从零本地部署大模型(零基础友好版)
最近在做大模型,自己折腾了小半年,摸索出来了一些经验,写这篇blog的目的是为了让师弟师妹在模型部署的环节少走弯路,也能快速体验到LLM的智能,减少部署环节的痛苦
如果是进行只需要跑通模型当前流行的6b7b参数模型,至少要保证显卡10G显存并且cuda版本最好高于11.x,如果是需要训练可能需要更大的显存,16b参数以上的模型还是推荐上V100。
部署模型有四件事情要做:
1.确定本地硬件是否支持大模型部署。
2.确定模型需要的依赖。
3.下载好模型的权重和配置文件。
4.运行模型
以下就开始详细介绍模型部署的每一个问题和解决方案。
1.确定本地硬件是否支持需要部署的大模型。
如果需要部署大模型,首先要确定系统是Linux还是Windows
建议使用Linux系统,因为很多python包目前不支持Windows,其次要确定GPU显存和Nvidia版本是否支持,可以通过shell命令查看,目前AMD公司的显卡暂时不支持pytorch。
nvidia-smi以下是输出结果,可以查看到Nvidia版本号,CUDA版本号,以及显卡型号和显存大小。
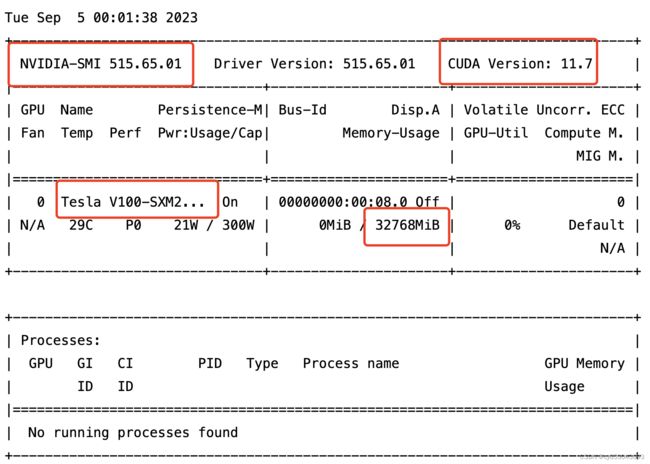
如果只是需要跑通模型,进行输入输出,至少需要10G和CUDA版本11.x以上的GPU,如果需要训练的话可能需要更大的GPU
如果安装了最新的Nvidia驱动请跳过第一步
1.安装Nvidia驱动:
Nvidia官网驱动下载页
选择自己的显卡型号,查看支持的nvdia驱动,最好选较高的CUDA-toolkit的版本例如11.7,这样可以免后续出现环境冲突。
方法一:利用wget命令使用官网链接下载:(推荐这一种)
点击搜索,然后跳转到下载页,右键下载并复制链接
输入命令:(需要复制为适合自己显卡型号的Nvidia驱动下载链接)
$ wget https://www.nvidia.cn/content/DriverDownloads/confirmation.php?url=/tesla/515.105.01/NVIDIA-Linux-x86_64-515.105.01.run&lang=cn&type=Tesla执行安装:
$ chmod +x NVIDIA-Linux-x86_64-515.105.01.run
$ ./NVIDIA-Linux-x86_64-515.105.01.run方法二:查看符合自己GPU的Nvidia驱动版本之后本地命令直接查询并下载
执行以下命令
$ sudo add-apt-repository ppa:graphics-drivers/ppa
$ sudo apt-get update
$ sudo apt-cache search nvidia-*
$ sudo apt-get install nvidia-版本号
执行 $ sudo apt-cache search nvidia-* 能查看到当前可以使用的所有版本
执行 $ sudo apt-get install nvidia-版本号 ,如: $ sudo apt-get install nvidia-384
执行上述命令即可安装;需要重启
$ sudo reboot安装Nvidia驱动大概率会出现以下报错:
ERROR: The Nouveau kernel driver is currently in use by your system. This driver is incompatible with the NVIDIA driver, and must be disabled before proceeding. Please consult the NVIDIA driver README and your Linux distribution's
documentation for details on how to correctly disable the Nouveau kernel driver.则需要禁用原有的Nouveau kernel driver:
$ echo "blacklist nouveau" >> /etc/modprobe.d/blacklist-nouveau.conf
$ update-initramfs -u
$ echo "options nouveau modeset=0" >> /etc/modprobe.d/nouveau-kms.conf然后重启:
$ sudo reboot然后输入Nvidia-smi查看是否存在Nvidia信息。
2.安装CUDA
输入以下命令查看CUDA版本信息,如果已经安装CUDA则会输出版本信息
$ nvcc -V如果已经安装CUDA11.x版本请跳过此步骤
在Nvidia-smi中的CUDA版本号会限制我们的CUDA版本,所以我们不能超过这个版本号
进入CUDA官网:CUDA官网
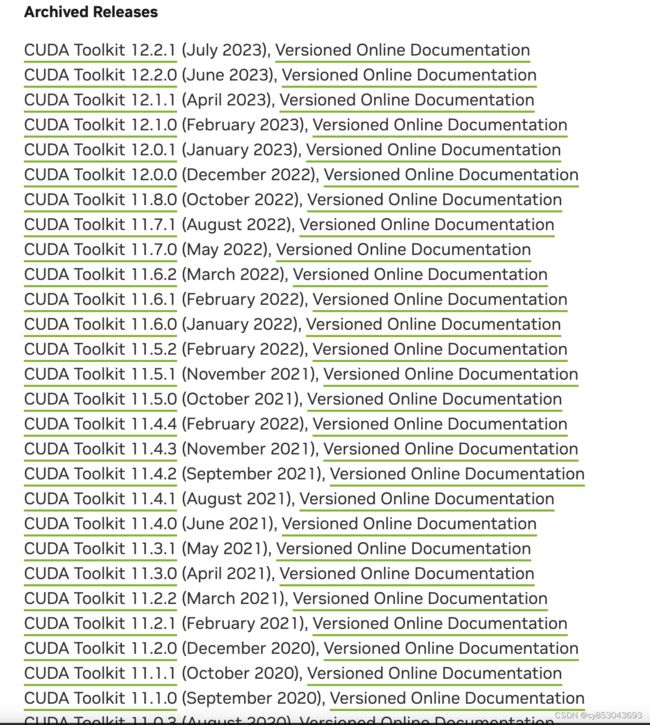 选择适合自己的CUDA版本号,并进入链接,以11.7.0版本为例,选择自己的环境信息,如果是Windows系统在OS中选择Windows
选择适合自己的CUDA版本号,并进入链接,以11.7.0版本为例,选择自己的环境信息,如果是Windows系统在OS中选择Windows
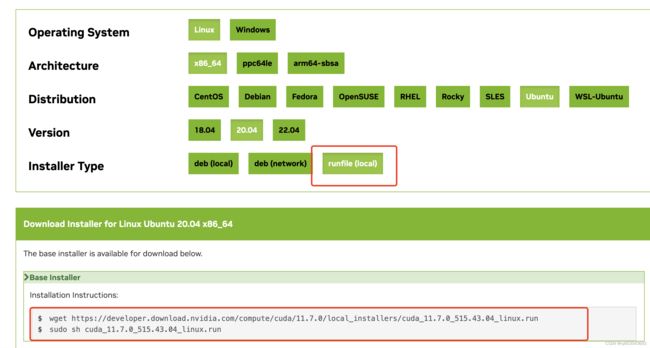
输入以下命令进行安装
$ sudo sh cuda_11.7.0_515.43.04_linux.run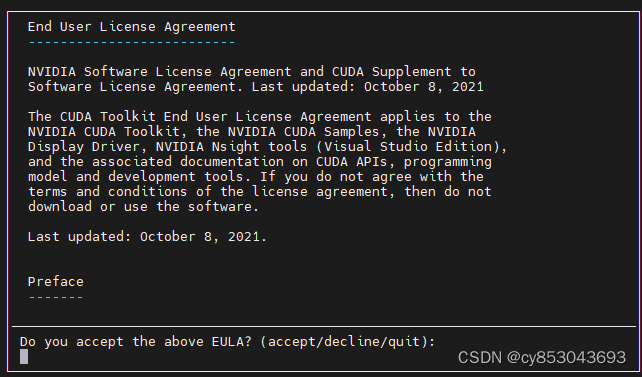
一直同意即可完成安装,如果Nvidia驱动没有安装会在此提示搭配的Nvidia驱动版本。
如果出现以下报错:
ubuntu@VM-0-16-ubuntu:~$ nvcc -V
Command 'nvcc' not found, but can be installed with:
sudo apt install nvidia-cuda-toolkit千万不要使用其推荐的命令,否则会安装不适配的nvidia-cuda-toolkit,需要进行环境变量配置:
sudo vim ~/.bashrc在文件结尾添加:
export PATH=/usr/local/cuda-11.7/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-11.7/lib64:$LD_LIBRARY_PATH如果不是安装的11.7则需要换成自己的版本号。如果不会用vim,按a键可以编辑,退出的时候按esc键然后按引号冒号:接推出命令,:wq为写入并退出vim,:q为不写入退出,:q!为不写入强制退出。
更新环境变量:
$ source ~/.bashrc查看CUDA信息:
$ nvcc -V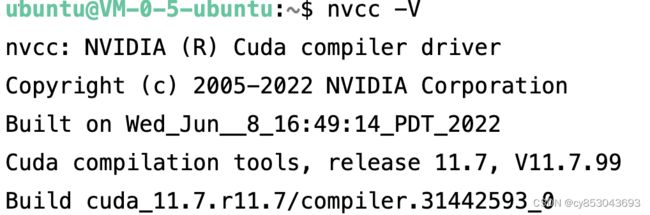
至此,我们已经把Nvidia驱动和CUDA驱动安装成功,可以开始对我们的模型环境进行配置了。
2.配置模型环境
这里每个模型需要的环境可能不尽相同,以下笔者用THUDM/CodeGeeX2作为例子
需要进入THUDM/CodeGeeX2的GitHub页面尽可能在部署模型之前完整阅读readme。
克隆项目到本地:
$ git clone https://github.com/THUDM/CodeGeeX2.git进入项目浏览目录:
$ cd CodeGeeX2打开项目中的requirement.txt文件:requirements.txt
我们可以发现他的环境需要如下包: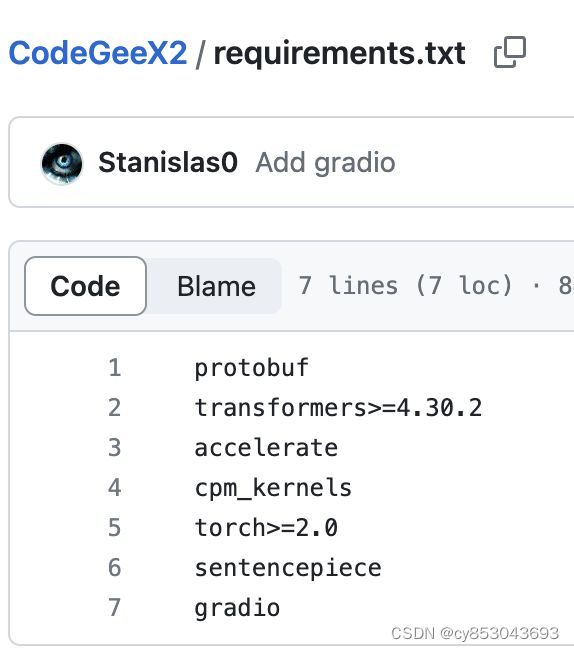
为了安装的环境可以干净且不受其他项目环境的影响我们应该安装conda并创建一个虚拟空间:
1.安装Anaconda3
进入anacondo官网Anaconda官网
选择适合自己系统的版本:
这里我以自己的版本为例:Anaconda3-5.3.0-Linux-x86_64.sh
在这个版本的蓝色字体处点击右键复制链接
在shell里面输入命令,以我的版本为例(不对的话应该换成自己下载的版本名)
$ wget https://repo.anaconda.com/archive/Anaconda3-5.3.0-Linux-x86_64.sh安装Anaconda3
可能会出现sh命令不能使用:执行以下命令
$ chmod +x Anaconda3-5.3.0-Linux-x86_64.sh执行以下命令
:
$ sh ./Anaconda3-5.3.0-Linux-x86_64.sh进入Anaconda安装页面: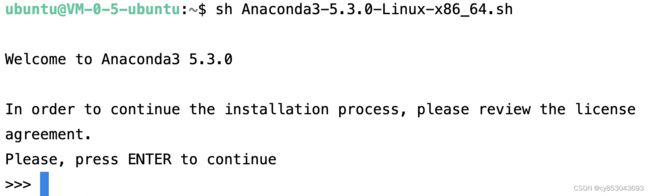
一路点击enter,会询问是否添加进入环境变量,这里输入yes,并按enter。

是否加入mircosoft vs code这里根据自己需要选择,感觉不太需要就输入no并按enter。
安装完成,输入:
$ conda info查看condo信息
如果报错,更新系统环境文件:
$ source .bashrc继续输入
$ conda info出现以下界面即为安装成功:
2.创建一个conda虚拟环境
输入以下命令以创建环境:
conda create -n MagicFairyCastle(输入虚拟环境名字) python=3.10(输入自己需要的版本号)一路选yes:

激活虚拟环境:
$ conda activate MagicFairyCastle用户名前面出现(虚拟环境名)即安装成功

给Conda配置国内源:(先跳过这一步,有问题再回来)
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
如果有问题可以恢复为默认源:
conda config --remove-key channels同时补充pip源:
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
pip config set install.trusted-host mirrors.aliyun.com
3.安装torch2.0.0,torchvision
torch有CPU版本和GPU版本,如果直接pip install torch可能会自动下载CPU版本导致无法使用GPU加速:
进入torch官网:torch官网,选择torch,进入页面选择适合自己Python版本和CUDA版本的GPU版torch2.0.0,我这里是Python3.10和CUDA11.7而且是Linux的X86_64版本:
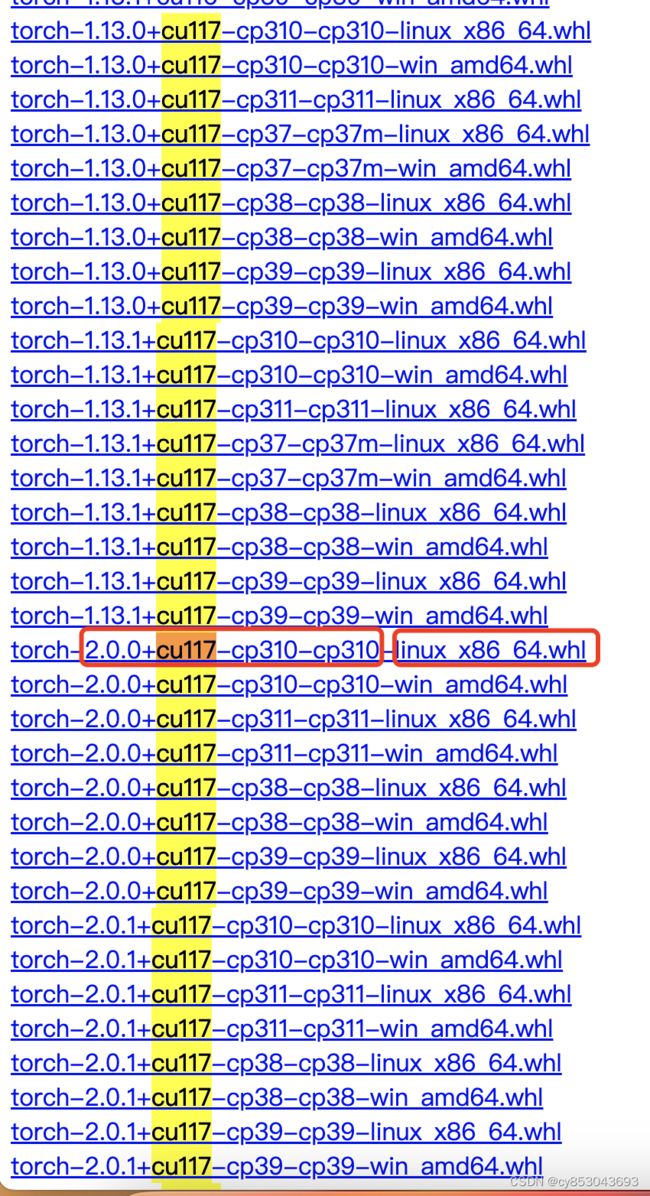
选择适合自己的版本,右键复制链接,然后输入以下wget下载命令(要对照自己的版本链接进行改动):
$ wget https://download.pytorch.org/whl/cu117/torch-2.0.0%2Bcu117-cp310-cp310-linux_x86_64.whl下载地址为当前目录,运行安装包:
$ pip install torch-2.0.0%2Bcu117-cp310-cp310-linux_x86_64.whl然后同样方法下载torchvision: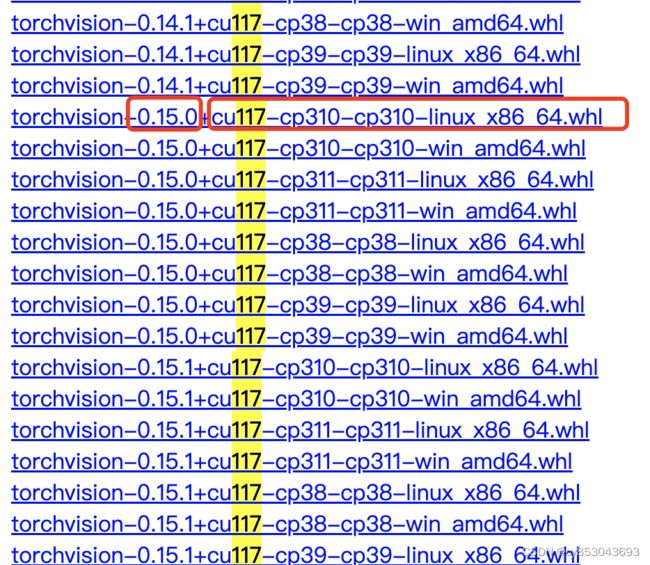
$ wget https://download.pytorch.org/whl/cu117/torchvision-0.15.0%2Bcu117-cp310-cp310-linux_x86_64.whl
$ pip install torchvision-0.15.0+cu117-cp310-cp310-linux_x86_64.whl查看是否安装成功:
$ pip list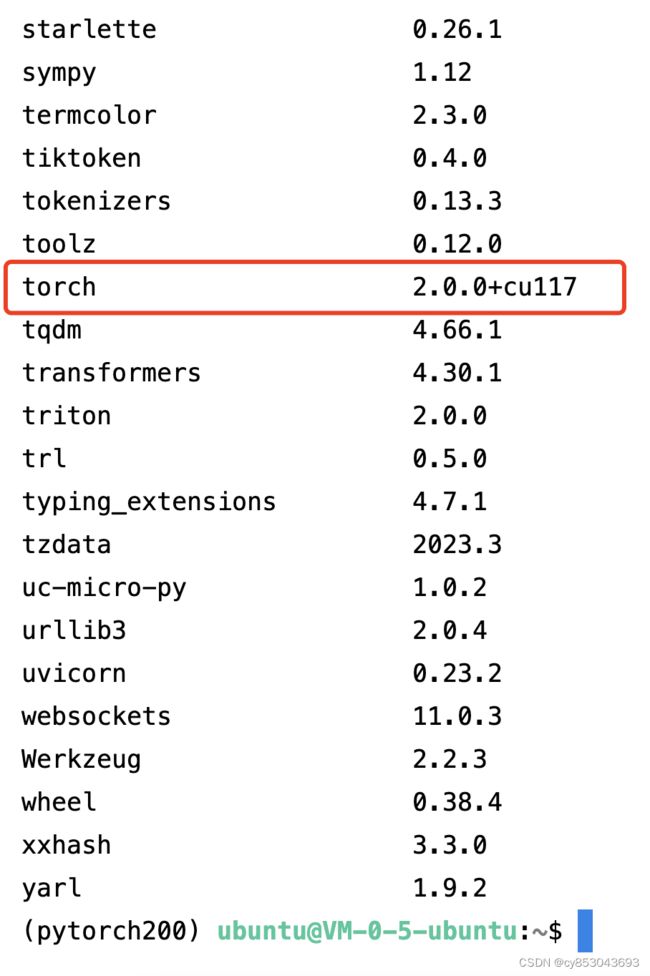
检查是否可以运行torch:
$ python
import torch
# 检测torch、cuda、cudnn版本
print(torch.__version__)
print(torch.version.cuda)
print(torch.backends.cudnn.version())
# 是否可用gpu
flag = torch.cuda.is_available()
print(flag)输出应该是版本信息和CUDA是否可用
2.0.0
11.7
true4.按照requirements.txt文件安装其他相应依赖:
$ pip install 包名如果pip 报错无法连接可以使用清华源作为镜像:
$ pip install package(修改为需要下载的包名) -i https://pypi.tuna.tsinghua.edu.cn/simple嫌麻烦的话也可以进入CodeGeeX2目录批量下载并安装:
$ pip install -r requirements.txt3.下载模型权重
(如果你的模型不是CodeGeeX2,可以去huggingface搜索,并在模型页面的files and versions下载模型权重文件和配置文件)
再次回到GitHub模型主页,找到模型权重的下载地址: 1.模型权重以及配置文件下载
1.模型权重以及配置文件下载
模型权重下载
将所有的文件链接复制然后,在模型目录中新建一个文件夹保存这些项目,例如我用来存放权重文件的目录为/home/ubuntu/model
进入该文件夹之后:
$ cd /home/ubuntu/model下载所有模型配置文件:
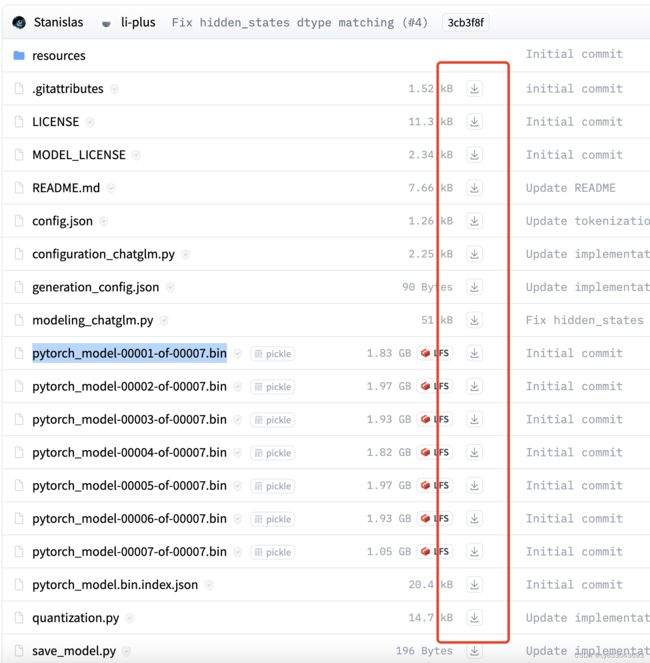
$ wget https://huggingface.co/THUDM/codegeex2-6b/resolve/main/.gitattributes
$ wget https://huggingface.co/THUDM/codegeex2-6b/resolve/main/LICENSE
$ wget https://huggingface.co/THUDM/codegeex2-6b/resolve/main/MODEL_LICENSE
$ wget https://huggingface.co/THUDM/codegeex2-6b/resolve/main/README.md
$ wget https://huggingface.co/THUDM/codegeex2-6b/resolve/main/config.json
$ wget https://huggingface.co/THUDM/codegeex2-6b/resolve/main/configuration_chatglm.py
$ wget https://huggingface.co/THUDM/codegeex2-6b/resolve/main/generation_config.json
$ wget https://huggingface.co/THUDM/codegeex2-6b/resolve/main/modeling_chatglm.py
$ wget https://huggingface.co/THUDM/codegeex2-6b/resolve/main/pytorch_model-00001-of-00007.bin
$ wget https://huggingface.co/THUDM/codegeex2-6b/resolve/main/pytorch_model-00002-of-00007.bin
$ wget https://huggingface.co/THUDM/codegeex2-6b/resolve/main/pytorch_model-00003-of-00007.bin
$ wget https://huggingface.co/THUDM/codegeex2-6b/resolve/main/pytorch_model-00004-of-00007.bin
$ wget https://huggingface.co/THUDM/codegeex2-6b/resolve/main/pytorch_model-00005-of-00007.bin
$ wget https://huggingface.co/THUDM/codegeex2-6b/resolve/main/pytorch_model-00006-of-00007.bin
$ wget https://huggingface.co/THUDM/codegeex2-6b/resolve/main/pytorch_model-00007-of-00007.bin
$ wget https://huggingface.co/THUDM/codegeex2-6b/resolve/main/pytorch_model.bin.index.json
$ wget https://huggingface.co/THUDM/codegeex2-6b/resolve/main/quantization.py
$ wget https://huggingface.co/THUDM/codegeex2-6b/resolve/main/save_model.py
$ wget https://huggingface.co/THUDM/codegeex2-6b/resolve/main/tokenization_chatglm.py
$ wget https://huggingface.co/THUDM/codegeex2-6b/resolve/main/tokenizer.model
$ wget https://huggingface.co/THUDM/codegeex2-6b/resolve/main/tokenizer_config.json进入到模型项目的/CodeGeeX2/demo/run_demo.py中,将add_code_generation_args(parse):函数中的model_path改成存放模型配置文件以及权重文件的目录:如果不知道在哪可以输入确定当前路径:
$ pwd2.更改权重路径

4.运行模型
现在让我们开始最后一步:python run_demo.py
至此,大模型的部署可能会遇到的问题就是这些,如果有不正确的地方欢迎讨论并指正,转载希望尊重原创,下一期应该会出大模型的几种微调方式。