Linux & Windows 的Tensorflow 配置: Nvidia 老显卡运算能力低于3.0
实测成功配置信息1:
Windows10,GT755m, Capability 3.0
- Ana(Mini)conda管理,环境 Python 3.6(.13)
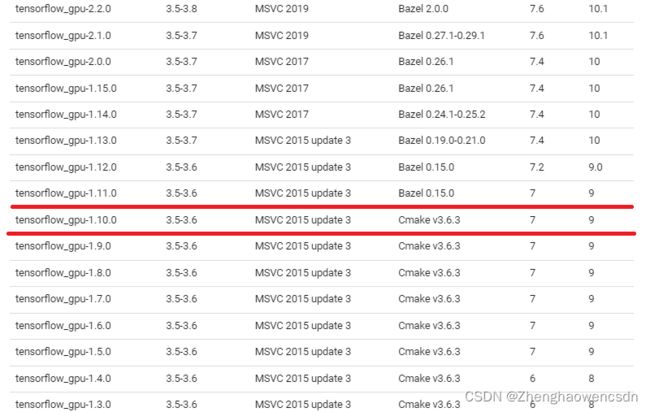
- Cuda=9.0 Cudnn=7.0 Tensorflow_gpu=1.10.0(1.11.0 就已经不行了)
- matplotlib = 2.2.5, pandas = 1.0.0 (限制版本是因为不能破坏tensorflow对numpy依赖:<=1.14.5,更高的版本没有试)
- jupyter = 1.0.0 (Miniconda 需要自装,高版本未测)
更新!
在 tf 训练时发现一条信息(不是错误,不理它也没关系):“Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA”
说明 pip 库的 tf-gpu 版本不支持 cpu 的 avx2,这是因为gpu版本下 cpu 的支持不是很重要,且不是所有 cpu 都支持avx2,官方库优先考虑了兼容性。但我们只有3.0算力的显卡,如果弹出了这条信息,那还是尽可能提升 cpu 的性能能力吧。
avx2 支持需要 tf 源码在编译时加入特定的编译选项,比较麻烦。好在 github 上有别人编译好的,直接下载并用 pip 本地安装。
解决方案:彻底解决“Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA”警告_dracarys~的博客-CSDN博客问题描述在使用TensorFlow时,总是提醒“Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA”解决办法网上有很多说在python代码中添加:os.environ[“TF_CPP_MIN_LOG_LEVEL”]=‘2’ # 只显示 warning 和 ...https://blog.csdn.net/wlwlomo/article/details/82806118?spm=1001.2101.3001.6661.1&utm_medium=distribute.pc_relevant_t0.none-task-blog-2~default~CTRLIST~Rate-1.pc_relevant_default&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2~default~CTRLIST~Rate-1.pc_relevant_default&utm_relevant_index=1
实测支持AVX2 的配置:
github 库中 tf 的版本和配置为: Tensorflow_gpu=1.10.0 (GitHub - fo40225/tensorflow-windows-wheel: Tensorflow prebuilt binary for Windows) Cuda=9.2(+ 官网 patch) Cudnn=7.2。 实测成功,avx2警告消失,gpu 可用。 测试使用Windows 10平台
实测成功配置信息2:
Arch Linux: kernel 5.4-LTS,GT755m, Capability 3.0
- Ana(Mini)conda管理,环境 Python 3.8
- Cuda=10.2(显卡最高支持的版本) Cudnn=7.0 Tensorflow_gpu=2.8.0(源码编译,禁用XLA)
- NVIDIA 驱动 470.103.01 (kernel 5.4可用且支持老显卡)
下载了源码,设置两线程编译,纯编译 14h 。不浪费大家时间,且中间踩坑都在免费资源的帮助下解决,所以 0币下载,自取,下载前看看资源介绍里的配置信息:
https://download.csdn.net/download/ZhenghaowenCSDN/85047916 https://download.csdn.net/download/ZhenghaowenCSDN/85047916
https://download.csdn.net/download/ZhenghaowenCSDN/85047916
编译过程记录(可跳过):
显卡驱动准备:看看是适用于哪款驱动,同时适配Linux kernel和老显卡Appendix A. Supported NVIDIA GPU Products
CUDA&CUDNN准备:搜一圈,据称我的显卡最高支持到cuda10.2,自己也验证过了cuda11确实不支持。cudnn在NVIDIA官网下载,一定要选适配cuda10.2的。
总体编译过程按官网走:从源代码构建 | TensorFlow,Bazel 4.2.1 版本
configure 后 生成的编译配置文件小修改:很重要!! 算力3.0老显卡不支持XLA技术,这是装不了高版本TF的主要原因,所以编译时要禁掉 XLA。非常感谢大神的方法:https://github.com/tensorflow/tensorflow/issues/46653
做法:生成在源码目录里的.tf_configure.bazelrc文件:删掉 build:xla 行(如果有的话),添加
build --define=with_xla_support=false
build --action_env TF_ENABLE_XLA=0Bazel 编译命令小修改:内存限制+禁用XLA
bazel build --config=cuda --local_cpu_resources=2 --discard_analysis_cache --copt=-DTF_EXTRA_CUDA_CAPABILITIES=3.0 //tensorflow/tools/pip_package:build_pip_package- --config=cuda 是官网编译教程给的
- 内存限制:我的内存只有8G,前几次编译的过程中爆内存,因此必须限制编译时的内存消耗
- --local_cpu_resources=2:只允许开两个线程,每个线程都会耗内存,开多了容易爆
- --discard_analysis_cache:不太懂,大概是编译完就丢掉一些缓存,腾出一些内存空间,从Bazel 官网抄来:Memory-saving Mode - Bazel main
- --copt=-DTF_EXTRA_CUDA_CAPABILITIES=3.0:很重要!!禁掉XLA
编译一开始需要收集资源,可能有联网问题,停止运行再重开试试。编译中途停止不要怕,有缓存的,重开后不会从头开始。
最后生成wheel的时候有些 warning 不用理。
NUMPY 问题一定要注意:在编译环境中,numpy 版本要与 tensorflow 版本匹配,因为编译时会链接到编译环境中的 numpy。之前编译 tensorflow 2.4 时环境中装了过高版本的 numpy (1.22,实际只支持到 1.19),导致编译好的 tensorflow 在 import 的时候需要 numpy 1.22,而跑模型的时候又会因为不适配高版本numpy 而报错;装回numpy 1.19 时又无法 import tensorflow。这就产生了一个无解的问题,numpy 要降版本但又降不了。
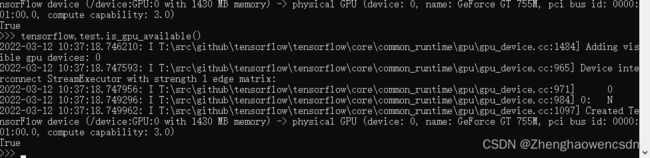
配后检查 Windows:
import tensorflow
tensorflow.test.is_gpu_available()
性能检测:
import tensorflow as tf
import timeit
# 基本信息查询
tf_gpu_ok = tf.test.is_gpu_available()
print("TF Ver: ",tf.__version__)
print("TF GPU Use: ",tf_gpu_ok)
# 大矩阵乘法
with tf.device('/cpu:0'):
cpu_a = tf.random_normal([10000, 1000])
cpu_b = tf.random_normal([1000, 2000])
print(cpu_a.device, cpu_b.device)
with tf.device('/gpu:0'):
gpu_a = tf.random_normal([10000, 1000])
gpu_b = tf.random_normal([1000, 2000])
print(gpu_a.device, gpu_b.device)
# 不同芯片运行
def cpu_run():
with tf.device('/cpu:0'):
c = tf.matmul(cpu_a, cpu_b)
return c
def gpu_run():
with tf.device('/gpu:0'):
c = tf.matmul(gpu_a, gpu_b)
return c
# 计算运算时间 对比芯片性能
cpu_time = timeit.timeit(cpu_run, number=10)
gpu_time = timeit.timeit(gpu_run, number=10)
print('Tensorflow warmup /CPU,GPU/: ', cpu_time, gpu_time)
cpu_time = timeit.timeit(cpu_run, number=100000)
gpu_time = timeit.timeit(gpu_run, number=100000)
print('Tensorflow run time /CPU,GPU/: ', cpu_time, gpu_time)性能检测2:Linux gpu版
跑模型,官编 tensorflow-cpu 一个step 23ms,自编 tensorflow-gpu 一个step 21ms,测试中性能基本一样。这也是3.0算力的显卡不再得到官编支持的原因。
观察具体情况,gpu使用率跑到 65%,显存总共 2G 占了 95%,说明显存更可能是老gpu加速的瓶颈。