Pytorch_course2
PyTorch基础:Tensor和Autograd
- PyTorch基础:Tensor和Autograd¶
-
- 3.1 Tensor
-
- 3.1.1 基础操作
-
- 创建Tensor
- 常用Tensor操作
- 索引操作
- 高级索引
- Tensor类型
- 逐元素操作
- 归并操作
- 比较
- 线性代数
- 3.1.2 Tensor和Numpy
- 3.1.3 广播法则
- 3.2 Pytorch的层次结构
- 3.3 数据
-
- 3.3.1 Dataset and DataLoader
PyTorch基础:Tensor和Autograd¶
3.1 Tensor
Tensor,又名张量,读者可能对这个名词似曾相识,因它不仅在PyTorch中出现过,它也是Theano、TensorFlow、Torch和MxNet中重要的数据结构。关于张量的本
质不乏深度的剖析,但从工程角度来讲,可简单地认为它就是一个数组,且支持高效的科学计算。它可以是一个数(标量)、一维数组(向量)、二维数组(矩
阵)和更高维的数组(高阶数据)。Tensor和Numpy的ndarrays类似,但PyTorch的tensor支持GPU加速。
3.1.1 基础操作
从接口的角度来讲,对tensor的操作可分为两类:
1、torch.function,如torch.save等。
2、tensor.function,如tensor.view等。
为方便使用,对tensor的大部分操作同时支持这两类接口,在本书中不做具体区分,如torch.sum (torch.sum(a, b))与tensor.sum (a.sum(b))功能等价。
而从存储的角度来讲,对tensor的操作又可分为两类:
1、不会修改自身的数据,如 a.add(b), 加法的结果会返回一个新的tensor。
2、会修改自身的数据,如 a.add_(b), 加法的结果仍存储在a中,a被修改了。
函数名以_结尾的都是inplace方式, 即会修改调用者自己的数据,在实际应用中需加以区分
创建Tensor
在PyTorch中新建tensor的方法有很多,具体如表3-1所示。
表3-1: 常见新建tensor的方法
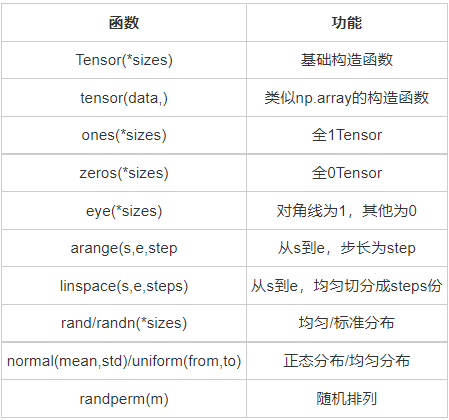
这些创建方法都可以在创建的时候指定数据类型dtype和存放device(cpu/gpu).
其中使用Tensor函数新建tensor是最复杂多变的方式,它既可以接收一个list,并根据list的数据新建tensor,也能根据指定的形状新建tensor,还能传入其他的tensor,下面举几个例子
# 指定tensor的形状
import torch
a = torch.Tensor(3, 5)
a # 数值取决于内存空间的状态,print时候可能overflow
tensor([[2.4219e+12, 7.2027e-43, 2.4219e+12, 7.2027e-43, 2.4219e+12],
[7.2027e-43, 2.4219e+12, 7.2027e-43, 2.4219e+12, 7.2027e-43],
[2.4219e+12, 7.2027e-43, 2.4219e+12, 7.2027e-43, 2.4219e+12]])
# 用list数据创建tensor
import torch
b = torch.Tensor([[1, 2, 3],[4, 5, 6]])
b
tensor([[1., 2., 3.],
[4., 5., 6.]])
b.tolist() # 把tensor转为list
[[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]]
tensor.size()返回torch.Size对象,它是tuple的子类,但其使用方式与tuple略有区别
b_size= b.size()
b_size
torch.Size([2, 3])
# b.numel() # b中元素总个数,2*3,等价于b.nelement()
b.nelement()
6
# 创建一个和b形状一样的tensor
c = torch.Tensor(b_size)
# 创建一个元素为2和3的tensor
d = torch.Tensor([2,3])
c,d
(tensor([[0., 0., 0.],
[0., 0., 0.]]),
tensor([2., 3.]))
除了tensor.size(),还可以利用tensor.shape直接查看tensor的形状,tensor.shape等价于tensor.size()
c.shape
torch.Size([2, 3])
需要注意的是,t.Tensor(*sizes)创建tensor时,系统不会马上分配空间,只是会计算剩余的内存是否足够使用,使用到tensor时才会分配,而其它操作都是在创建完tensor之后马上进行空间分配。其它常用的创建tensor的方法举例如下。
torch.ones(2,3)
tensor([[1., 1., 1.],
[1., 1., 1.]])
torch.zeros(3,2)
tensor([[0., 0.],
[0., 0.],
[0., 0.]])
torch.arange(1, 6, 2)
tensor([1, 3, 5])
torch.linspace(1, 10, 3)
tensor([ 1.0000, 5.5000, 10.0000])
torch.randn(2, 3, device=torch.device('cpu'))
tensor([[ 0.3982, -0.1161, 0.3255],
[ 0.1941, 0.9055, -0.4814]])
torch.randperm(20) # 长度为5的随机排列
tensor([12, 6, 4, 1, 10, 2, 5, 19, 0, 17, 13, 3, 8, 7, 18, 9, 14, 11,
15, 16])
torch.eye(3,3, dtype=torch.int) # 对角线为1, 不要求行列数一致
tensor([[1, 0, 0],
[0, 1, 0],
[0, 0, 1]], dtype=torch.int32)
torch.tensor是在0.4版本新增加的一个新版本的创建tensor方法,使用的方法,和参数几乎和np.array完全一致
scalar = torch.tensor(3.14159)
print('scalar: %s, shape of sclar: %s' %(scalar, scalar.shape))
vector = torch.tensor([1, 2])
print('vector: %s, shape of vector: %s' %(vector, vector.shape))
scalar: tensor(3.1416), shape of sclar: torch.Size([])
vector: tensor([1, 2]), shape of vector: torch.Size([2])
tensor = torch.Tensor(1,2) # 注意和t.tensor([1, 2])的区别
tensor.shape
torch.Size([1, 2])
matrix = torch.tensor([[0.1, 1.2], [2.2, 3.1], [4.9, 5.2]])
matrix,matrix.shape
(tensor([[0.1000, 1.2000],
[2.2000, 3.1000],
[4.9000, 5.2000]]),
torch.Size([3, 2]))
torch.tensor([[0.11111, 0.222222, 0.3333333]],
dtype=torch.float64,
device=torch.device('cpu'))
tensor([[0.1111, 0.2222, 0.3333]], dtype=torch.float64)
empty_tensor = torch.tensor([])
empty_tensor.shape
torch.Size([0])
常用Tensor操作
通过tensor.view方法可以调整tensor的形状,但必须保证调整前后元素总数一致。view不会修改自身的数据,返回的新tensor与源tensor共享内存,也即更改其中的一个,另外一个也会跟着改变。
在实际应用中可能经常需要添加或减少某一维度,这时候squeeze和unsqueeze两个函数就派上用场了。
a = torch.arange(0,6)
a.view(2,3)
tensor([[0, 1, 2],
[3, 4, 5]])
b = a.view(-1, 3) # 当某一维为-1的时候,会自动计算它的大小
b.shape
torch.Size([2, 3])
b.unsqueeze(1) #注意形状, 在第一维(下标从0开始)上增加‘1’
# 等价于b[:, None]
b[:, None,].shape # 等价于b[:, None].shape
# b.shape
torch.Size([2, 1, 3])
b.unsqueeze(-2)
tensor([[[0, 1, 2]],
[[3, 4, 5]]])
c = b.view(1, 1, 1, 2, 3)
c.squeeze(0) # 压缩第0维的“1”
tensor([[[[0, 1, 2],
[3, 4, 5]]]])
c.squeeze() # 把所有维度为“1”的压缩
tensor([[0, 1, 2],
[3, 4, 5]])
a[1] = 100
b # a修改,b作为view之后的,也会跟着修改
tensor([[ 0, 100, 2],
[ 3, 4, 5]])
resize是另一种可用来调整size的方法,但与view不同,它可以修改tensor的大小。如果新大小超过了原大小,会自动分配新的内存空间,而如果新大小小于原大小,则之前的数据依旧会被保存,看一个例子。
b.resize_(1,3)
tensor([[ 0, 100, 2]])
b.resize_(3, 3) # 旧的数据依旧保存着,多出的大小会分配新空间
b
tensor([[ 0, 100, 2],
[ 3, 4, 5],
[32932988893659237, 29273792722501740, 31244220638625897]])
索引操作
Tensor支持与numpy.ndarray类似的索引操作,语法上也类似,下面通过一些例子,讲解常用的索引操作。如无特殊说明,索引出来的结果与原tensor共享内存,也即修改一个,另一个会跟着修改。
a = torch.randn(3, 4)
a
tensor([[-1.6488, -1.2068, -0.7809, -3.4079],
[-1.7839, 1.2259, -0.7961, 0.7267],
[-0.6942, 0.6834, -0.8989, -0.0749]])
a[0] # 第0行(下标从0开始)
tensor([-1.6488, -1.2068, -0.7809, -3.4079])
a[:, 0] # 第0列
tensor([-1.6488, -1.7839, -0.6942])
a[0][2] # 第0行第2个元素,等价于a[0, 2]
tensor(-0.7809)
a[0, -1] # 第0行最后一个元素
tensor(-3.4079)
a[:2] # 前两行
tensor([[-1.6488, -1.2068, -0.7809, -3.4079],
[-1.7839, 1.2259, -0.7961, 0.7267]])
a[:2, 0:2] # 前两行,第0,1列
tensor([[-1.6488, -1.2068],
[-1.7839, 1.2259]])
print(a[0:1, 0:2]) # 第0行,前两列
print(a[0, :2]) # 注意两者的区别:形状不同
tensor([[-1.6488, -1.2068]])
tensor([-1.6488, -1.2068])
# None类似于np.newaxis, 为a新增了一个轴
# 等价于a.view(1, a.shape[0], a.shape[1])
a[None].shape
torch.Size([1, 3, 4])
a[None].shape # 等价于a[None,:,:]
torch.Size([1, 3, 4])
a[:,None,:].shape
torch.Size([3, 1, 4])
a[:,None,:,None,None].shape
torch.Size([3, 1, 4, 1, 1])
a > 1 # 返回一个ByteTensor
tensor([[False, False, False, False],
[False, True, False, False],
[False, False, False, False]])
a[a < 1] # 等价于a.masked_select(a > 1)
# 选择结果与原tensor不共享内存空间
tensor([-1.6488, -1.2068, -0.7809, -3.4079, -1.7839, -0.7961, 0.7267, -0.6942,
0.6834, -0.8989, -0.0749])
a[torch.LongTensor([0,1])] # 第0行和第1行
tensor([[-1.6488, -1.2068, -0.7809, -3.4079],
[-1.7839, 1.2259, -0.7961, 0.7267]])
其它常用的选择函数如表3-2所示。
表3-2常用的选择函数

对tensor的任何索引操作仍是一个tensor,想要获取标准的python对象数值,需要调用tensor.item(), 这个方法只对包含一个元素的tensor适用
a = torch.arange(0, 16).view(4, 4)
a
tensor([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15]])
a[0][0] # 依旧是tensor
tensor(0)
a[0,0].item() # python float
0
d = a[0:1, 0:1, None]
print(d.shape)
d.item()# 只包含一个元素的tensor即可调用tensor.item,与形状无关
torch.Size([1, 1, 1])
0
# a[0].item() ->
# raise ValueError: only one element tensors can be converted to Python scalars
高级索引
PyTorch在0.2版本中完善了索引操作,目前已经支持绝大多数numpy的高级索引1。高级索引可以看成是普通索引操作的扩展,但是高级索引操作的结果一般不和原始的Tensor共享内存。
x = torch.arange(0,27).view(3,3,3)
x
tensor([[[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8]],
[[ 9, 10, 11],
[12, 13, 14],
[15, 16, 17]],
[[18, 19, 20],
[21, 22, 23],
[24, 25, 26]]])
x[[1, 2], [1, 2],[2, 0]] # x[1,1,2]和x[2,2,0]
tensor([14, 24])
x[[2, 1, 0], [0], [1]] # x[2,0,1],x[1,0,1],x[0,0,1]
tensor([19, 10, 1])
x[[0, 2], ...] # x[0] 和 x[2]
tensor([[[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8]],
[[18, 19, 20],
[21, 22, 23],
[24, 25, 26]]])
Tensor类型
Tensor有不同的数据类型,如表3-3所示,每种类型分别对应有CPU和GPU版本(HalfTensor除外)。默认的tensor是FloatTensor,可通过t.set_default_tensor_type 来修改默认tensor类型(如果默认类型为GPU tensor,则所有操作都将在GPU上进行)。Tensor的类型对分析内存占用很有帮助。例如对于一个size为(1000, 1000, 1000)的FloatTensor,它有100010001000=10^9个元素,每个元素占32bit/8 = 4Byte内存,所以共占大约4GB内存/显存。HalfTensor是专门为GPU版本设计的,同样的元素个数,显存占用只有FloatTensor的一半,所以可以极大缓解GPU显存不足的问题,但由于HalfTensor所能表示的数值大小和精度有限,所以可能出现溢出等问题。

各数据类型之间可以互相转换,type(new_type)是通用的做法,同时还有float、long、half等快捷方法;
CPU tensor与GPU tensor之间的互相转换通过tensor.cuda和tensor.cpu方法实现;
可以使用tensor.to(device)。Tensor还有一个new方法,用法与t.Tensor一样,会调用该tensor对应类型的构造函数,生成与当前tensor类型一致的tensor。
torch.like(tensora) 可以生成和tensora拥有同样属性(类型,形状,cpu/gpu)的新tensor。 tensor.new(new_shape) 新建一个不同形状的tensor。
# 设置默认tensor,注意参数是字符串
import torch
torch.set_default_tensor_type('torch.DoubleTensor')
a = torch.Tensor(2,3)
a.dtype # 现在a是DoubleTensor,dtype是float64
torch.float64
# 恢复之前的默认设置
torch.set_default_tensor_type('torch.FloatTensor')
# 把a转成FloatTensor,等价于b=a.type(t.FloatTensor)
b = a.float()
b.dtype
torch.float32
c = a.type_as(b)
c
tensor([[0., 0., 0.],
[0., 0., 0.]])
a.new(2,3) # 等价于torch.DoubleTensor(2,3),建议使用a.new_tensor
tensor([[0., 0., 0.],
[0., 0., 0.]], dtype=torch.float64)
torch.zeros_like(a)
tensor([[0., 0., 0.],
[0., 0., 0.]], dtype=torch.float64)
torch.zeros_like(a, dtype=torch.int16) #可以修改某些属性
tensor([[0, 0, 0],
[0, 0, 0]], dtype=torch.int16)
torch.rand_like(a)
tensor([[0.4486, 0.3648, 0.5967],
[0.0473, 0.3290, 0.6960]], dtype=torch.float64)
a.new_ones(4,5, dtype=torch.int)
tensor([[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1]], dtype=torch.int32)
a.new_tensor([3,4]) #
tensor([3., 4.], dtype=torch.float64)
逐元素操作
这部分操作会对tensor的每一个元素(point-wise,又名element-wise)进行操作,此类操作的输入与输出形状一致。常用的操作如表3-4所示。
表3-4: 常见的逐元素操作

对于很多操作,例如div、mul、pow、fmod等,PyTorch都实现了运算符重载,所以可以直接使用运算符。如a ** 2 等价于torch.pow(a,2), a * 2等价于torch.mul(a,2)。
其中clamp(x, min, max)的输出满足以下公式:
y_i =
\begin{cases}
min, & \text{if } x_i \lt min \
x_i, & \text{if } min \le x_i \le max \
max, & \text{if } x_i \gt max\
\end{cases}
clamp常用在某些需要比较大小的地方,如取一个tensor的每个元素与另一个数的较大值。
import torch
a = torch.arange(0, 6).view(2, 3).float()
torch.cos(a)
tensor([[ 1.0000, 0.5403, -0.4161],
[-0.9900, -0.6536, 0.2837]])
a % 3# 等价于t.fmod(a, 3)
tensor([[0., 1., 2.],
[0., 1., 2.]])
a ** 2 # 等价于t.pow(a, 2)
tensor([[ 0., 1., 4.],
[ 9., 16., 25.]])
# 取a中的每一个元素与3相比较大的一个 (小于3的截断成3)
print(a)
torch.clamp(a, min=3)
tensor([[0., 1., 2.],
[3., 4., 5.]])
tensor([[3., 3., 3.],
[3., 4., 5.]])
b = a.sin_()# 效果同 a = a.sin();b=a ,但是更高效节省显存
a
tensor([[ 0.0000, 0.8415, 0.9093],
[ 0.1411, -0.7568, -0.9589]])
归并操作
此类操作会使输出形状小于输入形状,并可以沿着某一维度进行指定操作。如加法sum,既可以计算整个tensor的和,也可以计算tensor中每一行或每一列的和。常用的归并操作如表3-5所示。
表3-5: 常用归并操作

以上大多数函数都有一个参数dim,用来指定这些操作是在哪个维度上执行的。关于dim(对应于Numpy中的axis)的解释众说纷纭,这里提供一个简单的记忆方式:
假设输入的形状是(m, n, k)
- 如果指定dim=0,输出的形状就是(1, n, k)或者(n, k)
- 如果指定dim=1,输出的形状就是(m, 1, k)或者(m, k)
- 如果指定dim=2,输出的形状就是(m, n, 1)或者(m, n)
size中是否有"1",取决于参数keepdim,keepdim=True会保留维度1。注意,以上只是经验总结,并非所有函数都符合这种形状变化方式,如cumsum。
b = torch.ones(2,3)
b.sum(dim=0, keepdim=True)
tensor([[2., 2., 2.]])
# keepdim=False,不保留维度"1",注意形状
b.sum(dim=0, keepdim=False)
tensor([2., 2., 2.])
b.sum(dim=1)
tensor([3., 3.])
a = torch.arange(0, 6).view(2, 3)
print(a)
a.cumsum(dim=1) # 沿着行累加
tensor([[0, 1, 2],
[3, 4, 5]])
tensor([[ 0, 1, 3],
[ 3, 7, 12]])
比较
比较函数中有一些是逐元素比较,操作类似于逐元素操作,还有一些则类似于归并操作。常用比较函数如表3-6所示。
表3-6: 常用比较函数
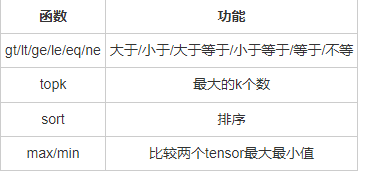
表中第一行的比较操作已经实现了运算符重载,因此可以使用a>=b、a>b、a!=b、a==b,其返回结果是一个ByteTensor,可用来选取元素。max/min这两个操作比较特殊,以max来说,它有以下三种使用情况:
- t.max(tensor):返回tensor中最大的一个数
- t.max(tensor,dim):指定维上最大的数,返回tensor和下标
- t.max(tensor1, tensor2): 比较两个tensor相比较大的元素
至于比较一个tensor和一个数,可以使用clamp函数。下面举例说明。
a = torch.linspace(0,15,6).view(2,3)
a
tensor([[ 0., 3., 6.],
[ 9., 12., 15.]])
b = torch.linspace(15, 0, 6).view(2, 3)
b
tensor([[15., 12., 9.],
[ 6., 3., 0.]])
a > b
tensor([[False, False, False],
[ True, True, True]])
a[a>b] # a 大于 b的元素
tensor([ 9., 12., 15.])
torch.max(a)
tensor(15.)
torch.max(b, dim=1)
# 第一个返回值的15和6分别表示第0行和第1行最大的元素
# 第二个返回值的0和0表示上述最大的数是该行第0个元素
torch.return_types.max(
values=tensor([15., 6.]),
indices=tensor([0, 0]))
torch.max(a, b)
tensor([[15., 12., 9.],
[ 9., 12., 15.]])
# 比较a和10较大的元素
torch.clamp(a, min=10)
tensor([[10., 10., 10.],
[10., 12., 15.]])
线性代数
PyTorch的线性函数主要封装了Blas和Lapack,其用法和接口都与之类似。常用的线性代数函数如表3-7所示。
表3-7: 常用的线性代数函数

需要注意的是,矩阵的转置会导致存储空间不连续,需调用它的.contiguous方法将其转为连续。
http://pytorch.org/docs/torch.html#blas-and-lapack-operations
b = a.t()
b.is_contiguous()
False
b.contiguous()
tensor([[ 0., 9.],
[ 3., 12.],
[ 6., 15.]])
3.1.2 Tensor和Numpy
Tensor和Numpy数组之间具有很高的相似性,彼此之间的互操作也非常简单高效。需要注意的是,Numpy和Tensor共享内存。由于Numpy历史悠久,支持丰富的操作,所以当遇到Tensor不支持的操作时,可先转成Numpy数组,处理后再转回tensor,其转换开销很小
import numpy as np
a = np.ones([2,3], dtype=np.float32)
a
array([[1., 1., 1.],
[1., 1., 1.]], dtype=float32)
b = torch.from_numpy(a)
b
tensor([[1., 1., 1.],
[1., 1., 1.]])
b = torch.Tensor(a) #也可以直接将numpy对象传入Tensor
b
tensor([[1., 1., 1.],
[1., 1., 1.]])
a[0, 1]=100
b
tensor([[ 1., 100., 1.],
[ 1., 1., 1.]])
c = b.numpy()# a, b, c三个对象共享内存
c
array([[ 1., 100., 1.],
[ 1., 1., 1.]], dtype=float32)
注意: 当numpy的数据类型和Tensor的类型不一样的时候,数据会被复制,不会共享内存。
a = np.ones([2,3])
# 注意和上面的a的区别(dtype不是float32)
a.dtype
dtype('float64')
b = torch.Tensor(a)# 此处进行拷贝,不共享内存
b.dtype
torch.float32
c = torch.from_numpy(a)# 注意c的类型(DoubleTensor)
c
tensor([[1., 1., 1.],
[1., 1., 1.]], dtype=torch.float64)
a[0, 1] = 100
b # b与a不共享内存,所以即使a改变了,b也不变
tensor([[1., 1., 1.],
[1., 1., 1.]])
c # c与a共享内存
tensor([[ 1., 100., 1.],
[ 1., 1., 1.]], dtype=torch.float64)
注意: 不论输入的类型是什么,t.tensor都会进行数据拷贝,不会共享内存
tensor=torch.tensor(a)
tensor[0,0]=0
a
array([[ 1., 100., 1.],
[ 1., 1., 1.]])
3.1.3 广播法则
广播法则(broadcast)是科学运算中经常使用的一个技巧,它在快速执行向量化的同时不会占用额外的内存/显存。
Numpy的广播法则定义如下:
- 让所有输入数组都向其中shape最长的数组看齐,shape中不足的部分通过在前面加1补齐
- 两个数组要么在某一个维度的长度一致,要么其中一个为1,否则不能计算
- 当输入数组的某个维度的长度为1时,计算时沿此维度复制扩充成一样的形状
PyTorch当前已经支持了自动广播法则,但是笔者还是建议读者通过以下两个函数的组合手动实现广播法则,这样更直观,更不易出错:
- unsqueeze或者view,或者tensor[None],:为数据某一维的形状补1,实现法则1
- expand或者expand_as,重复数组,实现法则3;该操作不会复制数组,所以不会占用额外的空间。
注意,repeat实现与expand相类似的功能,但是repeat会把相同数据复制多份,因此会占用额外的空间。
a = torch.ones(3, 2)
b = torch.zeros(2, 3,1)
a + b
# 自动广播法则
# 第一步:a是2维,b是3维,所以先在较小的a前面补1 ,
# 即:a.unsqueeze(0),a的形状变成(1,3,2),b的形状是(2,3,1),
# 第二步: a和b在第一维和第三维形状不一样,其中一个为1 ,
# 可以利用广播法则扩展,两个形状都变成了(2,3,2)
tensor([[[1., 1.],
[1., 1.],
[1., 1.]],
[[1., 1.],
[1., 1.],
[1., 1.]]])
# 手动广播法则
# 或者 a.view(1,3,2).expand(2,3,2)+b.expand(2,3,2)
a[None].expand(2,3,2) + b.expand(2,3,2)
tensor([[[1., 1.],
[1., 1.],
[1., 1.]],
[[1., 1.],
[1., 1.],
[1., 1.]]])
# expand不会占用额外空间,只会在需要的时候才扩充,可极大节省内存
e = a.unsqueeze(0).expand(10000000000000, 3,2)
3.2 Pytorch的层次结构
Pytorch中一共有5个不同的层次结构,分别为硬件层、内核层、低阶API、中阶API和高阶API(torchkeras)
| 硬件层 | 底层的计算资源包括CPU和GPU |
|---|---|
| 内核层 | 使用C++来实现 |
| 低阶API | Python实现的操作符,提供了封装C++内核的低级API指令,主要包括各种张量操作算 子、自动微分、变量管理. 如torch.tensor,torch.cat,torch.autograd.grad,nn.Module. |
| 中阶API | Python实现的模型组件,对低级API进行了函数封装,主要包括各种模型层,损失函数,优化器,数据管道等等。 如 torch.nn.Linear,torch.nn.BCE,torch.optim.Adam,torch.utils.data.DataLoader. |
| 高阶API | Python实现的模型接口。Pytorch没有官方的高阶API。为了便于训练模型,我们仿照 keras中的模型接口,使用了不到300行代码,封装了Pytorch的高阶模型接口 torchkeras.Model |
3.3 数据
Pytorch主要通过Dataset和DataLoader进行构建数据管道
3.3.1 Dataset and DataLoader
| Dataset | 一个数据集抽象类,所有自定义的Dataset都需要继承它,并且重写__getitem__()或__get_sample__()这个类方法 |
|---|---|
| DataLoader | 一个可迭代的数据装载器。在训练的时候,每一个for循环迭代,就从DataLoader中获取一个batch_sieze大小的数据。 |
5.2 数据读取与预处理
DataLoader的参数如下
DataLoader(
dataset,
batch_size=1,
shuffle=False,
sampler=None,
batch_sampler=None,
num_workers=0,
collate_fn=None,
pin_memory=False,
drop_last=False,
timeout=0,
worker_init_fn=None,
multiprocessing_context=None,
)
主要实用的数据如下(着色):

介绍一下Epoch、Iteration、Batchsize之间的关系:

dataloader读取数据的流程为:

-
从DataLoader开始
-
进入DataLoaderIter,判断单线程还是多线程
-
进入Sampler进行采样,获得一批一批的索引,这些索引告诉我们需要读取哪些数据、
-
进入DatasetFetcher,依据索引读取数据
-
Dataset告诉我们数据的地址
-
自定义的Dataset中会重写__getietm__方法,针对不同的数据来进行定制化的数据读取
-
到这里就获取的数据的Text和Label
-
进入collate_fn将之前获取的个体数据进行组合成batch
-
一个一个batch组成Batch Data
from torch.utils.data import DataLoader
from torch.utils.data.dataset import TensorDataset
# 自构建数据集
dataset = TensorDataset(torch.arange(1, 40))
dl = DataLoader(dataset,
batch_size=10,
shuffle=True,
num_workers=1,
drop_last=True)
# 数据输出
for batch in dl:
print(batch)
参考:【Pytorch】2022 Pytorch基础入门教程(完整详细版