2021斯坦福CS224N课程笔记~2
2 Neural Classifiers

2.1本篇内容覆盖
- word2vec与词向量回顾
- 算法优化基础
- 计数与共现矩阵
- GloVe模型
- 词向量评估
- word senses
2.2.回顾:word2vec 的主要思想
2.2.1. 主要步骤
具体见 1.3.2 Word2Vec算法的具体思路
(1) 随起:从随机的词向量开始;
(2) 遍历:遍历整个语料库中的每个单词;
(3) 预测:尝试使用词向量预测周围的词(见图 2.1):

(4) 学习:更新向量,以便他们可以更好地预测周围的实际单词。
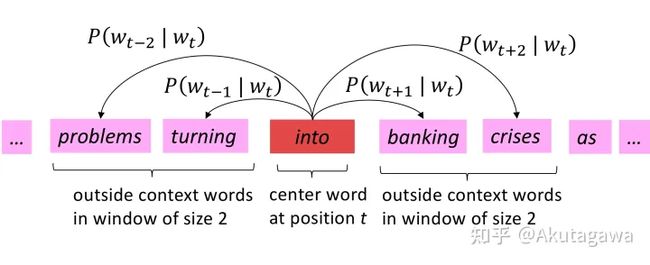
注意:该算法学习词向量,在词空间中捕捉良好的词相似性和有意义的方向!
该算法仅限于词向量,不做其它更多的事。
2.2.2. 参数计算
Word2vec 的参数和计算过程:
根据中心词 V(例如第四个词 v4)和外围词 U,作点积计算,再作归一化处理,得到概率估计值,如图 2.2:

其实,我们想要的就像上述模型一样,模型在每个位置做出相同的预测,它可以对上下文中出现的所有单词(经常)给出合理的高概率估计,这个模型就是**“词袋”模型**。
-
每行代表一个单词的词向量,点乘后得到的分数通过softmax映射为概率分布,并且我们得到的概率分布是对于该中心词而言的上下文中单词的概率分布,该分布于上下文所在的具体位置无关,所以在每个位置的预测都是一样的
-
我们希望模型对上下文中(相当频繁)出现的所有单词给出一个合理的高概率估计
-
the, and, that, of 这样的停用词,是每个单词点乘后得到的较大概率的单词
-
- 去掉这一部分可以使词向量效果更好
2.2.3. 最大化目标函数
Word2vec 通过将相似的词放在临近的空间(见图 2.3)来最大化目标函数。

图 2.3 中,t-SNE(t-distributed Stochastic Neighbor Embedding)的思想就是将高维的数据,通过条件概率来表示点与点之间的相似性。t-SNE 的一个用处是:通过视觉直观验证算法有效性【相似的词汇在词向量空间里是比较接近的】,或者说是算法评估。值得一提的是,t-SNE 是**少数可以同时考虑数据全局与局部关系的算法**,在很多聚类问题上效果很好。
2.2.4. 优化:梯度下降
假设我们有一个想要最小化的成本函数 J(θ),那么就可以去学习一个好的词向量。词向量的学习方法是梯度下降法,它是一种通过改变θ来最小化 J(θ)的算法。
梯度下降思路是:从θ的当前值,计算 J(θ)的梯度,然后向负梯度方向小步走;重复。
注意:我们实际的目标函数可能不是下图这样的凸函数
【学习因子α】但是,如果学习步长α太小,则收敛缓慢;如果α太大,则可能不收敛。例如,当α值较大时,J(θ)可能不会在每次迭代中减小,反而会导致发散,甚至导致无法收敛,可能错过极值点,如图 2.5:

推荐的学习步长α:
首先,选择α为 0.001、0.01、0.1 等等;
然后,评估其收敛效果;如果收敛太慢,则可放大α为 0.003、0.03、0.3 等等,直到满意为止。
下面是梯度下降和随机梯度下降算法
2.2.4.1. 梯度下降
梯度下降就是对方程不断地更新,更新有两种表示法(其中:α表示学习步长):


2.2.4.2. 随机梯度下降(SGD)

①问题:因为上述 J(θ)是语料库(可能是数十亿!)中所有窗口的函数,其梯度的计算成本非常高,需要等待很长时间才能进行一次更新,所以,对于几乎所有的神经网络来说,它都是一个非常糟糕的想法!
②方案:上述问题的解决方案,是采用随机梯度下降(SGD)法:即在单个样本里计算和更新参数,并遍历所有样本。
但基于单个样本更新会表现为参数震荡很厉害,收敛过程并不平稳,所以很多时候我们会改为使用mini-batch gradient descent(具体可以参考**ShowMeAI的深度学习教程中文章神经网络优化算法**)
Mini-batch具有以下优点:通过batch平均,减少梯度估计的噪音;在GPU上并行化运算,加快运算速度。
③但是,又产生新问题:稀疏。


因此,又提出新方案:我们可能只更新实际出现的词向量!具体是下面两者选一:
(1) 要么您需要稀疏矩阵更新操作来仅更新完整嵌入矩阵 U 和 V 的某些行(不是列!);
(2) 要么您需要保留词向量的哈希表,即只更新特定的列,或者通过哈希表来为每个单词构建到单词向量的哈希映射(在 Word2vec 的源代码中,要计算单词的哈希值,并且以哈希表的形式存储之),如图 2.6(b)。
如果您有数百万个词向量并进行分布式计算,那么不必到处发送巨大的更新就很重要!
2.2.5. Word2vec 算法族:两个向量、两种模型、两种算法
为什么是两个向量?因为更容易优化。最后平均两者即为最终词向量。
Word2vec 是一个软件,包实际上包含两种模型和两种算法(训练方法):
两种模型:Continuous Bag-of-Words(CBOW)和 Skip-Gram。CBOW 是根据中心词周围的上下文单词来预测该词的词向量;Skip-Gram 则相反,是根据中心词预测周围上下文的词的概率分布。
两种算法:Negative Sampling 和 Hierarchical Softmax。Negative Sampling 通过抽取负样本来定义目标;H ierarchical Softmax 通过使用一个有效的树结构来计算所有词的概率来定义目标。【其实可以使用负采样方法加快训练速率】
以下只聚焦于 Skip-gram 模型(跳字模型)和 Negative Softmax 算法(负采样算法,作业 2 的内容)。
因为带负采样的的归一化项(即下列方程 的分母)的计算成本很高,因此,在标准 word2vec 中,您可以**使用负采样实现跳字模型**。
主要思想:针对 true pair 真实对(中心词和窗口词的配对,简称正对)与几个 noise pair 噪声对(中心词与随机词的配对,简称负对),训练二元逻辑回归。
(详见:Distributed Representations of Words and Phrases and their Compositionality(Mikolov et al. 2013))

抽样概率分布
当我们对单词进行采样的时候,我们不仅仅是根据她们在语料库中出现的概率,我们所作的是从单词的一元逻辑分布开始。即为单词在我们的语料库中实际出现的概率。(eg:假设我们有十亿个单词的语料库并且一个特定的单词在其中出现了90次,那么我们就用90除以十亿即为这个词的概率)
sigmoid函数
我们要最大化2个词共现的概率

- 我们希望中心词与真实上下文单词的向量点积更大,中心词与随机单词的点积更小
- k是我们负采样的样本数目
2.3.共现矩阵
在自然语言处理里另外一个构建词向量的思路是借助于共现矩阵(我们设其为 X ),我们有两种方式,可以基于窗口(window)或者全文档(full document)统计:
我们能否**通过计数更有效地捕捉词义的本质**?答案是肯定的。换言之,我们**可以直接获取共现计数**。
为构建共现矩阵 X,要有 2 个条件:窗口与完整文档。
•窗口 Window :类似于 word2vec,在每个单词周围使用窗口来捕获一些句法和语义信息;
•文档 Word-document :共现矩阵的基本假设是在同一篇文章中出现的单词更有可能相互关联。若单词 wi 出现在文档 dj中,则共现矩阵元素 Xij加 1。当我们处理完数据库中的所有文档章后,就得到了矩阵 X,其大小为|V|×M,其中|V|为词汇量,而 M 为文档数。这一构建共现矩阵的方法也是经典的潜在语义分析(Latent Semantic Analysis)所采用的。共现矩阵将给出导致潜在语义分析的一般主题(例如,所有体育术语都有相似的条目)。
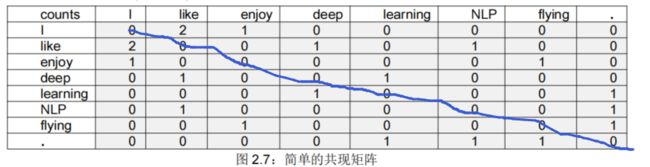
例 2.2:基于窗口的共现矩阵。
利用某个定长窗口(通常取5-10)中单词与单词同时出现的次数,来产生基于窗口的共现矩阵。
如果假设窗口长度为 1(通常是 5–10),共现矩阵是对称的(与上下文的左或右无关),语料库为如下三句话:I like deep learning. I like NLP. I enjoy flying.
那么共现矩阵如下(见图 2.7):
2.3.1. 共现向量
一个共现向量是共现矩阵的一行,代表一个词向量。直接基于共现矩阵构建词向量,会有一些明显的问题,如下:
问题:简单的计数共现向量具有如下缺陷:
• 使用共现次数衡量单词的相似性,向量随着词汇量的增加而增加;
• 非常高的维度:需要大量存储(虽然稀疏);
• 后续分类模型存在稀疏问题,导致模型不太稳健。
方案:构建低维向量。【降维】
想法:将“大部分”重要信息存储在固定的少量维度(如 25-1000)中,构建密集向量,类似 Word2vec。
那么,如何降维呢?
2.3.2. 降维方法:奇异值分解(SVD)
下面讲降维的两个重要概念:奇异值分解、k-秩近似。
第一个概念是奇异值分解。
奇异值分解的定义:矩阵 X(其维度是 mxn)可以分解成如下三个矩阵的乘积:
X = U ∑ V T ( 2.7 ) X=U∑V^T ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~(2.7) X=U∑VT (2.7)
其中:
U 是一个酉矩阵(Unitary Matrix),其维度是 mxm;
VT是一个酉矩阵的共轭矩阵(即 VT和 U 是正交的),其维度是 nxn;
∑是一个对角矩阵,其维度是 mxn,其对角线上是以降序排列的非零值(也被称为奇异值)。
例 2.3:奇异值的分解,见图 2.8:

图 2.8(a)是奇异值分解的完整形式:X 矩阵被分成 U、∑、VT三个矩阵,∑矩阵对角线上有 3 个奇异值。
图 2.8(b)是奇异值分解的简化形式:因为∑矩阵的第四行、第四例和第五列的元素都为 0,即可删除这一行两列,相应地 U 矩阵删除一列、VT矩阵删除一行,所以三个矩阵都被降维简化了。
图 2.8©是大型应用的降维效果:假设 m= 1000,000,n= 500,000,即 X 矩阵有 100 万乘以 50 万=5000亿个元素,如果以 5 号字体打印出来,则有两个杭州西湖那么大!奇异值分解,就是把上面这样一个大 X矩阵,分解成三个较小矩阵相乘:一个 100 万乘以 100 的矩阵 U,一个 100 乘以 100 的矩阵∑,和一个 100乘以 50 万的矩阵VT。这三个矩阵的元素总数加起来也不过 1.5 亿,不到原来的三千分之一(“弱水三千,只取一瓢饮”),相应的存储量和计算量都会小三个数量级以上,所以降维效果非常明显。
为了减少尺度同时尽量保存有效信息,可保留对角矩阵的最大的 k 个值,并将矩阵 U , V 的相应的行列保留。
- 这是经典的线性代数算法,对于大型矩阵而言,计算代价昂贵。
第二个概念是 k-秩近似。
**矩阵的秩(rank)**是矩阵中线性无关的行(或列)向量的最大数量。
如果向量 r 不能表示为 r1 和 r2 的线性组合,即:
r ≠ a r 1 + b r 2 r ≠ ar_1+br_2 r=ar1+br2
则称向量 r 与向量 r1 和 r2 线性无关。
考虑下面三个矩阵:

在矩阵 A 中,行向量 r2是 r1的 2 倍,即 r2 = 2 r1,因此 Rank(A)= 1。
在矩阵 B 中,行向量 r3是 r1和 r2之和,即 r3 = r1 + r2,但 r1和 r2是无关的,因此 Rank(B)= 2。
在矩阵 C 中,所有 3 行彼此无关,因此 Rank©= 3。
矩阵的秩可以被认为是由矩阵表示的独特信息量多少的代表。秩越高,信息越高。
在大型应用中,可**用 SVD 得到 X 矩阵的 k-秩近似**:因为,对角矩阵∑对角线上的所有以降序排列的非零元素中,前面少量(k 个)的奇异值很大,后面大部分的奇异值都非常小,可以省略。所以,只取前面k 个奇异值,并相应地截断三个矩阵(见图 2.9),这三个矩阵的乘积就是 X 矩阵的 k-秩近似,即 Xk。
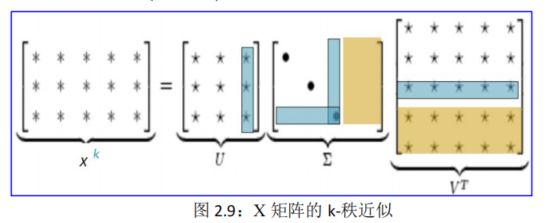
从图 2.9 可知,X 矩阵的 k-秩近似经过两次降维:
第一次是清除零值,即把矩阵∑对角线上的零值元素全部清除,同时把矩阵 U 和 VT中相应的行列清除掉(图中绿色部分);
第二次是清除小值,即在矩阵∑对角线上保留较大的 k 个非零值作为奇异值,而把较小的非零值清除掉,同时把矩阵 U 和 VT中相应的行列清除掉(图中灰色部分)。
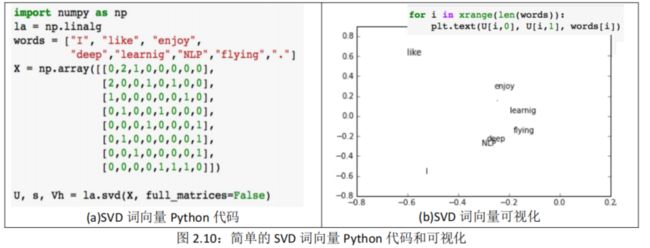
例 2.4:如果假设语料库为 I like deep learning. I like NLP. I enjoy flying,则简单的 SVD 词向量 Python 代码如图 2.10(a)所示;打印出对应于 2 个最大奇异值的 U 矩阵的前两列如图 2.10(b)所示。
2.3.3. 求 X 矩阵的小技巧
下面介绍 Rohde 等人于 2005 年在 COALS 中使用的几个小技巧
(Rohde et al. ms., 2005. An Improved Model of Semantic Similarity Based on Lexical Co-Occurrence):
(1) 在原始计数上运行 SVD 效果不佳;
(2) 缩放单元格中的计数会有很大帮助;
问题:虚词(the、he、has)太频繁,导致句法影响太大。一些修正:
1 记录频率
2 min(X,t),其中 t ≈ 100(即限制高频词的出现,当超过 100 次时,只取 100 次)
3 忽略虚词
4 使用log进行缩放
(3) 倾斜的窗口:【在基于窗口的计数中,提高更加接近的单词的计数】多对较近的单词进行计数(即根据与中心词的距离对权重进行衰减),例如与中心词相邻时记 1 次共现,与中心词相距 5 个单词时记 0.5 次共现;
(4) 使用 Pearson 系数代替计数,然后将负值设置为 0;等等。
用 COALS 模型训练得到的词向量,也表现出了很多有趣的性质(与 Word2Vec 类似),见图 2.11。

在图 2.11(a)的句法模式中,词向量基本上是团块组件,同一个动词的不同时态基本上团聚在一起。
在图 2.11(b)的语义模式中,词向量基本上是线性组件,动词和动词实施者的基本方向是一致的。
但 SVD 也有缺陷:在大的数据集上训练是很困难,计算复杂度高;若想将新的词汇或文章融合进去,就必须重新进行 SVD,计算代价高。
2.4.GloVe 模型
我们来总结一下基于共现矩阵计数和基于预估模型两种得到词向量的方式特点:

基于计数:使用整个矩阵的全局统计数据来直接估计
直接预测:定义概率分布并试图预测单词
特别地,我们对比一下 SVD 和 Word2vector 的优缺点:
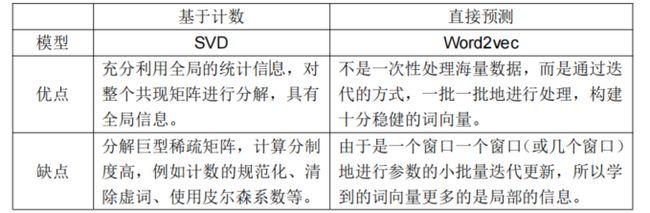
基于以上优缺点,启发了斯坦福的一群研究者,GloVe 词向量就是在这样的动机下产生的。
GloVe (Global Vectors)是一种结合了两种方法的优点的方法,能够充分利用统计数据,因此训练速度快,可以在很大的语料库上训练,同时在较小的语料库上训练或训练维度较小的词向量时也能有不错的表现。
2.4.1. 编码含义分量
关键思想:==共现概率的比值==可以对meaning component进行编码
重点不是单一的概率大小,重点是他们之间的比值,其中蕴含着meaning component。
GloVe 的关键洞察:共现概率的比率可以编码含义成分(Pennington、Socher 和 Manning,EMNLP 2014)。

我们从一个简单的例子开始,展示如何直接从共现概率中提取含义。考虑两个词 i 和 j,它们表现出特定的兴趣,为具体起见,假设我们对热力学相关的概念感兴趣,为此取 i = ice 和 j = steam。我们通过研究它们与各种探测词的共现概率 x 的比率来检查这些词的关系。
图 2.12 中左边是定性推理,右边是定量计算,最后用定量来检验定性的正确性。下面作三个检验:
①因为,solid 词与 ice 词关联性应当比较强(固体的冰),但是很少说固体的蒸汽,所以,定性推理是 P(x|ice)应当比 P(x|steam)大得多(即左边的 large),而右边对应的定量计算结果确实很大(为 8.9)。
②因为 gas 通常不会用来形容 ice,但是却会与 steam 同时出现,所以,定性推理是 P(x|ice)应当比P(x|steam)小得多(即左边的 small),而右边对应的定量计算结果确实很小(为 8.5×10 -2)。
③因为**“water”和“ice”、“steam”都比较相关,而“fashion”和“ice”、“steam”都不相关**,所以,定性推理是在这两种情况下 P(x|ice)应当与 P(x|steam)很接近(即左边两项为≈1 和≈1),而右边对应的定量计算结果确实很接近(即右边两项为 1.36 和 0.96)。
以上三个检验都验证推理是正确的。
与原始概率 P(x|ice)和 P(x|steam)相比,**相对概率 P(x|ice)/P(x|steam)**能够更好地区分相关词(solid 和gas)与不相关词(water 和 fashion),也能够更好地区分两个相关词。
问题提出:我们如何将共现概率的比率捕获为词向量空间中的线性含义分量?
解决方案:根据对数双线性模型
$$
log-bilinear 模型 : w_i⋅w_j=logP(i|j) \
向量差异 : w_x⋅(w_a−w_b)=logP\frac{P(x|a)}{P(x|b)}
$$
求出目标函数。
• 如果使向量点积等于共现概率的对数(对数双线性模型),那么向量差异变成了共现概率的比率(向量差异)
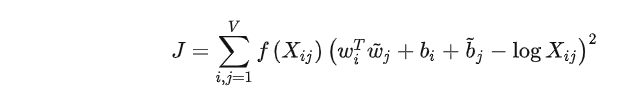
-
使用平方误差促使点积尽可能得接近共现概率的对数
-
使用 f(x) 权重函数对常见单词进行限制【对嘈杂的共现赋予更小的权重】
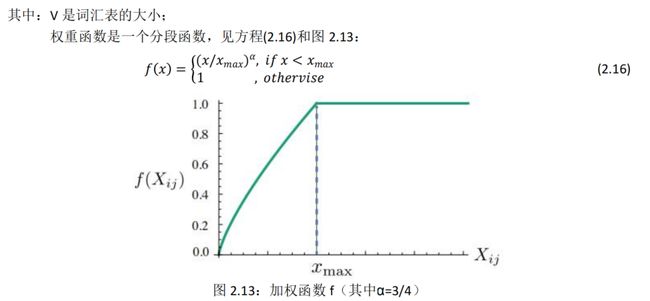
2.4.2. 目标函数推导▲
上述论点表明,词向量学习的合适起点应该是共现概率的比率(Pik /Pjk),而不是概率本身(Pik和 Pjk)。注意到比率 Pik /Pjk 取决于三个词 i、j 和 k,最通用的模型采用以下形式:

其中 w∈Rd是词向量,而w~∈Rd是单独的上下文词向量。在这个方程 2.8 中,右侧是从语料库中提取的,左侧的 F 可能取决于一些尚未指定的参数。F 的可能性有很多,但通过强制执行一些要求,我们可以执行一个独特的选择。首先,我们希望 F 对呈现词向量空间中 Pik/Pjk比率的信息进行编码。由于向量空间本质上是线性结构,因此最自然的方法是使用向量差。出于这个目的,可以将我们的考虑**限制在那些仅依赖于两个目标词差异的函数 F**,因此修改方程(2.8),得到:

接下来,我们注意到方程(2.9)中左边 F 的参数是向量,而右侧是标量。虽然 F 可以被视为一个复杂的函数,例如由神经网络参数化,但这样做会混淆我们试图捕获的线性结构。为了避免这个问题,我们可以先取参数的点积:

这可以防止 F 以不受欢迎的方式混合向量维度。接下来,请注意,对于词-词共现矩阵,词和上下文词之间的区别是任意的,我们可以自由交换这两种角色。为了始终如一地这样做,我们不仅必须**交换w↔ w~而且还要交换 X ↔ XT**。在这种重新标记下,我们的最终模型应该是不变的,但方程(2.10)不是。然而,对称性可以通过两个步骤恢复。
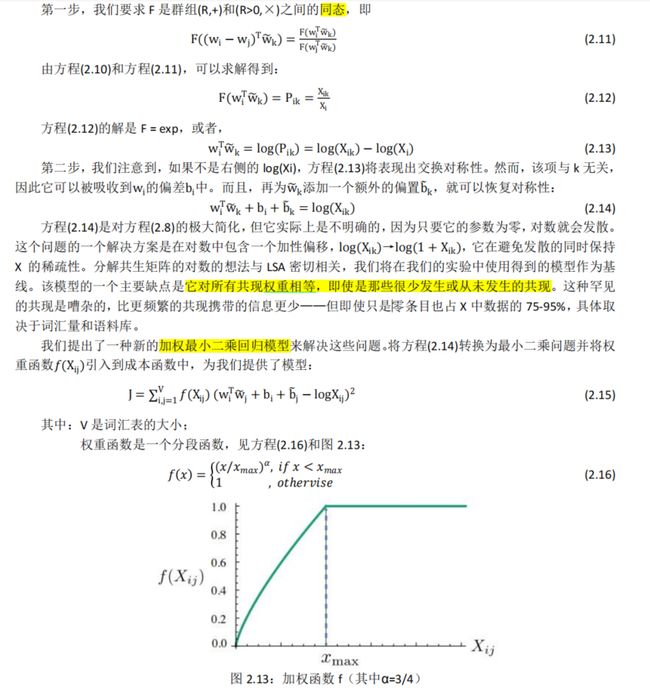
2.4.3. 模型优点和结果
一、模型优点
• 训练速度非常快;
• 可扩展到庞大的语料库;
• 即使在小语料库和小向量的情况下也有良好的性能。
二、模型结果
例如,一个GloVe词向量示例,我们通过GloVe得到的词向量,我们可以找到frog(青蛙)最接近的一些词汇,可以看出它们本身是很类似的动物。:
1.青蛙
2.蟾蜍
3.利托里亚(litoria)
4.钩爪科(leptodactylidae)
5.拉娜(rana)
6.蜥蜴
7.刺五加(eleutherodactylus)
2.5.评估词向量
如何评估词向量?在 NLP 中评估方法有两种:内在的与外在的。
-
内在评估方式
-
- 对特定/中间子任务进行评估
- 计算速度快
- 有助于理解这个系统
- 不清楚是否真的有用,除非与实际任务建立了相关性
-
外部任务方式
-
- 对真实任务(如下游NLP任务)的评估
- 计算精确度可能需要很长时间
- 不清楚子系统问题所在,是交互还是其他子系统问题
- 如果用另一个子系统替换一个子系统可以提高精确性(获胜)
2.5.1. 内在评估
2.5.1.1. 词向量类比
词向量类比任务包含这样的问题:“a 对 b 就像 c 对 ?”,即 a:b::c:?。该数据集包含 19,544 个这样的问题,分为语义子集和句法子集。语义问题通常是关于人或地方的类比,例如“雅典之于希腊就像柏林之于?”。句法问题通常是关于动词时态或形容词形式的类比,例如“dance is to dance as fly is to ?”。为了正确回答问题,模型应该唯一标识缺失的术语,只有完全对应的才算作正确匹配。我们回答这个问题“a 对 b 就像 c 对 ?”是通过根据余弦相似度来找到表示 wd最接近 wb − wa + wc的词 d。
具体来说,词向量类比就是计算词向量的最大余弦相似度:
对于具备某种关系的词对a,b,在给定词c的情况下,找到具备类似关系的词如下(2.17)所示:

对方程(2.17)的直观的解释是:因为x_b-x_a=x_d-x_c例如,queen-king=actress-actor),所以x_d=x_b-x_a+x_c ,然后最大化两个词向量x_d和x_i之间的点积,最后作归一化处理,就得到余弦相似度。
实际上,词向量类比问题就是一个平行四边形模型。
例如,根据平行四边形模型的算法,如果输入三个已知词向量 man:woman::king: ?,就可以输出?为queen 的词向量,见图 2.14。
总之,词向量类比是通过加法后的余弦距离捕获直观语义和句法类比问题的程度来评估词向量。
注意:有时平行四边形算法 a:b::c: ?在 word2vec 或 GloVe 嵌入空间中返回的最接近值通常实际上不是d,而是 3 个输入单词之一或它们的词素变体(例如,cherry:red :: potato:x 返回 potato 或者 potatoes 而不是 brown),因此必须明确排除这些内容,即丢弃搜索(结果输出)中的那些与输入词相同的内容!
问题:如果有信息但它们不是线性的关系,那怎么办?
2.5.1.2. GloVe 可视化
GloVe 可以捕获词向量空间的关系属性,例如语义属性和句法属性,见图 2.15

上述为GloVe得到的词向量空间分布,我们对词向量进行减法计算,可以发现类比的词对有相似的距离。
brother – sister, man – woman, king - queen
2.5.1.3. 类比评估和超参数
超参数的定义:在机器学习的上下文中,超参数是在开始学习过程之前设置值的参数,而不是通过训练得到的参数数据。通常情况下,需要对超参数进行优化,给学习机选择一组最优超参数,以提高学习的性能和效果。
GloVe 词向量类比评估的超参数设置的一个实例:设定词向量的维度(Dim)为 300,语料库 token数量(Size)为 6Billion,在从 SVD 到 GloVe 的六个模型上对语义(Sem)、句法(Syn)和总体(Tot)进行了评估,结果见图 2.16:

GloVe 的研究结果见图 2.17:
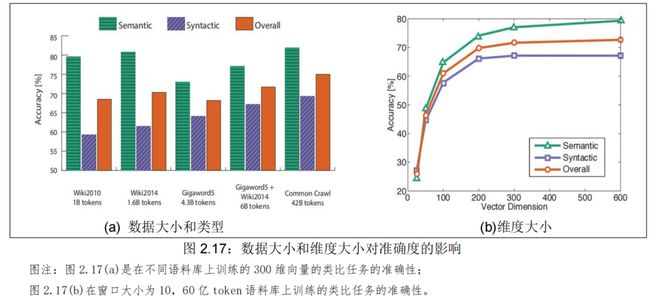
如图 2.17(a)所示,数据越多越准确,维基百科的数据胜过新闻文本的数据。这是因为模型训练的语料越大,模型的表现就会更好。例如,若训练的时候没有包含测试的词语,则词类比会产生错误的结果。
- 因为维基百科就是在解释概念以及他们之间的相互关联,更多的说明性文本显示了事物之间的所有联系
- 而新闻并不去解释,而只是去阐述一些事件
如图 2.17(b)所示,维度越大越准确,良好的维度约为 300。对于极高或者极低维度的词向量,模型的表现较差。一方面,低维度的词向量不能捕获在语料库中不同词语的意义,这是模型复杂度太低的高偏差问题。例如,我们考虑单词“king”、“queen”、“man”、“woman”。直观上,我们需要使用例如“性别”和“领导”两个维度来将它们编码成 2 字节的词向量。维度较低的词向量不会捕获四个单词之间的语义差异。另一方面,过高的维度可能捕获语料库中无助于泛化的噪声,这是所谓的高方差问题。
下图是对于类比评估和超参数的一些实验和经验
-
300是一个很好的词向量维度
-
不对称上下文(只使用单侧的单词)不是很好,不过这点在下游任务中不一定完全正确
-
window size 设为 8 对 Glove向量来说比较好
- window size设为2的时候实际上有效的,并且对于句法分析是更好的,因为句法效果非常局部
2.5.1.4. 另一种内在评估
另外一个评估词向量质量的简单方法是,让**人类去给两个词的相似度在一个固定的范围内(例如 0-10,即 10 分制)评分**,然后将其与对应词向量的余弦相似度进行对比。这已经在包含人为评估的各种数据集上尝试过。因此,词向量距离(余弦相似度),可以测试两个词之间的相关性(及其与人类判断的相关性),见图 2.18(a);也可以测试与“Sweden(瑞典)”最接近的单词,见图 2.18(b)。
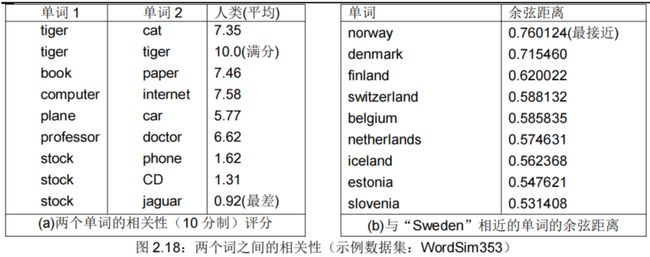
2.5.1.5. 相关性评估▲
Glove 论文的一些想法已被证明也可以改进 skip-gram (SG 跳字模型)模型(例如,平均两个向量),见图 2.19:

图 2.19 显示了五个不同单词相似性数据集的结果。通过首先对词汇表中的每个特征进行归一化,然后计算余弦相似度,从词向量中获得相似度分数。我们计算该分数与人类判断之间的 Spearman 等级相关系数。CBOW∗ 表示 word2vec 网站上可用的向量,这些向量是在 100B 个词的新闻数据上用词和短语向量训练的。GloVe 在使用不到一半大小的语料库时优于它。
2.5.2. 外在评估
词向量的外在评估,针对的是此类中的所有下游 NLP 任务。好的词向量应该直接提供帮助的一个例子:命名实体识别。图 2.20 显示了 GloVe 模型使用基于 CRF 的模型在 NER 任务上的结果。Discrete 模型是使用斯坦福 NER 模型标准分布附带的一组综合离散特征的基线,但没有词向量特征。除了之前讨论的 HPCA 和 SVD 模型,还与 Huang 等人(2012) (HSMN) 和 Collobert and Weston (2008) (CW) 的模型进行了比较。使用 word2vec 具训练了 CBOW 模型。GloVe 模型在所有评估指标上都优于所有其他方法,
除了 CoNLL 测试集,HPCA 方法在该测试集上的表现稍好一些。结果表明:GloVe 向量在下游 NLP 任务中很有用,正如(Turian et al., 2010)中首次展示的神经向量。

一个例子是在命名实体识别任务中,寻找人名、机构名、地理位置名,词向量非常有帮助
2.6.词义和歧义
2.6.1. 一词多义与聚类
在第 1.2.2 节,提及意义(sense)和含义(menaning):意义是一个单词的含义的一个方面的离散表示。
单词是有**歧义(ambiguous)**的:同一个词可以用来表示不同的东西。例如,“mouse”这个词(至少)有两种意义:(1)一种小型啮齿动物,(2)一种手动控制光标的装置;“bank”这个词的意思是:(1)一个金融机构,(2) 一个倾斜的堤岸。
大多数单词都是多义的
- 特别是常见单词
- 特别是存在已久的单词
那么,一个向量是否能够包含所有这些含义呢?
答案是肯定的,可以通过全局上下文和多个单词原型改进单词表示(Huang et al. 2012)。
主要思想是:围绕单词来聚类单词窗口,重新训练每个单词并分配到多个不同的聚类 bank1、bank2等,见图 2.21。
将常用词的所有上下文进行聚类,通过该词得到一些清晰的簇,从而将这个常用词分解为多个单词,例如 bank1 、 bank2 、 bank3 。
补充说明:虽然这很粗糙,并且有时sensors之间的划分也不是很明确,甚至相互重叠。

2.6.2. 一词多义与线性代数
词嵌入在 NLP 和信息检索中无处不在,但不清楚当词是多义词时它们代表什么。有研究(Arora, …, Ma, …, TACL 2018)表明多个词义存在于词嵌入中的线性叠加中,简单的稀疏编码可以近似捕获词义的向量。【此技术的一个新颖之处在于,每个提取的词义都伴随着大约 2000 个“话语原子(discourse atom)”中的一个,它给出了与该词义同时出现的其他词的简洁描述。话语原子可以具有独立的兴趣,并使该方法可能更有用】。
词义的线性代数简述如下:
一个词的不同含义存在于 word2vec 等标准词嵌入中的线性叠加(加权和)中,即:

令人惊讶的结果:
- 只是加权平均值就已经可以获得很好的效果
- 由于从稀疏编码中得到的概念,你实际上可以分离出意义(前提是它们相对比较常见)
补充讲解:可以理解为由于单词存在于高维的向量空间之中,不同的纬度所包含的含义是不同的,所以加权平均值并不会损害单词在不同含义所属的纬度上存储的信息。
图 2.22 显示了一个实例。每个单词(例如 tie)最多使用五个话语原子表示,这些原子通常捕获不同的含义(带有一些噪音/错误)。每个原子的内容可以通过查看附近的余弦相似度词来辨别。算法经常在最后一个(或两个)原子中出错,就像这里发生的那样。使用其他词嵌入(如 word2vec 和 GloVe)可获得类似的结果。

2.7.分类的论述和表示
对于分类问题,我们有训练数据集:它由一些样本组成

-
xi 是输入,例如单词(索引或是向量),句子,文档等等(维度为 d )
-
yi 是我们尝试预测的标签( C 个类别中的一个),例如:
- 类别:感情,命名实体,购买/售出的决定
- 其他单词
- 多词序列( 之后会提到)
基于这个数据集,对其进行训练,就可以进行分类
2.7.1. 分类的直觉解释
分类的直觉是:训练数据 {xi,yi}i=1N ,作出决策。
简单案例:Andrej Karpathy 使用 ConvNetJS 进行可视化,其中固定了用于分类的 2 维词向量输入,使用 softmax/logistic 回归和线性决策边界。
(参考网站 http://cs.stanford.edu/people/karpathy/convnetjs/demo/classify2d.html)
传统的机器学习/统计学(ML/Stats)方法:假设xi是固定的,训练(即设置)softmax/logistic 回归权重 W∈Rcxd,以便确定决策边界(超平面),如图 2.23 所示。具体的方法是,对于每个固定的 x,作出预测:
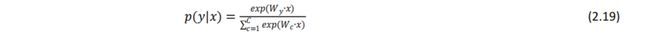

2.7.2. Softmax 归一化函数:线性分类器

2.7.3. 交叉熵损失函数
在softmax分类器中最常用到交叉熵损失,也是负对数概率形态。

2.7.4. 传统的机器学习优化

2.8.神经网络分类器
逻辑回归主要工具是 Softmax 分类器,但是 Softmax 分类器只给出线性决策边界,其本身并不是很强大,而且其功能还可能非常有限,特别是在问题复杂时无能为力。例如,如图 2.24(a)所示,Softmax 分类器把箭头所指的两个点简单地、线性地、错误地分为负类。其实,如果用非线性分类器(例如下面即将介绍的 Sigmod 激活函数),则可正确地把它们分为正类,见图 2.24(b)。

从图 2.24 中可以看出,原始空间中具有非线性的边界。因为神经网络可以学习具有非线性决策边界的更复杂的函数,能够正确地作出分类,所以神经网络获胜了!
-
单独使用线性分类器Softmax( ≈ logistic回归)并不十分强大
-
如上图所示,Softmax得到的是线性决策边界
-
- 对于复杂问题来说,它的表达能力是有限的
- 有一些分错的点,需要更强的非线性表达能力来区分—>Sigmod
-
神经网络可以学习更复杂的函数和非线性决策边界
-
tip :更高级的分类需要
-
- 词向量
- 更深层次的深层神经网络
2.8.1. 词向量的分类
-
一般在NLP深度学习中:
-
- 我们学习了常规的参数矩阵 W 和词向量 x 。
- 我们学习传统参数和表示。
- 词向量是对one-hot 向量的重新表示(re-present)——在中间层向量空间中移动它们——以便 (线性)softmax分类器可以更好地分类,概念上通过嵌入层:x = Le(即线性嵌入),见方程 2.26:
- 即将词向量理解为一层神经网络,输入单词的one-hot 向量并获得单词的词向量表示,并且我们需要对其进行更新。

现在我们来估计一下同时训练模型的权值(W)和词向量(x)时需要更新的参数的数量。我们知道一个简单的线性决策模型至少需要一个 d 维的词向量输入和生成一个 C 个类别的分布。因此更新模型的权值,我们需要 Cd 个参数。如果我们也对词汇表 V 中的每个单词都更新词向量,那么就要更新 V 个词向量,每一个词向量的维度是 d 维。因此对一个简单的线性分类模型,总共的参数数目是 Cd+V*d。
2.8.2. 神经单元
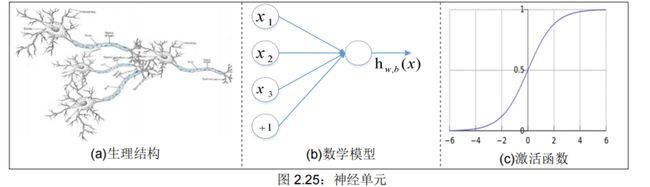
神经单元的生理结构包括(见图 2.25(a)):
树突:接受从其他神经元传入信息的神经元纤维;
胞体:接受外来的信息,对各种信息进行汇总,并进行阈值处理,产生神经冲动;
轴突:连接其他神经元的树突和细胞体,以及完成神经元之间的信息传递。
突触:单方向的传递信息,且强度可变、具有学习功能。

2.8.3. 神经网络
一个神经网络:多个逻辑回归组合
如果同时运行多个逻辑回归单元,那么就可以得到一个神经网络。
如果我们提供一个输入向量,并且让它通过一群逻辑回归函数,那么我们就会得到一个输出向量,但是我们不必提前决定这些逻辑回归试图预测哪些变量,如图 2.26(a);我们可以将其再次输入到另一个逻辑回归函数中,损失函数将指导中间隐藏变量应该是什么,以便更好地预测下一层的目标等,如图 2.26(b);继续,我们有一个多层神经网络,如图 2.26©。

多层神经网络有多种表示方法,见图 2.27:

2.8.4. Sigmoid 激活函数:非线性分类器1
我们为什么需要非线性(也称“f”)Sigmoid 激活函数?因为它可以逼近任意复杂函数。例如:
如果没有非线性,深度神经网络只能做线性变换,额外的层也只可以编译成一个单一的线性变换:W1W2x=Wx;
如果有了非线性和更多的层,则可以逼近更复杂的任意函数,见图 2.28
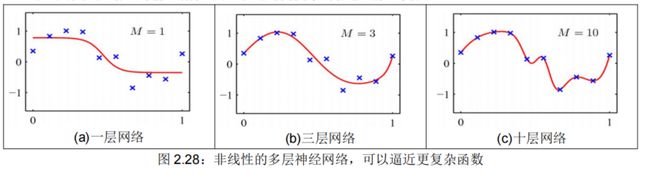
-
例如:函数近似,如回归或分类
-
- 没有非线性,深度神经网络只能做线性变换
- 多个线性变换,也还是组成一个线性变换 W1W2x=Wx
-
因为线性变换是以某种方式旋转和拉伸空间,多次的旋转和拉伸可以融合为一次线性变换【多合一】
-
对于非线性函数而言,使用更多的层,他们可以近似更复杂的函数
1 编译者注:Softmax 函数和 Sigmiod 函数的区别:
Softmax 是归一化函数,可作为线性分类器之用;
Sigmoid 是激活函数,可作为非线性分类器之用。
常用的激活函数:Sigmoid 、linear、relu