GAN 公式推导
目录
零、前言
一、完美生成器的数学模型
二、转化为最优化问题
三、详细的公式证明
四、寻找最好的鉴别器
五、查找最好的生成器
六、收敛
七、总结
零、前言
笔者在学习GAN的过程中,查阅了许许多多资料,最终发现台湾大学李宏毅教授的GAN教程讲的极好(PPT非常干净、讲解的很清楚),除此之外网易慕课上的一个Pytorch教程里的GAN部分讲的也是不错,近期还看了B站上李沐大佬的论文精度系列(大佬一段段拆开读,甚好),都有将原理和推导。但最后发现GAN的学习路程上还是有个拦路虎,就是损失函数公式的推导,这是GAN论文的精华所在,同时也是为了记录下自己学习的情况,所以本文参考网络资料与原文进行一个GAN公式的推导计算。推导公式时,本文大量参考了国外的一个大牛博士的笔记。
以下因为一些原因给的都是Bilibili的链接(之间点击或者搜索)
生成对抗神经网络课程 (GAN) - 李宏毅_哔哩哔哩_bilibili 李宏毅教授的GAN视频
PyTorch深度学习快速入门教程_哔哩哔哩_bilibili 慕课上的一个Pytorch视频(里面有GAN)
GAN论文逐段精读【论文精读】_哔哩哔哩_bilibili 李沐大佬的GAN论文精读
14年GAN的原文PDF(可能要科学网)GAN原文pdf里面有比较详细的推导(结合李沐视频使用)
详细的GAN公式推导这个是公式推导作者Scott Rome 博士,笔者基本上就是参考大佬 ^_^
一、完美生成器的数学模型
GAN由一个生成网络与一个判别网络组成,我们需要通过严谨的数学证明。GAN的目的就是做生成,那么我们就要使生成的东西与真实的图片难以区分。换一句话说就是生成的随机变量在分布上与真实分布是相等的:![]() ,如果最终生成器
,如果最终生成器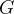 生成的数据满足该关系,GAN就可以说完成训练啦!
生成的数据满足该关系,GAN就可以说完成训练啦!
二、转化为最优化问题
在GAN的文章中,需要鉴别器D来识别来自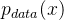 的分布,具体的公式为:
的分布,具体的公式为:
![]()
其中E表示期望。这一项来自于损失函数的正部分(损失函数有D和G两部分)。当![]() 使这一项最大化即D(x) = 1 就能够精准的判别图像的真假。另一项来自于损失函数的负部分,生成器G的损失函数公式为:
使这一项最大化即D(x) = 1 就能够精准的判别图像的真假。另一项来自于损失函数的负部分,生成器G的损失函数公式为:
![]()
如果该公式数值是最大值 = 0(logx 在x<1的时候是负数)表示D(G(z)) = 0,G没有骗到D。
不妨将这两个公式结合起来,我们发现判别器D的目标是要Maximize最大化结合后的函数,当然这个函数最大值其实也就是0。(这里的G最终目的是让D能跟好辨别数据?)
![]()
这意味着判别器D能正确的识别真假数据分布。对于给定的G,上述方程意义下的最佳鉴别器将记为![]() 。可以定义该函数的值
。可以定义该函数的值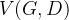
![]()
此时,我们可以记最佳辨别器![]() , (V值最大,其实在这里就是D最好)。当
, (V值最大,其实在这里就是D最好)。当![]() 时,G的目标是相反的,最优的G使前一个方程最小化。在GAN论文中,作者们倾向于写出最优的G与D来求解值函数的极大极小数值的博弈解
时,G的目标是相反的,最优的G使前一个方程最小化。在GAN论文中,作者们倾向于写出最优的G与D来求解值函数的极大极小数值的博弈解
![]()
这时,我们可以写出最优解为:![]()
(最后说个简单的人话哈,就是我搞最好的D,目的要让V最大。我搞最好的G,目的是要让V最小。那么问题就来了,最大最小就会存在一个博弈解,其实就是训练时要达到纳什均衡!)
三、详细的公式证明
在这个部分,我们要给出一个有力的证明来表述这个优化问题有一个唯一的最优解![]() 并且该解必须满足分布
并且该解必须满足分布 ![]() 。
。
GAN论文中的一个重要观点与其他方法不同的是G不一定是可逆的(这个相当重要)因为实际上GAN是不可逆的。所以在使用微积分的变量变换公式时就得仔细斟酌。整个证明依赖于这个等式:
![]()
(其来自于Radon-Nikodym定理,有时被称之为unconscious statiscian法则)
接下来这个式子在GAN原文的命题1的证明中:
![]()
![]()
这一步的计算是不能直接用变量变换公式来做的,因为在改变变量时必须计算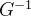 但其实它是不存在的(在神经网络中,实际上是并不存在的)
但其实它是不存在的(在神经网络中,实际上是并不存在的)
四、寻找最好的鉴别器
受益于最后一个等式,我们可以通过G写出最优化的D。对于上述的式子我们发现他是一个结构比较简单的例子,可以用微积分的知识就能找到被积函数的最大值(求导,找导数为0的点)。然后选择它作为D。不妨将被积函数设为:
![]()
接下来我们寻找他的极点:
1.对f(x)函数先求一次导得出导数为零的极值点 y(a+b是不等于零的)
![]()
2.为了判断![]() 是不是f(x)的极大值,需要求二次导判断
是不是f(x)的极大值,需要求二次导判断
![]()
(一阶导数是自变量的变化率,二阶导数是一阶导数的变化率,即一阶导数变化率的变化率。连续函数的一阶导数就是相应的切线斜率。一阶导数 > 0,则递增;一阶倒数 < 0,则递减;一阶导数等于0,则不增不减。二阶导数可以反映图象的凹凸。二阶导数 > 0,图象为凹;二阶导数 < 0,图象为凸;二阶导数等于0,不凹不凸。凹f``(x)在该点为极大,凸f``(x)在该点为极小 )
所以,当![]() 时,
时,![]() 是最大值,此时最好的判别器
是最大值,此时最好的判别器![]() 就出现了,没有比它更好的D了。由此,我们可以推导出命题1函数的边界范围:
就出现了,没有比它更好的D了。由此,我们可以推导出命题1函数的边界范围:
![]()
![]()
但其实D(x)是不能够直接进行计算的。我们一开始是不知道,所以我们永远不能再训练期间直接使用它。另一方面来说,D(x)的存在表明了我们能够证明存在一个最优的G(x),在训练的过程中我们只需要逼近这个D(x)。
五、查找最好的生成器
在证明能够找到最优的D(x)后,我们再回到最终目的上(生成图片),即生成器G 生成的图片可以以假乱真(![]() ),不妨将等式带入鉴别器公式中得出最优
),不妨将等式带入鉴别器公式中得出最优![]()
![]()
这就意味着,最优秀的鉴别器也无法辨别真假分布了,此时就证明了GAN存在MaxMin博弈解G
其理论如为:只有在数据分布为![]() 时,训练的最终目标
时,训练的最终目标 可以达到最大值。
可以达到最大值。
该定理目前当且仅当是命题,因此我们同时从两个方向进行证明。首先,我们向后逼近最佳值。然后我们用新发现的知识从后面的方向推进。假设![]() ,我们可以写成:
,我们可以写成:
![]()
![]()
该值是全局最小值的候选值,现在我们停止继续向后计算,我们要来证明一下这个值总是最小的(满足当与当且仅当部分)。所以抛开分布相等![]() 的假设,可以将最佳辨别器
的假设,可以将最佳辨别器![]() 代入
代入![]()
![]()
注释:右边部分的被积函数推导小技巧可如下所示:
![]()
![]()
由于我们知道-log4是全局最小值的候选项(代入算算就知道),把这个值塞进方程,再对积分同时加上与减去log2,乘上相应的概率密度p可以的到以下公式(本质上不会对式子进行改变,因为加减最后值为0)
![]()
![]()

![]()
注释1:并且由于概率密度的定义,分布p的积分值最终是为1的,所以在计算前半部分时将 和
和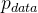 = 1.
= 1.
前半部分: ![]()
注释2:由于log函数的定义,可以将C(G)后半部分写为
此时我们将C(G)函数的前半部分与后半部分进行替换,可得:
直到这一步的可以发现C(G)的式子是可以用 Kullback-Leibler divergence KL散度表示,其实很特别,我们写下用KL散度表示的公式:
![]()
由于KL散度总是非负数的,所以我们可以推断除C(G)的全局最小值是-log4. 如果我们证明只有一个G满足这个条件,其实已经完成了证明,因为![]() 将是
将是![]() 的唯一点。要证明这部分,得注意到第二个证明:
的唯一点。要证明这部分,得注意到第二个证明:
![]()
JSD被称作是JS散度Jenson-Shannon divergence。该散度其实是Jenson-Shannon distance metric的平方,是Kullback-Leibler 散度的对称和平滑版本。
此时可以得出当![]() 时:
时:
![]()
所以说对鉴别器D的优化就是在求 ![]() 与
与 的JS散度
的JS散度![]() ,对
,对![]() 其实G的优化就是在缩小
其实G的优化就是在缩小 ![]() 与的JS散度。
与的JS散度。
六、收敛
总结来说就是 ![]() 在
在![]() 是最佳值。并且在给定足够多的训练数据和适当情况下,数据是会收敛到最佳的G。
是最佳值。并且在给定足够多的训练数据和适当情况下,数据是会收敛到最佳的G。
七、总结
后面有空再加