PSANet: 场景解析的逐点空间注意力网络_PSANet:Point-wise Spatial Attention Network for Scene Parsing
0.摘要
由于卷积滤波器的物理设计限制,我们注意到卷积神经网络中的信息流只在局部邻域内流动,这限制了对复杂场景的整体理解。在本文中,我们提出了逐点空间注意力网络(PSANet)来放宽局部邻域的限制。特征图上的每个位置通过自适应学习的注意力掩码与所有其他位置相连。此外,我们还开启了双向信息传播用于场景解析。其他位置的信息可以帮助当前位置的预测,反之亦然,当前位置的信息可以分布到其他位置来帮助它们的预测。我们提出的方法在多个竞争的场景解析数据集上取得了最好的性能,包括ADE20K、PASCAL VOC 2012和Cityscapes,证明了其有效性和通用性。
关键词:逐点空间注意力,双向信息流动,自适应上下文聚合,场景解析,语义分割。
1.引言
场景解析,又称语义分割,是计算机视觉中的一个基础且具有挑战性的问题,它将每个像素分配给一个类别标签。它是实现视觉场景理解的关键步骤,在自动驾驶和机器人导航等应用中起着重要作用。强大的深度卷积神经网络(CNN)的发展在场景解析方面取得了显著的进展[26、1、29、4、5、45]。由于CNN结构的设计,其感受野局限于局部区域[47、27]。有限的感受野对于基于全卷积网络(FCN)的场景解析系统来说产生了严重的不利影响,因为它对周围上下文信息的理解不足。
为了解决这个问题,尤其是利用长程依赖,已经进行了一些修改。[4,42]提出了通过膨胀卷积来进行上下文信息的聚合。将膨胀引入到经典的紧凑卷积模块中,以扩大感受野。通过池化操作也可以实现上下文信息的聚合。ParseNet中的全局池化模块[24]、DeepLab中基于不同膨胀率的空洞空间金字塔池化(ASPP)模块[5]、PSPNet中基于不同区域的金字塔池化模块(PPM)[45]可以在一定程度上提取上下文信息。与这些扩展不同的是,还利用了条件随机场(CRF)[4,46,2,3]和马尔可夫随机场(MRF)[25]。此外,ReSeg中引入了循环神经网络(RNN)[38],因为它具有捕捉长程依赖关系的能力。然而,这些基于膨胀卷积[4,42]和基于池化[24,5,45]的扩展以非自适应的方式利用了图像区域的同质上下文依赖,忽略了不同类别的局部表示和上下文依赖的差异。而基于CRF/MRF[4,46,2,3,25]和基于RNN[38]的扩展效率较低,不如基于CNN的框架高效。
在本论文中,我们提出了点级空间注意力网络(PSANet),以灵活和自适应的方式聚合长程上下文信息。特征图中的每个位置通过自适应预测的注意力图与所有其他位置相连,从而收集附近和远处的各种信息。此外,我们设计了双向信息传播路径,以全面理解复杂场景。每个位置都从所有其他位置收集信息,以帮助自身的预测,反之亦然,每个位置的信息可以在全局范围内分布,有助于其他所有位置的预测。最后,将双向汇总的上下文信息与局部特征融合,形成复杂场景的最终表示。我们的PSANet在三个竞争激烈的语义分割数据集上取得了最佳性能,即ADE20K [48],PASCAL VOC 2012 [9]和Cityscapes [8]。我们相信,我们提出的点级空间注意力模块以及双向信息传播范式也可以有益于其他密集预测任务。我们提供了所有实施细节,并向社区公开提供了代码和训练模型1。我们的主要贡献有三个方面: - 通过学习的点级位置敏感的上下文依赖关系和双向信息传播范式,实现了对场景解析的长程上下文聚合。 - 我们提出了点级空间注意力网络(PSANet),以从特征图中的所有位置提取上下文信息。每个位置通过自适应学习的注意力图与所有其他位置相连。 - PSANet在各种竞争激烈的场景解析数据集上取得了最佳性能,证明了其有效性和普适性。
2.相关工作
最近,在场景解析和语义分割任务中,基于CNN的方法[26,4,5,42,45,6]取得了显著的成功。FCN [26]是第一种将分类网络中的全连接层替换为卷积层以进行语义分割的方法。DeconvNet [29]和SegNet [1]采用了编码器-解码器结构,利用低层次的信息来帮助细化分割掩模。扩张卷积 [4,42]在特征图上应用跳跃卷积来扩大网络的感受野。UNet [33]将低层次的输出与高层次的输出进行拼接,以进行信息融合。DeepLab [4]和CRF-RNN [46]利用CRF进行场景解析中的结构预测。DPN [25]利用MRF进行语义分割。LRR [11]和RefineNet [21]采用逐步重建和细化的方法来获取解析结果。PSPNet [45]通过金字塔池化策略实现了高性能。还有像ENet [30]和ICNet [44]这样的高效框架用于实时应用,如自动驾驶。
上下文信息聚合。上下文信息在图像理解中起着关键作用。扩张卷积 [4,42]将扩张插入到经典卷积核中,以扩大CNN的感受野。全局池化在各种基本的分类骨干网络 [19,35,36,13,14]中被广泛采用,用于获取全局表示的上下文信息。Liu等人提出了ParseNet [24],利用全局池化来聚合场景解析的上下文信息。陈等人开发了ASPP [5]模块,赵等人提出了PPM [45]模块,以获取不同区域的上下文信息。Visin等人提出了ReSeg [38],利用RNN捕捉长程上下文依赖信息。
注意力机制。注意力机制被广泛应用在神经网络中。Mnih等人[28]学习了一个自适应选择一系列区域或位置进行处理的注意力模型。陈等人[7]学习了几个注意力掩码,用于融合来自不同分支的特征图或预测结果。Vaswani等人[37]学习了一个自注意力模型,用于机器翻译。Wang等人[40]通过计算特征图中每个空间点之间的相关矩阵得到了注意力掩码。我们的点级注意力掩码与上述研究不同。具体来说,通过我们的PSA模块学习到的掩码是自适应的,并且对位置和类别信息敏感。PSA学习了使每个点自适应地聚合上下文信息的能力。
3.框架
为了捕捉上下文信息,特别是在长程上下文中,信息聚合对于场景解析[24,5,45,38]非常重要。在本文中,我们将信息聚合步骤形式化为一种信息流,并提出从两个角度自适应地学习每个位置的像素级全局注意力图,以在整个特征图上聚合上下文信息。
3.1.公式化
将通用特征学习或信息聚合建模为
 其中zi是在位置i上新聚合的特征,xi是输入特征图X中位置i处的特征表示。∀j∈Ω(i)枚举与i相关的感兴趣区域中的所有位置,∆ij表示位置i和j之间的相对位置。F(xi,xj,∆ij)可以是任何函数或根据操作进行学习的参数,它表示从j到i的信息流。注意,通过考虑相对位置∆ij,F(xi,xj,∆ij)对不同的相对位置敏感。这里的N是用于归一化的。具体来说,我们简化了公式并针对不同的相对位置设计了不同的函数F。公式(1)更新为...
其中zi是在位置i上新聚合的特征,xi是输入特征图X中位置i处的特征表示。∀j∈Ω(i)枚举与i相关的感兴趣区域中的所有位置,∆ij表示位置i和j之间的相对位置。F(xi,xj,∆ij)可以是任何函数或根据操作进行学习的参数,它表示从j到i的信息流。注意,通过考虑相对位置∆ij,F(xi,xj,∆ij)对不同的相对位置敏感。这里的N是用于归一化的。具体来说,我们简化了公式并针对不同的相对位置设计了不同的函数F。公式(1)更新为... 其中{F∆ij}是一组特定位置的函数。它模拟了从位置j到位置i的信息流。请注意,函数F∆ij(·,·)将源信息和目标信息作为输入。当特征图中有许多位置时,组合(xi,xj)的数量非常大。在本文中,我们简化了公式并进行了近似处理。首先,我们将函数F∆ij(·,·)简化为...
其中{F∆ij}是一组特定位置的函数。它模拟了从位置j到位置i的信息流。请注意,函数F∆ij(·,·)将源信息和目标信息作为输入。当特征图中有许多位置时,组合(xi,xj)的数量非常大。在本文中,我们简化了公式并进行了近似处理。首先,我们将函数F∆ij(·,·)简化为...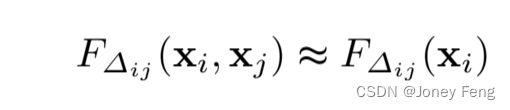
在这个近似中,从j到i的信息流仅与目标位置i的语义特征和i和j的相对位置有关。基于公式(3),我们将公式(2)重写为...
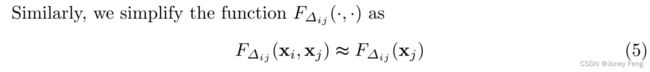 其中从j到i的信息流只与源位置j的语义特征和位置i和j的相对位置有关。最终,我们将函数分解和简化为一个双向信息传播路径。结合公式(3)和公式(5),我们得到...
其中从j到i的信息流只与源位置j的语义特征和位置i和j的相对位置有关。最终,我们将函数分解和简化为一个双向信息传播路径。结合公式(3)和公式(5),我们得到... 对于第一项,F∆ij(xi)编码了其他位置的特征在预测中起到的作用。每个位置从其他位置“收集”信息。对于第二项,F∆ij(xj)预测了一个位置的特征对其他位置的重要性。每个位置将信息“分发”给其他位置。图1展示了这种双向信息传播路径,使网络能够学习更全面的表示,这在我们的实验部分有证据支持。具体而言,我们的PSA模块旨在自适应地预测整个特征图上的信息传递,将特征图中的所有位置作为Ω(i),并利用卷积层作为F∆ij(xi)和F∆ij(xj)的操作。F∆ij(xi)和F∆ij(xj)都可以被视为预测的注意力值,用于聚合特征xj。我们进一步将公式(7)重写为...
对于第一项,F∆ij(xi)编码了其他位置的特征在预测中起到的作用。每个位置从其他位置“收集”信息。对于第二项,F∆ij(xj)预测了一个位置的特征对其他位置的重要性。每个位置将信息“分发”给其他位置。图1展示了这种双向信息传播路径,使网络能够学习更全面的表示,这在我们的实验部分有证据支持。具体而言,我们的PSA模块旨在自适应地预测整个特征图上的信息传递,将特征图中的所有位置作为Ω(i),并利用卷积层作为F∆ij(xi)和F∆ij(xj)的操作。F∆ij(xi)和F∆ij(xj)都可以被视为预测的注意力值,用于聚合特征xj。我们进一步将公式(7)重写为... 其中ac i, c i,j和ad i,j分别表示来自“collect”和“distribute”分支的点级注意力图Ac和Ad中的预测注意力值。
其中ac i, c i,j和ad i,j分别表示来自“collect”和“distribute”分支的点级注意力图Ac和Ad中的预测注意力值。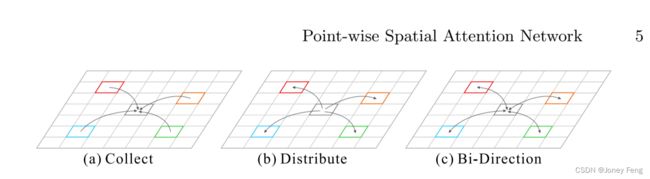 图1.双向信息传播模型的示意图。每个位置都“收集”和“分发”信息,以实现更全面的信息传播。
图1.双向信息传播模型的示意图。每个位置都“收集”和“分发”信息,以实现更全面的信息传播。
3.2.概述
我们在图2中展示了PSA模块的框架。PSA模块以空间特征图X作为输入。我们将X的空间大小表示为H×W。通过两个分支生成每个特征图位置的像素级全局注意力图,通过几个卷积层。根据公式(8),我们根据注意力图聚合输入特征图,生成与长程上下文信息结合的新特征表示,即来自“collect”分支的Zc和来自“distribute”分支的Zd。我们将新的表示Zc和Zd连接起来,并应用一个带有批量归一化和激活层的卷积层进行降维和特征融合。然后,我们将新的全局上下文特征与局部表示特征X连接起来。接下来是一个或多个带有批量归一化和激活层的卷积层,生成用于后续子网络的最终特征图。需要注意的是,我们提出的PSA模块中的所有操作都是可微分的,并且可以与网络的其他部分一起进行端到端的联合训练。它可以灵活地附加到网络中的任何特征图上。通过为每个位置预测上下文依赖关系,它能够自适应地聚合适当的上下文信息。在下面的子节中,我们详细介绍生成两个注意力图Ac和Ad的过程。
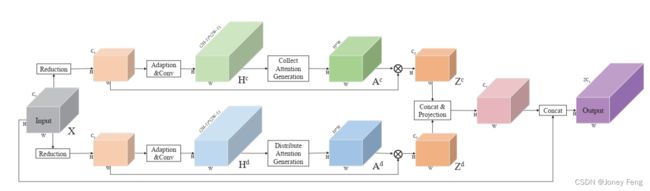 图2.提出的PSA模块的架构
图2.提出的PSA模块的架构
3.3.驻点空间注意力
网络结构。PSA模块首先通过两个并行分支生成两个点级空间注意力图,即Ac和Ad。尽管它们代表了不同的信息传播方向,但网络结构完全相同。如图2所示,在每个分支中,我们首先使用1×1卷积层来减少输入特征图X的通道数,以减少计算开销(即图2中的C2 < C1)。然后,再应用一个1×1卷积层进行特征适应。这些层都使用了批量归一化和激活层。最后,一个卷积层负责为每个位置生成全局注意力图。
与为每个位置i预测一个大小为H×W的图相反,我们预测一个超完备的图,即大小为(2H-1)×(2W-1),覆盖输入特征图。结果是,对于特征图X,我们得到一个临时表示图H,其空间大小为H×W,通道数为(2H-1)×(2W-1)。如图3所示,对于每个位置i,hi可以重塑为一个以位置i为中心,具有2H-1行和2W-1列的空间图,其中只有H×W个值在特征聚合中有用。在图3中,有效区域用虚线边界框突出显示出来。通过我们的实例化,用于预测不同位置的注意力图的滤波器集并不相同。这使得网络能够通过调整权重来对相对位置敏感。实现这个目标的另一个实例化方法是使用全连接层将输入特征图和预测的像素级注意力图连接起来。但这会导致参数数量巨大。
注意力图生成。基于来自“collect”分支的预测超完备图Hc和来自“distribute”分支的Hd,我们进一步生成注意力图Ac和Ad。在“collect”分支中,对于每个位置i,具有k行l列,我们根据位置i处的特征预测当前位置与其他位置的关联性。因此,ac i对应于hc i中从(H-k)行(W-l)列开始的H行W列的区域。具体而言,在注意力掩码ac i中,第s行第t列的元素,即ac [k,l]is![]() 其中[·,·]是行和列的索引。这个注意力图有助于收集其他位置的有信息性的内容,以使当前位置的预测受益。另一方面,我们将当前位置的信息分发到其他位置。在每个位置,我们预测当前位置对其他位置的信息的重要性。ad i的生成方式与ac i类似。这个注意力图有助于分发信息,以实现更好的预测。这两个注意力图以互补的方式编码了不同位置对之间的上下文依赖关系,从而实现了改进的信息传播和增强了对长程上下文的利用。利用这两种不同的注意力的好处在实验中得到了体现。
其中[·,·]是行和列的索引。这个注意力图有助于收集其他位置的有信息性的内容,以使当前位置的预测受益。另一方面,我们将当前位置的信息分发到其他位置。在每个位置,我们预测当前位置对其他位置的信息的重要性。ad i的生成方式与ac i类似。这个注意力图有助于分发信息,以实现更好的预测。这两个注意力图以互补的方式编码了不同位置对之间的上下文依赖关系,从而实现了改进的信息传播和增强了对长程上下文的利用。利用这两种不同的注意力的好处在实验中得到了体现。 图3.点级空间注意力的说明。
图3.点级空间注意力的说明。 图4.将PSA模块与ResNet-FCN主干网络结合的网络结构。采用深度监督以获得更好的性能。
图4.将PSA模块与ResNet-FCN主干网络结合的网络结构。采用深度监督以获得更好的性能。
3.4.PSA模块与FCN的结合
我们的PSA模块是可扩展的,并可以附加到FCN结构的任何阶段。我们在图4中展示了我们的实例化。给定一个输入图像I,我们通过FCN获取其局部表示作为特征图X,该特征图是PSA模块的输入。与[45]中的方法相同,我们将ResNet [13]作为FCN的主干网络。我们提出的PSA模块用于从局部表示中聚合长程的上下文信息。它遵循ResNet的第五阶段,这是FCN主干网络的最后阶段。第五阶段的特征具有更强的语义。将它们聚合在一起可以更全面地表示长程的上下文。此外,第五阶段的特征图的空间大小较小,可以减少计算开销和内存消耗。参考[45],我们还采用相同的深度监督技术。在图4中,除了主要的损失之外,还应用了辅助损失分支。
3.5.讨论
已经有研究利用上下文信息进行场景解析。然而,广泛使用的空洞卷积[4,42]利用固定的稀疏网格来操作特征图,失去了利用整个图像信息的能力。而池化策略[24,5,45]在每个位置以固定权重捕捉全局上下文,但不能适应输入数据,具有较少的灵活性。最近提出的非局部方法[40]通过计算输入特征图上每对位置之间语义特征的相关性来编码全局上下文,忽略了这两个位置之间的相对位置。与这些解决方案不同,我们的PSA模块通过卷积层自适应地为输入特征图上的每个位置预测全局注意力图,并考虑相对位置。此外,可以从两个不同的角度预测注意力图,以捕捉位置之间不同类型的信息流动。正如图1所示,这两个注意力图实际上构建了双向信息传播路径。它们在整个特征图上收集和分发信息。在这方面,全局池化技术只是我们PSA模块的一种特殊情况。因此,我们的PSA模块能够有效地捕捉长程上下文信息,适应输入数据并利用多样的注意力信息,从而实现更准确的预测。
4.实验评估
提出的PSANet在场景解析和语义分割任务上是有效的。我们在三个具有挑战性的数据集上评估我们的方法,包括复杂场景理解数据集ADE20K [48],对象分割数据集PASCAL VOC 2012 [9]和城市场景理解数据集Cityscapes [8]。接下来,我们首先展示与训练策略和超参数相关的实现细节,然后展示相应数据集上的结果,并可视化PSA模块生成的学习掩码。
4.1.实现细节
我们基于Caffe [15]进行实验。在训练过程中,我们将小批量大小设置为16,使用同步批量归一化,并将基础学习率设置为0.01。遵循之前的工作[5,45],我们采用了“poly”学习率策略,幂次设置为0.9。对于ADE20K数据集的实验,我们将最大迭代次数设置为150K,对于VOC 2012数据集设置为30K,对于Cityscapes数据集设置为90K。动量和权重衰减分别设置为0.9和0.0001。对于数据增强,我们对所有数据集都采用了随机镜像和随机调整大小,大小范围为0.5到2之间。我们还对ADE20K和VOC 2012数据集添加了额外的随机旋转范围为-10到10度和随机高斯模糊。
4.2.ADE20K
场景解析数据集ADE20K [48]具有最多150个类别和多样的复杂场景,包括1038个图像级别的类别。该数据集被划分为20K/2K/3K用于训练、验证和测试。对于该数据集,需要对对象和场景进行解析。在评估指标方面,采用了类别间交并比的平均值(Mean IoU)和像素级准确率(Pixel Acc.)。
信息聚合方法的比较。我们在ADE20K的验证集上比较了几种不同的信息聚合方法在两个不同的网络骨干(ResNet-50和ResNet-101)上的性能。实验结果列在表1中。我们的基准网络是基于ResNet的FCN,其中在第4和5阶段引入了空洞卷积模块,即这两个阶段的空洞率分别设置为2和4。
基于FCN提取的特征图,DenseCRF [18]只能带来轻微的改善。全局池化[24]是一种简单直观的尝试,用于获取长程上下文信息,但它以相同的方式对待特征图上的每个位置。金字塔结构[5,45]通过多个分支可以捕捉不同尺度的上下文信息。另一种选择是为特征图中的每个位置使用注意力掩码。在[40]中采用了一种非局部方法,其中通过计算每对位置之间的特征相关性来生成每个位置的注意力掩码。在我们的PSA模块中,除了为每个点生成独特的注意力掩码外,我们的点级掩码是通过卷积操作进行自适应学习的,而不是简单地采用非局部方法[40]中的矩阵乘法。与这些信息聚合方法相比,我们的方法表现更好,这表明PSA模块在捕捉长程上下文信息方面是更好的选择。
我们进一步探索了PSA模块中的两个分支。以ResNet50为例,在表1中,在“collect”模式下的信息流(标记为“+COLLECT”),我们的单尺度测试结果在Mean IoU和像素准确率方面分别达到了41.27/79.74% ,超过基线方法4.04/1.73个百分点。这一显著改进证明了我们提出的PSA模块的有效性,即使在简化版本中仅具有单向信息流。在我们的双向信息流模型(标记为“+COLLECT +DISTRIBUTE”)中,性能进一步提高至41.92/80.17%,在绝对改进上超过基线模型4.69/2.16个百分点,在相对改进上超过基线模型12.60/2.77个百分点。这种改进只是针对骨干网络而言。这表明两个信息传播路径都是有效且互补的。此外,请注意我们的位置敏感掩码生成策略对我们的高性能发挥了关键作用。标记为“(compact)”的方法意味着使用尺寸为H×W的紧凑掩码生成,而不是使用加倍尺寸的过完备掩码,忽略相关位置信息。如果考虑相对位置,则性能更高。然而,"compact" 方法的性能优于“non-local”方法,这也表明了从特征图中自适应学习的长程依赖性比从特征相关性计算得到的更好。
方法比较。我们在表2中展示了我们的方法与其他方法的比较。在相同的网络骨干下,PSANet的性能比RefineNet [21]和PSPNet [45]更高。PSANet50甚至在骨干网络更深的情况下也优于以ResNet-152为骨干的RefineNet。它稍微优于使用称为Wider ResNet的强大骨干的WiderNet [41]。视觉改进。我们在图5中展示了分割结果的视觉比较。PSANet显著提高了分割质量,与没有PSA模块的情况相比,生成了更准确、更详细的预测。我们在补充材料中包含了PSANet与其他方法之间的更多视觉比较。
表1.不同方法下的上下文信息聚合。结果在ADE20K数据集的验证集上报告。“SS”代表单尺度测试,“MS”表示采用多尺度测试策略。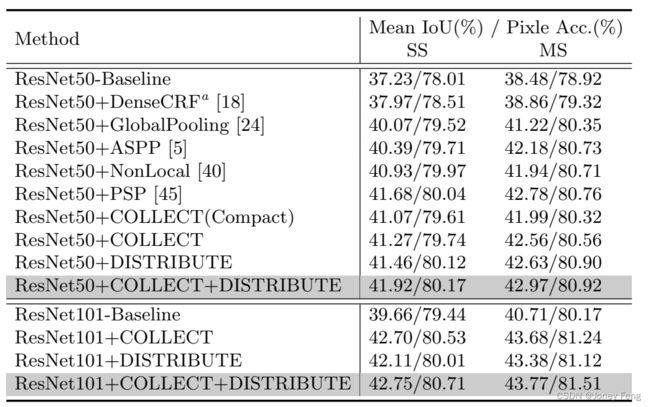 表2.在ADE20K验证集上报告的方法比较。
表2.在ADE20K验证集上报告的方法比较。
表3.在VOC 2012测试集上报告的方法比较。
4.3.PASCAL VOC2012
ASCAL VOC 2012语义分割数据集[9]是面向对象的分割任务,包含20个对象类别和一个背景类别。我们采用了来自[12]的扩充注释,用于训练、验证和测试,分别得到了10,582张、1,449张和1,456张图像。如表4所示,我们引入的PSA模块对于对象分割也非常有效。它大大提升了性能,远远超过了基线方法。与[4,5,45,6]的方法相似,我们还在MS-COCO [23]数据集上进行了预训练,然后在VOC数据集上进行了微调。表3列出了不同框架在VOC 2012测试集上的性能表现,PSANet实现了最佳性能。视觉改进显而易见,如附加材料中所示。同样地,引入PSA模块可以得到更好的预测结果。 图5.在ADE20K验证集上的视觉改进。提出的PSANet获得更准确和详细的解析结果。“PSA-COL”表示带有“COLLECT”分支的PSANet,“PSA-COL-DIS”表示双向信息流模式,进一步增强了预测。
图5.在ADE20K验证集上的视觉改进。提出的PSANet获得更准确和详细的解析结果。“PSA-COL”表示带有“COLLECT”分支的PSANet,“PSA-COL-DIS”表示双向信息流模式,进一步增强了预测。
表4.由PSA模块引入的改进。结果在VOC 2012数据集的训练扩充集上训练,验证集上评估。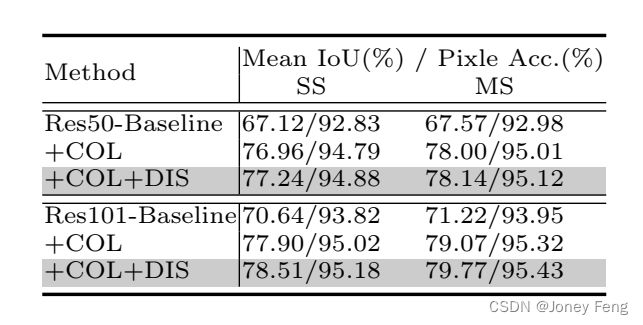
表5.由PSA模块引入的改进。结果在Cityscapes数据集的训练集和验证集上训练和评估。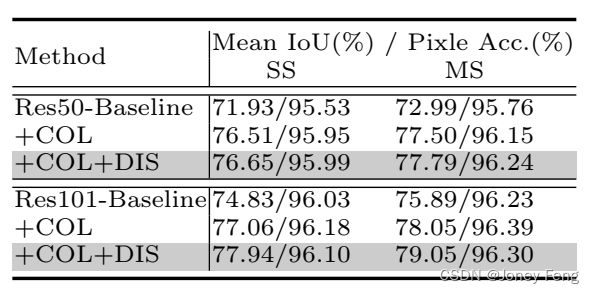
表6.在Cityscapes测试集上报告的方法比较。使用细粒度和粗略数据进行训练的方法用†标记。

4.4.Cityscapes
Cityscapes数据集[8]是为了城市场景理解而收集的。它包含5,000张精细标注的图像,分为2,975张、500张和1,525张用于训练、验证和测试。该数据集注释了道路、行人、汽车等30个常见类别,并且其中19个类别被用于语义分割评估。此外,还提供了另外20,000张粗略标注的图像。我们首先在表5中展示了PSA模块相对于基线方法带来的改进,然后在表6中列出了不同方法在测试集上的比较,其中包括两种设置:仅使用精细数据进行训练和使用粗略+精细数据进行训练。PSANet在两种设置下都取得了最好的性能。补充材料中还包含了一些视觉预测结果。
4.5.掩码可视化
为了更深入地理解我们的PSA模块,我们在图6中可视化了学习到的注意力掩模。这些图像来自ADE20k的验证集。对于每个输入图像,我们显示两个点(红点和蓝点)处生成的掩模,分别用红色和蓝色表示。对于每个点,我们显示由“COLLECT”和“DISTRIBUTE”分支生成的掩模。我们发现,注意力掩模在当前位置上的注意力较低。这是合理的,因为聚合的特征表示已经与原始的局部特征串联在一起,其中已经包含了局部信息。我们发现,我们的注意力掩模有效地将注意力集中在相关区域,以获得更好的性能。例如,在第一行中,红色点的掩模位于海滩上,给海洋和沙滩分配了更大的权重,这有助于对红色点的预测。而在天空中,蓝色点的注意力掩模给其他天空区域分配了更高的权重。在其他图像中也观察到了类似的趋势。可视化的掩模证实了我们模块的设计直觉,即每个位置可以从附近和远处的区域收集有信息量的上下文信息,以获得更好的预测结果。图6. PSANet学习到的掩模的可视化。掩模对位置和类别信息敏感,收集不同的上下文信息。
5.总结和结论
我们提出了适用于场景解析的PSA模块。通过卷积层,它自适应地为特征图中的每个位置预测两个全局注意力图。通过该模块,实现了位置特定的双向信息传播,以获得更好的性能。通过与全局注意力图聚合信息,可以有效地捕捉长距离上下文信息。在三个具有挑战性的数据集上展开的大量实验表明,我们提出的方法在场景解析性能方面名列前茅,证明了其有效性和普适性。我们相信这个提出的模块能够推动社区中相关技术的发展。