知识蒸馏论文翻译(9)—— Multi-level Knowledge Distillation via Knowledge Alignment and Correlation
知识蒸馏论文翻译(9)—— Multi-level Knowledge Distillation via Knowledge Alignment and Correlation
基于知识对齐和关联的多层次知识蒸馏
文章目录
- 知识蒸馏论文翻译(9)—— Multi-level Knowledge Distillation via Knowledge Alignment and Correlation
- 摘要
- 一、介绍
- 二、相关工作
- 三、多层次知识提炼
-
- 3.1 知识整合
- 3.2 知识关联
- 3.3 有监督的知识提炼
- 3.4 MLKD objective
- 四、知识量化度量
- 五、实验
- 六、结论
摘要
知识蒸馏(KD)已成为模型压缩和知识转移的重要技术。在这项工作中,我们首先对通过不同KD方法转移的知识进行全面分析。我们证明了传统的KD方法,即最小化网络间softmax输出的KL差异,只与单个样本的知识对齐有关。同时,目前基于对比学习的知识发现方法主要是在不同样本之间传递相关知识,即知识相关性。考虑到知识从多层次(MLKD)向学生的有效转移,我们认为知识从多层次(MLKD)向学生的有效转移很重要。MLKD是任务不可知论和模式不可知论的,可以很容易地从有监督或自我监督的预培训教师那里转移知识。我们发现,MLKD可以提高学习表征的可靠性和可转移性。实验表明,MLKD在大量实验环境下,包括不同的(a)预训练策略(b)网络结构(c)数据集(d)任务,都优于其他最先进的方法。
代码:https://github.com/pytorch/examples/tree/master/imagenet
一、介绍
深度神经网络最近在计算机视觉[39]和自然语言处理[4]方面取得了显著的成功,但它们需要较高的计算和内存需求,这限制了它们在实际应用中的部署。KD提供了一个很有希望的解决方案,可以通过额外的监督信号从高能力教师那里转移知识,从而构建轻量级模型[5,23]。
要开发一种有效的提炼方法,主要有两个问题:
- 教师网络中编码了哪些类型的知识
- 如何在网络之间传递知识。现有的知识发现方法根据知识转移是来自单个样本还是跨样本,侧重于知识对齐或知识关联。
原始KD最小化了教师和学生网络概率输出之间的KL发散损失。该目标旨在将暗知识[23]即相对概率的分配转移到错误的类别。我们的分析表明,该logit匹配解决方案实际上对单个样本执行知识对齐。最近,CRD[35]被提出基于对比目标学习结构表征知识。SEED[17]是另一种对比提炼方法,鼓励学生向自我监督的预培训教师学习。基于对比学习的方法注重知识相关性,因为它们在不同样本之间传递关系知识。
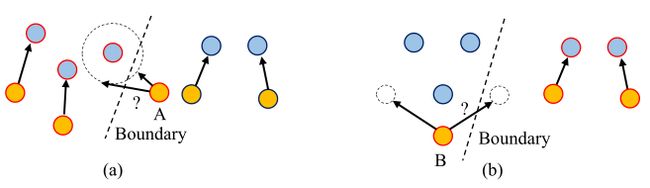
图1:知识一致性(a)和相关性(b)的必要性说明。蓝色:老师,Y黄色:学生,红色圆圈:语义相同的样本,边界:决策边界。知识对齐侧重于直接的特征匹配,而知识关联捕获样本之间的相对关系。当只考虑一个目标时,可能会导致不同的映射(A的圆和B的两个可能映射),并且可能无法实现最佳蒸馏。
在剖析KD之后,我们发现在以前的工作中忽略了两个关键因素。首先,传统的KD过于依赖于特定的训练前策略和网络架构。随着新的培训方法和体系结构不断涌现,我们需要一个更通用的KD解决方案。其次,现有知识发现方法中的知识对齐和知识关联在很大程度上是分离的。我们在图1中说明了知识对齐和关联的必要性。在这项工作中,我们通过有效地考虑知识对齐和关联,引入了多层知识蒸馏(MLKD)。我们提出了一种特征匹配方法来协调教师和学生之间的知识。特别是,我们发现纺锤形转换在知识对齐中起着关键作用。我们还引入了一种有效的知识关联解决方案来获取结构化知识。它们都关注最终的特性表示,因此我们的解决方案(MLKD)不依赖于特定的预训练任务或体系结构。此外,我们还通过利用标签引入了一个可选的监督蒸馏目标,可以考虑在网络之间间接传递类别结构知识。
MLKD使学生能够从教师那里学习到更丰富的表征性知识,而现有方法可能无法有效地获取这些知识。然后,我们定义了一个通用的知识量化度量来衡量和评估视觉概念在学习表示中的一致性。我们的实验表明,MLKD可以让学生学习更多的广义表征,某些学生甚至可以取得比老师更好的表现。在大量实验中,我们的方法始终优于最先进的方法,包括不同的预训练策略(有监督、自我监督)、网络架构(vgg、Resnet、WideResnet、MobileNet、ShuffleNet)、数据集(CIFAR-10/100、STL10、ImageNet、Cityscapes)和任务(分类、分割、自我监督学习)。
二、相关工作
知识提炼。Hinton等人[23]首先提出KD将黑暗知识从教师转移到学生身上。softmax输出编码的知识比热标签更丰富,可以提供额外的监控信号。SRRL[41]利用教师的投影矩阵,通过二语损失训练学生的表达能力,从而实现知识提炼。然而,这些工作依赖于有监督的预培训教师(使用logits),并且它们可能不适合于自我监督的预培训教师。SSKD[40]提出将自监督辅助任务与KD相结合,以传递更丰富的暗知识,但它不能以端到端的训练方式进行训练。与logits匹配类似,中间表示[32,43,42,36,22]广泛用于KD。FitNet[32]建议匹配整个特征图,这很困难,在某些情况下可能会影响学生的收敛性。注意转移[43]利用空间注意图作为监控信号。AB[22]提出在教师中学习隐藏神经元的激活边界。SP[36]专注于在教师和学生之间转移类似(不同)的激活。然而,这些工作大多依赖于某些体系结构,如卷积网络。由于这些蒸馏方法涉及单个样本中的知识匹配,因此它们与知识对齐有关。我们的工作还包括知识整合目标,它不依赖于预培训策略或网络架构。
知识提炼和自我监督学习。自监督学习[30,2,8,20,6]侧重于通过实例判别学习低维表征,这通常需要大量负样本。最近,BYOL[18]和DINO[7]利用动量编码器避免在没有负片的情况下崩溃。动量编码器可被视为平均教师[34],在学生培训期间动态构建。对于KD,教师在蒸馏过程中进行预培训和固定。虽然在自监督学习中,不同的视图(增强图像)通过网络传递,但它们来自相同的原始样本,并且具有相同的语义。因此,在每次迭代中,它在学生和动量教师之间执行知识对齐。特别是,DINO专注于基于多作物增强的本地到全球知识整合。
关系知识提炼。除了知识对齐,KD的另一个研究方向是转移样本之间的关系。DarkRank[10]利用交叉样本相似性来传递度量学习任务的知识。此外,RKD【31】传递了不同特征表示的距离和角度关系。最近,CRD[35]提出将对比目标应用于结构知识提炼。然而,它随机抽取负样本,并不可避免地选择假阴性,从而导致次优解决方案。SEED[17]旨在鼓励学生从一位自我监督、接受过培训的教师那里学习表征知识。但由于使用了大队列,无法在不同语义样本之间有效地传递知识。由于这些蒸馏方法侧重于在不同样本之间传递相关知识,因此它们与知识相关性相关。我们的工作提出了一个有效的知识关联目标。
三、多层次知识提炼
对于一对教师和学生网络, f η T ( ⋅ ) f^T_\eta(\cdot) fηT(⋅)和 f θ S ( ⋅ ) f^S_\theta(\cdot) fθS(⋅),学生在受监督或自我监督的预培训教师发出的额外监督信号下接受培训。 f η T ( ⋅ ) f^T_\eta(\cdot) fηT(⋅)是特征蒸馏器, z T z_T zT表示学习的最后一层特征。以监督分类任务为例,除了 f η T ( ⋅ ) f^T_\eta(\cdot) fηT(⋅),还有一个投影矩阵 W T ∈ R D × K W_T\in \reals^{D\times K} WT∈RD×K将特征表示映射到 K K K个category logits,其中 D D D是特征维度。我们用 s ( ⋅ ) s(\cdot) s(⋅)表示softmax函数和标准KD损耗[23]可以写成:
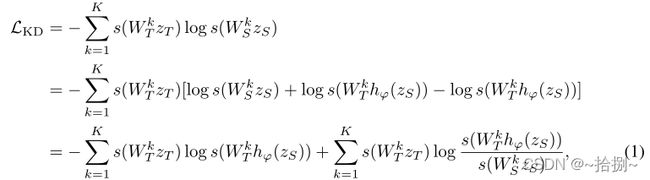
其中, h φ ( ⋅ ) h_\varphi(\cdot) hφ(⋅)、 z S z_S zS和 W T k W^k_T WTk是可训练的, z T z_T zT和 W T k W^k_T WTk是被冷冻的。 h φ ( ⋅ ) h_\varphi(\cdot) hφ(⋅)是从学生到教师的特征转换函数。我们可以观察到,当 z T = h φ ( z S ) z_T=h_\varphi(z_S) zT=hφ(zS)时,第一个损失项达到最优解,第二个损失项成为softmax分布之间的KL散度。因此, h φ ( ⋅ ) h_\varphi(\cdot) hφ(⋅)在最小化网络输出之间的差异方面起着关键作用,简单地匹配维度[32]可能无法有效工作。首先,我们更愿意让学生从老师那里学习优秀的特性,而不仅仅是为了最大限度地减少第一个损失项,因此对 h φ ( ⋅ ) h_\varphi(\cdot) hφ(⋅)的要求是它不应该太强大。第二,当 h φ ( ⋅ ) h_\varphi(\cdot) hφ(⋅)较弱时,上述两个损失项都变大,使学生更难优化。因此,为 h φ ( ⋅ ) h_\varphi(\cdot) hφ(⋅)设置合适的建模能力至关重要。
上述目标有两个主要局限性。首先,这两个损失项目都取决于教师的登录,因此这种方法只适用于在分类任务上预先培训标签的教师。因此,它不能扩展到自我监督的预培训教师的知识转移。第二,这两个损失项都侧重于特征对齐和最小化网络输出之间的差异,但忽略了教师的重要结构知识。这项工作建议在表示层将知识对齐和关联结合起来,以克服这两个限制。
3.1 知识整合
一位训练有素的教师已经编码了优秀的表征知识,即分类知识(来自同一类别的样本在表征空间中很接近),为了更好地匹配教师的表征( f η T ( ⋅ ) f^T_\eta(\cdot) fηT(⋅))和学生表征的转换( h φ ( f θ S ( x ) ) h_\varphi(f^S_\theta(x)) hφ(fθS(x))),需要更强的监督。因此,我们采用以下目标来鼓励学生直接学习教师的表达方式:
![]()
这一目标迫使学生直接模仿老师的表现,并能提供比标准KD损失更强大的班级间相似性监督信号[23]。等式2只关注最后一个特征表示之间的匹配。这与之前的FitNet loss不同,FitNet loss匹配的是整个特征图,这将导致训练变得困难,甚至在 h φ ( ⋅ ) h_\varphi(\cdot) hφ(⋅)仅被视为维度匹配时失败。在第5节中,我们确认 h φ ( ⋅ ) h_\varphi(\cdot) hφ(⋅)的适当表达能力在知识整合中起着关键作用。
知识对齐可以进一步表示为:
![]()
其中, l ( ⋅ , ⋅ ) l(\cdot,\cdot) l(⋅,⋅)损失函数用于惩罚不同输出中网络之间的差异。这是对现有KD目标的概括[23,32,42,43,41]。例如,Hinton等人[23]计算 f T f^T fT和 f S f^S fS之间的KL散度,其中线性函数 h φ h_\varphi hφ和 g φ g_\varphi gφ将表示映射到Logit。SRRL[41]利用教师预先训练好的投影矩阵 W T W_T WT来强化教师和学生的特征,通过二语损失产生相同的逻辑。这些方法依赖于分类任务的登录。相比之下,我们的方法与任务无关。虽然知识整合是有效的,但它不能确保教师的知识得到充分转移,因为它只关注个别样本的知识转移。
3.2 知识关联
训练前的教师还对样本之间丰富的关系进行编码,样本关系转移允许学生学习与教师相似的表征空间结构。在这里,我们提出了一个知识关联目标来传递结构知识。具体来说,我们计算每个(n+1)-元组样本的关系分数作为交叉样本关系知识。目标可以表示为:
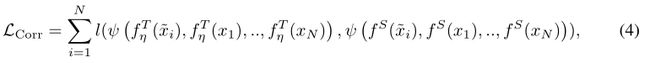
其中, N N N是批量大小, Ψ \varPsi Ψ是关系函数,用于测量增广的 x ~ i \tilde{x}_i x~i样本 { x i } i = 1 : N \{x_i\}_{i=1:N} {xi}i=1:N之间的关系分数。 l ( ⋅ , ⋅ ) l(\cdot,\cdot) l(⋅,⋅)是损失函数。每批样本具有不同的语义相似度, Ψ \varPsi Ψ需要给语义相似的样本分配较高的分数,否则分配较低的关系分数。在这里,我们应用余弦相似性来度量表示之间的语义相似性,并将其转换为softmax分布以进行知识相关性计算。 { x ~ i } i = 1 : N \{\tilde{x}_i\}_{i=1:N} {x~i}i=1:N和 { x i } i = 1 : N \{x_i\}_{i=1:N} {xi}i=1:N之间的所有相似性都可以写成矩阵 A A A。关系函数为:

式中, τ \tau τ是软化峰值分布的温度参数, f ( ⋅ ) f(\cdot) f(⋅)是教师或学生网络。对于教师网络, A i , j A_{i,j} Ai,j由表示计算。对于学生网络,我们还将变换函数应用于表示 z S z_S zS,以进行损耗计算。我们注意到,这种关系函数类似于InfoNCE loss[30],它被广泛用于自我监督对比学习[8,20]。然而,我们的目标是编码样本之间的关系,而不是实现实例区分[38]。然后,我们应用KL发散损失将这些关系从教师转移到学生。
相比之下,RKD[31]提出了关系知识蒸馏的距离和角度损失。前者在量表上存在显著差异,使训练不稳定。后者利用三组样本计算角度分数( O ( N 3 ) O(N^3) O(N3))复杂度。我们基于KL的解决方案实现了 O ( N 2 ) O(N^2) O(N2)复杂度的高阶特性。SEED[17]提出利用样本和队列之间的相似性分数,从自我监督的预培训教师那里转移知识。然而,由于大量不同的样本,大队列导致softmax输出稀疏,这使得它无法在不同语义样本之间有效地传递知识。我们直接计算每个批次中的相互关系,并利用KL发散损失,它不需要额外的队列和大批量,并且具有较高的计算效率。
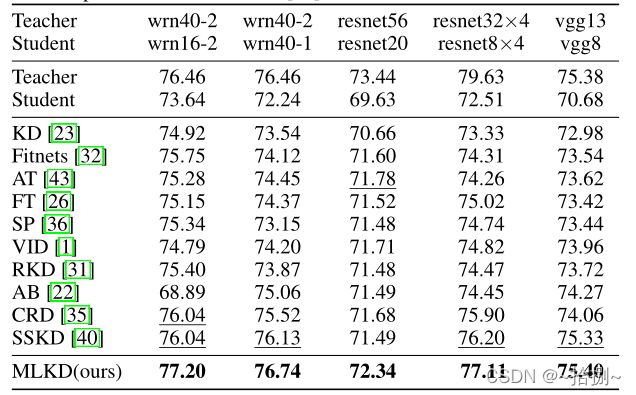
表1:类似结构之间的蒸馏性能比较。它报告了CIFAR100测试数据集的最高精度(%)。我们用粗体和下划线表示最好和次好的结果。所有比较方法的结果来自[40]。
3.3 有监督的知识提炼
上述两个目标都与特征表示有关,因此它们不依赖于特定的训练前任务。在此,我们还提出了一个基于信息损失的额外目标,供受监督的预培训教师使用。我们利用真标签从同一类别构造正标签,从不同类别构造负标签,这克服了CRD中的抽样偏差问题[35]。升华中有两种锚:教师锚和学生锚。前者来自教师的输出,相应的积极和消极来自学生。后者来自学生的输出,其正面和负面来自教师。
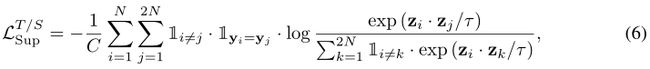
其中 C = 2 N y i − 1 C=2N_{y_i}-1 C=2Nyi−1和 N y i − 1 N_{y_i}-1 Nyi−1小批量中标签为 y i y_i yi的图像数。这个目标可以被认为是在网络之间间接地传递类别结构知识。它提供了分类相似性,以鼓励学生将同一类别的样本映射到紧密的表示空间中,而不同类别的样本则要远离。我们的公式类似于监督对比损失[25]。然而,所有样品都有助于梯度计算,而我们的蒸馏包含固定锚,需要进一步分析下限。此外,还对学生进行了交叉熵损失训练。
3.4 MLKD objective
任何培训前教师的总蒸馏损失都是知识对齐和相关性损失的线性组合:
![]()
其中 λ 1 \lambda_1 λ1和 λ 2 \lambda_2 λ2是平衡重。对于有监督的预训练教师,我们还添加了上述有监督蒸馏损失 L S u p L_{Sup} LSup和 L C E L_{CE} LCE标准交叉熵损失(带平衡权)。
四、知识量化度量
有必要通过量化网络中编码的知识来理解抽象的表示。Cheng等人[11]提出量化前景和背景上网络的视觉概念,这需要对对象边界框进行注释。然而,这些类型的地面真相边界框并不总是可用的。在这里,我们定义了更通用的度量来解释和分析基于条件熵的网络中编码的知识。

表2:不同结构之间的蒸馏性能比较。它报告了CIFAR100测试数据集的最高精度(%)。我们用粗体和下划线表示最好和次好的结果。所有比较方法的结果来自[40]。
设 X X X表示一组输入图像。条件熵 H ( X ∣ z = f ( x ) ) H(X|z=f(x)) H(X∣z=f(x))测量在正向传播期间从输入图像x到表示z的信息被丢弃的程度[19,11]。提出了一种基于摄动的近似 H ( X ∣ z ) H(X|z) H(X∣z)的方法[19]。扰动输入遵循高斯分布,假设像素之间独立 x ~ N ( x , ∑ = d i a g ( σ 1 2 , . . . , σ n 2 ) ) \tilde{x}~N(x,\sum=diag(\sigma^2_1,...,\sigma^2_n)) x~ N(x,∑=diag(σ12,...,σn2)),其中 n n n表示像素总数。因此,图像级条件熵 H ( X ∣ z ) H(X|z) H(X∣z)可以分解为像素级熵 H ( X ∣ z ) = ∑ i = 1 n H i H(X|z)=\sum^n_{i=1}H_i H(X∣z)=∑i=1nHi,其中 H i = l o g σ i + 1 2 l o g ( 2 π e ) H_i=log\sigma_i+\frac{1}{2}log(2\pi e) Hi=logσi+21log(2πe)。高像素熵表示通过层丢弃更多信息,低像素熵的像素与表示更相关,低熵的像素可以被视为可靠的视觉概念。
我们从知识量化和一致性的角度定义了两个通用的量化指标:平均值和IoU。图像的平均熵 H ˉ = 1 n ∑ i H i \bar{H}=\frac{1}{n}\sum_iH_i Hˉ=n1∑iHi表示在整个输入中丢弃了多少信息。较小的 H H H表示网络利用更多像素从输入计算特征表示。然而,更多的视觉概念并不总是导致最佳特征表示,这可能会导致过度拟合问题[3]。理想情况下,一个经过良好学习的网络应该能够编码出更健壮、更可靠的知识。因此,我们通过IoU度量来度量知识的一致性,IoU度量量化了同一图像的两个视图之间的视觉概念的一致性,即两个增强图像 x 1 x_1 x1和 x 2 x_2 x2。

其中1是指示函数, S c o n c e p t ( x ) S_{concept}(x) Sconcept(x)表示视觉概念集(熵小于 H ˉ \bar{H} Hˉ的像素)。 i ∈ x 1 ∩ x 2 i\in x_1\cap x_2 i∈x1∩x2$表示两个增强图像的相同像素。这些相同的像素应该获得相似的视觉概念,并在增强图像之间保持良好的一致性。因此,我们选择视觉概念重叠数和视觉概念联合数(IoU)之间的比率来衡量学习表示的知识一致性。我们的IoU度量满足通用性和一致性[11]的要求,并可用于量化和分析视觉概念,而无需依赖特定的体系结构、任务和数据集。
五、实验
网络架构。我们采用vgg[33]ResNet[21]、WideResNet[44]、MobileNet[24]和ShuffleNet[45]作为师生组合,对CIFAR100数据集[28]和ImageNet数据集[16]上的监督KD进行评估。它们的实现来自[35]。对于结构化KD,我们基于[29]实现了MLKD,并在Cityscapes数据集[14]上对其进行了评估。教师模型是带有ResNet101的PSPNet架构[46],学生模型设置为ResNet18。对于自我监督的KD,教师通过MoCo-V2[9]或SwA V[6]进行预训练,我们直接下载预训练权重进行评估。学生网络设置为较小的ResNet网络(ResNet 18、34)。我们还对STL10数据集[13]和TinyImageNet数据集[15,16]上的表示进行了可转移性评估。

表3:ImageNet上排名前1和前5的错误率(%)。我们用粗体和下划线表示最好和次好的结果。
实施细节。我们的实现主要是为了验证MLKD的有效性。我们遵循基于现有解决方案的相同培训策略,没有任何技巧。对于监督KD,我们使用动量为0.9的SGD优化器。权重衰减为 5 × 1 0 − 4 5×10^{−4} 5×10−4英寸CIFAR100。所有学生都接受了240个时代的培训,批量为64个。初始学习率为0.05,然后在第150、180和210个时期除以10。在ImageNet中,我们遵循Pytorch1的官方实现,并采用带有0.9的SGD优化器,动量和 1 × 1 0 − 4 1×10^{−4} 1×10−4重量衰减。初始学习率为0.1,在第30、60和90个纪元,总共100个纪元中,衰变为10。对于这两个数据集,我们采用常规的数据增强方法,例如四角旋转,即0◦,90◦,180◦,270◦. 为了执行结构化KD,学生使用动量为0.9的SGD优化器进行训练,,重量衰减为 5 × 1 0 − 4 5×10^{−4} 5×10−4,40000次迭代。训练输入设置为512×512,训练期间使用常规数据增强方法,如随机缩放和翻转。自监督KD由SGD优化器以0.9的动量进行训练。权重衰减为 1 × 1 0 − 4 1×10^{−4} 1×10−4,200个epochs。在比较的方法(CRD[35]、SKD[29]和SEED[17])中可以找到更详细的培训信息。 L C o r r L_{Corr} LCorr和 L S u p L_{Sup} LSup中的温度 τ \tau τ设置为0.5和0.07。对于平衡重,我们根据损失值的大小设置 λ 1 = 10 \lambda_1=10 λ1=10和 λ 2 = 20 \lambda_2=20 λ2=20。在监督KD期间,我们将 L S u p L_{Sup} LSup和 L C E L_{CE} LCE的权重设置为0.5和1.0。所有型号均在NVIDIA DGX2服务器上使用特斯拉V100 GPU进行培训。
六、结论
在这项工作中,我们将现有的蒸馏方法总结为知识对齐和关联,并提出了一种有效且灵活的多层蒸馏方法MLKD,该方法侧重于学习个体和结构表征知识。我们进一步证明,我们的解决方案可以增加教师和学生表示分布之间的互信息下限。我们进行了深入的实验,以证明我们的方法在不同的实验设置下达到了最先进的蒸馏性能。对学生表征的进一步分析表明,MLKD可以提高学习表征的可迁移性。我们还证明,我们的方法可以很好地工作在有限的训练数据在少数镜头的情况下。由于硬件的限制,我们没有进行更系统的超参数调整,这可以在未来的工作中进行,以进一步获得更好的性能。我们将通过在GitHub帐户上在线维护源代码来确保我们的方法公开可用。我们的解决方案与潜在的恶意使用无关,也没有任何隐私/安全考虑。