(2023|AAAI,MS-VQGAN,分层扩散,PyU-Net,粗到细调制)Frido:用于复杂场景图像合成的特征金字塔扩散
Frido: Feature Pyramid Diffusion for Complex Scene Image Synthesis
公众号:EDPJ(添加 VX:CV_EDPJ 或直接进 Q 交流群:922230617 获取资料)
目录
0. 摘要
1. 简介
2. 基础
3. 方法
3.1 学习多尺度感知潜在
3.2 特征金字塔潜在扩散模型
4. 实验
4.1 数据集和评估
4.2 条件复杂场景生成
4.3 模型分析
5. 相关工作
6. 结论
附录
E. 附加讨论
E.1 限制和未来方向
S. 总结
S.1 主要贡献
S.2 架构和方法
0. 摘要
Frido 是一种特征金字塔扩散模型,用于图像合成,尤其适用于复杂场景。它通过多尺度的从粗到细的去噪过程来生成图像,可以很好地描述图像的全局结构和对象细节。该模型将输入图像分解为依赖于尺度的矢量量化特征,然后进行从粗到细的调制以生成图像输出。在多尺度表示学习阶段,还可以利用额外的输入条件,如文本、场景图或图像布局。因此,Frido 也适用于有条件的或跨模态的图像合成。作者进行了广泛的实验,涵盖了各种无条件和有条件的图像生成任务,包括从文本到图像的合成、从布局到图像、从场景图到图像以及从标签到图像。具体来说,在五个基准任务上,即在 COCO 和 OpenImages 上的布局到图像、在 COCO 和 Visual Genome 上的场景图到图像,以及在 COCO 上的标签到图像,Frido 实现了最先进的 FID 分数。
代码地址:https://github.com/davidhalladay/Frido
1. 简介
在计算机视觉研究中,生成逼真的照片是一项关键任务。在这个任务中,设计一个生成模型,该模型能够学习给定一组图像的潜在数据分布,并能够从所学分布中合成新样本。为实现这一目标,提出了一系列方法,包括 VAEs(Kingma和Welling 2014; Van Den Oord,Vinyals等,2017),GANs(Goodfellow等,2014; Radford,Metz和Chintala,2015),基于流的方法(Dinh,Krueger和Bengio,2014; Kingma和Dhariwal,2018),以及流行的扩散模型(DMs)(Sohl-Dickstein等,2015; Ho,Jain和Abbeel,2020)。随着这些工作的贡献,生成图像的质量得到了快速提高。此外,这一任务本身也从无条件的以目标为中心的图像合成发展到了复杂场景图像生成,有时是基于多模态条件(例如文本、布局、标签和场景图)。

最近,扩散模型(Ho、Jain和Abbeel 2020; Nichol和Dhariwal 2021; Ho等人 2022; Rombach等人 2022; Ramesh等人 2022)展示了在高质量图像合成方面具有卓越能力,并在多个任务上胜过其他生成方法,包括但不限于无条件图像生成、文本到图像生成和图像超分辨率。尽管有了令人鼓舞的进展,但扩散模型可能在目标图像更加复杂且条件输入高度抽象的情况下表现不佳。在这些任务中,对象和部分的组合以及高级语义关系占主导地位,这些在早期以目标为中心的基准测试中较少见,可能对更高质量的生成至关重要。
特别是,我们指出现有 DM 工作中存在两个主要挑战。首先,大多数现有的 DM 处理单一尺度/分辨率下的特征图或图像像素,这可能无法捕捉现实世界复杂场景中的图像语义或组合。以图 1 的第一行为例,可以看到,虽然 LDM(Rombach等人 2022)基于文本条件生成了包含 “人” 的图像,但 “骑摩托车” 和 “背景中的山” 等语义结构没有得到充分表现。其次,通常需要大量的计算资源来训练和测试 DM,因为需要进行迭代去噪过程,特别是用于生成高分辨率输出。这不仅限制了可访问性,还导致大量的碳排放。因此,一种能够利用粗略/高层次合成输出引入多尺度视觉信息的计算效率高的扩散模型将是可取的。
为了解决这些限制,我们提出了 Frido(Feature Pyramid Diffusion model),一种用于生成复杂场景图像的特征金字塔扩散模型。Frido 是一种新颖的多尺度粗到细扩散和去噪框架,允许合成具有增强全局结构保真度和逼真物体细节的图像。具体来说,我们引入了一种新颖的特征金字塔 U-Net(PyU-Net)和粗到细的调制设计,使我们的模型能够以自上而下的方式去噪来自多个空间尺度的视觉特征。这些多尺度特征由我们的 MS-VQGAN 生成,这是一种新设计的 VQGAN 的多尺度变种,它将图像编码成多尺度视觉特征(离散潜在编码)。如图 1 所示,随着特征逐渐去噪,图像以从全局结构到细粒细节的粗到细的方式重建(由我们的 MS-VQGAN 解码器解码)。另一方面,最近的一种竞争性扩散模型(Rombach等人 2022)在空间尺度上均匀重建图像。
Frido 是一个通用的扩散框架,可以从多种多样的多模态输入合成图像,包括文本、盒式布局、场景图和标签。此外,我们的模型引入了最少的额外参数,同时允许我们加速传统 DM 的明显缓慢的推理。进行了大量实验来展示新设计的有效性。
我们的贡献总结如下:(i) 我们提出了 Frido,一种新颖的扩散模型,用于从多模态输入生成逼真的图像,具有扩散模型范式中尚未充分探索的粗到细的先验。 (ii) 从实证角度看,我们取得了 5 个新的最先进的成果,包括 COCO 和 OpenImages 上的布局到图像、COCO 和 Visual Genome上的场景图到图像以及 COCO 上的标签到图像,所有这些都是具有高度抽象条件的复杂场景。 (iii) 在实践中,Frido 的推理速度很快,通过与已经很快的扩散模型 LDM 进行了并排比较来展示。
2. 基础
已经提出了多种生成逼真照片的方法,包括 VAEs、GANs 和 Invertible-Flows,并在以目标为中心的图像方面取得了令人印象深刻的结果。然而,VAEs 存在模糊的输出。GANs 训练困难,缺乏多样性。基于流的模型由于不完美的逆变换而遭受形状扭曲。我们的工作属于扩散模型(DMs)的范式,已经被证明在所有深度生成方法中,最能合成高质量的图像。为了完整起见,我们总结了 DMs 的基本原理以及最近的改进,即潜在扩散模型(LDMs)(Rombach等人 2022)。
3. 方法
尽管现有的 DM(扩散模型)可以为单个对象生成具有出色质量的高分辨率图像,但它们大多只处理单一分辨率的特征图或图像像素。因为它们平等地对待高低级别的视觉概念,这使得这些 DM 模型难以描述相应的图像语义或构成。这可能限制了它们用于合成复杂场景图像的能力。
为了增强 DM 的全局结构建模,我们提出通过特征金字塔以粗到细的方式对潜在特征进行建模。首先,我们引入了多尺度矢量量化模型(Multi-Scale Vector Quantization model,MS-VQGAN),它将图像编码为多个空间层次的潜在编码。接下来,我们提出了特征金字塔扩散模型(Frido),将扩散和降噪扩展到多尺度、粗到细的方式。为了实现这一目标,我们设计了一种新的特征金字塔U-Net(PyU-Net),配备了特殊的调制机制,允许进行粗到细的学习。在本节中,我们将详细介绍每个组件。
3.1 学习多尺度感知潜在
在以粗到细的方式对图像进行建模之前,我们首先将图像编码成具有多个空间分辨率的潜在编码。借鉴于 VQGAN(Esser, Rombach, and Ommer 2021),我们训练了一个多尺度自编码器,命名为 MSVQGAN,它包括特征金字塔编码器 E 和解码器 D。如图 3a 所示,给定图像 x_0,编码器 E首先生成一组 N 个尺度的潜在特征图集合
![]()
这里,N 表示特征图的数量(阶段数),c 表示特征的通道大小,s 表示最大特征图的大小。在这个设计中,我们鼓励 z^1 保留更低级别的视觉细节,而 z^N 代表更高级别的形状和结构。其次,在量化和融合之后,我们将这些特征上采样到相同的形状,将它们连接起来,然后将它们馈送到解码器 D 来重建图像 D(Z) = ~x_0。这个自编码器模块的目标函数是 x0 和 ~x0 之间的 L2 损失的加权和,以及 VQGAN 中的其他感知损失(补丁鉴别损失和感知重建损失)。
需要强调的是,通过这种设计,MS-VQGAN 不仅可以将输入图像编码成具有不同语义级别的多尺度编码,还可以保留更多的结构和细节,如后面模型去除的部分将在第 4.3 节中分析。
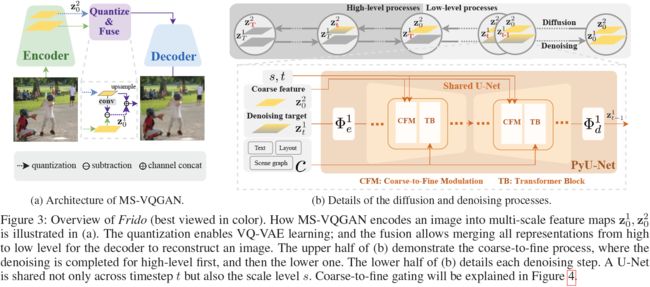
3.2 特征金字塔潜在扩散模型
在训练完成 MS-VQGAN 后,我们可以使用它将图像编码成多层次的特征图 Z。接下来,我们引入特征金字塔扩散模型(Frido)来建模底层特征分布,然后从噪声生成图像。与其他 DM 不同, Frido 包含两个部分:扩散过程和去噪过程。
Frido 的扩散过程。与在 T 步骤中同时在所有 N 个特征尺度 Z = {z^1, ..., z^N} 上添加噪声不同,我们按顺序进行扩散过程,从低级(z^1)到高级(z^N),每个级别进行 T 个扩散步骤(总共 N * T 个时间步),请参见图 3b 的上半部分。与经典的扩散过程(以无偏差的方式破坏像素成噪声)不同,我们观察到 Frido 的扩散过程从破坏对象的细节开始,然后是对象的形状,最后是整个图像的结构。这使 Frido 能够捕获不同语义级别的信息。请参见图 1 以获取定性示例。
Frido 的去噪过程。在去噪阶段,训练了一系列神经功能估算器 ε_(θ, t, n),其中 t = 1, 2, ..., T 且 n = N, N - 1, ..., 1。为了进行逐层去噪,我们引入了一种新颖的特征金字塔 U-Net(PyU-Net)作为神经逼近器。PyU-Net 可以按顺序从高级 z^N 到低级 z^1 去噪多尺度特征,实现从粗到细的生成。需要强调的是,与 LDM 不同,我们的 PyU-Net 更适合于粗到细的扩散,具有以下两个新特性:(1)共享的 U-Net,具有轻量的级别特定层,将不同级别的特征投影到共享空间,以便可以在所有级别重复使用较重的(heavier) U-Net,减少可训练参数,(2)粗到细的调制,以已经生成的高级特征为条件调制低级特征的去噪。
特征金字塔 U-Net(PyU-Net)。PyU-Net 是用于学习粗到细的去噪过程的模型。以 N = 2(Z = {(z^1)_0,(z^2)_0})为例,PyU-Net 接受四个输入:(1)阶段 s 和时间步 t 的嵌入,(2)高级特征条件 (z^2)_0,(3)目标特征图 (z^1)_t,以及(4)其他跨模态条件 c。通过共同观察这些输入,PyU-Net 预测应用于目标特征 (z^1)_t 上的噪声 ε,如图 3b 所示。
与为每个级别 n 使用单独的 U-Net 不同,我们选择使用单个共享的 U-Net 以减少参数数量。首先,输入去噪目标 (z^1)_t 由级别特定的层 (Φ^1)_e 投影到共享空间,以便应用共享的 U-Net。最后,另一个级别特定的投影 (Φ^1)_d 将 U-Net 的输出解码为添加到 (z^1)_t 上的噪声 ε,其目标与等式(3)类似。
![]()
![]()
我们注意到 PyU-Net 不仅减少了可训练参数的数量,而且与普通的逐级 U-Net 相比,还改善了结果。关于分析,请参考实验部分。另外,为了提高训练效率,我们采用了类似于序列到序列语言模型(Brown等人,2020)的 “教师强制” 技巧,即在去噪低级特征图时使用了真实的特征条件。
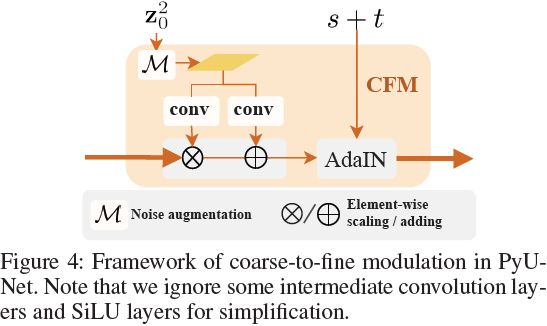
Frido 按顺序从高级到低级特征图生成潜在编码。例如,在生成 (z^1)_t(低级)时,模型会以 (z^2)_0(高级)为条件。因此,我们引入了如图 4 所示的粗到细的调制。
我们的粗到细的调制(coarse-to-fine modulation,CFM)旨在将 2D 高级特征以及 1D 阶段和时间嵌入引入残差块,使 Frido 具有高级特征以及阶段-时间感知。因此,在我们提出的 CFM 中,有两种类型的调制依次应用于归一化特征,其中插入了额外的卷积(conv)和 SiLU 层(Elfwing,Uchibe和Doya 2018)。
具体来说,给定高级别的真实特征 (z^2)_0,我们通过 M(z20) = z
![]()
![]()
进行噪声增强。其中, ε ~ N(0, I),λ 是一个超参数。然后,假设 CFM 的输入是 f_i,在第一次调制中,我们使用两个卷积操作,分别使用来自高级特征 f_z 的 2D 缩放和平移参数来调制归一化特征 norm(f_i),生成中间表示 h,如下所示:
![]()
在第二次调制中,为了赋予 U-Net 阶段-时间意识,我们进一步用 1D 阶段+时间嵌入来调制 h,并生成输出 f_o,类似于等式 6。需要注意的是,我们使用线性层来转换 s + t,还在 AdaIN(Huang 和 Belongie 2017)之后添加了卷积和 SiLU。
总结一下,需要强调的是,我们的 PyU-Net 框架使 DM 具备了以粗到细方式学习的能力,与传统的分层学习策略(Razavi、Van den Oord 和 Vinyals 2019)相比,参数适度增加。Frido 继承了三种生成范式,即 VAE、GAN 和 DM,并进一步嵌入了粗到细的先验。此外,扩散首先在低分辨率地图上运行,从而在推理过程中实现了加速。接下来,我们将展示在与强大、快速 DM 相似的计算预算下可以实现最先进的结果。
总结一下,需要强调的是,我们的 PyU-Net 框架使 DM 具备了以粗到细方式学习的能力,与传统的分层学习策略(Razavi、Van den Oord 和 Vinyals 2019)相比,参数适度增加。Frido 继承了三种生成范式,即 VAE、GAN 和 DM,并进一步嵌入了粗到细的先验。此外,扩散首先在低分辨率图上运行,从而在推理过程中实现了加速。接下来,我们将展示在与强大、快速 DM 相似的计算预算下可以实现最先进的结果。
4. 实验
在这一部分,我们通过文本到图像生成、场景图到图像生成和标签到图像生成任务的角度,经验性地证明了 Frido 生成了高质量的复杂场景图像,这些图像也与多模态条件一致。此外,为了强调在图像中全局捕捉多个对象的能力,我们进行了布局到图像生成任务的实验。最后,我们进行了广泛的分析来验证设计选择。我们展示了 Frido 在 5 种设置下实现了多个任务的最先进的 FID 分数,并提高了推理速度。
注释。Frido 可以在不同的特征分辨率和级别下进行训练。为简单和可读性起见,一个潜在特征图,其中每个特征对应于 n x n 的原始图像像素,被表示为 fn。例如,一个用于生成 256 x 256 图像的 Frido,使用 32 x 32 的高级和 64 x 64 的低级潜在编码,表示为 Frido-f8f4。对于 LDM 基线,LDM-n 对 n x n 像素进行编码。
4.1 数据集和评估
我们考虑的主要任务是在 COCO 上进行文本到图像生成(T2I),在 COCO-stuff 和 Visual Genome 上进行场景图到图像生成(SG2I),在 COCO-stuff 上进行标签到图像生成(Label2I),以及在 COCO-stuff 和 OpenImages 上进行布局到图像生成(Layout2I)。用于评估图像合成任务的标准度量包括 Fréchet Inception 距离(FID)和 Inception score(IS)。此外,我们还考虑了其他特定任务的指标,如 CLIP 分数、精度和召回、SceneFID、YOLO 分数、PSNR 和 SSIM,视情况而定。在适用时,请参阅补充材料以获取详细设置。为了完整起见,我们还进行了用户偏好研究,并进行了无条件图像生成(UIG)的实验,包括 LSUN-bed、CelebA-HQ 和 Lanscape。由于页面限制,请参阅补充材料以获取更多结果。

4.2 条件复杂场景生成
文本条件图像生成。我们首先在 COCO 上进行标准的文本到图像(T2I)生成实验,结果如表 1 所示。我们考虑在 COCO train2014 分割上的标准训练设置。与最近在大规模图像文本对上预训练的 T2I 模型不同,我们的目标是从多样的条件中生成图像。在这种情况下,FID 用于测量图像质量,CLIP-Score 用于评估图像和文本的一致性。为了完整起见,也报告了 IS,尽管众所周知,FID 与人类判断的相关性强于 IS。除了标准的扩散推断,我们还报告了不使用分类器的引导的变种。如表 1 所示,对于两种推断类型,Frido 在 FID 上明显比先前的最佳模型 LDM 少 2,在 CLIP-Score 上多 1,实现了 FID(15.38 比 11.24)和 CLIP-Score(0.6607 比 0.7046)的最新得分。在不同的设置中,LAFITE(Zhou等,2022)合并了预训练的 CLIP(Radford等,2021),其中包含了来自 Web 规模数据对的丰富文本图像知识。作为将 CLIP 知识与 Frido 相结合的初始步骤,我们报告了仅在测试时使用 CLIP 排名技巧(Ding 等,2021)(10 次推断)的结果。我们可以看到,CLIPr 进一步显著提高了所有指标,实现了与 LAFITE 相当的 FID 和 CLIP-Score。将 CLIP 用于训练的方法与 LAFITE 类似,留给未来的研究。
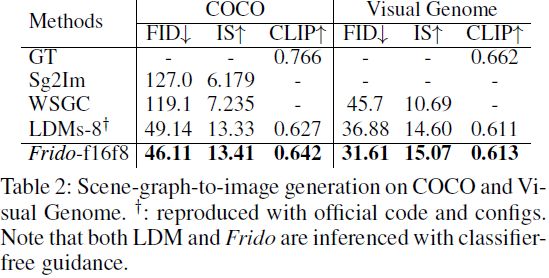
从场景图生成图像。为了进一步验证所宣称的语义关系捕捉,我们在 COCO-stuff 和 VG 数据集上运行 SG2I,并结果如表 2 所示。显然,Frido 在 FID 和 IS 方面均优于所有先前的方法,包括 sg2im(Johnson、Gupta和Li 2018)、WSGC(Herzig等2020)和 LDMs,实现了新的最新成就。此外,为了定量地衡量图像与其 SG 条件的语义正确性,我们将 SG 转换为标题,方法是连接关系三元组(即主谓宾),并报告生成的图像-标题对的 CLIP 分数。我们的模型在 COCO 上超过以前的工作 2%,在 VG 上超过 0.2%。这从经验上验证了使用特征金字塔和自上而下的生成策略,Frido 改进了复杂关系的建模。
标签到图像生成。标签到图像生成根据图像级标签生成场景图像。与 T2I 或 SG2I 不同,T2I 或 SG2I 的场景结构由文本条件指定,而此任务要求模型自由组合对象并生成连贯的图像。除了 FID 和 IS,还报告了目标级质量和多样性测量的精度和召回率。我们在 COCO-stuff 上进行了 Label2I的实验。如表 3 所示,我们的模型在 FID 和精度以及召回率方面均优于以前的方法,包括 LayoutVAE(Jyothi等2019)和 LDMs,而不仅在常见的 3-8 标签设置下。这表明,Frido 实现了更好的图像质量和多对象图像数据流形建模。我们进一步挑战 Frido,使用更困难的 2-30 标签设置,仍然建立了 SOTA FID。

布局到图像生成。我们的 Layout2I 结果展示了可以合成多个对象的形状和细节。具体来说,我们在两种不同的设置下将我们的 Frido 与以前的方法进行了比较。首先,我们遵循 LDM,并在COCO stuff 分割挑战分割和 OpenImage 数据集上进行实验。结果如表 4 所示。人们可以发现,Frido 在 FID 方面表现优于以前的方法,包括 LostGAN-v2(Sun和Wu 2019)、OC-GAN(Sylvain等2021)、SPADE(Park等2019)、VQGAN+T(结合Esser,Rombach和Ommer 2021和Brown等人2020)和 LDM,至少提高了 2,实现了 COCO 和 OpenImages 的最新最高水平。此外,我们获得了最佳的 YOLO 分数和 sceneFID,表明了最逼真的实例级对象。 其次,我们遵循 TwFA(Yang等2022)并在标准的 COCO stuff 和 Visual Genome 数据集上进行实验。更多详细信息请参阅补充材料。
4.3 模型分析
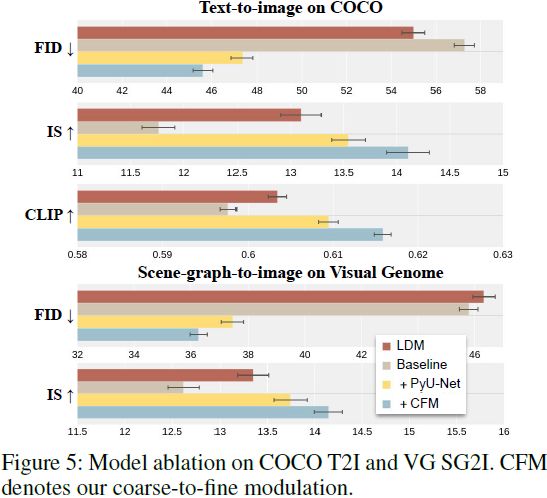
模型消融。为验证 Frido 的关键创新设计,我们在两个任务上进行了消融研究:在 COCO上 进行文本到图像(T2I)和在 Visual Genome 上进行场景图到图像(SG2I)。图 5 展示了 Frido 中每个部署组件的贡献。在消融和超参数调整中,我们进行了 250,000 次迭代的训练,以进行更多的实验。具有最佳开发分数的模型进一步进行训练,以获得第 4.2 节中的最终测试分数。我们通过进行 Bootstrap 检验(Koehn 2004)报告均值和相应的 95% 置信区间;采样大小等于测试集大小;重新采样 100 次。对于基线,我们使用了两个 LDM,并执行了简单的顺序学习策略。具体来说,第一个 LDM 学习高级特征映射的分布(LDM-16);第二个 LDM 用于建模 f8 的低级特征(LDM-8)。在此基线模型中,我们将 LDM-8 的输出特征映射和去噪目标特征级连输入 LDM-8 进行去噪。为了验证 PyU-Net 的共享 U-Net 设计,我们首先将此模块应用于没有 CFM 的基线。共享 U-Net 将模型参数从 1.18B(基线)减少到 590M(基线+PyU-Net)。最后,添加了粗到细的调制,参数数量仅略微增加(总共为 697M),并进一步提高了所有指标的性能。我们可以看到,每个组件都显着提高了生成结果;具有 PyU-Net 和 CFM 的模型在所有指标上均显着优于 LDM。
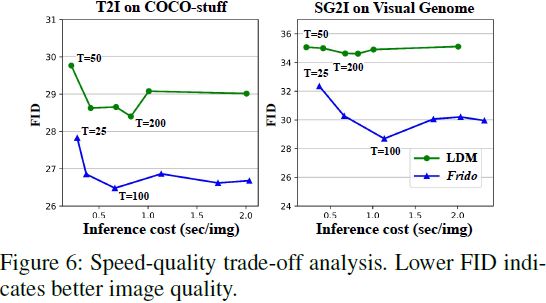
计算成本分析。在这里,我们分析了我们模型的推断成本。在图 6 中,我们比较了 Frido 和 LDM 在速度和质量权衡上的表现。在这个图中,我们使用不同的推断时间步长 T 进行推断每个模型,然后绘制 FID 分数和每个图像的推断成本。请注意,这些实验是在验证数据集上进行的,批处理大小为 32,使用 1 个 V100 GPU。结果表明,在类似的推断预算下,Frido 相对于 LDM 实现了不错的性能提升,从而证实了我们模型的高效性。有关 FLOP、参数数量和推断时间的其他比较,请参阅补充材料。需要注意的是,通过在潜在空间中操作,LDM 在 DM 模型类别中属于更快速的模型之一。Frido 通过将部分去噪负载放在低分辨率处进一步降低了成本。
总结。经验研究表明,Frido 在复杂场景图像合成方面明显优于基线 LDM,甚至在 5 个设置中取得了最佳成绩。我们的建模创新,包括 PyU-Net 和粗到细的调制,在统计上是有效的。最重要的是,Frido 更加高效,正如在与 LDM 的对比中所看到的,它减轻了扩散模型的推断成本,这是众所周知的。
5. 相关工作
更多的图像合成生成模型。在过去的十年里,图像合成领域取得了巨大的进展。除了前面讨论的作品外,GAN(生成对抗网络)家族(Liao等人,2022;Xu等人,2018;Karras,Laine和Aila,2019;Brock,Donahue和Simonyan,2019;Gafni等人,2022;Zhang等人,2021;Hinz,Heinrich和Wermter,2020;Karras等人,2021)、VAE(变分自动编码器)(Sohn,Lee和Yan,2015)、自回归模型(Razavi,Van den Oord和Vinyals,2019;Chang等人,2022;Yu等人,2022)、基于流的方法(Dinh,Sohl-Dickstein和Bengio,2017)、以及基于扩散的模型(Saharia等人,2022;Gu等人,2022)都为塑造这个领域做出了重大贡献。Frido 是 VAE 和 DM 家族的混合体,结合了两者的优点,以在复杂场景上获得出色的图像质量,并显着提高了 DM 的推断效率。最近,大规模的文本到图像生成预训练模型(Ramesh等人,2022)引起了广泛关注,并取得了卓越的结果。Frido 与这些模型是正交的,因为我们研究了粗到细的合成和多模态输入,不仅限于文本。
两阶段生成模型。最近,提出了许多两阶段生成模型(Van Oord,Kalchbrenner和Kavukcuoglu,2016;Jahn,Rombach和Ommer,2021;Pandey等,2022),用来解决单阶段模型的缺点。代表性的 VQ-VAE(Van Den Oord,Vinyals等,2017)首先将图像编码为具有较低空间分辨率的离散潜空间,然后使用自回归网络来对这种空间进行建模。第一步被称为向量量化(VQ),它减少了输入信息以允许自动编码器学习。此外,VQ 通过将图像转换为离散标记,无缝地将图像与其他模态(如语言(Ding等,2021;Chen等,2020)和音频(Yan等,2021))相连接。在第二阶段,采用了自回归(例如PixelCNN(Van den Oord等,2016),VQGAN)或扩散模型(LDM,VQ-Diffusion(Tang等,2022))来对编码的潜空间进行建模。Frido 通过提出 MS-VQGAN 和 PyU-Net 来贡献于这两个阶段。
粗到细的图像生成方法。与一步生成完整分辨率图像不同,粗到细的生成方法通过多个步骤合成图像,从像素空间中的低到高分辨率(Gregor等,2015;Mansimov等,2016)或从潜在空间中的高级到低级信息(Razavi,Van den Oord和Vinyals,2019;Child等,2019)。这使得模型更好地捕捉不同级别的信息,并已被证明可以实现更高的质量。例如,AttnGAN(Xu等,2018)和StackGAN(Zhang等,2017,2018)首先在低分辨率(例如,完整尺寸的1/8)上生成图像,然后迭代地扩大生成的图像,直到达到最终分辨率。与上述方法不同,我们为每个尺度共享了核心网络。因此,与单尺度模型相比,开销最小化。
6. 结论
我们提出了 Frido,这是一种新的图像生成模型,为扩散模型家族中未充分探索的粗到细的先验提供了支持。通过大量实验证明,关键设计,如多尺度码本、单一共享的 U-Net 和特殊的调制机制,是有效的。从经验的角度来看,我们将这个模型应用到各种不同的跨模态图像合成任务中,实现了 5 个新的最新成果。从实际的角度来看,Frido 还减轻了扩散方法已知的慢推理问题。
附录
E. 附加讨论
E.1 限制和未来方向
我们观察到,每个尺度上由 MS-VQGAN 编码的特征的分布没有被正则化,导致不同尺度上的特征的均值和标准差变化很大。这可能会对扩散模型的学习产生负面影响。具体而言,在扩散过程中,嘈杂的数据是通过将输入特征与标准正态变化进行插值而创建的,这要求输入特征的分布最好是均值为 0,标准差为 1。因此,非正则化的输入特征可能不会像预期的那样在扩散过程中被破坏成噪音,从而损害了降噪过程的学习。在这篇论文中,我们通过独立地缩放每个尺度的特征,并使用相应特征的标准差的倒数来减轻这个问题。然而,我们认为需要一个正则化目标来限制这种量化过程中编码的潜在分布,以供扩散模型使用。
另一个未来的潜在方向是探索 “特征中编码的高级或低级知识对于粗到细扩散模型的学习会有什么好处?” 在 Frido 中,我们设计了一个多尺度的 VQGAN,配备了特征金字塔融合模块,使我们能够将输入图像编码成具有多个尺度的特征,并隐式提取高级和低级信息。为了探索上述问题,我们可以通过向 MS-VQGAN 添加一个目标函数来引导在高级或低级特征上提取的信息。具体来说,可以施加一个重建损失,该损失是输入图像的低分辨率与仅由高级特征解码的重建图像之间的损失,以引导多尺度量化的过程。我们将这些方向留待未来的研究。
S. 总结
S.1 主要贡献
现有的 DM(扩散模型) 只处理单一分辨率的特征图或图像像素,限制了合成复杂场景的能力。本文提出通过特征金字塔扩散模型 Frido(Feature Pyramid Diffusion model),以粗到细的方式对潜在特征进行建模。
- 首先,使用多尺度矢量量化模型(Multi-Scale Vector Quantization model,MS-VQGAN)将图像编码为多个空间层次的潜在编码。
- 然后,使用特征金字塔扩散模型(Frido),将扩散和降噪扩展到多尺度、粗到细的方式。
S.2 架构和方法
学习多尺度感知潜在。如图 3a 所示,
- 首先,训练一个多尺度自编码器 MSVQGAN,来把输入图像编码为一组 N 个尺度的潜在特征图集合,不同的尺度分别保留低级视觉细节以及高级形状和结构。
- 在量化和融合之后,将这些特征上采样到相同的形状后连接起来,然后馈送到解码器来重建图像。
特征金字塔扩散模型(Frido)。与在 T 步骤中同时在所有 N 个特征尺度上添加噪声不同,按顺序进行扩散过程,从低级到高级,每个级别进行 T 个扩散步骤(总共 N * T 个时间步),参见图 3b 的上半部分。以两个特征尺度(低级(下),高级(上))为例,
1) 扩散阶段:
- 在低级特征处理阶段,固定高级特征(上),对低级特征(下)进行 T 个扩散步;
- 在高级特征处理阶段,固定低级特征(下),对高级特征(上)进行 T 个扩散步;
2) 去噪阶段:
- 在高级特征处理阶段,固定低级特征(下),对高级特征(上)进行 T 个去噪步;
- 在低级特征处理阶段,固定高级特征(上),对低级特征(下)进行 T 个去噪步;
特征金字塔 U-Net(PyU-Net)。通过将不同级别的特征投影到共享空间,可以在所有级别复用 U-Net,减少可训练参数;粗到细的调制,以已经生成的高级特征为条件调制低级特征的去噪。
- PyU-Net 有四个输入:阶段 s 和时间步 t 的嵌入、高级(粗糙)特征条件 (z^2)_0、目标特征图 (z^1)_t 以及其他跨模态条件(文本、布局、场景图等) c。
- 首先,输入去噪目标 (z^1)_t 由级别特定的层 (Φ^1)_e 投影到共享空间,以便应用共享的 U-Net。最后,另一个级别特定的投影 (Φ^1)_d 将 U-Net 的输出解码为添加到 (z^1)_t 上的噪声 ε。
粗到细调制。 详细框架如图 4 所示。M 表示噪声增强。
- 使用两个卷积操作获取来自高级特征的 2D 缩放和平移参数,来调制归一化特征,生成中间表示。
- 为了赋予 U-Net 阶段-时间意识,用 1D 阶段+时间嵌入来调制中间表示。