 scale 和 zero_point,以便在量化过程中最小化量化误差。校准是量化流程中的一个关键步骤,尤其是在 Post-training Quantization (PTQ) 中。
1. Max 方法:
- 这是最简单的方法。它使用待量化数据的最大绝对值来确定 scale
- 例如,对于对称量化,如果 max_abs_value 是数据的最大绝对值,那么 scale 可能被设置为 max_abs_value/127(对于 int8)
- 尽管这种方法简单,但它可能不是最优的,因为它不考虑数据的整体分布
2. Histogram 方法:
- 在这种方法中,首先构建数据的直方图,然后确定一个量化范围,使得大部分数据都落在这个范围内
- 这样 scale 和 zero_point 可以根据这个范围来确定
- 直方图方法考虑了数据的整体分布,因此通常比 Max 方法更准确
3. Entropy 方法:
- 这种方法的目标是找到一个量化范围,使得量化数据的熵最大化。
- 熵是一个信息论的概念,表示随机变量的不确定性。通过最大化熵,我们尝试确保量化数据尽可能多地保留原始数据的信息。
- 这也是一种在数据的整体分布下选择 scale 和 zero_point 的方法。
在量化流程中,这些校准方法的角色是:
- 在 PTQ 中,首先运行模型的推理部分(使用校准数据集),收集需要量化的层的激活值。
- 使用上述方法之一(或其他方法)来确定每个层的 scale 和 zero_point。
- 使用确定的 scale 和 zero_point 进行实际的量化。
总之,这些方法的目的是确定合适的 scale 和 zero_point,从而最小化量化误差。它们不仅仅是统计量化误差,而是帮助我们在量化过程中做出最佳的决策。
问题8:PTQ 量化中是不是常常使用 Entropy 方法确定合适的 scale 和 zero-point,而 QAT 量化是不是没有用到这些方法,它是通过模型的训练来确定 scale 和 zero-point 的,和 PTQ 的方式完全不一样,是吗?还是说 QAT 量化中也会用到诸如直方图统计这种方法呢?
回答:
你的观点基本上是对的,但让我们更详细地探讨这两种方法。
PTQ (Post-training Quantization):
- 在 PTQ 中,模型首先完成训练,然后进行量化。
- 在校准步骤中,通常使用一种方法(如 Entropy、Histogram 或 Max)来确定合适的 scale 和 zero_point。其中,Entropy 方法是一个比较受欢迎的选择,因为它考虑了数据的整体分布。
- 这些方法都是基于校准数据集上的模型推理来进行的。
QAT (Quantization Aware Training):
- QAT 在训练过程中模拟量化的效果,从而允许模型适应量化误差。
- 由于量化是在训练过程中进行的,QAT 通常使用不同的策略来确定 scale 和 zero_point。例如,它们可能会动态地根据每个 mini-batch 的数据分布来调整,或使用移动平均来跟踪数据分布。
- 但是,QAT 也可以利用一些校准方法。例如,某些 QAT 实现可能会使用直方图统计或其他方法在训练的初期阶段为每一层确定一个初始的 scale 和 zero_point。然后,这些参数可以在训练过程中动态地进行微调。
总之,虽然 PTQ 和 QAT 在确定 scale 和 zero_point 时使用的策略确实存在差异,但两者并不是完全不同的。QAT 确实可以利用一些类似于 PTQ 中使用的校准方法,但通常这些方法在 QAT 中只是起到一个辅助或初始化的作用。
问题9:scale 和 zero-point 是通过 QDQ 节点加入到模型中进行训练的吗?它们也会参与神经网络的反向传播和梯度更新过程吗?
回答:
在 QAT (Quantization Aware Training) 中,scale 和 zero_point 确实可以被视为模型的参数,并可能在训练过程中被更新。但是,它们与模型的权重和偏置不完全相同,更新策略也可能有所不同。
1. QDQ 节点和训练:
- 在 QAT 过程中,模型中确实会插入 QDQ 节点或类似的量化/反量化操作来模拟量化的效果。
- 这些节点在前向传播中模拟量化操作,而在反向传播中,通常会使用直接的梯度或伪梯度来传递误差。
2. 更新 scale 和 zero_point:
- 有些 QAT 实现可能会选择固定 zero_point(特别是对于对称量化)并只更新 scale。
- 在训练过程中,scale 和 zero_point 的更新可能不会使用传统的梯度下降方法。相反,它们可能会基于统计方法(例如,移动平均或直方图统计)来动态调整。
- 但是,也有一些先进的 QAT 方法可能会将 scale 和 zero_point 作为可学习的参数,并使用梯度下降或其他优化算法进行更新。
3. 反向传播:
- 虽然 scale 和 zero_point 可能会在训练过程中被更新,但它们的更新通常是基于模型输出的量化误差或其他统计方法,而不是直接基于误差的梯度。
- 当模拟量化操作(如 QDQ 节点)在反向传播中遇到时,通常会使用直接的梯度或伪梯度来传递误差。这确保了量化误差被考虑在内,使得模型可以适应这些误差。
总的来说,虽然 scale 和 zero_point 可能会在 QAT 过程中被更新,但它们的更新策略与模型的其他参数可能有所不同。这些更新旨在最小化量化误差,从而在量化后保持模型的性能。
2. 不同精度模型对比
QAT 量化的模型性能到底怎么样呢?与其它精度的模型相比有哪些优势又有哪些劣势呢?
这个小节我们就来看看不同精度的模型的性能对比,主要从 mAP 和速度两个方面衡量。博主测试了在同一个验证集上原始 pytorch 模型,FP32 模型,FP16 模型,INT8 模型的性能。
原始 pytorch 模型和 INT8 模型性能我们之前已经了解过了,下面我们来看看 FP32 模型和 FP16 模型的性能。
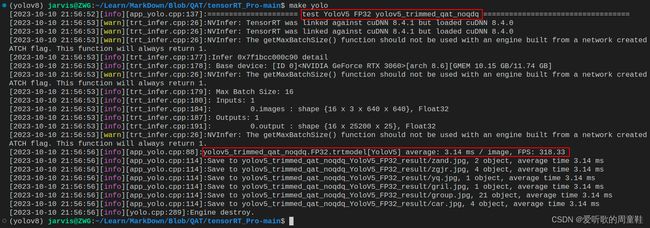
FP32模型:

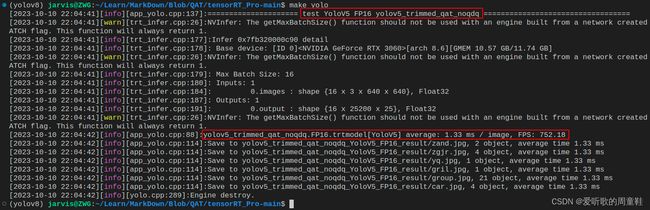
FP16模型:
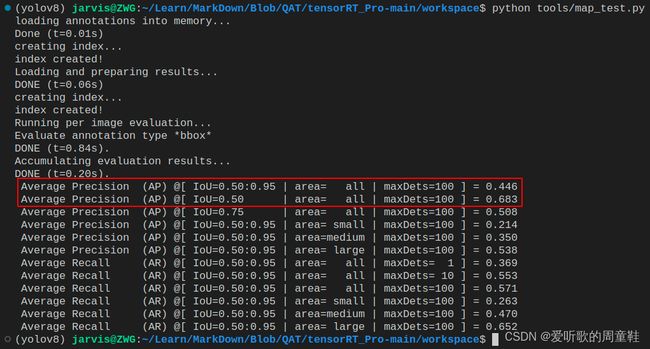
INT8模型:

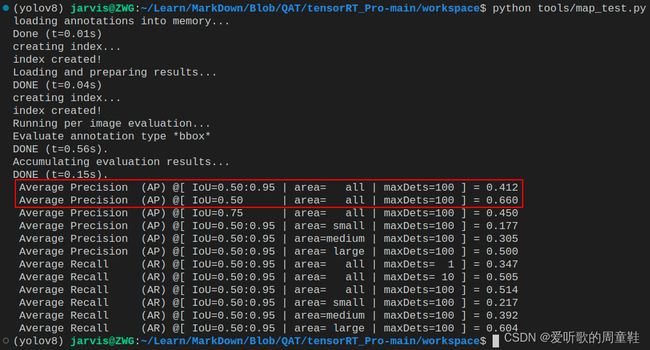
值得注意的是,关于速度的测试我们之前似乎并没有提到,它具体是如何测试的呢?
其实在 inference_and_performance 函数中就有关于速度相关的测试,主要说明如下:
- 1. 输入分辨率 640x640
- 2. batch_size = 1
- 3. 图像预处理 + 推理 + 后处理
- 4. CUDA-11.6,cuDNN-8.4.0,TensorRT-8.4.1.5
- 5. NVIDIA RTX3060
- 6. 测试次数,100 次取平均,去掉 warmup
- 7. 测试代码:src/application/app_yolo.cpp
- 8. 测试图像 6 张,位于 workspace/inference
- 分辨率分别为:810x1080,500x806,1024x684,550x676,1280x720,800x533
- 9. 测试方式,加载 6 张图后,以原图重复 100 次不停的塞进去。让模型经历完整的图像的预处理,后处理
测试结果如下表所示:
| Model | Precision | mAPval 0.5:0.95 |
mAPval 0.5 |
Elapsed Time/ms | FPS |
|---|---|---|---|---|---|
| YOLOv5s.pt | - | 0.471 | 0.711 | - | - |
| YOLOv5s-FP32 | FP32 | 0.447 | 0.683 | 3.14 | 318.33 |
| YOLOv5s-FP16 | FP16 | 0.446 | 0.683 | 1.33 | 752.18 |
| YOLOv5s-INT8 | INT8 | 0.412 | 0.660 | 0.99 | 1006.86 |
可视化图如下所示:
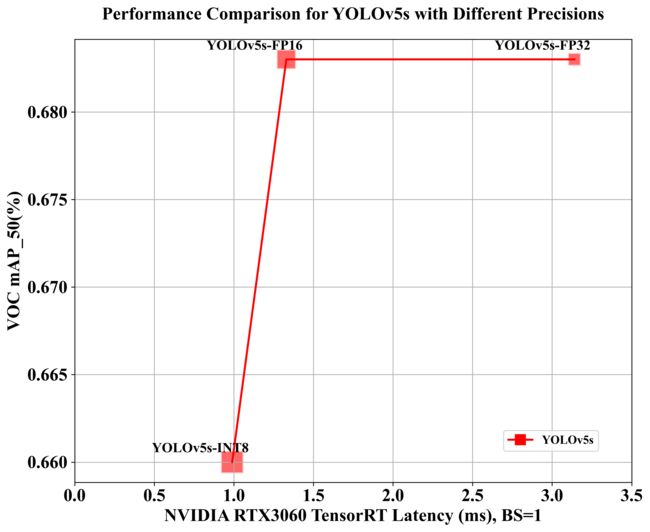
从表中的数据我们可以分析得到下面的一些结论:
1. 精度与模型性能的关系
- 当我们从原始 pytorch 模型转到 FP32 模型时,正常来说应该基本是无损的,但是 mAP 掉了将近 3 个点左右,这并不符合我们的直觉。
- mAP 差 3 个点的原因可能是在固定分辨率这件事上,tensorRT 将图片分辨率固定在 640x640 大小。还有就是 pytorch 实现的所有细节并未完全加入进来,这些细节可能有没有找到的部分。
- FP32 模型和 FP16 模型的 mAP 几乎一样,没有任何精度的损失,这倒是符合我们的直觉
2. 速度与模型性能的关系
- FP16 和 INT8 的 FPS 分别为 752.18 和 1006.86,远高于 FP32 的 318.33
- INT8 模型是所有模型中最快的,达到了 1000 FPS 的速度,尽管其精度稍低。
3. 权衡速度与精度
- FP32 提供了较好的精度,但速度较慢
- FP16 提供了与 FP32 类似的精度,但速度提高了约 2.4 倍,是一个非常不错的选择。
- INT8 提供了略低的精度,但速度却是最快的,比 FP32 快约 3 倍。
综上所述,在实际应用中,需要根据具体的需求权衡速度和精度。例如,对于实时应用,可能会选择 FP16 或 INT8 以获得更高的速度,尽管可能牺牲一些精度。而对于需要高精度的应用,可能会选择 FP32。
3. QAT方案对比
我们在前面不是提供了 QAT 量化的两种方案嘛,一种是按照 TensorRT 中的建议放置 Q/DQ 节点,另一种是在每一层都插入 Q/DQ 节点。这两种方案哪种更好呢?在速度和精度方面有什么差异呢?
这个小节我们就来看看两种方案生成的 INT8 模型的性能对比,主要从 mAP 和速度两个方面衡量。博主测试了在同一个验证集上方案一和方案二生成的 INT8 模型性能。
注:这里采用的模型均是通过 trtexec 生成的 INT8 模型,为什么要强调这点呢?是因为 trtexec 直接生成的 INT8 模型和 tensorRT_Pro 生成的 INT8 模型的推理速度存在较大差异,具体可参考第 5 小节的内容。
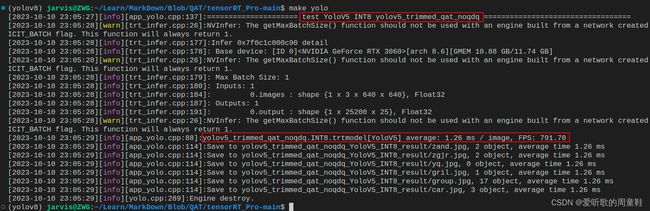
方案一:

方案二:
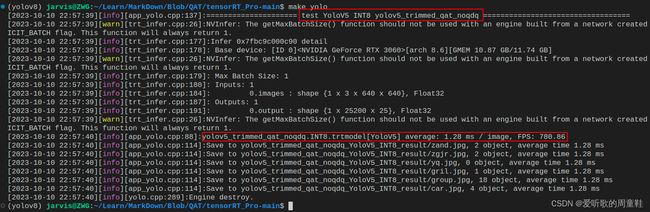
测试结果如下表所示:
| Method | Model | Precision | mAPval 0.5:0.95 |
mAPval 0.5 |
Elapsed Time/ms | FPS |
|---|---|---|---|---|---|---|
| 一 | YOLOv5s | INT8 | 0.412 | 0.660 | 1.26 | 791.78 |
| 二 | YOLOv5s | INT8 | 0.423 | 0.667 | 1.28 | 780.86 |
可视化图如下所示:

从表中的数据我们可以分析得到下面的结论:
1. 精度的对比:
- mAP 是衡量目标检测模型性能的常见指标,值越高表示模型的性能越好
- 对于 [email protected]:0.95 方案二比方案一要高出 1 个点左右,对于 [email protected] 方案二比方案一高出 0.7 个点
2. 速度的对比
- FPS 表示模型每秒可以处理的帧数,值越高表示模型的实时性越好
- 方案二比方案一推理时间快了约 0.02ms 左右,这可能是由于设备的波动引起的,实际上二者推理时间应该并无太大差异
如果速度是由波动引起的,那是不是意味着无脑选择方案二呢?毕竟同等速度下其 mAP 还要高
4. PTQ vs. QAT
PTQ 量化和 QAT 量化生成的 INT8 模型哪个更好呢?我们该选择哪种量化方式呢?
这个小节我们就来看看 PTQ 量化和 QAT 量化后的 INT8 模型性能对比,主要从 mAP 和速度两个方面衡量。
值得注意的是,博主在上篇文章使用 PTQ 量化的 pytorch 模型和本篇文章使用 QAT 量化的 pytorch 模型是同一个,因此我们直接把上篇文章的结果拿过来对比就行。
注:这里采用的模型均是通过 tensorRT_Pro 生成的 INT8 模型,为什么要强调这点呢?是因为 trtexec 直接生成的 INT8 模型和 tensorRT_Pro 生成的 INT8 模型的推理速度存在较大差异,具体可参考第 5 小节的内容。
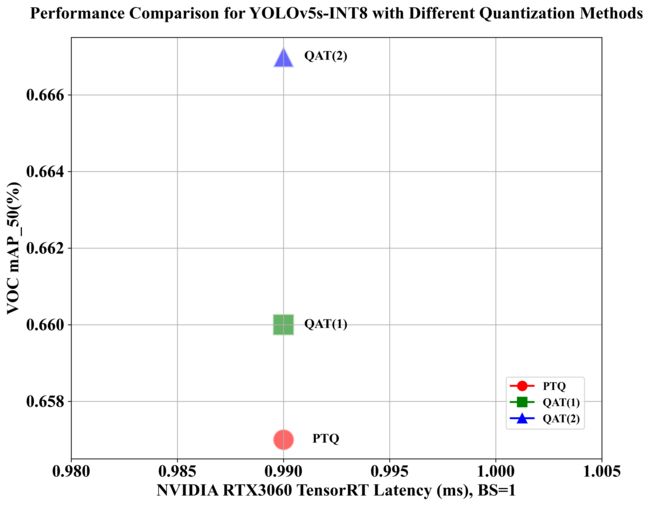
测试结果如下表所示:
| Model | Method | mAPval 0.5:0.95 |
mAPval 0.5 |
Elapsed Time/ms | FPS |
|---|---|---|---|---|---|
| YOLOv5s-INT8 | PTQ | 0.409 | 0.657 | 0.99 | 1008.93 |
| YOLOv5s-INT8 | QAT(一) | 0.412 | 0.660 | 0.99 | 1006.86 |
| YOLOv5s-INT8 | QAT(二) | 0.423 | 0.667 | 0.99 | 1007.13 |
可视化图如下所示:
从表中的数据我们可以分析得到下面的结论:
1. 量化方式与精度的关系
- QAT(一) 与 PTQ 量化方式生成的 INT8 模型在 mAP 上的差异相对较小
- QAT(二) 相比 PTQ 量化方式有轻微的优势,[email protected]:0.95 提升了 1.4 个点,[email protected] 提升了 1 个点。[email protected]:0.95 提升了更明显的原因可能是在 QAT 量化训练时我们是根据 [email protected]:0.95 指标来选择 QAT 模型的。
2. 量化方式与速度的关系
- 在推理速度上,不同量化方式的模型表现相当,几乎没有差距
- 可能是因为针对 YOLOv5s 模型而言,PTQ 和 QAT 量化的层基本上差不多,只是获取的量化信息不尽相同
3. 量化方式的选择
- PTQ 量化作为一个后训练量化方法,提供了与 QAT 接近的性能,但其实现相对简单,因为它不需要训练过程,只需要准备校准图片即可。
- QAT 量化尽管其实现可能比 PTQ 更复杂,但提供了稍微好一点的 mAP。因此,如果追求更高的精度,并且愿意投入更多的时间和资源进行训练,QAT 量化是一个更好的选择。
QAT 实际效果和博主想象的还是有些差距,原本以为 QAT 量化训练后的 INT8 模型的 mAP 会与 FP32 模型相当,实际上并没有,也不清楚是不是博主某些操作没做或者没做对。
但是有一个比较好的点就是 QAT 量化训练后生成的 INT8 模型可以手动去控制每一层的精度,不至于完全不可控。另外也不需要去考虑 PTQ 模型的校准图片数量选取,某种意义上是进阶版的 PTQ,只是实现的方式和流程略微复杂了点。
5. INT8模型生成方式对比
我们在前面不是提供了 INT8 模型生成的两种方式嘛,一种是根据 trtexec 指令生成,另一种是通过 tensorRT_Pro 提供对应的 ONNX 模型和校准缓存文件,这两种方式生成的 INT8 模型在速度和精度上会存在差异吗?
这个小节我们就来看看两种方式生成的 INT8 模型性能对比,主要从 mAP 和速度两个方面衡量。
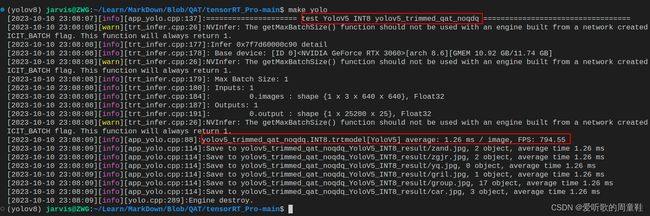
trtexec:

tensorRT_Pro:
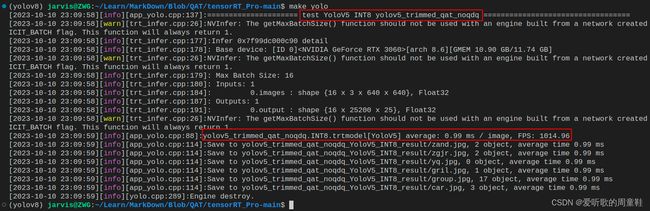
测试结果如下表所示:
| Method | Model | mAPval 0.5:0.95 |
mAPval 0.5 |
Elapsed Time/ms | FPS |
|---|---|---|---|---|---|
| trtexec | YOLOv5s-QAT-INT8 | 0.412 | 0.660 | 1.26 | 794.55 |
| tensorRT_Pro | YOLOv5s-QAT-INT8 | 0.412 | 0.660 | 0.99 | 1014.96 |
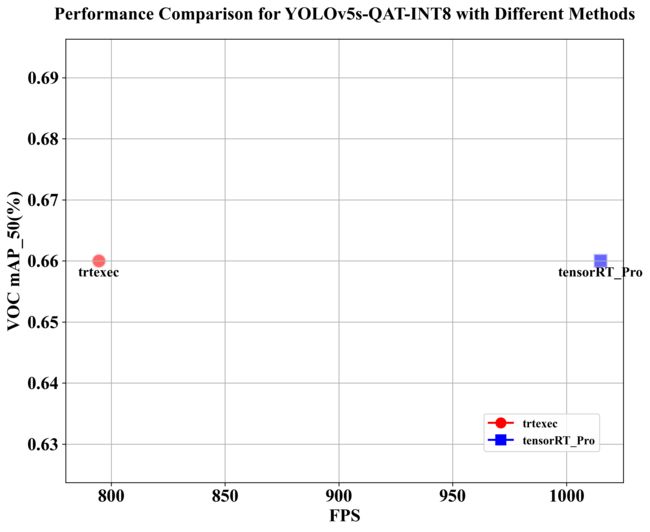
可视化图如下所示:
从表中的数据我们可以分析得到下面的结论:
1. 精度的一致性
- 两种方式生成的 INT8 模型性能无差异,这说明这两种方式生成的 INT8 模型对精度不会产生影响
2. 速度的差异性
- 从 FPS 来看,tensorRT_Pro 方法生成的 INT8 模型达到了 1014.96 FPS,而 trtexec 方法生成的模型仅为 794.55 FPS,约高出 28%。
- 这说明这两种方式生成的 INT8 模型在 tensorRT_Pro 中的推理速度有较大影响
- 这可能是由于 trtexec 指令中指定了 –fp16 参数,允许某些层运行时采用 FP16 精度模式
速度测试差距还是比较大的,博主也没有找到具体的原因是什么。两种方式都是采用的同一个 ONNX 模型和同一个校准文件,按理来说应该没有差距才对。
tensorRT_Pro 中模型的构建是通过底层的 C++ API 去调用 buildEngineWithConfig 函数完成的,有一些 IBuilderConfig 配置可能与 trtexec 指令有出入。还有一些细节实现博主可能没有关注到。
OK!以上就是本篇文章的全部内容了,有问题欢迎各位看官交流讨论。
结语
本篇博客介绍了关于 yolov5 的 QAT 量化以及部署流程,博主在这里只做了最基础的演示,有些实现并没有完全按照 cuDLA-samples 来做,各位看官感兴趣的话可以自行测试。感谢各位看到最后,创作不易,读后有收获的看官帮忙点个⭐️
下载链接
- 软件安装包下载链接【提取码:yolo】
- 源代码、权重、数据集下载链接【提取码:yolo】
参考
- COCO Python API
- tensorRT模型性能测试
- 如何熟练的使用trtexec
- Ubuntu20.04部署YOLOv5
- TensorRT量化第四课:PTQ与QAT
- 目标检测mAP计算以及coco评价标准
- 目标检测:PASCAL VOC 数据集简介
- https://github.com/ultralytics/yolov5
- https://github.com/shouxieai/tensorRT_Pro
- https://github.com/NVIDIA-AI-IOT/cuDLA-samples
- 利用Anaconda安装pytorch和paddle深度学习环境+pycharm安装—免额外安装CUDA和cudnn(适合小白的保姆级教学)