爬虫练习-爬取豆瓣音乐TOP250的数据
前言:
爬取豆瓣音乐TOP250的数据,并将爬取的数据存储于MongoDB中
本文为整理代码,梳理思路,验证代码有效性——2020.1.1
环境:
Python3(Anaconda3)
PyCharm
Chrome浏览器
主要模块:
requests
lxml
re
pymongo
time
1.
分析网页
https://music.douban.com/top250
https://music.douban.com/top250?start=25
https://music.douban.com/top250?start=50
...
https://music.douban.com/top250?start=225
虽然第一页的网址url有点标新立异,但是经验告诉我们,它可以通过https://music.douban.com/top250?start=0来访问
我们来构造url列表解析式
urls = ['https://music.douban.com/top250? start={}'.format(str(i)) for i in range(0, 250, 25)]
2.
其后,我们再定义一个详情页的url的函数
# 定义获取豆瓣音乐的详细URL的函数
def get_url_music(url):
html = requests.get(url, headers=headers, timeout=30)
selector = etree.HTML(html.text)
music_hrefs = selector.xpath('//a[@class="nbg"]/@href')
for music_href in music_hrefs:
get_music_info(music_href)
3.
分析信息的html结构
打开开发者工具 F12
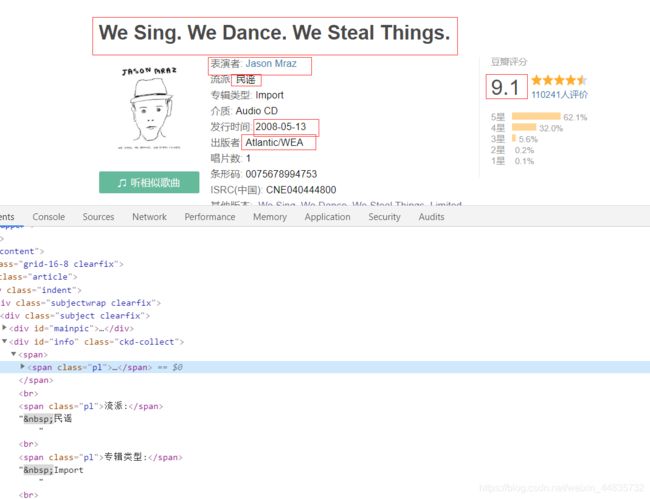
具体的html结构分析,当然,在分析测试过程中,出了一些出人意料的事情,在下一点中稍微提及一下。
html = requests.get(url, headers=headers, timeout=30)
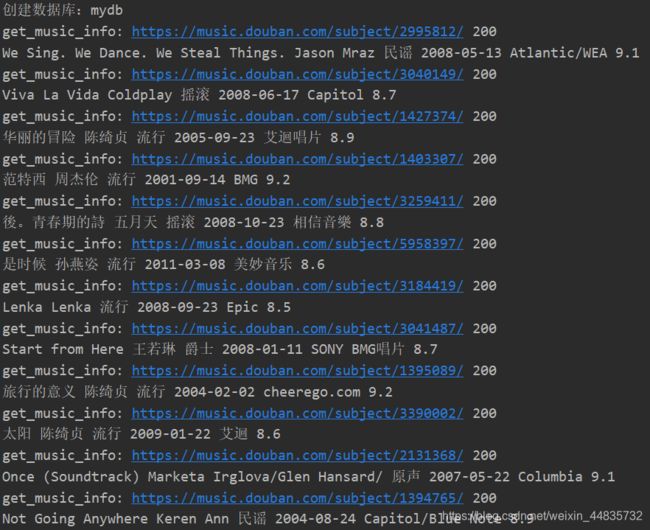
print("get_music_info:", url, html.status_code)
selector = etree.HTML(html.text)
name = selector.xpath('//*[@id="wrapper"]/h1/span/text()')[0]
author = selector.xpath('//*[@id="info"]/span[2]/span/a/text()')
if author == []:
author = selector.xpath('//*[@id="info"]/span[1]/span/a/text()')
flag_author = ""
if len(author) > 1:
for i in range(len(author)):
flag_author = str(author[i])+ '/' + flag_author
author = flag_author
else:
author = author[0]
styles = re.findall('流派: (.*?), html.text, re.S)
if len(styles) == 0:
style = '未知'
else:
style = styles[0].strip()
book_times = re.findall('发行时间: (.*?), html.text, re.S)
if len(book_times) == 0:
book_time = '未知'
else:
book_time = book_times[0].strip()
publishers = re.findall('出版者: (.*?), html.text, re.S)
if len(publishers) == 0:
publisher = '未知'
else:
publisher = publishers[0].strip() # 前几个用正则表达式提取
score = selector.xpath('//*[@id="interest_sectl"]/div/div[2]/strong/text()')[0]
4.
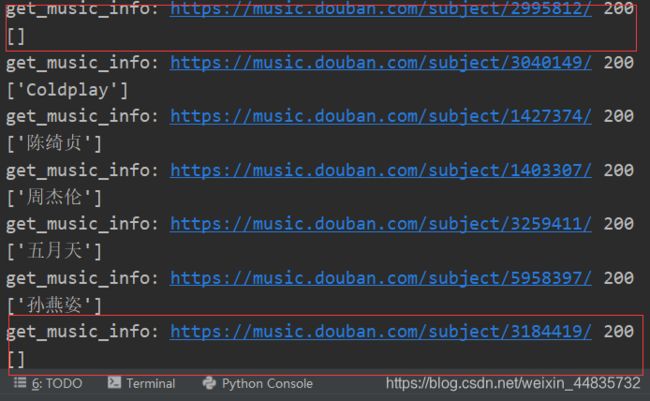
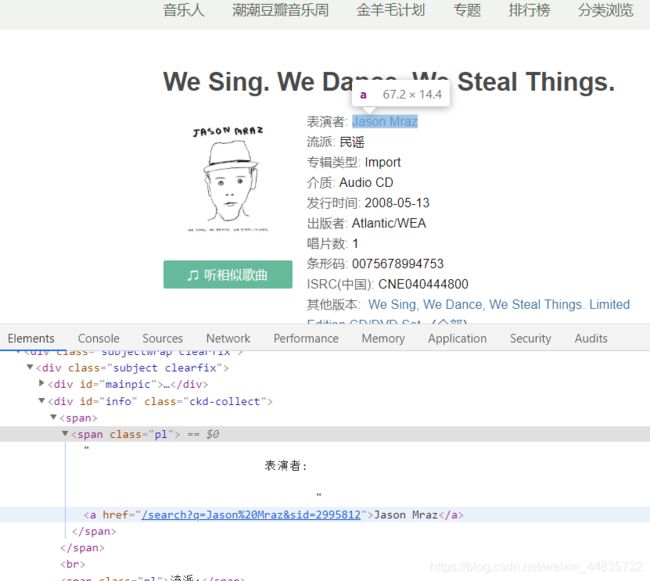
测试解析“表演者”时出现部分返回值为空的现象,我们去网页具体分析一下,由以下两图可知,因为有些歌曲有别名,而一些没有,所以我们在返回为空时,加入 if 语句解析另一种情况;而且由下面第二张图可知,有的”表演者“有两个或者可能更多个,我们这里针对这种要进行遍历拼接字符串
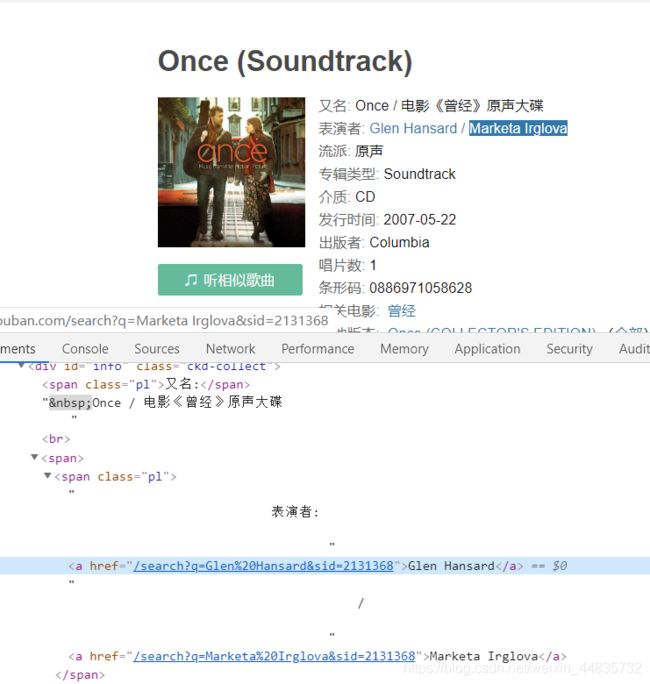
5.
有了相应的数据,我们就可以将数据放到数据库中了,我这略微提一下MongoDB的使用
注:出现pymongo.errors.ServerSelectionTimeoutError: localhost:27017: [WinError 10061] 由于目标计算机积极拒绝,无法连接。 问题的 解决方案
首先安装pymongo
# cmd窗口下运行安装
pip install pymongo
# 我这用Anaconda,所以是
conda install pymongo
及导入pymongo库
import pymongo
使用 MongoClient 对象,指定相应的url地址
# 使用 MongoClient 对象,指定相应的url地址
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
创建一个名为mydb的数据库
dblist = myclient.list_database_names()
# 判断是否存在数据库 mydb
if "mydb" not in dblist:
# 创建一个名为mydb的数据库
print("创建数据库:mydb")
mydb = myclient["mydb"]
创建数据集合
# 创建数据集合
musictop = mydb['musictop']
插入数据
info = {'name': name, 'author': author, 'style': style, 'book_time': book_time, 'publisher': publisher, 'score': score}
# 插入数据
musictop.insert_one(info)
最后
祝大家元旦快乐! 心想事成,大家在新的一年里会更加美好。
完整代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# 导入相应的库文件
import requests
from lxml import etree
import re
import pymongo
import time
# 使用 MongoClient 对象,指定相应的url地址
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
dblist = myclient.list_database_names()
# 判断是否存在数据库 mydb
if "mydb" not in dblist:
# 创建一个名为mydb的数据库
print("创建数据库:mydb")
mydb = myclient["mydb"]
# 创建数据集合
musictop = mydb['musictop']
# 加入请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36'
'(KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
}
# 调用歌曲详细信息的函数
# 定义获取豆瓣音乐的详细URL的函数
def get_url_music(url):
html = requests.get(url, headers=headers, timeout=30)
selector = etree.HTML(html.text)
music_hrefs = selector.xpath('//a[@class="nbg"]/@href')
for music_href in music_hrefs:
get_music_info(music_href)
# 定义获取详细信息的函数
def get_music_info(url):
html = requests.get(url, headers=headers, timeout=30)
print("get_music_info:", url, html.status_code)
selector = etree.HTML(html.text)
name = selector.xpath('//*[@id="wrapper"]/h1/span/text()')[0]
author = selector.xpath('//*[@id="info"]/span[2]/span/a/text()')
if author == []:
author = selector.xpath('//*[@id="info"]/span[1]/span/a/text()')
flag_author = ""
if len(author) > 1:
for i in range(len(author)):
flag_author = str(author[i])+ '/' + flag_author
author = flag_author
else:
author = author[0]
styles = re.findall('流派: (.*?), html.text, re.S)
if len(styles) == 0:
style = '未知'
else:
style = styles[0].strip()
book_times = re.findall('发行时间: (.*?), html.text, re.S)
if len(book_times) == 0:
book_time = '未知'
else:
book_time = book_times[0].strip()
publishers = re.findall('出版者: (.*?), html.text, re.S)
if len(publishers) == 0:
publisher = '未知'
else:
publisher = publishers[0].strip() # 前几个用正则表达式提取
score = selector.xpath('//*[@id="interest_sectl"]/div/div[2]/strong/text()')[0]
print(name, author, style, book_time, publisher, score)
info = {'name': name, 'author': author, 'style': style, 'book_time': book_time, 'publisher': publisher, 'score': score}
# 插入数据
musictop.insert_one(info)
# 程序主入口
if __name__ == '__main__':
urls = ['https://music.douban.com/top250? start={}'.format(str(i)) for i in range(0, 250, 25)]
for url in urls:
# 构造urls并循环调用函数
get_url_music(url)
# 睡眠2秒
time.sleep(2)
print("爬取结束!")
数据截图