04.Finetune vs. Prompt
目录
- 语言模型回顾
- 大模型的两种路线
-
- 专才
- 通才
- 二者的比较
- 专才养成记
- 通才养成记
-
- Instruction Learning
- In-context Learning
- 自动Prompt
部分截图来自原课程视频《2023李宏毅最新生成式AI教程》,B站自行搜索
语言模型回顾
GPT:文字接龙
How are __.
Bert:文字填空
How __ you.
使用大型语言模型就好比下图:

小老鼠就能驾驭大象。
大模型的两种路线
专才
主要利用模型解决某一个特定的任务,例如翻译

或者是文本摘要:

通才
主要利用模型解决解决各种不同的任务,对不同Prompt有不同的响应。

例如上图中的红色字体就是Prompt。
早在18年就有The Natural Language Decathlon: Multitask Learning as Question Answering,让语言模型完成各种不同的任务,文章的思想就是将所有的不同的任务都看做是问答,例如:

上面的提问分别对应了多种不同的任务:阅读理解,摘要,情感分析等。
这些提问用在现在的GPT上就是Prompt
二者的比较
专才的优点:在专才的单一任务上比通才性能要强。
Is ChatGPT A Good Translator? Yes With GPT-4 As The Engine
这个文章给出分析九印证了这一点,先自问自答找出GPT翻译的Prompt:

然后给出12种翻译结果(两两互翻译),从结果中可以看到ChatGPT比单一任务模型的BLEU分数要低一些

这个文章是腾讯在ChatGPT刚出来的时候,还未发布API的时候测的(文章在23年3月有更新),且只做了10个句子。
微软在23年2月发表了How Good Are GPT Models at Machine Translation? A Comprehensive Evaluation,ChatGPT与在WMT上取得最好成绩的模型进行比较,还是比不过。

通才的优点:只需要重新设计Prompt就可以开发新功能,不需要修改代码。
专才养成记
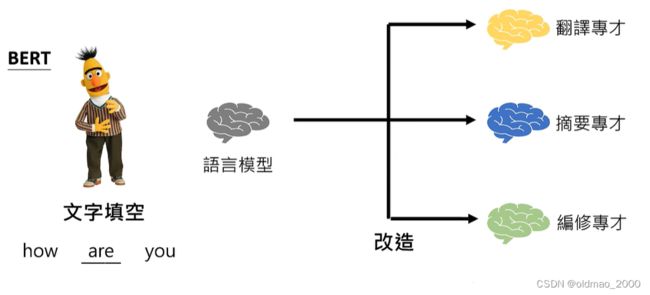
改造方式有两种:加外挂和微调
所谓加外挂就是基于BERT有四种用法,具体可以看这里。
微调:以翻译任务为例就是收集成对的语料,可以不用很大量,然后在训练好的语言模型(预训练好的)基础上进行GD。
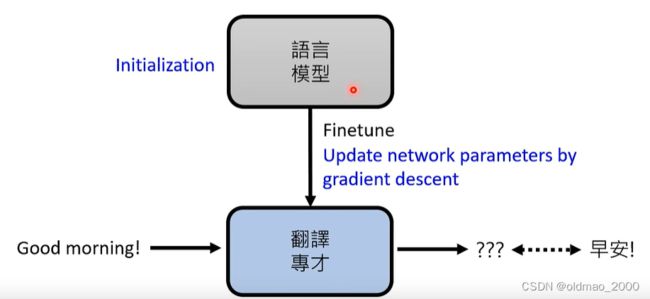
Adapter:在语言模型中加入额外的layer,在训练过程中保存语言模型的参数不变,只更新Adapter中的参数。

Adapter有很多种,可以看这里。
魔鬼筋肉人版BERT。。。
EXPLORING EFFICIENT-TUNING METHODS IN SELF-SUPERVISED SPEECH MODELS,这篇李宏毅团队发表的文章中介绍了如何在BERT里面加Adapter

Bitfit:把Bias作为额外插件,在微调时只更新神经元的Bias;
Houlsby:在最后的Feed-Forward后面的Houlsby再加入一层Feed-Forward结构,并只更新该结构的参数;
AdapterBias:是对后面Houlsby是结果加的Bias,主要是对结果进行平移;
Prefix-tuning:修改Attention部分;
LoRA:修改Attention部分。
这里给出了多个Adapter专才的解决方法

通才养成记
有两种做题方式:
Instruction Learning
根据题目叙述来回答问题

只做文字接龙的模型是看不同题目的,无法明白题目的含义,因此,需要对模型进行Instruction-tuning,就是对模型进行如下训练

21年的文章Multitask Prompted Training Enables Zero-Shot Task Generalization中就提出了类似的思想:
文章Finetuned Language Models Are Zero-Shot Learners提出FLAN(Finetuned Language Net),收集了大量不同领域NLP相关的数据集:

然后将这些任务转化为相应的模板,例如下面NLI的任务,原文就给出10个模板。

最后结果如下,需要注意的是,在做各个任务evaluation的时候,训练过程是不带evaluation任务的数据的,只是训练模型看各种模板。

文章Chain-of-Thought Prompting Elicits Reasoning in Large Language Models提供了另外一种让模型学会看懂不同Prompt的思路。
模型在逻辑推理方面效果不好,例如下面例子中虽然给出了例子,但是模型回答应用题就不对:

具体改进就是在Prompt中加入亿点点解题思路和推论过程:

最后模型在应用题上的结果还不错:

当然这个好麻烦,我都会解题步骤还需要模型干嘛,然后就出现了下面的Prompt,结果居然起飞。

然后进一步的在Self-Consistency Improves Chain of Thought Reasoning in Language Models里面借鉴了少数服从多数的理念,对CoT进行了改进:
由于模型在生成答案是有随机性的,因此考虑如果模型生成的答案中通过不同的计算方式得到相同的答案,那么这个答案大概率就是正确答案。

CoT的另外一个做法在文章Least-to-Most Prompting Enables Complex Reasoning in Large Language Models中提到,就是Least-to-Most Prompting。思想就是将复杂的数学问题进行分解(Problem Reduction)

这里的数学问题是小女孩要玩滑梯,爬上去要4分钟,滑下来要1分钟,如果还有15游乐园关门,小女孩能玩几次?
这里的第一次分解是依靠模型完成的,得到结果是先要求小女孩玩一次滑梯要多少时间?然后将分解的问题在丢进模型得到结果是5分钟,然后在将中间过程和最后的问题放入模型得到答案:3次。
In-context Learning
根据范例来回答问题

例如要做SA任务,先要给一些例子

然后模型可以完成相关任务,这个过程不涉及到GD:

由于不涉及到GD,模型是没有对所给的范例进行学习的,例如论文:Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?中做了相关实验,故意给出标注错误/随机的范例,发现模型性能并未下降很多,说明模型并未受到范例的影响。
下图蓝色是未给范例的结果,橙色正确范例的结果,而最后深橙色是随机范例结果:

文章还做了另外一个实验,用随机sample来的语料进行情感分析

下图中紫色部分就是给错误语料示范的结果,发现性能下降比较厉害,也就意味在跨Domain上进行Evaluation效果较差。

最后文章分析:模型本来就知道如何做情感分析,只不过需要范例来提示它,指出需要做情感任务。范例的样本数量多少其实并不太重要。文中也给出了相应的实验结果,横轴为范例个数:

也有部分论文提出其他观点:模型可以从范例中学习到相关知识,具体没有展开。
当下谷歌最新文章Larger language models do in-context learning differently做了以下实验,颜色越深模型越大,横轴表示模型吃进去的标签错误百分比。图中显示模型越大越容易受到标签的影响。

附录中还给出了一个离谱的用大模型做线性分类的实验,实验数据如下:
Input: 648, 626, 543, 103, 865, 910, 239, 665, 132, 40, 348, 479, 640, 913, 885, 456
Output: Bar
Input: 720, 813, 995, 103, 24, 94, 85, 349, 48, 113, 482, 208, 940, 644, 859, 494
Output: Foo
Input: 981, 847, 924, 687, 925, 244, 89, 861, 341, 986, 689, 936, 576, 377, 982, 258
Output: Bar
Input: 191, 85, 928, 807, 348, 738, 482, 564, 532, 550, 37, 380, 149, 138, 425, 155
Output: Foo
Input: 284, 361, 948, 307, 196, 979, 212, 981, 903, 193, 151, 154, 368, 527, 677, 32
Output: Bar
Input: 240, 910, 355, 37, 102, 623, 818, 476, 234, 538, 733, 713, 186, 1, 481, 504
Output: Foo
Input: 917, 948, 483, 44, 1, 72, 354, 962, 972, 693, 381, 511, 199, 980, 723, 412
Output: Bar
Input: 729, 960, 127, 474, 392, 384, 689, 266, 91, 420, 315, 958, 949, 643, 707, 407
Output: Bar
Input: 441, 987, 604, 248, 392, 164, 230, 791, 803, 978, 63, 700, 294, 576, 914, 393
Output: Bar
…
期待模型根据:
Input: 101, 969, 495, 149, 394, 964, 428, 946, 542, 814, 240, 467, 435, 987, 297, 466
Output:
得到:
Answer:
Bar
结果如下,横轴是给出的输入的维度:

上面的模型都是只学习文字接龙,就来做其他任务,文章MetaICL: Learning to Learn In Context中提出让模型学习如何进行In-context Learning,就是要更好的驯化模型以达到更好的结果。

自动Prompt
现在大多数都是人直接下指令,属于:

如果不给指令:

这种其实与专才中的Adapter流派类似。
还有使用RL的方法来找Prompt:Learning to Generate Prompts for Dialogue Generation through Reinforcement Learning

还有使用LM自己找出Prompt:Large Language Models Are Human-Level Prompt Engineers
先来一个模板:

然后为这个模板提供类似以下数据:

希望模型能够给出情感分类的Prompt。
具体流程如下图:

1.先是给模板然后模型根据模板生成若干个Prompt;
2.将Prompt结果分别丢进模型进行生成;
3.对生成对结果排序;
4.选出较好的结果;
5.让模型再次生成与这些结果相近的Prompt。
最后两步效果提升不明显,到第3步就好了。
划重点:注意看第一句最强催眠Prompt
