kafka 核心知识分区和副本
在 Kafka 中还有两个特别重要的概念—主题(Topic)与分区(Partition)。Kafka 中的消息以主题为单位进行归类,生产者负责将消息发送到特定的主题(发送到 Kafka 集群中的每一条消息都要指定一个主题),而消费者负责订阅主题并进行消费。
主题是一个逻辑上的概念,它还可以细分为多个分区,一个分区只属于单个主题,很多时候也会把分区称为主题分区(Topic-Partition)。同一主题下的不同分区包含的消息是不同的,分区在存储层面可以看作一个可追加的日志(Log)文件,消息在被追加到分区日志文件的时候都会分配一个特定的偏移量(offset)。
offset 是消息在分区中的唯一标识,Kafka 通过它来保证消息在分区内的顺序性,不过 offset 并不跨越分区,也就是说,Kafka 保证的是分区有序而不是主题有序。

kafka分区机制
分区机制是kafka实现高吞吐的秘密武器,但这个武器用得不好的话也容易出问题,今天主要就来介绍分区的机制以及相关的部分配置。
首先,从数据组织形式来说,kafka有三层形式,kafka有多个主题,每个主题有多个分区,每个分区又有多条消息。
而每个分区可以分布到不同的机器上,这样一来,从服务端来说,分区可以实现高伸缩性,以及负载均衡,动态调节的能力。
当然多分区就意味着每条消息都难以按照顺序存储,那么是不是意味着这样的业务场景kafka就无能为力呢?不是的,最简单的做法可以使用单个分区,单个分区,所有消息自然都顺序写入到一个分区中,就跟顺序队列一样了。而复杂些的,还有其他办法,那就是使用按消息键,将需要顺序保存的消息存储的单独的分区,其他消息存储其他分区
分区个数选择
既然分区效果这么好,是不是越多分区越好呢?显而易见并非如此。
分区越多,所需要消耗的资源就越多。甚至如果足够大的时候,还会触发到操作系统的一些参数限制。比如linux中的文件描述符限制,一般在创建线程,创建socket,打开文件的场景下,linux默认的文件描述符参数,只有1024,超过则会报错。
因为每个业务场景都不同,只能结合具体业务来看。假如每秒钟需要从主题写入和读取1GB数据,而消费者1秒钟最多处理50MB的数据,那么这个时候就可以设置20-25个分区,当然还要结合具体的物理资源情况。
分区写入策略
所谓分区写入策略,即是生产者将数据写入到kafka主题后,kafka如何将数据分配到不同分区中的策略。
常见的有三种策略,轮询策略,随机策略,和按键保存策略。其中轮询策略是默认的分区策略,而随机策略则是较老版本的分区策略,不过由于其分配的均衡性不如轮询策略,故而后来改成了轮询策略为默认策略。
- 轮询策略
所谓轮询策略,即按顺序轮流将每条数据分配到每个分区中。
举个例子,假设主题test有三个分区,分别是分区A,分区B和分区C。那么主题对接收到的第一条消息写入A分区,第二条消息写入B分区,第三条消息写入C分区,第四条消息则又写入A分区,依此类推。
轮询策略是默认的策略,故而也是使用最频繁的策略,它能最大限度保证所有消息都平均分配到每一个分区。除非有特殊的业务需求,否则使用这种方式即可。
- 随机策略
随机策略,也就是每次都随机地将消息分配到每个分区。其实大概就是先得出分区的数量,然后每次获取一个随机数,用该随机数确定消息发送到哪个分区。
在比较早的版本,默认的分区策略就是随机策略,但其实使用随机策略也是为了更好得将消息均衡写入每个分区。但后来发现对这一需求而言,轮询策略的表现更优,所以社区后来的默认策略就是轮询策略了。
- 按键保存策略
按键保存策略,就是当生产者发送数据的时候,可以指定一个key,计算这个key的hashCode值,按照hashCode的值对不同消息进行存储。
至于要如何实现,那也简单,只要让生产者发送的时候指定key就行。欸刚刚不是说默认的是轮询策略吗?其实啊,kafka默认是实现了两个策略,没指定key的时候就是轮询策略,有的话那激素按键保存策略了。
上面有说到一个场景,那就是要顺序发送消息到kafka。前面提到的方案是让所有数据存储到一个分区中,但其实更好的做法,就是使用这种按键保存策略。
让需要顺序存储的数据都指定相同的键,而不需要顺序存储的数据指定不同的键
实现自定义分区
kafka提供了两种让我们自己选择分区的方法
- 第一种是在发送producer的时候,在ProducerRecord中直接指定,但需要知道具体发送的分区index,所以并不推荐。
- 第二种则是需要实现Partitioner.class类,并重写类中的partition(String topic, Object key, byte[] keyBytes,Object value, byte[] valueBytes, Cluster cluster) 方法。后面在生成kafka producer客户端的时候直接指定新的分区类就可以了。

kafka副本机制
Kafka 为分区引入了多副本(Replica)机制,通过增加副本数量可以提升容灾能力。
同一分区的不同副本中保存的是相同的消息(在同一时刻,副本之间并非完全一样),副本之间是“一主多从”的关系,其中 leader 副本负责处理读写请求,follower 副本只负责与 leader 副本的消息同步。副本处于不同的 broker 中,当 leader 副本出现故障时,从 follower 副本中重新选举新的 leader 副本对外提供服务。Kafka 通过多副本机制实现了故障的自动转移,当 Kafka 集群中某个 broker 失效时仍然能保证服务可用。
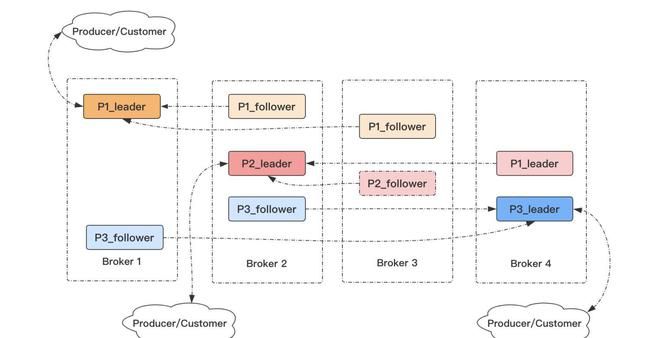
- kafka的副本都有哪些作用?
在kafka中,实现副本的目的就是冗余备份,且仅仅是冗余备份,所有的读写请求都是由leader副本进行处理的。follower副本仅有一个功能,那就是从leader副本拉取消息,尽量让自己跟leader副本的内容一致。
- leader副本挂掉后,如何选举新副本?
如果你对zookeeper选举机制有所了解,就知道zookeeper每次leader节点挂掉时,都会通过内置id,来选举处理了最新事务的那个follower节点。
从结果上来说,kafka分区副本的选举也是类似的,都是选择最新的那个follower副本,但它是通过一个In-sync(ISR)副本集合实现。
kafka会将与leader副本保持同步的副本放到ISR副本集合中。当然,leader副本是一直存在于ISR副本集合中的,在某些特殊情况下,ISR副本中甚至只有leader一个副本。
当leader挂掉时,kakfa通过zookeeper感知到这一情况,在ISR副本中选取新的副本成为leader,对外提供服务。
但这样还有一个问题,前面提到过,有可能ISR副本集合中,只有leader,当leader副本挂掉后,ISR集合就为空,这时候怎么办呢?这时候如果设置unclean.leader.election.enable参数为true,那么kafka会在非同步,也就是不在ISR副本集合中的副本中,选取出副本成为leader,但这样意味这消息会丢失,这又是可用性和一致性的一个取舍了。
- ISR副本集合保存的副本的条件是什么?
上面一直说ISR副本集合中的副本就是和leader副本是同步的,那这个同步的标准又是什么呢?
答案其实跟一个参数有关:replica.lag.time.max.ms。
前面说到follower副本的任务,就是从leader副本拉取消息,如果持续拉取速度慢于leader副本写入速度,慢于时间超过replica.lag.time.max.ms后,它就变成“非同步”副本,就会被踢出ISR副本集合中。但后面如何follower副本的速度慢慢提上来,那就又可能会重新加入ISR副本集合中了。
- producer的acks参数
跟副本关系最大的,那自然就是acks机制,acks决定了生产者如何在性能与数据可靠之间做取舍。
配置acks的代码其实很简单,只需要在新建producer的时候多加一个配置:
Properties properties = new Properties()
......
props.put("acks", "0/1/-1"); //配置acks,有三个可选值
......其他配置
Producer producer = new KafkaProducer[String, String](properties)acks这个配置可以指定三个值,分别是0,1和-1。我们分别来说三者代表什么:
- acks为0:这意味着producer发送数据后,不会等待broker确认,直接发送下一条数据,性能最快
- acks为1:为1意味着producer发送数据后,需要等待leader副本确认接收后,才会发送下一条数据,性能中等
- acks为-1:这个代表的是all,意味着发送的消息写入所有的ISR集合中的副本(注意不是全部副本)后,才会发送下一条数据,性能最慢,但可靠性最强