sknearl-7处理文本数据
本章代码大部分没跑,只供学习
第四节特征工程里提到,有连续特征和离散特征,对于文本数据,文本特征可以看作第三种特征
1 用字符串表示的数据类型
2 例子 电影评论情感分析
给定一个影评(输入),输出影评是正面还是负面
sklearn无法处理文本数据,需要将文本数据转换为数值表示,然后再用机器学习算法处理
3 将文本数据表示为词袋
词袋 即统计每个单词出现的频率
词袋构造步骤
1 划分原始字符串:将原始字符串用空格或标点负号分隔,获取单词拼写
2 构建词表,可进行编号
3 统计单词频率

3.1 词袋应用于玩具数据集
通过sklearn.feature_extraction.text.CountVectorizer构造词袋。构造完了可访问.vocabulary_访问词表,然后调用transform获取词袋,看下词表和词袋
def test_workds_bag(self):
bards_words = ['the fool doth think he is wise,', 'but the wise man knows himself to be a fool']
vect = CountVectorizer().fit(bards_words)
print(f'vocabulary type: {type(vect.vocabulary_)}, vocabulary: {vect.vocabulary_}')
bag_words_trans = vect.transform(bards_words)
print(f'words bag transform type:{type(bag_words_trans)},\n'
f'words bag transfrom shape:{bag_words_trans.shape},\n'
f'words bag transform repr: {repr(bag_words_trans)}\n'
f'words bag transform:\n {bag_words_trans.toarray()}')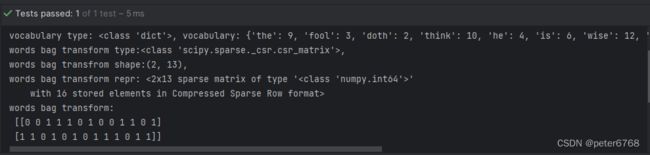
注意,vocabulary只是单词排序,字典的值不是单词出现次数,只是在句子里的下标,注意区分词表和词袋的概念。
词袋用稀疏矩阵表示(sparse matrix)
CountVectorier默认使用的正则是"\b\w\w+\b",含义是提起至少两个字符以上的字母数字且被单词边界分开。所以不会提取长度为1的作为单词,所以上述句子提取的词袋也没提取到a
3.2 词袋应用于电影数据集
先构造词袋,然后用LogisticRegression交叉验证,然后网格搜索最优的C
def test_movies_bag(self):
movie_train, movie_test = load_files('train_path'), load_files('test_path')
text_tr, ytr, text_te, yte = movie_train.data, movie_train.target, movie_test.data, movie_test.target
text_tr, test_te = [doc.replace(b"
", b"") for doc in text_tr], [doc.replace(b"
", b"") for doc in text_te]
vect = CountVectorizer().fit(text_tr)
xtr = vect.transform(text_tr)
print(f'vect transform features :{vect.get_feature_names()}') # shape: (25000, n) feature num is n, sort by alphabet
# cross validation
print(f'mean logistic regression cross score: {cross_val_score(LogisticRegression(), xtr, ytr, cv=5)}')
# grid search
params_grid = {'C': [0.001, 0.01, 0.1, 1, 10]}
grid = GridSearchCV(LogisticRegression(), params_grid, cv=5).fit(xtr, ytr)
print(f'grid best score: {grid.best_score_:.3f}')
print(f'grid best params: {grid.best_params_}') # C:0.1
print(f'grid test score: {grid.score(text_te, yte)}')词袋数据存在稀疏矩阵,对于高维稀疏矩阵,线性模型的LogisticRegression性能最好,约为88%
其实仅靠词袋还有很多问题,动词有进行时,过去时,单三等形式,还可能有很多写错的字符,这些需要考虑影响程度。可考虑在词袋基础做单词改进(不识别大小写,即大小写不同的单词会被识别为同一单词)
考虑CountVectorizer提取单词原理,使用"\b\w\w+\b",对于doesn't,bilibili.txt这类单词,会拆开识别
方案1 仅考虑在两个以上的文档中出现的相同单词
通过CountVectorizer的min_df参数实现(仅出现一次的单词可能没什么用,先这么试试)
def get_movie_data_test(self):
movie_train, movie_test = load_files('train_path'), load_files('test_path')
text_tr, ytr, text_te, yte = movie_train.data, movie_train.target, movie_test.data, movie_test.target
text_tr, test_te = [doc.replace(b"
", b"") for doc in text_tr], [doc.replace(b"
", b"") for doc in
text_te]
return text_tr, test_te, ytr, yte
def test_movies_bag_5_appear(self):
xtr, xte, ytr, yte = self.get_movie_data_test()
vect = CountVectorizer(min_df=5).fit(xtr)
xtr_trans = vect.transform(xtr)
grid = GridSearchCV(LogisticRegression(), {'C': [0.001, 0.01, 0.1, 1, 10]}, cv=5).fit(xtr, ytr)
print(f'logistic regression best score: {grid.score(xte, yte)}')结论 精度大概为89%,发现处理单词出现频率后,精度没明显的提升,但减少了约三分之二的特征,可提升处理速度
4 停用词
删除没有意义的词语还有一种方法:删除出现频率过高的词语。有两种方法:1使用特定的语言停用词词表(sklearn.feature_extraction.text.ENGLISH_STOP_WORDS提供了停用词词表) 2指定特定频率,舍弃频率在该频率以上的词语。比如说above, into, well, anyone等词
可以从数据集里删除停用词。虽然减少不了多少特征,但可能会提升性能,因为停用词出现频率可能高一些
5 tf-idf放缩数据
tf-idf概念 也叫词频-逆向文档频率(term frequency - inverse document frequency, tf-idf)。给词语赋予权重,对于语料库中经常出现的词语,不会赋予很高权重;在某个文档出现频率次数较高的词被识别为术语,赋予较高的权重。最后通过一个量化指标 tf-idf分数来反映单词权重。sklearn里有两个类实现了tf-idf:TfidfTransformer和TfidfVectorizer,前者接受稀疏矩阵并转换,后者接受文本数据完成词袋特征提取和tfidf变换,计算公式如下

N是文档总数量,Nw是出现某个单词的文档数量,tf是单词在查询文档中出现的次数
可以看下tfidf得分最高和最低的单词
tfidf得分较小时,说明单词要么出现频率很低,要么就是在很多文档里都有使用
tfidf得分较大时,说明词汇较高频率出现在某些文档中。但这类词语有的对影评情感分类并没有显著的作用,比如电影标题
看下idf得分最低的单词(出现频率最高,只按频率排序,idf和tfidf不一样)
这些单词主要是停用词
def test_tfidf_show_features(self):
xtr, xte, ytr, yte = self.get_movie_data_test()
pipe = make_pipeline(TfidfVectorizer(min_df=5), LogisticRegression())
grid = GridSearchCV(pipe, {'logisticregression__C': [0.001, 0.01, 0.1, 1, 10]}, cv=5).fit(xtr, ytr)
print(f'best cross score: {grid.best_score_}')
# show tfidf words
vectorizer = grid.best_estimator_.named_steps["tfidfvectorizer"]
xtr_trans = vectorizer.transform(xtr)
max_val = xtr_trans.max(axis=0).toarray().ravel()
sorted_by_tfidf = max_val.argsort()
feature_name = np.array(vectorizer.get_feature_names())
# show tf-idf score
print(f'tfidf score lowest 20 ea: {feature_name[:20]}')
print(f'tfidf score highest 20 ea: {feature_name[-20:]}')
# show idf score
print(f' idf score lowest 20 ea: {vectorizer.idf_[:20]}')6 研究模型系数
看下训练的logistic模型系数的最大最小值
mglearn.tools.visualize_coefficients(grid.best_estimator_.named_steps["logisticregression"].coef_,
feature_names=feature_names, n_top_features=40)
看x轴发现最小得分的单词大多是负面情绪的单词,比如worst,waste等,得分高的单词大部分也是正面单词:great, excellent等
7 多个单词词袋
词袋缺点 舍弃了单词顺序
词袋解决方案 有一种词袋考虑上下文中单词的计数,即某个单词相邻某几个单词的计数
二元分词 两个词例,以此类推三元等,词例范围可通过vector类的ngram_range参数传入来指定词例个数。ngram_range是一个元组,包括了词例的最小长度和最大长度。CountVectorizer默认是(1,1)的ngram_range
def test_word_bag_ngram(self):
bards_words = ['the fool doth think he is wise,', 'but the wise man knows himself to be a fool']
vector = CountVectorizer(ngram_range=(1, 1)).fit(bards_words)
print(f'length of feature: {len(vector.vocabulary_)},\nvector feature names: {vector.get_feature_names_out()}')
仅查看二元分词
def test_word_bag_ngram(self):
bards_words = ['the fool doth think he is wise,', 'but the wise man knows himself to be a fool']
vector = CountVectorizer(ngram_range=(1, 1)).fit(bards_words)
print(f'length of feature: {len(vector.vocabulary_)},\nvector feature names: {vector.get_feature_names_out()}')
# show 2 dimension words
vector = CountVectorizer(ngram_range=(2, 2)).fit(bards_words)
print(f'feature len: {len(vector.vocabulary_)},\n2 di vector feature names: {vector.get_feature_names_out()}')
优缺点 多元分词可能导致过拟合,也会增加计算量,n元分词计算量是一元分词的n倍
可以同时使用一元,二元,三元分词
vector = CountVectorizer(ngram_range=(1, 3)).fit(bards_words)
print(f'feature len: {len(vector.vocabulary_)},\n vector feature names: {vector.get_feature_names_out()}')
7.1 对影评数据应用3元词袋
对影评数据应用1-3元词袋,然后网格搜索出最佳参数,然后热图可视化(没跑,用的教材的图)
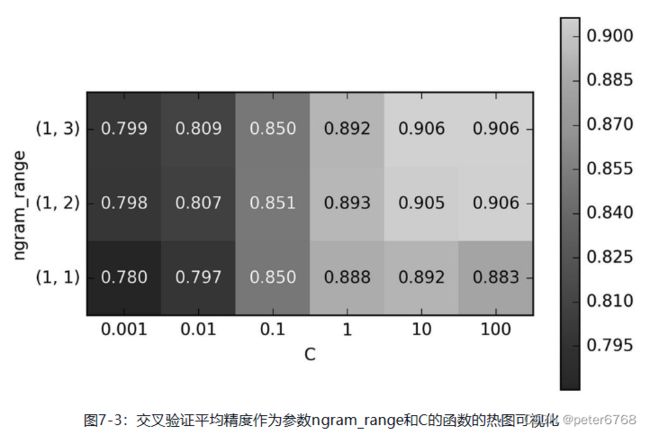
二元的精度提升了约一个百分点,发现一元到二元精度提升很多,二元到三元没提升多少,表明三元可能没太大作用,
看下特征系数,绘制bar图
发现三元特征的特征系数普遍较低,也验证了三元分词没起太多作用
8 高级分词、词干提取、词形还原
目的 很多单词有不同分词形式,将分词形式作为单独特征可能会导致过拟合,将词干提取或合并可减少次问题导致的误差
词干提取(stemming) 删除单词不同分词形式的通用分词后缀,然后合并词干
词形还原(lemmatization) 将单词不同分词形式按照已有分词字典进行合并还原
标准化 词干提取和词形还原都叫标准化,即将一个单词还原成标准形式
先看下词干提取
def test_word_stem(self):
en_nlp = spacy.load('en_core_web_sm')
stemmer = nltk.stem.PorterStemmer()
def compare_normalization(doc):
doc_spacy = en_nlp(doc)
print(f'show word split result: {[token.lemma_ for token in doc_spacy]}')
print(f'show word stem found result: {[stemmer.stem(token.norm_.lower()) for token in doc_spacy]}')
test_text = "our meeting today was worse than yesterday, I'm scared of meeting the clients tomorrow"
compare_normalization(test_text)
was词干提取后变成wa,因为词干提取原理是删分词后缀
worse变成wors,meeting变成meet
sklearn里没支持词干提取和词形还原,单CountVectorizer可以使用tokenizer指定分词器将文档转换为词例列表
看下词形还原
def test_lemmatization(self):
regexp = re.compile('(?u)\\b\\w\\w+\\b')
en_nlp = spacy.load('en_core_web_sm')
old_tokenizer = en_nlp.tokenizer
en_nlp.tokenizer = lambda string: old_tokenizer.tokens_from_list(regexp.findall(string))
def custom_tokenizer(doc):
doc_spacy = en_nlp(doc, entity=False, parse=False)
return [token.lemma_ for token in doc_spacy]
lemma_vect = CountVectorizer(tokenizer=custom_tokenizer, min_df=5)
xtr, xte, ytr, yte = self.get_movie_data_test()
xtr_lemma = lemma_vect.fit_transform(xtr)
print(f'words lemmatization shape: {xtr_lemma.shape}')词形还原可以合并特征,可以看作正则化,因为选的特征变少了。数据集比较小时,词形还原可以有较大的性能提升。
9 主题建模与文档归类
另一种常用的文本建模方法是主题建模,比如每个新闻都涉及一些主题,比如财经,体育,科技等。给一个新闻预测是哪个主题,是主题建模要考虑的问题。一般主题建模指隐含狄利克雷分布(Latent Dirichlet Allocation,LDA)的分解方法
机器学习学习到的主题,和我们日常提到的主题可能不太一样。机器学习可能按词频学到词频较高的词语作为主题,类似于PCA的主成分,没有什么让人直观理解的含义,只是个计算量。
预处理 应用LDA前应删掉常见的频率很高的非主题词,可以在CountVctorizer构造传入参数min_df=.3,表示删除至少在30%文档出现的词语
任务 现在设置学习目标是10个主题。主题类似于NMF中的分量,没有内在的顺序,但改变主题数量会改变所有主题(其实LDA和NMF有一定相似性,也可试着用NMF提取主题)。此处用batch学习方法,比online方法稍慢,但结果可能会更好,然后增大max_iter,可以得到更好的模型
9.1 模型1
def test_topic_modeling(self):
vect = CountVectorizer(max_features=10000, max_df=.15)
x = vect.fit_transform('test train')
lda = LatentDirichletAllocation(n_topics=10, learning_method='batch', max_iter=25, random_state=0)
topics = lda.fit_transform(x)
print(f'lda component shape: {lda.components_.shape}') # (10, 10000)查看每个主题最重要的词语

从词汇重要程度看,topic1可能和战争有关,主题2可能和喜剧有关,主题3可能和电视连续剧有关
9.2 模型2
lda100 = LatentDirichletAllocation(n_topics=100, learning_method='batch', max_iter=25, random_state=0)
topics_100 = lda100.fit_transform(x)
# randomly select several topics
topics_sample = np.array([11, 21, 31, 41, 51])
sorting_100 = np.argsort(lda100.components_, axis=1)[:, ::-1]
feature_names_100 = np.array(vect.get_feature_names_out())
mglearn.tools.print_topics(topics=topics_sample, feature_names=feature_names_100,
sorting=sorting_100, topic_per_chunk=7, n_words=20)9.3 汇总每个文档主题重要性
还有一种量化指标是将所有文档的主题重要性汇总,然后按会总量从大到小可视化,或者按topic可视化
9.4 优缺点
主题建模是无监督学习,最好有已知标签进行进一步验证。学习结果和random_state挂钩
10 小结
讨论了CountVectorizer和TfidfVectorizer,是相对简单的方法,其他高级的方法可使用py的包spacy(相对较新,较高效,设计良好),nltk(很完整的库,有些过时),gensim(着重于主题建模的nlp包)
研究方向
1 使用连续向量表示。
2 递归神经网络(RNN)。很适合自动翻译和摘要,