NVIDIA NCCL 源码学习(九)- 单机内ncclSend和ncclRecv的过程
上节介绍了通信链路的建立过程,本节介绍下单机内部ncclSend和ncclRecv的运行过程。
单机内的通信都是通过kernel来进行的,所以整个通信的过程可以分为两步,第一步是准备kernel相关的参数,第二步是实际执行kernel的过程。
为方便表述,下边例子不加说明的话均为单机单线程两卡的场景,测试用例如下。
#include
#include "cuda_runtime.h"
#include "nccl.h"
#include
#include
#define CUDACHECK(cmd) do { \
cudaError_t e = cmd; \
if( e != cudaSuccess ) { \
printf("Failed: Cuda error %s:%d '%s'\n", \
__FILE__,__LINE__,cudaGetErrorString(e)); \
exit(EXIT_FAILURE); \
} \
} while(0)
#define NCCLCHECK(cmd) do { \
ncclResult_t r = cmd; \
if (r!= ncclSuccess) { \
printf("Failed, NCCL error %s:%d '%s'\n", \
__FILE__,__LINE__,ncclGetErrorString(r)); \
exit(EXIT_FAILURE); \
} \
} while(0)
int main(int argc, char* argv[])
{
//each process is using two GPUs
int nDev = 2;
int nRanks = nDev;
int chunk = 1024*1024;
int size = nDev * chunk;
float** sendbuff = (float**)malloc(nDev * sizeof(float*));
float** recvbuff = (float**)malloc(nDev * sizeof(float*));
cudaStream_t* s = (cudaStream_t*)malloc(sizeof(cudaStream_t)*nDev);
//picking GPUs based on localRank
for (int i = 0; i < nDev; ++i) {
CUDACHECK(cudaSetDevice(i));
CUDACHECK(cudaMalloc(sendbuff + i, size * sizeof(float)));
CUDACHECK(cudaMalloc(recvbuff + i, size * sizeof(float)));
CUDACHECK(cudaMemset(sendbuff[i], 1, size * sizeof(float)));
CUDACHECK(cudaMemset(recvbuff[i], 0, size * sizeof(float)));
CUDACHECK(cudaStreamCreate(s+i));
}
ncclUniqueId id;
ncclComm_t comms[nDev];
//generating NCCL unique ID at one process and broadcasting it to all
ncclGetUniqueId(&id);
//initializing NCCL, group API is required around ncclCommInitRank as it is
//called across multiple GPUs in each thread/process
NCCLCHECK(ncclGroupStart());
for (int i=0; i 通信参数准备
先看下通信参数准备的过程,陷入细节之前我们先看下整体样貌。
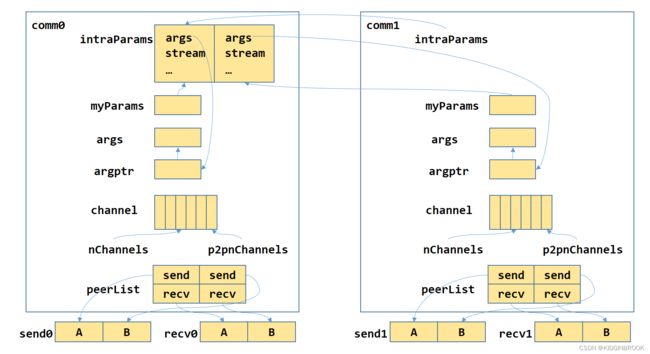 图一
图一
最下边send0和recv0表示用户为rank0准备的数据buffer
然后来一一介绍下
p2p channel
先看下p2p操作对应的channel如何创建出来的
ncclResult_t ncclTopoComputeP2pChannels(struct ncclComm* comm) {
comm->p2pnChannels = std::min(comm->nChannels, (int)ncclParamMaxP2pNChannels());
comm->p2pnChannels = std::max(comm->p2pnChannels, (int)ncclParamMinP2pNChannels());
int minChannels = comm->p2pnChannels;
// We need to loop through all local GPUs to have a global picture
for (int g=0; gtopo->nodes[GPU].count; g++) {
for (int r=0; rnRanks; r++) {
int nChannels;
NCCLCHECK(ncclTopoGetNchannels(comm->topo, g, r, &nChannels));
if (nChannels >= 0) minChannels = std::min(minChannels, nChannels);
}
}
// Round to next pow2 nChannelsPerPeer and nChannels
comm->p2pnChannelsPerPeer = nextPow2(minChannels);
comm->p2pnChannels = nextPow2(comm->p2pnChannels);
// Init channels that weren't used so far
for (int c=comm->nChannels; cp2pnChannels; c++) NCCLCHECK(initChannel(comm, c));
// We want to spread channels used when there aren't many and progressively
// fill the whole space of nChannels. To do so we mirror the bits in the
// nChannels space.
for (int c=0; cp2pnChannelsPerPeer; c++) {
int mirror = 0;
for (int b=1, mb=(comm->p2pnChannels>>1); bp2pnChannels; b<<=1, mb>>=1) if (c & b) mirror |= mb;
comm->p2pChannels[c] = mirror;
}
INFO(NCCL_INIT, "%d coll channels, %d p2p channels, %d p2p channels per peer", comm->nChannels, comm->p2pnChannels, comm->p2pnChannelsPerPeer);
return ncclSuccess;
} 之前在建立ringGraph的时候有搜索出一系列的环,并根据这些环建立了channel,假设现在一共有nChannels个channel,而p2p需要p2pnChannels个channel,那么如果p2pnChannels大于nChannles,会再创建p2pnChannels - nChannels个channel,其他的复用;否则直接复用即可。
对于每个send/recv操作,会使用p2pnChannelsPerPeer个channel并行发送/接收,那么当p2pnChannelsPerPeer比较小,p2pnChannels比较大,会导致只用了前边的几个channel,无法充分利用所有的channel,举个例子,p2pnChannelsPerPeer = 2,p2pnChannels = 32,rank0和rank1,rank2的通信都会使用channel[1]和channel[2], 为了解决这个问题,nccl使用数组p2pChannels[p2pnChannelsPerPeer]作为偏移,比如p2pChannels[0] = 0, p2pChannels[1] = 16,那么rank0和rank1的通信会使用channel[1]和channel[17],rank0和rank2的通信会使用channel[2]和channel[18],更充分的利用了channel。
为了方便理解,后续举例时假定p2pnChannels和p2pnChannelsPerPeer都为1。
peerlist
然后看下peerlist,其实是comm->p2plist的一个成员,图一只列出来了peerlist,具体含义见下边的注释。
struct ncclP2Pinfo {
const void* sendbuff; // 用户指定要发送的数据buffer
void* recvbuff; // 用户指定的接收数据的buffer
ssize_t sendbytes; // sendbuff长度
ssize_t recvbytes; // recvbuff长度
};
struct ncclP2PConnect {
int nrecv[MAXCHANNELS]; // nrecv[id]表示第id个channel会recv几个rank
int nsend[MAXCHANNELS]; // nsend[id]表示第id个channel会send给几个rank
int* recv; // recv[id * nranks]开始的nrecv[id]个rank,表示第id个channel会从这几个rank recv
int* send; // send[id * nranks]开始的nsend[id]个rank,表示第id个channel会send给这几个rank
};
struct ncclP2Plist {
struct ncclP2Pinfo *peerlist;
int count;
struct ncclP2PConnect connect;
};cudaLaunchParams
图一中的intraParams和myParams类型都为cudaLaunchParams,通信实际是通过kernel完成的,cudaLaunchParams记录了kernel的参数。
struct cudaLaunchParams {
void *func;
dim3 gridDim;
dim3 blockDim;
void **args;
size_t sharedMem;
cudaStream_t stream;
};在initTransportsRank的最后会设置参数,intraRank0表示当前机器的第一个rank是谁,intraRanks表示当前机器上有几个rank,intraRank表示当前rank在当前机器是第几个。
int intraRank0 = -1, intraRank = -1, intraRanks = 0;
for (int i = 0; i < nranks; i++) {
if ((allGather1Data[i].peerInfo.hostHash == allGather1Data[rank].peerInfo.hostHash) &&
(allGather1Data[i].peerInfo.pidHash == allGather1Data[rank].peerInfo.pidHash)) {
if (intraRanks == 0) intraRank0 = i;
if (i == rank) intraRank = intraRanks;
intraRanks++;
}
}
NCCLCHECK(ncclCommSetIntra(comm, intraRank, intraRanks, allGather1Data[intraRank0].comm));intraBarrier用于cpu的同步,这里可以看到intraBarrier,intraParams其实都是用的intraRank0的。
ncclResult_t ncclCommSetIntra(struct ncclComm* comm, int rank, int ranks, struct ncclComm* comm0) {
comm->intraRank = rank;
comm->intraRanks = ranks;
comm->intraPhase = 0;
// Alloc shared structures
if (rank == 0) {
assert(comm == comm0);
int* bar;
NCCLCHECK(ncclCalloc(&bar, 2));
bar[0] = bar[1] = 0;
comm->intraBarrier = bar;
NCCLCHECK(ncclCalloc(&comm->intraParams, comm->intraRanks));
NCCLCHECK(ncclCalloc(&comm->intraCudaDevs, comm->intraRanks));
int* CGMode;
NCCLCHECK(ncclCalloc(&CGMode, 1));
*CGMode = 0x11;
comm->intraCGMode = CGMode;
int* CC;
NCCLCHECK(ncclCalloc(&CC, 1));
*CC = ncclCudaCompCap();
comm->intraCC = CC;
} else {
comm->intraBarrier = (int*)waitForNonNullPtr(&comm0->intraBarrier);
comm->intraParams = (struct cudaLaunchParams*)waitForNonNullPtr(&comm0->intraParams);
comm->intraCudaDevs = (int*)waitForNonNullPtr(&comm0->intraCudaDevs);
comm->intraCGMode = (int*)waitForNonNullPtr(&comm0->intraCGMode);
comm->intraCC = (int*)waitForNonNullPtr(&comm0->intraCC);
}
comm->intraCudaDevs[comm->intraRank] = comm->cudaDev;
NCCLCHECK(initParams(comm));
int cgMdLaunch = 0;
// Set CG Mode
comm->launchMode = ncclComm::GROUP;
char* str = getenv("NCCL_LAUNCH_MODE");
if (str) INFO(NCCL_ENV, "NCCL_LAUNCH_MODE set by environment to %s", str);
if (comm->intraRanks == 1 || (str && strcmp(str, "PARALLEL") == 0)) {
comm->launchMode = ncclComm::PARALLEL;
}
if (comm->launchMode == ncclComm::GROUP) {
CUDACHECK(cudaStreamCreateWithFlags(&comm->groupStream, cudaStreamNonBlocking));
#if CUDART_VERSION >= 9000
if (*comm->intraCC && (ncclCudaCompCap() == *comm->intraCC)) {
// Check whether the GPU supports Cooperative Group Multi Device Launch
(void) cudaDeviceGetAttribute(&cgMdLaunch, cudaDevAttrCooperativeMultiDeviceLaunch, comm->cudaDev);
}
#endif
}
// Disable cgMdLaunch if any rank does not support it
if (cgMdLaunch == 0) {
*comm->intraCGMode = 0x10;
}
return ncclSuccess;
}然后通过initParam完成了args,myParam的设置,如图一。
ncclResult_t initParams(struct ncclComm* comm) {
struct cudaLaunchParams* params = comm->myParams = comm->intraParams+comm->intraRank;
params->args = &comm->argsptr;
params->stream = NULL;
params->sharedMem = 0;
params->blockDim.x = 0; params->blockDim.y = params->blockDim.z = 1;
params->gridDim.x = 0; params->gridDim.y = params->gridDim.z = 1;
return ncclSuccess;
}然后开始执行ncclSend,通过用户参数生成ncclInfo。
ncclResult_t ncclSend(const void* sendbuff, size_t count, ncclDataType_t datatype, int peer,
ncclComm_t comm, cudaStream_t stream) {
struct ncclInfo info = { ncclCollSendRecv, "Send",
sendbuff, NULL, count, datatype, ncclSum, peer, comm, stream, /* Args */
1, 1 };
ncclResult_t ret;
NCCLCHECK(ncclGroupStart());
ret = ncclEnqueueCheck(&info);
NCCLCHECK(ncclGroupEnd());
return ret;
}
ncclGroupStart只是对ncclGroupMode加一,ncclGroupMode非0表示处于Group操作中,GroupStart和GroupEnd间的操作不会阻塞,最后通过GroupEnd一次性提交操作。
ncclResult_t ncclGroupStart() {
if (ncclGroupMode == 0) {
memset(ncclGroupArgs, 0, sizeof(struct ncclAsyncArgs)*MAX_ASYNC_OPS);
}
ncclGroupMode++;
return ncclSuccess;
}然后看下ncclEnqueueCheck
ncclResult_t ncclEnqueueCheck(struct ncclInfo* info) {
// Launch asynchronously if needed
if (ncclAsyncMode()) {
ncclResult_t ret = ncclSuccess;
int savedDev = -1;
// Check arguments
NCCLCHECK(PtrCheck(info->comm, info->opName, "comm"));
if (info->comm->checkPointers) {
CUDACHECKGOTO(cudaGetDevice(&savedDev), ret, end);
CUDACHECKGOTO(cudaSetDevice(info->comm->cudaDev), ret, end);
}
NCCLCHECKGOTO(ArgsCheck(info), ret, end);
// Always register comm even in case of error to make sure ncclGroupEnd
// cleans it up.
NCCLCHECKGOTO(ncclAsyncColl(info->comm), ret, end);
NCCLCHECKGOTO(checkSetStream(info), ret, end);
if (info->coll == ncclCollSendRecv) { //p2p stored separately
NCCLCHECKGOTO(ncclSaveP2p(info), ret, end);
} else {
NCCLCHECKGOTO(ncclSaveKernel(info), ret, end);
}
end:
if (savedDev != -1) CUDACHECK(cudaSetDevice(savedDev));
ncclAsyncErrCheck(ret);
return ret;
}ncclGroupArgs和ncclGroupIndex是thread_local的变量,表示一共有ncclGroupIndex个AsyncArgs;这里会对比当前ncclGroupArgs里边是否有当前comm的AsyncArgs,如果没有则新加一个,设置funcType为ASYNC_FUNC_COLL,设置comm。
ncclResult_t ncclAsyncColl(ncclComm_t comm) {
struct ncclAsyncArgs* args = ncclGroupArgs;
for (int i=0; icoll.comm == comm) return ncclSuccess;
args++;
}
if (ncclGroupIndex >= MAX_ASYNC_OPS) {
WARN("Too many async operations in progress, max is %d", MAX_ASYNC_OPS);
return ncclAsyncErrCheck(ncclInvalidUsage);
}
ncclGroupIndex++;
args->funcType = ASYNC_FUNC_COLL;
args->coll.comm = comm;
return ncclSuccess;
} 然后将comm->userStream设置为info->stream。
static ncclResult_t checkSetStream(struct ncclInfo* info) {
if (info->comm->userStreamSet == false) {
info->comm->userStream = info->stream;
info->comm->userStreamSet = true;
} else if (info->stream != info->comm->userStream) {
WARN("Error : mixing different streams within a group call is not supported.");
return ncclInvalidUsage;
}
return ncclSuccess;
}然后执行ncclSaveP2p,将p2p相关的信息保存到comm的p2plist,peer是要发送给谁,这里delta是指(rank + delta) % nranks = peer, 这样通过rank + delta就可以找到对应channel。p2pnChannelsPerPeer个channel会并行执行数据的发送,如果channel还没有建立和peer的连接的话需要先记录一下连接信息,比如第id个channel的send,会在send[id * nranks + nsend[id] ]的位置记录下peer,然后nsend[id]加一,以便于后续执行建链的逻辑。最后将sendbuff和数据长度记录到对应peerlist中的对应peer,即对应图一。
ncclResult_t ncclSaveP2p(struct ncclInfo* info) {
struct ncclComm* comm = info->comm;
struct ncclP2Plist* p2plist = &comm->p2plist;
int peer = info->root;
p2plist->count++;
ssize_t nBytes = info->count*ncclTypeSize(info->datatype);
if (info->recvbuff == NULL) {
if (peer != comm->rank) {
int delta = (comm->nRanks - (comm->rank-peer)) % comm->nRanks;
for (int c=0; cp2pnChannelsPerPeer; c++) {
int channelId = (delta+comm->p2pChannels[c]) % comm->p2pnChannels;
if (comm->channels[channelId].peers[peer].send.connected == 0) {
p2plist->connect.send[channelId*comm->nRanks+p2plist->connect.nsend[channelId]++] = peer;
}
}
}
p2plist->peerlist[info->root].sendbytes = nBytes;
p2plist->peerlist[info->root].sendbuff = info->sendbuff;
} else {
if (peer != comm->rank) {
int delta = (comm->nRanks + (comm->rank-peer)) % comm->nRanks;
for (int c=0; cp2pnChannelsPerPeer; c++) {
int channelId = (delta+comm->p2pChannels[c]) % comm->p2pnChannels;
if (comm->channels[channelId].peers[peer].recv.connected == 0) {
p2plist->connect.recv[channelId*comm->nRanks+p2plist->connect.nrecv[channelId]++] = peer;
}
}
}
p2plist->peerlist[info->root].recvbytes = nBytes;
p2plist->peerlist[info->root].recvbuff = info->recvbuff;
}
return ncclSuccess;
} 然后开始执行ncclGroupEnd,由于此时ncclGroupMode不为0,因此直接返回,ncclSend就执行完成了。
ncclResult_t ncclGroupEnd() {
if (ncclGroupMode == 0) {
WARN("ncclGroupEnd: not in a group call.");
return ncclInvalidUsage;
}
ncclGroupMode--;
if (ncclGroupMode > 0) return ncclSuccess;
...
}接下来是ncclRecv的过程,和ncclSend完全一致,执行结束后recv的相关信息也被保存到了p2plist。
ncclResult_t ncclRecv(void* recvbuff, size_t count, ncclDataType_t datatype, int peer,
ncclComm_t comm, cudaStream_t stream) {
struct ncclInfo info = { ncclCollSendRecv, "Recv",
NULL, recvbuff, count, datatype, ncclSum, peer, comm, stream, /* Args */
1, 1 };
ncclResult_t ret;
NCCLCHECK(ncclGroupStart());
ret = ncclEnqueueCheck(&info);
NCCLCHECK(ncclGroupEnd());
return ret;
}然后开始执行ncclGroupEnd,刚刚通过ncclSend和ncclRecv将相关信息写到了p2plist,接下来第一步就是如果没有建链则建链。
ncclResult_t ncclGroupEnd() {
if (ncclGroupMode == 0) {
WARN("ncclGroupEnd: not in a group call.");
return ncclInvalidUsage;
}
ncclGroupMode--;
if (ncclGroupMode > 0) return ncclSuccess;
int savedDev;
CUDACHECK(cudaGetDevice(&savedDev));
int activeThreads = 0;
int doneArray[MAX_ASYNC_OPS];
for (int i=0; ifuncType == ASYNC_FUNC_COLL) {
struct ncclP2Plist* p2plist = &args->coll.comm->p2plist;
if (p2plist->count != 0) {
struct ncclComm* comm = args->coll.comm;
args->coll.connect = 0;
for (int c=0; cp2pnChannels; c++)
args->coll.connect += comm->p2plist.connect.nsend[c] + comm->p2plist.connect.nrecv[c];
if (args->coll.connect) {
pthread_create(ncclGroupThreads+i, NULL, ncclAsyncThreadPreconnect, args);
}
}
}
}
for (int i=0; ifuncType == ASYNC_FUNC_COLL && (args->coll.connect)) {
int err = pthread_join(ncclGroupThreads[i], NULL);
if (err != 0) {
WARN("Error waiting for pthread_join : %s\n", strerror(errno));
return ncclSystemError;
}
NCCLCHECKGOTO(args->ret, ret, end);
}
}
...
} 对每个AsyncArgs启动一个线程执行ncclAsyncThreadPreconnect,这里对每个p2p channel都要执行ncclTransportP2pSetup,nsend,send等相关信息都记录在了p2plist。
void* ncclAsyncThreadPreconnect(void* args_) {
struct ncclAsyncArgs* args = (struct ncclAsyncArgs*)args_;
CUDACHECKTHREAD(cudaSetDevice(args->coll.comm->cudaDev));
for (int c=0; ccoll.comm->p2pnChannels; c++) {
struct ncclComm* comm = args->coll.comm;
struct ncclChannel* channel = comm->channels+c;
struct ncclP2PConnect* connect = &comm->p2plist.connect;
NCCLCHECKTHREAD(ncclTransportP2pSetup(comm, NULL, channel, connect->nrecv[c], connect->recv+c*comm->nRanks, connect->nsend[c], connect->send+c*comm->nRanks));
connect->nrecv[c] = 0;
connect->nsend[c] = 0;
}
return args;
} 然后开始将所有的ncclSend和ncclRecv任务分发到各个channel,遍历每个AsyncArgs的每个delta,得到send给谁(to),从哪里接收(from),然后使用p2pnChannelsPerPeer个channel并行收发,每个channel负责sendbytes / p2pnChannelsPerPeer大小。按照上述例子的话,rank0(第一个AsyncArgs)将会执行两次scheduleSendRecv,第一个是from=to=0,第二个是from=to=1。
ncclResult_t ncclGroupEnd() {
...
for (int i=0; ifuncType == ASYNC_FUNC_COLL) {
struct ncclComm* comm = args->coll.comm;
int rank = comm->rank;
int nRanks = comm->nRanks;
struct ncclP2Plist* p2plist = &args->coll.comm->p2plist;
if (p2plist->count) {
for (int delta=0; deltabuffSizes[NCCL_PROTO_SIMPLE] / NCCL_STEPS;
// Split each operation on p2pnChannelsPerPeer max.
ssize_t recvChunkSize = DIVUP(p2plist->peerlist[from].recvbytes, comm->p2pnChannelsPerPeer);
ssize_t sendChunkSize = DIVUP(p2plist->peerlist[to].sendbytes, comm->p2pnChannelsPerPeer);
recvChunkSize = std::max((ssize_t)1, DIVUP(recvChunkSize, stepSize)) * stepSize;
sendChunkSize = std::max((ssize_t)1, DIVUP(sendChunkSize, stepSize)) * stepSize;
ssize_t sendOffset = 0;
ssize_t recvOffset = 0;
int remaining = 1;
int chunk = 0;
while (remaining) {
int channelId = (delta+comm->p2pChannels[chunk%comm->p2pnChannelsPerPeer]) % comm->p2pnChannels;
remaining = 0;
ssize_t recvbytes = p2plist->peerlist[from].recvbytes-recvOffset;
ssize_t sendbytes = p2plist->peerlist[to].sendbytes-sendOffset;
if (recvbytes > recvChunkSize) { remaining = 1; recvbytes = recvChunkSize; } else p2plist->peerlist[from].recvbytes = -1;
if (sendbytes > sendChunkSize) { remaining = 1; sendbytes = sendChunkSize; } else p2plist->peerlist[to].sendbytes = -1;
if (sendbytes >= 0 || recvbytes >= 0) {
NCCLCHECKGOTO(scheduleSendRecv(comm, delta, channelId,
recvbytes, ((char*)(p2plist->peerlist[from].recvbuff)) + recvOffset,
sendbytes, ((const char*)(p2plist->peerlist[to].sendbuff)) + sendOffset), ret, end);
}
recvOffset += recvChunkSize;
sendOffset += sendChunkSize;
chunk++;
}
}
p2plist->count = 0;
}
}
}
...
}
然后生成一个ncclInfo,记录下channelId,sendbuff,recvbuff等信息,执行ncclSaveKernel。
static ncclResult_t scheduleSendRecv(struct ncclComm* comm, int delta, int channelId, ssize_t recvbytes, void* recvbuff, ssize_t sendbytes, const void* sendbuff) {
struct ncclInfo info = { ncclCollSendRecv, "SendRecv",
sendbuff, recvbuff, (size_t)std::max(sendbytes,recvbytes), ncclInt8, ncclSum, -1, comm, comm->userStream, /* Args */
1, 1 };
info.delta = delta;
info.channelId = channelId;
info.sendbytes = sendbytes;
info.recvbytes = recvbytes;
if (delta == 0 && sendbytes != recvbytes) return ncclInvalidUsage;
NCCLCHECK(ncclSaveKernel(&info));
return ncclSuccess;
} 然后通过ncclSaveKernel设置kernel相关参数,即ncclColl,图一中的args类型就是ncclColl,第七节中讲到在initChannel的时候会为每个channel申请collectives,即ncclColl数组。
struct ncclColl {
union {
struct {
struct CollectiveArgs args;
uint16_t funcIndex; // 应该使用哪个kernel
uint16_t nextIndex; // 下一个ncclColl
uint8_t active; // 当前ncclColl是否被占用
};
int data[0x10];
};
};
struct CollectiveArgs {
struct ncclDevComm* comm;
// local and remote input, output, and buffer
const void * sendbuff;
void * recvbuff;
// Op-specific fields. Make sure the common part stays the
// same on all structs of the union
union {
struct {
uint16_t nThreads;
} common;
struct {
uint16_t nThreads;
uint8_t bid;
uint8_t nChannels;
uint32_t root;
size_t count;
size_t lastChunkSize;
} coll;
struct {
uint16_t nThreads;
uint16_t unused;
int32_t delta;
size_t sendCount;
size_t recvCount;
} p2p;
};
};computeColl中会通过ncclInfo初始化ncclColl coll,比如sendbuf,recvbuf,comm等,然后设置myParams的blockDim,根据info中的channelId找到channel,尝试将当前的coll加入到channel的collectives,collFifoTail为collectives队尾,对应的ncclColl为c,首先需等待c的active直到不被占用,然后将coll拷贝到c,设置active为1,将channel的collcount加一,collFifoTail指向下一个ncclColl,c的nextIndex设置为collFifoTail。注意在当前场景下函数ncclProxySaveP2p没有作用,因此略去。
ncclResult_t ncclSaveKernel(struct ncclInfo* info) {
if (info->comm->nRanks == 1 && info->coll != ncclCollSendRecv) {
if (info->sendbuff != info->recvbuff)
CUDACHECK(cudaMemcpyAsync(info->recvbuff, info->sendbuff, info->nBytes, cudaMemcpyDeviceToDevice, info->stream));
return ncclSuccess;
}
struct ncclColl coll;
struct ncclProxyArgs proxyArgs;
memset(&proxyArgs, 0, sizeof(struct ncclProxyArgs));
NCCLCHECK(computeColl(info, &coll, &proxyArgs));
info->comm->myParams->blockDim.x = std::max(info->comm->myParams->blockDim.x, info->nThreads);
int nChannels = info->coll == ncclCollSendRecv ? 1 : coll.args.coll.nChannels;
int nSubChannels = (info->pattern == ncclPatternCollTreeUp || info->pattern == ncclPatternCollTreeDown) ? 2 : 1;
for (int bid=0; bidcoll == ncclCollSendRecv) ? info->channelId :
info->comm->myParams->gridDim.x % info->comm->nChannels;
struct ncclChannel* channel = info->comm->channels+channelId;
if (channel->collCount == NCCL_MAX_OPS) {
WARN("Too many aggregated operations on channel %d (%d max)", channel->id, NCCL_MAX_OPS);
return ncclInvalidUsage;
}
// Proxy
proxyArgs.channel = channel;
// Adjust pattern for CollNet based on channel index
if (nSubChannels == 2) {
info->pattern = (channelId < info->comm->nChannels/nSubChannels) ? ncclPatternCollTreeUp : ncclPatternCollTreeDown;
}
if (info->coll == ncclCollSendRecv) {
info->comm->myParams->gridDim.x = std::max(info->comm->myParams->gridDim.x, channelId+1);
NCCLCHECK(ncclProxySaveP2p(info, channel));
} else {
NCCLCHECK(ncclProxySaveColl(&proxyArgs, info->pattern, info->root, info->comm->nRanks));
}
info->comm->myParams->gridDim.x++;
int opIndex = channel->collFifoTail;
struct ncclColl* c = channel->collectives+opIndex;
volatile uint8_t* activePtr = (volatile uint8_t*)&c->active;
while (activePtr[0] != 0) sched_yield();
memcpy(c, &coll, sizeof(struct ncclColl));
if (info->coll != ncclCollSendRecv) c->args.coll.bid = bid % coll.args.coll.nChannels;
c->active = 1;
opIndex = (opIndex+1)%NCCL_MAX_OPS;
c->nextIndex = opIndex;
channel->collFifoTail = opIndex;
channel->collCount++;
}
info->comm->opCount++;
return ncclSuccess;
}
到这里scheduleSendRecv就执行结束了,回到ncclGroupEnd继续看,这里会对每个AsyncArgs执行ncclBarrierEnqueue
ncclResult_t ncclGroupEnd() {
...
for (int i=0; ifuncType == ASYNC_FUNC_COLL) {
if (args->coll.comm->userStream == NULL)
CUDACHECKGOTO(cudaSetDevice(args->coll.comm->cudaDev), ret, end);
NCCLCHECKGOTO(ncclBarrierEnqueue(args->coll.comm), ret, end);
}
}
...
} 首先会通过setupLaunch设置myParams。
ncclResult_t ncclBarrierEnqueue(struct ncclComm* comm) {
struct cudaLaunchParams* params = comm->myParams;
if (params->gridDim.x == 0) return ncclSuccess;
NCCLCHECK(setupLaunch(comm, params));
...
return ncclSuccess;
}我们之前在channel搜索的时候提过一个channel对应一个block,在setupLaunch这里就能看到会遍历p2p channel,有几个channel就将gridDim.x设置为几。但是由于有的channel上没有p2p操作,因此,需要为这些空channel fake一个ncclColl,设置delta为-1表示这是没有p2p操作的channel,并设置funcIndex,comm等其他信息。然后设置最后一个ncclColl的active为2表示这是最后一个ncclColl。然后将第一个channel的第一个ncclColl拷贝到comm->args然后设置myParam中的func,到这里kernel所需的参数就设置好了。
ncclResult_t setupLaunch(struct ncclComm* comm, struct cudaLaunchParams* params) {
// Only launch blocks where we have work to do.
for (int c=0; cp2pnChannels; c++) {
if (comm->channels[c].collCount) params->gridDim.x = c+1;
}
// Set active = 2 for the last operation and add a no-op on empty channels (p2p case).
for (int c=0; cgridDim.x; c++) {
struct ncclChannel* channel = comm->channels+c;
if (channel->collCount == 0) {
int opIndex = channel->collFifoTail;
struct ncclColl* c = channel->collectives+opIndex;
volatile uint8_t* activePtr = (volatile uint8_t*)&c->active;
while (activePtr[0] != 0) sched_yield();
c->args.p2p.delta = -1; // no-op
c->funcIndex = FUNC_INDEX_P2P;
c->args.comm = comm->devComm;
c->active = 1;
opIndex = (opIndex+1)%NCCL_MAX_OPS;
c->nextIndex = opIndex;
channel->collFifoTail = opIndex;
channel->collCount++;
}
channel->collectives[(channel->collStart+channel->collCount-1)%NCCL_MAX_OPS].active = 2;
}
// Find the first operation, choose the kernel accordingly and pass it
// as the first argument.
struct ncclColl* coll = comm->channels[0].collectives+comm->channels[0].collStart;
memcpy(&comm->args, coll, sizeof(struct ncclColl));
// As we pass that coll directly, we can free it immediately.
coll->active = 0;
params->func = ncclKerns[coll->funcIndex];
return ncclSuccess;
} 然后回到ncclBarrierEnqueue,会执行ncclCpuBarrierIn。
ncclResult_t ncclBarrierEnqueue(struct ncclComm* comm) {
...
if (comm->launchMode == ncclComm::GROUP) {
int isLast = 0;
NCCLCHECK(ncclCpuBarrierIn(comm, &isLast));
if (isLast) {
// I'm the last. Launch all operations.
NCCLCHECK(ncclLaunchCooperativeKernelMultiDevice(comm->intraParams, comm->intraCudaDevs, comm->intraRanks, *comm->intraCGMode));
NCCLCHECK(ncclCpuBarrierLast(comm));
}
}
return ncclSuccess;
}这里会对intraBarrier进行cas操作,直到第intraRanks次执行ncclBarrierEnqueue才会将isLast设置为1,换句话说只有执行最后一个AsyncArgs时才会起kernel。
ncclResult_t ncclCpuBarrierIn(struct ncclComm* comm, int* isLast) {
volatile int* ptr = (volatile int*)(comm->intraBarrier+comm->intraPhase);
int val = *ptr;
bool done = false;
while (done == false) {
if (val >= comm->intraRanks) {
WARN("Trying to launch too many collectives");
return ncclInvalidUsage;
}
if (val+1 == comm->intraRanks) {
// Reset the barrier.
comm->intraBarrier[comm->intraPhase^1] = 0;
*isLast = 1;
return ncclSuccess;
}
done = __sync_bool_compare_and_swap(ptr, val, val+1);
val++;
}
*isLast = 0;
return ncclSuccess;
}然后通过cudaLaunchCooperativeKernelMultiDevice一次性在多个设备上启动kernel。
ncclResult_t ncclLaunchCooperativeKernelMultiDevice(struct cudaLaunchParams *paramsList, int* cudaDevs, int numDevices, int cgMode) {
#if CUDART_VERSION >= 9000
if (cgMode & 0x01) {
CUDACHECK(cudaLaunchCooperativeKernelMultiDevice(paramsList, numDevices,
// These flags are to reduce the latency of using this API
cudaCooperativeLaunchMultiDeviceNoPreSync|cudaCooperativeLaunchMultiDeviceNoPostSync));
return ncclSuccess;
}
#endif
int savedDev;
CUDACHECK(cudaGetDevice(&savedDev));
for (int i = 0; i < numDevices; i++) {
struct cudaLaunchParams* params = paramsList+i;
CUDACHECK(cudaSetDevice(cudaDevs[i]));
CUDACHECK(cudaLaunchKernel(params->func, params->gridDim, params->blockDim, params->args, params->sharedMem, params->stream));
}
CUDACHECK(cudaSetDevice(savedDev));
return ncclSuccess;
}kernel执行
ncclKerns定义如下,我们用的是第一个,即ncclSendRecvKernel_copy_i8
#define NCCL_KERN_NAME(coll, op, dtype) \
coll##Kernel_##op##_##dtype
static void* const ncclKerns[1+NCCL_NUM_FUNCTIONS*ncclNumOps*ncclNumTypes*NCCL_NUM_ALGORITHMS*NCCL_NUM_PROTOCOLS] = {
(void*)NCCL_KERN_NAME(ncclSendRecv, copy, i8),
NCCL_FUNCS2B(ncclBroadcast),
NCCL_FUNCS2A(ncclReduce),
NCCL_FUNCS2B(ncclAllGather),
NCCL_FUNCS2A(ncclReduceScatter),
NCCL_FUNCS2A(ncclAllReduce)
};第一个ncclColl通过参数传入了kernel,所以第0个block的c可以直接设置为firstcoll,其他的block则需要load_coll进行拷贝,load结束后可以设置host的ncclColl的active为0。
static __device__ void load_parallel(void* dst, void* src, size_t size, int tid) {
int* d = (int*)dst;
int* s = (int*)src;
for (int o = tid; o < (size/sizeof(int)); o += blockDim.x) d[o] = s[o];
}
static __device__ void load_coll(struct ncclColl* localColl, struct ncclColl* hostColl, int tid, struct ncclDevComm* comm) {
// Check whether the last operation was aborted and make sure all threads exit
int abort = tid == 0 ? *(comm->abortFlag) : 0;
exitIfAbortBarrier(abort);
load_parallel(localColl, hostColl, sizeof(struct ncclColl), tid);
__syncthreads();
if (tid == 0) hostColl->active = 0;
}然后开始while循环遍历执行每一个ncclColl,直到ncclColl的active为2,表示这是最后一个,此时会退出循环。
#define IMPL_COLL_KERN(coll, op, ncclFunc, dtype, ctype, fIndex) \
__global__ void NCCL_KERN_NAME(coll, op, dtype)(struct ncclColl firstColl) { \
int tid = threadIdx.x; \
int bid = blockIdx.x; \
__shared__ volatile uint64_t shmem[NCCL_LL128_SHMEM_SIZE]; \
ncclShmem = shmem; \
__shared__ struct ncclColl localColl; \
\
struct ncclDevComm* comm = firstColl.args.comm; \
struct ncclChannel* channel = comm->channels+bid; \
struct ncclColl* c; \
if (bid == 0) { \
/* To optimize for latency, (only) the first operation is passed as argument.*/ \
c = &firstColl; \
} else { \
c = &localColl; \
load_coll(c, channel->collectives+channel->collFifoHead, tid, comm); \
} \
while (1) { \
if (tid < c->args.common.nThreads) { \
if (c->funcIndex == fIndex) { \
coll##Kernel, ctype>(&c->args); \
} else { \
ncclFuncs[c->funcIndex](&c->args); \
} \
} \
int nextIndex = c->nextIndex; \
if (tid == 0) channel->collFifoHead = nextIndex; \
\
if (c->active == 2) { \
return; \
} \
\
/* Load next collective operation*/ \
c = &localColl; /* for bid 0 */ \
load_coll(c, channel->collectives+nextIndex, tid, comm); \
} \
} 对每个ncclColl会执行ncclSendRecvKernel<4, FuncSum
首先计算nthreads,这里为256,从args中获取到sendbuff和recvbuff,如果delta小于0,说明这个channel没有p2p操作,是fake的,因此直接return即可,如果delta为0,那么就是同卡之间的send/recv,那么直接通过ReduceOrCopyMulti执行数据的拷贝,每次拷贝长度为blockSize。
template
__device__ void ncclSendRecvKernel(struct CollectiveArgs* args) {
const int tid = threadIdx.x;
const int nthreads = args->p2p.nThreads-2*WARP_SIZE;
// Compute pointers
const T* sendbuff = (const T*)args->sendbuff;
T* recvbuff = (T*)args->recvbuff;
if (args->p2p.delta < 0 ) return; // No-op
if (args->p2p.delta == 0) {
if (tid < nthreads && sendbuff != recvbuff) {
// local copy : ReduceOrCopyMulti takes an int as number of elements,
// so we split it in blocks of 1G elements.
int blockSize = 1<<30;
for (size_t offset=0; offsetp2p.sendCount; offset += blockSize) {
size_t remaining = args->p2p.sendCount - offset;
if (remaining < blockSize) blockSize = remaining;
ReduceOrCopyMulti(tid, nthreads, 1, &sendbuff, 1, &recvbuff, blockSize);
sendbuff += blockSize; recvbuff += blockSize;
}
}
return;
}
...
}
然后看下ReduceOrCopyMulti,该函数负责实际数据拷贝,将nsrcs个源数组通过FUNC规约后拷贝到ndsts个目标数组中,每个数组长度都为N。ReduceOrCopyMulti会尝试使用128位向量化load/store来提高带宽利用率,并减少指令数量以提高性能,但是前提是待处理的数据是对齐的(16字节),如果src和dst不是16字节对齐的,但是对16取模后是一样的,那么可以先通过非向量化指令拷贝前面没对齐的数据,之后的数据就可以用向量化指令处理了;如果取模后也不一样,那就只能用非向量化指令进行拷贝了。整体分为三步骤,先处理前边未对齐的,然后处理中间对齐的数据,最后处理尾部数据。
ptrAlign128就是对16字节取模,首先通过异或判断srcs和dsts的首地址对齐是否一致,如果不一致,那么Npreamble = N,后续都需要用非向量化指令拷贝,否则Npreamble = (alignof(Pack128) - align) % alignof(Pack128),即前面未对齐的一部分。
typedef ulong2 Pack128;
template
__device__ int ptrAlign128(T* ptr) { return (uint64_t)ptr % alignof(Pack128); }
template
__device__ __forceinline__ void ReduceOrCopyMulti(const int tid, const int nthreads,
int nsrcs, const T* srcs[MAXSRCS], int ndsts, T* dsts[MAXDSTS],
int N) {
int Nrem = N;
if (Nrem <= 0) return;
int alignDiff = 0;
int align = ptrAlign128(srcs[0]);
#pragma unroll
for (int i=1; i(tid, nthreads, nsrcs, srcs, ndsts, dsts, 0, Npreamble);
Nrem -= Npreamble;
if (Nrem == 0) return;
}
...
} 对于未对齐的这部分数据,直接使用ReduceCopyMulti通过非向量化指令拷贝即可,128线程从src中读取连续的128个int8_t,然后存到dst,循环执行。访问模式如下图。
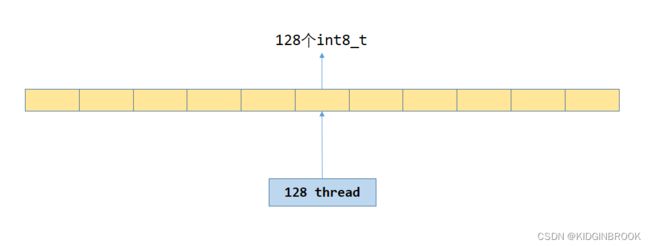 图二
图二
template inline __device__
T vFetch(const volatile T* ptr) {
return *ptr;
}
template inline __device__
void vStore(volatile T* ptr, const T val) {
*ptr = val;
}
template
__device__ __forceinline__ void ReduceCopyMulti(const int tid, const int nthreads,
int nsrcs, const T* srcs[MAXSRCS], int ndsts, T* dsts[MAXDSTS],
const int offset, const int N) {
for (int idx = offset+tid; idx < offset+N; idx += nthreads) {
T val = vFetch(srcs[0]+idx);
#pragma unroll
for (int i=1; i 然后开始第二步,处理对齐的部分数据,这里分为两步,首先对于整除packFactor * AUTOUNROLL * WARP_SIZE的部分数据可以开启AUTOUNROLL执行ReduceCopy128bMulti,对于剩余的部分设置AUTOUNROLL为1执行ReduceCopy128bMulti。
最后对于不足packFactor,就是说最后凑不够128位的数据还是使用ReduceCopyMulti进行非向量化拷贝。
template
__device__ __forceinline__ void ReduceOrCopyMulti(const int tid, const int nthreads,
int nsrcs, const T* srcs[MAXSRCS], int ndsts, T* dsts[MAXDSTS],
int N) {
...
int offset = Npreamble;
// stage 2: fast path: use 128b loads/stores to do the bulk of the work,
// assuming the pointers we have are all 128-bit alignable.
int w = tid / WARP_SIZE; // Warp number
int nw = nthreads / WARP_SIZE; // Number of warps
int t = tid % WARP_SIZE; // Thread (inside the warp)
const int packFactor = sizeof(Pack128) / sizeof(T);
// stage 2a: main loop
int Npack2a = (Nrem / (packFactor * AUTOUNROLL * WARP_SIZE))
* (AUTOUNROLL * WARP_SIZE); // round down
int Nelem2a = Npack2a * packFactor;
ReduceCopy128bMulti(w, nw, t, nsrcs, srcs, ndsts, dsts, offset, Npack2a);
Nrem -= Nelem2a;
if (Nrem == 0) return;
offset += Nelem2a;
// stage 2b: slightly less optimized for section when we don't have full
// unrolling
int Npack2b = Nrem / packFactor;
int Nelem2b = Npack2b * packFactor;
ReduceCopy128bMulti(w, nw, t, nsrcs, srcs, ndsts, dsts, offset, Npack2b);
Nrem -= Nelem2b;
if (Nrem == 0) return;
offset += Nelem2b;
// stage 2c: tail
ReduceCopyMulti(tid, nthreads, nsrcs, srcs, ndsts, dsts, offset, Nrem);
}
然后看下ReduceCopy128bMulti使用向量化指令拷贝的过程,这里的load/store使用了内联PTX,不过感觉并没有必要。Fetch128就是从p指向的位置load一个ulong2到寄存器变量v里。这里有一个变量UNROLL,一个warp一次处理连续的UNROLL * WARP_SIZE个ulong2,其实就是类似循环展开的作用,当UNROLL为4的时候访存模式如下图,比如线程0的话会将4个黄框的第一个ulong2读取到寄存器变量vals,然后写到dst。
 图三
图三
特别的当UNROLL为1的时候,访存模式和ReduceCopyMulti类似,即128线程处理连续的128个ulong2,然后接着循环执行下一个128个ulong2。
inline __device__ void Fetch128(Pack128& v, const Pack128* p) {
asm volatile("ld.volatile.global.v2.u64 {%0,%1}, [%2];" : "=l"(v.x), "=l"(v.y) : "l"(p) : "memory");
}
inline __device__ void Store128(Pack128* p, Pack128& v) {
asm volatile("st.volatile.global.v2.u64 [%0], {%1,%2};" :: "l"(p), "l"(v.x), "l"(v.y) : "memory");
}
template
struct MULTI128 {
__device__ void operator()(Pack128& x, Pack128& y) {
x.x = MULTI()(x.x, y.x);
x.y = MULTI()(x.y, y.y);
}
};
template
__device__ __forceinline__ void ReduceCopy128bMulti( const int w, const int nw, const int t,
int nsrcs, const T* s[MAXSRCS], int ndsts, T* d[MAXDSTS],
const int elemOffset, const int Npack) {
const int inc = nw * UNROLL * WARP_SIZE;
int offset = w * UNROLL * WARP_SIZE + t;
const Pack128* srcs[MAXSRCS];
for (int i=0; i()(vals[u], vals2[u]);
}
#pragma unroll 1
for (int i=MINSRCS; i()(vals[u], vals2[u]);
}
// Store
for (int i = 0; i < MINDSTS; i++) {
for (int u = 0; u < UNROLL; ++u) Store128(dsts[i]+u*WARP_SIZE, vals[u]);
}
#pragma unroll 1
for (int i=MINDSTS; i 到这里同一张卡内部的send/recv就执行完成了,接着看ncclSendRecvKernel,这里可以看到之前说的320线程中160个线程用于send,160线程用于recv,send和recv线程都实例化了一个ncclPrimitives,通过directSend发送数据,通过directRecv接收数据。
template
__device__ void ncclSendRecvKernel(struct CollectiveArgs* args) {
const int tid = threadIdx.x;
const int nthreads = args->p2p.nThreads-2*WARP_SIZE;
// Compute pointers
const T* sendbuff = (const T*)args->sendbuff;
T* recvbuff = (T*)args->recvbuff;
...
struct ncclDevComm* comm = args->comm;
struct ncclChannel* channel = comm->channels+blockIdx.x;
const int stepSize = comm->buffSizes[NCCL_PROTO_SIMPLE]/(sizeof(T)*NCCL_STEPS)/SENDRECV_SLICEFACTOR;
int nthreadsSplit = nthreads/2;
// We set NRECV or NSEND to 2 to use different barriers in primitives for the send threads and
// receive threads, but then we define all peers to -1 since sender threads don't receive and
// receive threads don't send.
int peerNone[2] = {-1,-1};
if (tid < nthreadsSplit + WARP_SIZE ) {
const ssize_t sendSize = args->p2p.sendCount;
if (sendSize < 0) return;
int peer = (comm->rank+(int)args->p2p.delta)%comm->nRanks;
ncclPrimitives
prims(tid, nthreadsSplit, peerNone, &peer, recvbuff, stepSize*4, channel, comm);
if (sendSize == 0) {
prims.send(sendbuff, 0);
} else for (ssize_t offset = 0; offset < sendSize; offset += stepSize) {
int realChunkSize = min(stepSize, sendSize-offset);
ALIGN_SIZE(realChunkSize, nthreads*sizeof(uint64_t)/sizeof(T));
int nelem = min(realChunkSize, sendSize-offset);
prims.directSend(sendbuff+offset, offset, nelem);
}
} else {
const ssize_t recvSize = args->p2p.recvCount;
if (recvSize < 0) return;
int peer = (comm->rank-(int)args->p2p.delta+comm->nRanks)%comm->nRanks;
ncclPrimitives
prims(tid-nthreadsSplit-WARP_SIZE, nthreads-nthreadsSplit, &peer, peerNone, recvbuff, stepSize*4, channel, comm);
if (recvSize == 0) {
prims.recv(recvbuff, 0);
} else for (ssize_t offset = 0; offset < recvSize; offset += stepSize) {
int realChunkSize = min(stepSize, recvSize-offset);
ALIGN_SIZE(realChunkSize, nthreads*sizeof(uint64_t)/sizeof(T));
int nelem = min(realChunkSize, recvSize-offset);
prims.directRecv(recvbuff+offset, offset, nelem);
}
}
}
为了方便理解,这里写下各个模板类型
/*
send:
UNROLL: 4,
SLICESPERCHUNK: 1,
SLICESTEPS: 1,
T: int8_t,
NRECV: 2,
NSEND: 1,
DIRECT: 1,
FUNC: FuncSum
recv:
UNROLL: 4,
SLICESPERCHUNK: 1,
SLICESTEPS: 1,
T: int8_t,
NRECV: 1,
NSEND: 2,
DIRECT: 1,
FUNC: FuncSum
*/
template
class ncclPrimitives {
...
} 先看下ncclPrimitives的构造函数,这里nthreads为160 - 32 = 128,其中32线程为同步线程。由于send的recvPeer为-1,所以send不会loadRecvConn,recv不会loadSendConn。
__device__ __forceinline__
ncclPrimitives(const int tid, const int nthreads, int* recvPeers, int* sendPeers, T* directBuff, int stepSize, struct ncclChannel* channel, struct ncclDevComm* comm)
: comm(comm), tid(tid), nthreads(nthreads), wid(tid%WARP_SIZE), stepSize(stepSize) {
// Make sure step is updated before we read it.
barrier();
for (int i=0; i= 0; i++) loadRecvConn(&channel->devPeers[recvPeers[i]].recv.conn, i, directBuff);
for (int i=0; i= 0; i++) loadSendConn(&channel->devPeers[sendPeers[i]].send.conn, i);
loadRecvSync();
loadSendSync();
} 然后开始load recv的ncclConnInfo,保存下来recvBuff和step等信息,由于在p2p的setup过程中支持p2pread,因此conn->direct没有设置NCCL_DIRECT_GPU,所以不会进入第一个if。每个warp的第一个线程保存了ncclConnInfo,将recvConnTail和recvConnHead初始化为recvStep。
__device__ __forceinline__ void loadRecvConn(struct ncclConnInfo* conn, int i, T* directBuff) {
recvBuff[i] = (const T*)conn->buffs[NCCL_PROTO_SIMPLE];
recvStep[i] = conn->step;
recvStep[i] = ROUNDUP(recvStep[i], SLICESPERCHUNK*SLICESTEPS);
recvDirectBuff[i] = NULL;
if (DIRECT && (conn->direct & NCCL_DIRECT_GPU)) {
recvDirectBuff[i] = directBuff;
if (tid == 0) *conn->ptrExchange = directBuff;
}
if (wid == i) recvConn = conn;
if (wid == i) recvConnTail = recvConnHead = recvStep[i]; // Make sure we set this after rounding up
nrecv++;
}然后load send的conn,保存step和sendBuff,每个warp的第一个线程保存conn,并将sendConnTail和sendConnHead初始化为step
__device__ __forceinline__ void loadSendConn(struct ncclConnInfo* conn, int i) {
sendBuff[i] = (T*)conn->buffs[NCCL_PROTO_SIMPLE];
sendStep[i] = conn->step;
sendStep[i] = ROUNDUP(sendStep[i], SLICESPERCHUNK*SLICESTEPS);
sendDirectBuff[i] = NULL;
if (DIRECT && (conn->direct & NCCL_DIRECT_GPU)) {
void* volatile* ptr = conn->ptrExchange;
while ((sendDirectBuff[i] = (T*)(*ptr)) == NULL);
barrier();
if (tid == 0) *ptr = NULL;
}
if (wid == i) sendConn = conn;
if (wid == i) sendConnTail = sendConnHead = sendStep[i]; // Make sure we set this after rounding up
nsend++;
}第二个warp的第一个线程保存tail,并缓存tail的值;
同步线程的第一个线程保存了head
__device__ __forceinline__ void loadRecvSync() {
if (tid >= WARP_SIZE && tid < 2*WARP_SIZE && widtail;
recvConnTailCache = *recvConnTailPtr;
}
if (tid >= nthreads && wid < nrecv) {
recvConnHeadPtr = recvConn->head;
// Return credits in case we rounded up.
*recvConnHeadPtr = recvConnHead;
}
} 第一个线程保存了head,并缓存了head中值,fifo是proxy用的,本节暂用不到;
同步线程里的第一个线程保存了tail。
__device__ __forceinline__ void loadSendSync() {
if (tid < nsend) {
sendConnHeadPtr = sendConn->head;
sendConnHeadCache = *sendConnHeadPtr;
sendConnFifoPtr = sendConn->fifo;
}
if (tid >= nthreads && widtail;
}
} 然后我们来看下刚刚提到的这些变量都是干嘛的,在p2p transport的setup阶段,即第八节中讲的,每个rank都创建了用于协调发送接收过程的变量,如下所示,由于支持p2p read,所以buff位于发送端;tail位于接收端,发送端和接收端共同持有,由发送端更新,head位于发送端,发送端和接收端共同持有,由接收端进行更新;在ncclPrimitives的接收端,tail叫做recvConnTailPtr,head叫做recvConnHeadPtr;而在发送端,tail叫做sendConnTailPtr,head叫做sendConnHeadPtr。
 图四
图四
然后看下这些变量是如何协调发送接收过程的
 图五
图五
中间黄色的框就是图四里标的buff,整个buff被划分为NCCL_STEP块,图五只画出来六块。
sendConnHead,sendConnTailPtr,sendStep由发送端更新,每次发送都会加一,这几个值其实是相等的(所以感觉这几个变量有些冗余)。
recvConnTail,recvConnHeadPtr,recvStep由接收端更新,每次接收都会加一,这几个值其实是相等的。
因此对于接收端,只要recvConnTail小于recvConnTailPtr,就表示有数据可以接收,并将recvConnTail加一表示又接收了一块数据。
inline __device__ void waitRecv() {
spins = 0;
if (recvConnTailPtr) {
while (recvConnTailCache < recvConnTail + SLICESTEPS) {
recvConnTailCache = *recvConnTailPtr;
if (checkAbort(wid, 0)) break;
}
recvConnTail += SLICESTEPS;
}
}对于发送端,只要sendConnHead大于sendConnenHeadPtr加NCCL_STEP就说明有剩余空间用来发送,并将sendConnHead加一表示又执行了一次发送。
inline __device__ void waitSend(int nbytes) {
spins = 0;
if (sendConnHeadPtr) {
while (sendConnHeadCache + NCCL_STEPS < sendConnHead + SLICESTEPS) {
sendConnHeadCache = *sendConnHeadPtr;
if (checkAbort(wid, 1)) break;
}
if (sendConnFifoPtr) {
sendConnFifoPtr[sendConnHead%NCCL_STEPS] = nbytes;
}
sendConnHead += SLICESTEPS;
}
}然后看下directSend的过程,srcs数组只有一个元素,srcPtr就是args->sendbuff,即用户传入的,所以srcs[0]即sendbuff;dsts数组也只有一个元素。
__device__ __forceinline__ void
directSend(const T* src, ssize_t directOffset, int nelem) {
GenericOp<0, 1, 0, 1, 1, 0>(src, NULL, nelem, directOffset);
}
__device__ __forceinline__ void
directRecv(T* dst, ssize_t directOffset, int nelem) {
GenericOp<1, 0, 1, 0, 0, 1>(NULL, dst, nelem, directOffset);
}
/*
send:
DIRECTRECV: 0
DIRECTSEND: 1
RECV: 0
SEND: 1
SRC: 1
DST: 0
dstPtr: NULL
*/
template
inline __device__ void
GenericOp(const T* srcPtr, T* dstPtr, int nelem, ssize_t directOffset) {
int offset = 0;
int sliceSize = stepSize*SLICESTEPS;
int dataSize = max(DIVUP(nelem, 16*SLICESPERCHUNK)*16, sliceSize/32);
const T* srcs[RECV*NRECV+SRC];
srcs[0] = SRC ? srcPtr : directRecvPtr(0, directOffset);
if (RECV) {
if (SRC) srcs[1] = recvPtr(0);
for (int i=1; i(0, directOffset);
if (SEND) {
if (DST) dsts[1] = directSendPtr(0, directOffset);
for (int i=1; i(i, directOffset);
}
...
} DIRECTSEND为1,但是sendDirectBuff为NULL,所以dsts等于sendPtr(i)
template
inline __device__ T* directSendPtr(int i, ssize_t directOffset) {
return DIRECTSEND && sendDirectBuff[i] ? sendDirectBuff[i]+directOffset : sendPtr(i);
} 可以看到sendPtr就是通过sendStep在buff里找到了接下来该使用的一块,即图五的某个黄框。
inline __device__ int sendOffset(int i) { return (sendStep[i]%NCCL_STEPS)*stepSize; }
inline __device__ T* sendPtr(int i) { return ((T*)sendBuff[i])+sendOffset(i); }在看实际数据发送之前,我们看下几个同步函数,barrier()用于同步整个发送或者接收线程,subBarrier()负责同步发送/接收线程中的数据搬运线程(除去同步线程),其实就是通过不同的barrier同步不同的线程组。
inline __device__ void barrier() {
if (NSEND>NRECV) {
asm volatile ("bar.sync 1, %0;" :: "r"(nthreads+WARP_SIZE));
} else {
asm volatile ("bar.sync 2, %0;" :: "r"(nthreads+WARP_SIZE));
}
}
inline __device__ void subBarrier() {
if (NSEND>NRECV) {
asm volatile ("bar.sync 3, %0;" :: "r"(nthreads));
} else {
asm volatile ("bar.sync 4, %0;" :: "r"(nthreads));
}
}然后继续往下看,对于send操作的话,如果不是同步线程,需要执行上述waitSend的操作,直到可发送,由于只有第一个线程会执行waitSend,所以其他线程需要通过subBarrier等待第一个线程执行waitSend的过程,不然可能会出现buff已经满了,又开始发送导致数据覆盖的情况。然后通过ReduceOrCopyMulti将数据从src拷贝到dst,这个函数前边介绍过,不再赘述。接下来的barrier保证数据发送之后才更新队列指针信息,不然可能会出现队列指针已经更新,但是数据还没有拷贝结束的情况。然后通过incSend更新step。然后对于与同步线程,需要执行一下__threadfence_system之后再通过postSend更新tail指针,这个fence是为了保证其他线程在看到tail指针更新之后一定可以看到buff中正确的数据,而用system级别的原因是机器间通信的场景,会有cpu线程,所以必须通过system级别的内存屏障保证网络通信的正确性,而__threadfence_system比较耗时,所以才引入了单独的warp做同步以提高性能。由于postSend和执行内存屏障的线程可能不是同一个,所以这里需要通过__syncwarp同步一下当前warp。
template
inline __device__ void
GenericOp(const T* srcPtr, T* dstPtr, int nelem, ssize_t directOffset) {
...
bool syncThread = tid >= nthreads;
#pragma unroll
for (int slice=0; slice 0) {
subBarrier();
if (DIRECTRECV && recvDirectBuff[0]) {
// We can only have one direct receive. Since srcs[0] == dstPtr+offset, skip one copy
if (SEND) {
ReduceOrCopyMulti(tid, nthreads, 1, srcs, nsend, dsts+1, realSize);
}
} else {
ReduceOrCopyMulti(tid, nthreads, RECV*nrecv+SRC, srcs, SEND*nsend+DST, dsts, realSize);
}
}
}
barrier();
FOR_SEND(incSend);
FOR_RECV(incRecv);
if (syncThread) {
if (SEND) {
if (realSize > 0 && wid == 0) __threadfence_system();
__syncwarp();
postSend();
}
if (RECV) postRecv();
}
srcs[0] += SRC ? realSize : directRecvInc(0, realSize, sliceSize);
for (int i=1-SRC; i(0, realSize, sliceSize);
for (int i=1-DST; i(i, realSize, sliceSize);
offset += realSize;
}
} 到这里基本就完成了单机内部ncclSend/ncclRecv的过程,主要就是两步,先通过peerlist将用户的操作记录下来,根据记录生成kernel所需要的参数,然后启动kernel执行拷贝即可。对于不同卡的情况,send将数据从用户指定的sendbuff拷贝到nccl p2p transport的buff,recv将数据从buff拷贝到用户指定的recvbuff,buff在这里其实就是一个fifo,nccl通过head,tail指针来完成对发送和接收过程的协调;对于同卡的情况直接通过kernel将数据从sendbuff拷贝到recvbuff即可。