multimodal prompting
Prompting for Multimodal Hateful Meme Classification
这篇文献探讨了针对hateful memes的分类问题,提出了一种基于提示的方法(PromptHate),该方法利用预训练的语言模型来实现分类。由于hateful memes需要复杂的推理和上下文背景知识,因此很难用传统的方法进行分类。作者认为可以利用外部的显式知识库来补充上下文和文化信息,但目前还没有已知的外部知识库可以提供这样的恶意言论上下文信息。因此,PromptHate方法通过构建简单的提示和提供一些上下文示例,利用预训练的RoBERTa语言模型中的隐含知识来进行恶意网络迷因的分类。实验结果表明,PromptHate能够实现较高的分类精度,优于现有的基线方法。
Multimodal Chain-of-Thought Reasoning in Language Models
这篇文献描述了一种名为Multimodal-CoT的新型大型语言模型(LLM),该模型将语言和视觉信息相结合,以生成更好的中间推理链来推理答案。与现有的CoT研究侧重于单一语言模态不同,Multimodal-CoT提出了一种两阶段的框架,将推理链生成和答案推理分开。
现有工作的问题:
1.最直接的方法是将不同模态的输入转换为一种模态,并提示LLM执行CoT。例如用image caption来做图片转化为文字,但是,在标题生成过程中存在严重的信息丢失问题,因此使用标题(而不是视觉特征)可能会在不同模态的表示空间中缺乏相互协作。
2.另一个解决方案是通过融合多模态特征来微调更小的语言模型,以便能够调整模型体系结构以合并多模态特征。由于这种方法允许调整模型体系结构以合并多模态特征的灵活性,因此该文献研究了微调模型而不是提示LLM的方法。然而,关键的挑战是,参数在100亿以下的语言模型往往会生成幻觉推理链,从而误导答案推理。这也暗示着在使用这种微调方法时,需要对模型进行进一步的优化和调整,以解决这些挑战。
优化Cot的方法有两方面:1.优化实例,2.优化推理链
文章分析为什么CoT会失效?e hallucinated rationales that mislead the answer inference
作者观察到融入了视觉信息后CoT能够解决很多hallucinated rationales的问题。
A Multitask, Multilingual, Multimodal Evaluation of ChatGPT on Reasoning, Hallucination, and Interactivity
这篇论文提出了一个框架,用于定量评估交互式LLM(如ChatGPT)的性能,并使用公开可用的数据集对ChatGPT进行广泛的技术评估。作者使用23个数据集涵盖8个不同的常见NLP应用任务,评估了ChatGPT的多任务、多语言和多模态方面,并根据这些数据集和新设计的多模态数据集对其进行评估。作者发现,在大多数任务上,ChatGPT比zero-shot的LLM表现更好,甚至在某些任务上甚至比微调模型表现更好。作者还发现,ChatGPT在理解非拉丁文字语言方面比生成这些语言更好。此外,ChatGPT能够从文本提示生成多模态内容,通过中间代码生成步骤实现。但是,作者还发现,ChatGPT在逻辑推理、非文本推理和常识推理的10个不同推理类别中的平均准确率仅为63.41%,因此不是可靠的推理者。ChatGPT像其他LLM一样存在幻觉问题,而且它从其参数存储中生成更多外在幻觉,因为它没有访问外部知识库。
论文做了大量的实验,虽然所有的实验的测试集都是很小的一个子集,但一定程度上还是能够说明chatgpt比较适合哪一类任务。
See, Think, Confirm: Interactive Prompting Between Vision and Language Models for Knowledge-based Visual Reasoning
这篇文献介绍了一个名为Interactive Prompting Visual Reasoner (IPVR)的框架,旨在解决知识驱动的视觉推理任务,该任务要求模型全面理解图像内容,连接外部世界知识,并逐步进行推理以正确回答问题。IPVR包含三个阶段:看、想、确认。在看阶段,IPVR扫描图像并使用视觉感知模型对视觉概念进行定位。在想阶段,IPVR采用预训练的大型语言模型 (LLM) 来自适应地关注候选概念。然后,它将它们转换为文本上下文以进行视觉字幕提示,并采用LLM生成答案。在确认阶段,IPVR进一步使用LLM生成支持答案的理由,使用跨模态分类器验证生成的理由,并确保理由可以一致地推断预测的输出。
语言模型在视觉与语言任务中进行推理的方法主要分为两类。第一类是增加附加的视觉感知模块,将视觉输入编码,通过大量的视觉与语言数据对模型进行微调。虽然这种方法在下游视觉推理任务中能够实现高性能,但需要一个大的视觉与语言数据集来微调LLM和新的视觉模块,并且通常计算密集且耗时。第二类是使用基于prompt的方法进行视觉推理。例如,PICa 将图像翻译为caption,然后将其用作GPT-3的文本prompt输入来回答问题。尽管它们在知识驱动的视觉问题回答上具有高精度,但是它们的模型也存在局限性。首先,在PICa中,caption处理与问题的语义无关,限制了字幕只能关注图像的一般方面而不是与问题相关的对象。其次该方法无法提供step by step 的推理,使得问题回答成为一个黑盒过程。
在该文献中,作者讨论了IPVR模型的"confirm"阶段中确认预测的理由的两个重要方面。首先,所提供的理由应该与答案一致。例如,在图2中,对于答案“meat”的预测支持理由应该是“刀子是用来切肉的”,当将其添加到上下文中时,我们应该能够预测相同的答案。其次,理由应该与视觉输入一致。换句话说,理由应该是通过视觉感知模型从图像中推导出来的,并且与图像内容和前面迭代中预测的答案一致。这两个方面都有助于提高模型的可靠性和可解释性。
该方法任然受到目标检测模块的限制,也许开放的目标检测模型会更好一点?
PromptCap: Prompt-Guided Task-Aware Image Captioning
这篇文献的主要内容是关于图像描述和自然语言处理相结合的一个新方法,名为PromptCap。图像描述任务的目标是用自然语言描述图片的内容,使得强大的语言模型能理解图像。尽管在多种视觉-语言任务上,图像描述与语言模型的结合取得了成功,但一个图像包含的信息远远超过一个句子,因此可能会导致描述中遗漏重要的视觉细节。这在视觉问答(VQA)任务中尤为明显。
为了解决这一挑战,作者提出了PromptCap模型,该模型利用自然语言提示来控制生成的描述内容。提示包含一个问题,描述应有助于回答这个问题,并支持使用图像中的辅助文本输入,如场景文字。为了在普通图像描述模型中微调引导提示功能,作者提出了一个利用GPT-3和现有VQA数据集合成和过滤训练示例的流程。
评估方面,作者使用了一个现有的基于图像描述进行VQA的流程,并使用同一个语言模型,通过比较QA准确率来验证生成的描述与问题提示的相关性。实验结果显示,PromptCap在多种VQA任务上的表现优于普通描述方法,分别在OK-VQA和A-OKVQA数据集上达到了58.8%和58.0%的最新准确率。此外,对WebQA的零样本实验表明PromptCap能很好地泛化到未见过的领域。
在这项研究中,作者提出了PromptCap,它通过在生成描述时使用与任务相关的提示,生成更适合下游任务的视觉描述。尽管本研究的重点是将问题作为提示,但其他与任务相关的指令或辅助信息(如使用OCR从图像中提取的文本,在图1(c)中的TextVQA任务中),也可以类似地加以整合。这意味着PromptCap不仅可以针对问题生成有针对性的描述,还可以根据其他任务相关信息生成更丰富、更具针对性的图像描述。
IS CHATGPT A GENERAL-PURPOSE NATURAL LANGUAGE PROCESSING TASK SOLVER?
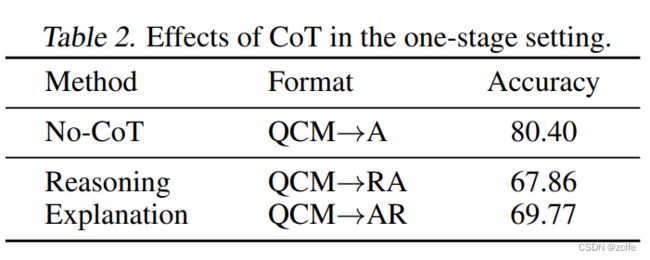
这篇文献研究了ChatGPT是否能够作为一个通用的自然语言处理任务求解器。近来,随着大规模语言模型的发展,它们已经展示出了在许多NLP任务中可以zero-shot学习的能力。最近,ChatGPT的推出引起了NLP社区的广泛关注,因为它可以根据人类输入生成高质量的响应,并根据后续对话进行自我修正。但是,目前还不清楚ChatGPT能否作为一个通用模型来zero-shot执行许多NLP任务。本文通过评估ChatGPT在涵盖7个代表性任务类别的20个流行NLP数据集上的表现,对ChatGPT的zero-shot学习能力进行了实证分析。通过广泛的实证研究,作者展示了当前版本的ChatGPT的有效性和局限性。作者发现,ChatGPT在许多强调推理能力的任务(例如算术推理)上表现良好,但在解决特定任务(例如序列标注)时仍面临挑战。此外,作者还通过定性案例研究进行了深入分析。
进行了7大类任务的评测:1.reasoning,2.natural language inference,3. question answering, 4. dialogue, summarization, 5. named entity recognition, 6. sentiment analysis.
尽管ChatGPT表现出了一定的通用性,可以执行多个任务,但在某些任务上,它通常表现不如针对特定任务微调的模型。ChatGPT在算术推理任务中表现出了优越的推理能力,但在常识、符号和逻辑推理任务中表现不佳,例如会生成不确定的响应。ChatGPT在自然语言推理和阅读理解等需要推理能力的任务中表现出了优异的性能,特别是在处理一致性文本时表现更佳。ChatGPT在对话任务中表现优于GPT-3.5,但在摘要任务中表现较差。此外,ChatGPT和GPT-3.5在某些任务上仍然面临挑战,例如序列标注任务。ChatGPT的情感分析能力接近于GPT-3.5。
ChatGPT generates longer summaries and performs worse than GPT-3.5 for summarization tasks. However, explicitly limiting summary length in the zero-shot instruction harms the summarization quality, leading to even worse performance.
Learn to Explain: Multimodal Reasoning via Thought Chains for Science Question Answering
科学QA的数据集
AUTOMATIC CHAIN OF THOUGHT PROMPTING IN LARGE LANGUAGE MODELS
这篇文献的核心是介绍了一种名为Auto-CoT的自动CoT提示方法,旨在通过生成推理链构建自动化的演示,以解决手动设计示范的缺点。为了减少推理链中可能出现的错误。Auto-CoT使用多样性采样问题,并生成推理链来构建示范。该方法主要包括两个步骤:将给定数据集的问题分成几个聚类,从每个聚类中选择一个代表性问题,并使用基于Zero-Shot-CoT生成其推理链来构造示例。
ICL中样例的多样性可能是一个关键。其实关键就是修改选取example的方式。
example与问题越相似,example的答案越会影响问题的答案。
PARAMETER-EFFICIENT FINE-TUNING DESIGN SPACES
这篇文献介绍了参数高效微调的设计范式和发现的适用于不同实验设置的设计模式。相比于关注于设计新的微调策略,文献提出了参数高效微调设计空间,该空间参数化微调结构和微调策略。具体而言,任何设计空间由四个组成部分组成:层分组,可训练参数分配,可调节组和策略分配。从一个初始设计空间开始,作者逐步基于每个设计选择的模型质量进行空间细化,并在这四个组成部分中的每个阶段进行贪心选择。作者发现以下设计模式:(i)以纺锤形式组合层;(ii)将可训练参数数量均匀分配到各层中;(iii)微调所有组;(iv)将适当的微调策略分配给不同的组。这些设计模式产生了新的参数高效微调方法。作者在自然语言处理的不同任务和不同主干模型上进行了实验,表明这些方法在各方面都显著优于现有的参数高效微调策略。
KAT: A Knowledge Augmented Transformer for Vision-and-Language
有意思的结论:隐式知识已经可以比显式知识更好地帮助模型补充知识了。
MM-REACT : Prompting ChatGPT for Multimodal Reasoning and Action
为了将图片和视频作为输入给chatgpt,论文直接将两者的文件路径作为chatgpt的输入,将图片和视频认为一个黑盒,当需要视觉内容的时候,chatgpt再去寻求vison expert的帮忙。这个任务主要聚焦于vision understanding的问题。
Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
ViperGPT: Visual Inference via Python Execution for Reasoning
Visual Prompt Multi-Modal Tracking
A Survey of Large Language Models
大模型的优势:
1.cot 拥有一定程度的推理能力
2.拥有一定程度的常识
3.输入和输出的通用性,通过自然语言进行交互
大模型的劣势:
1.难以微调,通常要做zero-shot或者few-shot
2.很难判断产生的结果是否正确,需要更仔细地辨认