C++常用STL容器
C++常用STL容器
-
- vector 向量容器
- 二维数组指针、二维向量
- pair 对
- list 双向列表
- map 表
- unordered_map 哈希表
- set 集合
- unordered_set 哈希集合
- string 字符串
- stack 栈
- queue 队列
- deque 双端队列
- priority_queue 优先级队列
vector 向量容器
当需要使用动态分配的数组的情况下,可以考虑使用vector,当删除元素时,不会释放限制的空间,所以向量容器的容量(capacity)大于向量容器的大小(size)。
头文件:#include
vector<int> myvector;
常用函数一览:
v.capacity(); //容器容量
v.size(); //容器大小
v.at(int idx); //用法和[ ]运算符相同
v.push_back(); //尾部插入
v.emplace_back(); //尾部插入,效率更高
v.pop_back(); //尾部删除,注意括号里不用加参数!
v.front(); //获取头部元素
v.back(); //获取尾部元素
v.begin(); //头元素的迭代器
v.end(); //尾部元素的迭代器
v.insert(iterator,elem); //在iterator指向的位置前插入值为elem的元素,返回指向这个值的迭代器。
v.insert(iterator, n, elem) //在iterator指向位置前插入n个值为elem的元素
v.insert(iterator, v2.begin, v2.end); //在v的iterator指向位置前,插入v2的[begin, end)区间的所有元素
v.erase(iterator); //移除iterator指向位置上的元素,迭代器此时指向下一个元素,但是迭代器指向位置不变
v.erase(begin, end); //移除[begin, end)区间的数据,迭代器此时指向下一个元素,但是迭代器指向位置不变
reverse(pos1, pos2); //将vector中的pos1~pos2的元素逆序存储
【附加注释】
1)erase函数可以用于删除vector容器中的一个或者一段元素,在删除一个元素的时候,其参数为指向相应元素的迭代器,而在删除一段元素的时候,参数为指向一段元素的开头的迭代器以及指向结尾元素的下一个元素的迭代器:
在进行单个元素删除后,传入的迭代器指向不变,仍然指向被删除元素的位置,而被删除元素之后的所有元素都向前移动一位,也就是该迭代器实际上是指向了原来被删除元素的下一个元素。
删除一段元素后,传入的迭代器指向也是不变的,仍然指向原来传进去时候的位置,修改的是删除段后面的元素的位置。
总结:
erase函数删除操作,传入参数为迭代器,而迭代器所指向的位置在删除前后是不发生改变的,改变的只是容器中的元素值,删除相应元素后,被删元素后面的所有元素复制到被删除元素的位置上去,同时指向容器尾部的迭代器也移动到新的尾部位置。
向量容器删除尾部元素有 v.pop_back() ,如果要删除首部元素则需要用到迭代器,如下:
//删除v第一个元素
vector<int>::iterator k = v.begin();
v.erase(k);
vecter相当于动态数组,需要经常删除第一个元素最好用deque,deque支持高效插入和删除容器的头部元素,因此也叫做双端队列。
2)insert函数与copy函数区分
insert函数通常可以与copy函数(结合inserter)实现相同的效果,
比如:将一段数据复制到vector的首部
list<int> lst = { 1, 2, 3, 4, 5, 6, 7, 8, 9 };
list<int> lst2 ={10}, lst3={10},lst4={10};
//lst被正序复制插入到迭代器lst2.begin()之前
//list类型里面迭代器不能加减,也不能使用下标运算符[]
//lst2包含1,2,3,4,5,6,7,8,9,10
copy(lst.cbegin(), lst.cend(), inserter(lst2, lst2.begin())); //在lst2首部插入复制元素
//等价于下面这句
lst2.insert(lst2.begin(), lst.begin(), lst.end()); //在lst2首部插入元素
copy函数与insert函数的区别:
从效果上来看,copy需要多次调用inserter函数,申请一段内存,每一次申请成功就复制数据;区间型insert则是在一个循环中申请够内存后再通过move_backward以逆向的方式一次性复制数据。
此外,copy每次调用inserter都会发生移动,而insert因为是申请区间内存,所以仅发生一次大的移动。
故从效率上看insert更好。
3)特别注意:
vector中的数据类型还可以是自定义的结构体,这样可以方便做题。
比如网易雷火春招机考中的第二题(华为也喜欢考这种结构体输入):
【题目描述】
你是倩女幽魂中的某个角色,要求用最少的技能次数将boss血量打到虚弱状态,注意不能打死。
首先输入一个数据M,表示M组数据。
每组数据的第一行分别输入boss的血量hp,boss虚弱血量的下界lowerhp,boss虚弱血量的上界upperhp,技能种类数 N。
第二行输入每种技能可以导致的boss掉血量。
输出将boss血量打到虚弱状态的最少技能次数。
【测试样例】
输入:
1
100 15 20 3
12 16 18
输出:
5
描述:最少需要5次技能来将boss血量降到虚弱状态。
【解答】可以将每组数据整合为一个结构体,再将M个结构体整合到一个结构体数组中进行输入
#include 其他常用方法:
①一维向量初始化:
//最常用的两种初始化方法
vector<int> a; // 声明一个int型向量a,size为0
vector<int> b(10); // 声明一个初始size为10的向量,初始值默认为0。
//向量默认初始值为0,但注意数组不会默认初始化为0,比如 int a[3]; 初始值不定。
//数组int a[3]={0};默认初始值才为0
vector<int> c(10, 1); // 声明一个初始size为10且初始值都为1的向量
vector<int> d(b); // 声明并用向量b初始化向量d
vector<int> e(c.begin(), c.begin() + 3); // 将c向量中从第0个到第2个(共3个)作为向量e的初始值,size为3
int n[] = { 1, 2, 3, 4, 5 };
std::vector<int> f(n, n + 5); // 将数组n的前5个元素作为向量f的初值,size为5
注意数组复制/拷贝的方法(下面几种方法都是深复制):
vector<int> a = {1, 2, 3};
(1) vector初始化时深复制
Ⅰ. 利用赋值操作符(深复制)
vector<int> b;
b = a;
Ⅱ. 利用赋值构造函数(深复制)
在初始化时,利用另一个已定义的向量进行深拷贝。
注意:默认拷贝构造函数执行的是浅拷贝。但vector中不是默认复制构造函数,因此是深拷贝。
vector<int> b(a);
//等价于
vector<int> b(a.begin(), a.end());
//等价于
vector<int> b = a;
//等价于
vector<int> b = vector<int>(a);
//等价于
vector<int> b = vector<int>(a.begin(), a.end());
(2)利用copy函数(深复制)
vector<int> b;
b.resize(a.size());
copy(a.begin(), a.end(), b.begin()); //以覆盖b数组原元素的形式进行复制
(3)利用assign()函数(清空并深复制)
vector<int> b{6, 6, 6};
b.assign(a.begin(), a.end());//清空b向量中原有的元素,赋予a向量中的元素
b.assign(5, 0); //清空b向量中原有的元素,赋予5个0
(4)利用swap()函数(交换两个vector)
注意:swap()是从堆上删除vector中的元素,使用swap函数可能会清空a向量里的元素
vector<int> b;
b.swap(a); //b向量与a向量交换,由于b向量初始为空,因此a向量会被清空
//若b向量初始不为空,则交换两个向量
vector<int> b{6, 6};
b.swap(a); //a向量变为{6, 6},b向量变为{1, 2, 3}
(5)使用insert函数
在b向量的末尾插入a向量的所有元素
vector<int> b;
b.insert(b.end(), a.begin(), a.end());
[附] clone()为浅拷贝
②插入元素
vector和deque如果没有预先指定大小,不能用下标法插入元素!
//尾部插入元素
myvector.emplace_back(元素);
myvector.push_back(元素);
//向量中迭代器指向元素前增加一个元素x
myvector.insert(iterator it,x);
//向量中迭代器指向元素前增加n个相同的元素x
myvector.insert(iterator it,int n,x);
//向量中迭代器指向元素前插入另一个相同类型向量的[first,last)间的数据
myvector.insert(iterator it,iterator first,iterator last);
完成同样的操作,push_back() 的底层实现过程比 emplace_back() 更繁琐,换句话说,emplace_back() 的执行效率比 push_back() 高。因此,在实际使用时,建议优先选用 emplace_back()。
注意初始化问题:
vector<pair<int,int> > dis(5);//初始化了一个长度为5的向量,pair默认都是<0,0>
dis.push_back(make_pair(i,m));//从第六个元素开始插入,前面5个pair默认都是<0,0>
dis[i] = make_pair(i, m);//i从0到5,这样才是从第一个元素开始覆盖插入
实际操作从键盘输入一个向量:
//输入整型向量
vector<int> tree;
int num,a;
cin>>num;
for(int i=0;i<num;++i)
{
cin>>a;
tree.push_back(a);
}
//输入字符型向量
vector<char> tree;
char ch;
while((ch=getchar())!='\n')
{
tree.emplace_back(ch);
}
//输入字符串,遇到换行符结束输入
string str;
while(getline(cin,str)) {...}
[注] getline()函数可以读取空格,遇到换行符或者EOF结束,但是不读取换行符。可以用这个函数输入一个带空格的字符串。
③ 删除元素
//删除尾部元素
myvector.pop_back();
//删除向量中迭代器指向元素
myvector.erase(iterator it);
//删除向量中[first,last)中元素
myvector.erase(iterator first,iterator last);
//将向量清空
myvector.clear();
vector删除元素之pop_back(),erase(),remove()_-CSDN博客
④vector的状态
//返回当前向量是否为空
myvector.empty();
if(myvector.empty()){cout<<“向量为空”;}
//返回当前向量元素个数
myvector.size();
//重新调整容器大小的通用函数resize()
myvector.resize(n);
//返回首尾两端元素的引用
myvector.front();
myvector.back();
//返回pos位置元素的引用
myvector.at(int pos);
//交换两个同类型向量的数据
void swap(vector&);
重新调整容器大小的通用函数resize():
1)resize(n)
调整容器的长度大小,使其能容纳n个元素。
如果n小于容器的当前的size,则删除多出来的元素。
否则,添加采用值初始化的元素。
2)resize(n,t)
多一个参数t,将所有新添加的元素初始化为t。
例如杨辉三角:
vector<vector<int>> ans(rowIndex+1);//初始化大小,否则后面无法用【下标】
for(int i=0;i<=rowIndex;i++)
{
ans[i].resize(i+1);//resize函数,可以使得后面下标超出
ans[i][0]=ans[i][i]=1;
for(int j=1;j<i;j++)
{
ans[i][j]=ans[i-1][j-1]+ans[i-1][j];
}
}
此外STL中还有reserve()函数,为容器预留空间,即为当前容器设定一个空间分配的阈值,但是并不会为容器直接allocate具体的空间,具体空间的分配是在创建对象时候进行分配。
capacity()为获取当前容器的预留空间。
⑤迭代器操作
//返回向量头指针,指向第一个元素
myvector.begin();
//返回向量尾指针,指向向量最后一个元素的下一个位置
myvector.end();
//样例:遍历向量
vector<int>::iterator it;
for(it=myvector.begin();it!=myvector.end();++it) {...} //正序遍历
for(it=myvector.rbegin();it!=myvector.rend();++it) {...} //逆序遍历
⑥main函数中为不确定大小向量输入元素
输入元素之间用空格间隔,回车结束
vector<int> myvector;
int num;
while(cin>>num)
{
myvector.push_back(num);
if(cin.get()=='\n')
{
break;
}
}
二维数组指针、二维向量
①二维数组指针
二维数组名是数组的首地址,虽然值等于第一个元素的地址,但是不代表元素的地址.
一维数组的数组名 直接付给指针, 如 int a[3]; int *p=a;
二维数组 对应的是二维数组的指针, 这样定义: int (*p) [4] ; p=a 就对了
int a[3][4]; a 与a[0]地址是一样的. a可以看成指向int [3]的指针, 与指向int类型的指针a的数据类型不同。虽然 a 和 a[0] 的类型不同,但它们的值是一样的.但值一样却未必是同样的数据类型!
p++只使p移动一个整数所占的字节长度,
a++却移动了三个整数所占的字节长度,
由指针运算就可以看出这两个指针不是同类型的。
当我们需要枚举数组中的两个元素时,如果我们发现随着第一个元素的递增,第二个元素是递减的,那么就可以使用双指针的方法,将枚举的时间复杂度从 O(N^2)减少至 O(N)。
② 二维向量初始化
注意后面的尖括号前面要加上空格,否则在有些编译器下会出现问题
//第一种比较常用
1 vector<vector<int> > dp(m , vector<int>(n ));//初始化m行,n列,默认值为0的二维数组。
2 vector<vector<int> > vt;//初始化一个 二维vector
3 vector<vector<int> > vect(vt);//使用另一个 二维 vector 初始化当前二维vector
4 vector< vector<int> > vec(row,vector<int>(column));//初始化一个 二维的vector 行row,列column,且值为0
5 vector<vector<int> > visited(row,vector<int>(column,6));//初始化一个 二维vector 行row,列column ,且 值为data=6 自定义data;
6 vector<vector<int> > vecto(row,vector<int>(vt[0].begin()+1,vt[0].begin()+3));初始化一个 二维vector 行row,第二个参数为一维vector;
注意返回值和函数形参的表示:
vector<vector<int>> kClosest(vector<vector<int>>& points)
③二维向量的输入
正确的二维向量输入方法就是模拟一个第二维向量,每次输入都输入到第二维向量中,再在第二维向量输入完成后,将该第二维向量添加到第一维向量中,实现二维向量的输入操作。
vector<vector<int> >res; // 保存结果(所有不重复的三元组)
// 找到一个和为零的三元组,添加到结果中
//res.push_back里必须是vector
vector<int> B;
res.push_back(B);
//下面这种表示比较常用
res.push_back(vector<int>{nums[i], nums[left], nums[right]});
res.push_back(vector<int>{1,2,3});
//这种表示可能不如上面的正规
res.push_back({L, R});
res.push_back({1,2});
C++二维向量(vector)的输入与遍历_fg river的博客
C++中vector
pair 对
头文件#include
C++ pair的基本用法总结
pair是将2个数据组合成一组数据,当一个函数需要返回2个数据的时候,可以选择pair, pair的实现是一个结构体,主要的两个成员变量是first和second 。
注意一下:make_pair()函数内调用的仍然是pair构造函数
创建pair对象:
pair<int, float> p1; //调用构造函数来创建pair对象
make_pair(1,1.2); //调用make_pair()函数来创建pair对象
pair对象的使用:
pair<int, float> p1(1, 1.2);
cout<< p1.first << endl;
cout<< p1.second << endl;
// 以v1和v2的值创建一个新的pair对象,其元素类型分别是v1和v2的类型。
make_pair(v1, v2);
// 创建一个空对象 word_count, 两个元素类型分别是string和int类型
pair<string, int> word_count;
// 创建一个author对象,两个元素类型分别为string类型,并默认初始值为James和Joy。
pair<string, string> author("James","Joy");
list 双向列表
这是一个双向链表类型
头文件 #include
创建对象:
list<int> L1;
list<int> L2(10);
基本操作:
(1) 元素访问:
lt.front();
lt.back();
lt.begin();
lt.end();
【注】list类型里面迭代器不能加减,也不能使用下标运算符[ ]
(2) 添加元素:
lt.push_back();
lt.push_front();
lt.insert(pos, elem);
lt.insert(pos, n , elem);
lt.insert(pos, begin, end);
lt.pop_back();
lt.pop_front();
lt.erase(begin, end);
lt.erase(elem);
(3)sort()函数、merge()函数、splice()函数:
sort()函数就是对list中的元素进行排序;
merge()函数的功能是:将两个容器合并,合并成功后会按从小到大的顺序排列;
比如:lt1.merge(lt2); lt1容器中的元素全都合并到容器lt2中。
splice()函数的功能是:可以指定合并位置,但是不能自动排序。
map 表
头文件#include
Map是一种键值对关联容器, 提供一对一的关联, 关联的形式为: Key—Value(键值对),另外关键字不能重复。
map 也可看做是关键字映射的集合, 即,map中不可出现重复的关键字,每条映射的关键字都是不同的。
map容器本身就带了字典排序的功能,由于内部红黑树结构的存储,查找的时间复杂度为O(log2N)。map的内部实现默认使用key键的升序来排序map的值,利用iterator在遍历它时,是一种中序遍历。
1.构造函数
map<char, int> mymap;
map<int, string> mapStudent;
2.插入元素 insert() 、emplace()
// 第一种 用insert或者emplace函數插入pair
// 插入单个值时,emplace效果好于insert
mymap[b] = 30;
mymp.emplace( b, 30 );
mymp.insert(b, 30 );
mymp.insert({ b, 30 });//insert可以用初始化列表形式,但emplace不可以
mymap.insert(make_pair('a', 100));
mymap.insert(pair<char, int>('a', 100));
// 第二种 用insert函数插入value_type数据
mapStudent.insert(map<int, string>::value_type(001, "student_one"));
// 第三种 用"array"方式插入
mapStudent[123] = "student_first";
mapStudent[456] = "student_second";
以上三种用法,虽然都可以实现数据的插入,但是它们是有区别的,当然了第一种和第二种在效果上是完成一样的,用insert函数插入数据,在数据的 插入上涉及到集合的唯一性这个概念,即当map中有这个关键字时,insert操作是不能在插入数据的,map中保存的还是之前的键值对。但是用数组方式就不同了,它可以覆盖以前该关键字对应的值。
注意:map、unordered_map、set、unordered_set都没有push_back()函数一说,可以用insert()和emplace()插入键值对。
3.元素取值 at()、 [ ]
Map中元素取值主要有 at 和 [ ] 两种操作,at 会作下标检查,而 [ ] 不会
没有关键字时,使用 [ ] 取值会导致插入
4.查找元素 find() 、count()
当所查找的关键key出现时,map::find()返回数据所在位置的迭代器,如果键不在Map容器中,则返回引用map.end()的迭代器。
用法: iterator map_name.find(key);
//find 返回迭代器指向当前查找元素的位置否则返回map::end()位置
iter = mapStudent.find("123");
if(iter != mapStudent.end())
cout<<"Find, the value is"<<iter->second<<endl;
else
cout<<"Do not Find"<<endl;
也可以用cout()计数关键字为key的元素的个数,在map里结果非0即1,返回的是布尔类型的值。
// 查询关键字为key的元素的个数,在map里结果非0即1,返回的是布尔类型的值
size_t count( const Key& key ) const;
5.刪除与清空元素 erase() 、clear()
//迭代器刪除
iter = mapStudent.find("123");
mapStudent.erase(iter);
//用关键字刪除
int n = mapStudent.erase("123"); //如果刪除了會返回1,否則返回0
//用迭代器范围刪除 : 把整个map清空
mapStudent.erase(mapStudent.begin(), mapStudent.end());
//等同于mapStudent.clear()
6.map的大小 size()
计算当前已经插入了多少数据。
int nSize = mapStudent.size();
7.map基本操作函数一览:
C++ maps是一种关联式容器,包含“关键字/值”对
begin() 返回指向map头部的迭代器
clear() 删除所有元素
count() 返回指定元素出现的次数,
(因为key值不会重复,所以只能是1 or 0)
empty() 如果map为空则返回true
end() 返回指向map末尾的迭代器
equal_range() 返回特殊条目的迭代器对
erase() 删除一个元素
find() 查找一个元素
get_allocator() 返回map的配置器
insert() 插入元素
key_comp() 返回比较元素key的函数
lower_bound() 返回键值>=给定元素的第一个位置
max_size() 返回可以容纳的最大元素个数
rbegin() 返回一个指向map尾部的逆向迭代器
rend() 返回一个指向map头部的逆向迭代器
size() 返回map中元素的个数
swap() 交换两个map
upper_bound() 返回键值>给定元素的第一个位置
value_comp() 返回比较元素value的函数
unordered_map 哈希表
unordered_map是c++11新加的一个标准容器,它提供了一对一的关系,是一个将key与value关联起来的容器,根据key值来查找value,其底层实现原理为哈希表,在查找速度上能达到O(1)的速度。
unordered_map和map类似,都是存储的key-value的值,可以通过key快速索引到value。不同的是unordered_map不会根据key的大小进行排序,存储时是根据key的hash值判断元素是否相同,即unordered_map内部元素是无序的。
unordered_map的源码是基于拉链式的哈希表,通过一个个bucket存储元素。
拉链法是将具有相同存储地址的关键字链成一单链表, m个存储地址就设m个单链表,然后用一个数组将m个单链表的表头指针存储起来,形成一个动态的结构,假设散列函数为 Hash(key) = key %13,其拉链存储结构为:

STL中哈希表的使用:
首先引入头文件:#include
1.哈希表的声明
哈希表声明:unordered_map
unordered_map<int,string> maplive;
unordered_map<int, int> mp;
第一个参数为键,第二个参数为键对应的值。存储是没有顺序的,只是根据key值将value存在指定的位置。可以使用[ ]操作符来访问key值对应的value值。
常用的key值类型: int、 float 、char、 string、 指针类型
默认不行的key类型:vector、list等,需要自己手写哈希函数,并作为第三个参数传入
比如49. 字母异位词分组:
unordered_map<string,vector<string>> mp; //哈希表声明
2.哈希表的初始化
1)在定义哈希表的时候通过初始化列表中的元素初始化:
unordered_map<int, int> hmap{ {1,10},{2,12},{3,13} };
//如果知道要创建的哈希表的元素个数时,也可以在初始化列表中指定元素个数
unordered_map<int, int> hmap{ {{1,10},{2,12},{3,13}},3 };
2)复制构造,通过其他已初始化的哈希表来初始新的表:
unordered_map<int, int> hmap{ {1,10},{2,12},{3,13} };
unordered_map<int, int> hmap1(hmap);
3)通过下标运算来添加元素:
当我们想向哈希表中添加元素时也可以直接通过下标运算符添加元素,格式为: mapName[key]=value;
如:hmap[4] = 14;
但是这样的添加元素的方式会产生覆盖的问题,也就是当hmap中key为4的存储位置有值时,
再用hmap[4]=value添加元素,会将原哈希表中key为4存储的元素覆盖
hmap[4] = 14;
hmap[5] = 15;
cout << hmap[4]; //结果为15
4)通过insert()函数来添加元素:
通过insert()函数来添加元素的结果和通过下标来添加元素的结果一样,不同的是insert()可以避免覆盖问题。
insert()函数在同一个key中插入两次,第二次插入会失败。
hmap.insert({ 5,15 });
hmap.insert({ 5,16 });
cout << hmap[5]; //结果为15
3.哈希表的遍历: 通过迭代器遍历
unordered_map<string,vector<string>> mp; //哈希表声明
mp[key].emplace_back(str);
vector<vector<string> ans;
//遍历哈希表
for (auto it = mp.begin(); it != mp.end(); ++it){
ans.emplace_back(it->second);
}
此外,还可以采用别的方法遍历哈希表:
819. 最常见的单词,遍历哈希表,找出出现频率最高的单词
unordered_map<string, int> frequencies;
for (auto &[word , frequency] : frequencies) {
if (frequency == maxFrequency) {
mostCommon = word;
break;
}
需要注意的是,[word , frequency]是C++17用法,用 auto a,a.first 和 a.second 可能更通用。
for(auto a:mp)
{
if(a.second>maxnum)
{
ss = a.first;
maxnum = a.second;
}
}
4.常用函数:
1)元素的插入:
①a[key]=value;和 a[key]++;
比如maplive[112]=“April”;
这种方法是最简单用的最多的添加数据方法
② Map_name.emplace(key,value);或者Map_name.emplace(pair
或者Map_name.emplace(make_pair(key,value));
emplace可以换成insert
解释:emplace/insert插入函数,因为我们这里要插入的是一个key/value pair(键值对),所以要用make_pair函数或者pair类的构造函数把一个字符串和一个整数打包成一个pair。
③ unordered_map
2)find() 函数 查找键值:
Map_name.find(key);
如果找到查找的键值,则返回该键值的迭代器位置,否则返回集合最后一个元素后一个位置的迭代器,即end();
比如maplive.find(112);
若mp.find(key) == mp.end()则表示没找到。
unordered_map<int,int>::iterator it = mp.find(target); //或者aoto it
2) count()函数:
统计某个key值对应的元素个数, 因为unordered_map不允许重复元素,所以返回值为0或1。
也可以用count函数查找键是否存在,Map_name.count(key)会返回key键在map中出现的次数,如果没有出现就返回0,出现则返回1,注意返回的不是key键对应的value值
if(mp.count(target) != 0) 等价于 if(mp.find(target) != mp.end())
{如果找到key了,...};
3) at()函数:根据key查找哈希表中对应的值
unordered_map<int, int> hmap{ {1,10},{2,12},{3,13} };
int elem = hmap.at(3);
4)迭代器
begin( )函数:该函数返回一个指向哈希表开始位置的迭代器
end( )函数:作用于begin函数相同,返回一个指向哈希表结尾位置的下一个元素的迭代器
cbegin() 和 cend():这两个函数的功能和begin()与end()的功能相同,唯一的区别是cbegin()和cend()是面向不可变的哈希表
用迭代器访问元素的键值 it->first
用迭代器访问元素的键值对应的元素值 it->second
//begin()用法
unordered_map<int, int>::iterator iter = hmap.begin(); //申请迭代器,并初始化为哈希表的起始位置
cout << iter->first << ":" << iter->second;
//end()用法
unordered_map<int, int>::iterator iter = hmap.end();
//cbegin() 和 cend()用法
const unordered_map<int, int> hmap{ {1,10},{2,12},{3,13} };
unordered_map<int, int>::const_iterator iter_b = hmap.cbegin(); //注意这里的迭代器也要是不可变的const_iterator迭代器
unordered_map<int, int>::const_iterator iter_e = hmap.cend();
5)erase()函数 删除元素
erase()函数: 删除某个位置的元素,或者删除某个位置开始到某个位置结束这一范围内的元素, 或者传入key值删除键值对
Map_name.erase(it)函数会删除迭代器it指向的元素。
Map_name.erase(key)可以直接删除哈希表中的(key,value)对
unordered_map<int, int> hmap{ {1,10},{2,12},{3,13} };
unordered_map<int, int>::iterator iter_begin = hmap.begin();
unordered_map<int, int>::iterator iter_end = hmap.end();
hmap.erase(iter_begin); //删除开始位置的元素
hmap.erase(iter_begin, iter_end); //删除开始位置和结束位置之间的元素
hmap.erase(3); //删除key==3的键值对
6)clear()函数:清空哈希表中的元素
hmap.clear()
7)empty()函数:判断哈希表是否为空,空则返回true,非空返回false
bool isEmpty = hmap.empty();
8)size()函数:返回哈希表的大小
int size = hmap.size();
9)bucket()函数:
以key寻找哈希表中该元素的储存的bucket编号(unordered_map的源码是基于拉链式的哈希表,所以是通过一个个bucket存储元素)
int pos = hmap.bucket(key);
10) bucket_count()函数:
该函数返回哈希表中存在的存储桶总数(一个存储桶可以用来存放多个元素,也可以不存放元素,并且bucket的个数大于等于元素个数)
int count = hmap.bucket_count();
总结一下最常用的函数
用法样例示范:
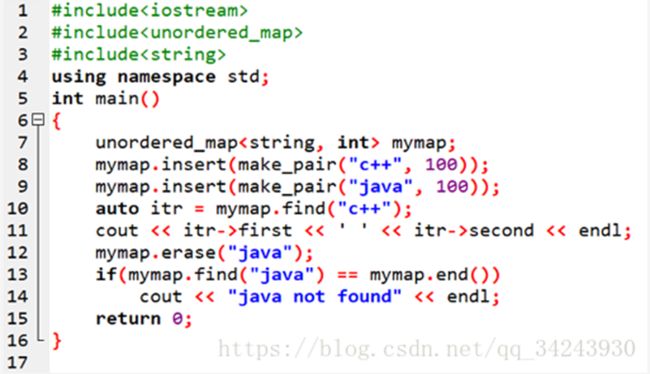
如果不用哈希表容器,如何自己构造一个哈希表?
//LeetCode 706.设计哈希映射
//实现 MyHashMap 类:
class MyHashMap {
private:
vector<list<pair<int,int>> > data;
static const int base=769;
static int hash(int key)
{
return key % base;
}
public:
//MyHashMap() 用空映射初始化对象
MyHashMap():data(base) {
}
//向 HashMap 插入一个键值对 (key, value) 。如果 key 已经存在于映射中,则更新其对应的值 value
void put(int key, int value) {
int h =hash(key);
//list>::iterator it;
//若换成rbegin(),rend()则是逆序从后往前遍历
for(auto it=data[h].begin();it != data[h].end();++it)
{
if((*it).first==key)
{
(*it).second = value;
return;
}
}
data[h].push_back({key,value}); //对应有data[h].erase(it);
//data[h].push_back(make_pair(key, value));
return;
}
}
MyHashSet(): data(base) {}这行代码是构造函数初始化列表,给data容器初始化大小,大小是769那么大 ,MyHashSet()是类名。
data(base)之所以是给容量而不是赋值,是因为data类型为vector。如果类型为vector,存在圆括号和花括号问题。data(base)表示给data开辟一个base容量,data{base},表示给data赋值base。详见C++ pirmer
这里用到了list,可以看下C/C++中vector与list的区别
那么,如何利用unordered_map + 自定义排序?
这里还需要用到pair
unordered_map<int, int> ht;
// 转为pair以对value进行排序
vector<pair<int, int>> tmp;
for(auto it = ht.begin(); it!=ht.end(); it++)
{
tmp.push_back(pair<int, int>(it->first, it->second));
}
// 降序排序
static bool cmp(pair<int, int> a, pair<int, int> b)
{
return a.second > b.second;
}
sort(tmp.begin(), tmp.end(), cmp);
调用成员函数cmp排序时出错的解决方法
注意:map、unordered_map、set、unordered_set都没有push_back()函数一说,可以用insert()和emplace()插入键值对。
set 集合
头文件#include
构造set集合的主要目的是为了快速检索,去重与排序。
set的特性:
所有元素都会根据元素的键值自动排序,set的元素不像map那样可以同时拥有实值(value)和键值(key),set元素的键值就是实值,实值就是键值。set不允许两个元素有相同的键值。
在set中每个元素的值都唯一,而且系统能根据元素的值自动进行排序。需要注意的是set中数元素的值不能直接被改变。
C++ STL中标准关联容器set, multiset, map, multimap内部采用的就是一种非常高效的平衡检索二叉树:红黑树,也称为RB树(Red-Black Tree)。RB树的统计性能要好于一般平衡二叉树,所以被STL选择作为了关联容器的内部结构。
总结:
(1) set存储的是一组无重复的有序元素,而multiset允许存储有序重复的元素;
(2) 如果要修改某一个元素值,必须先删除原有的元素,再插入新的元素。
创建对象:
set<T> s;
set<T, op(比较结构体)> s;
//op为排序规则,默认规则是less(升序排列),或者是greater(降序规则)。
基本操作:
s.size(); //元素的数目
s.max_size(); //可容纳的最大元素的数量
s.empty(); //判断容器是否为空
s.find(elem); //返回值是迭代器类型
s.count(elem); //elem的个数,要么是1,要么是0,multiset可以大于一
s.begin();
s.end();
s.rbegin();
s.rend();
s.insert(elem);
s.insert(pos, elem);
s.insert(begin, end);
s.erase(pos);
s.erase(begin,end);
s.erase(elem);
s.clear();//清除a中所有元素;
常见的key值类型:int、 float 、char、 string、 指针类型
默认不行的key类型:vector、list等,需要自己手写
注意:map、unordered_map、set、unordered_set都没有push_back()函数一说,可以用insert()和emplace()插入键值对。
unordered_set 哈希集合
头文件 #include
样例:

这个容器是个集合,所以重复插入相同的值是没有效果的。第10行输出的结果是2。
unordered_set可以把它想象成一个集合,它提供了几个函数让我们可以增删查:
unordered_set::insert(某元素)
unordered_set::erase(某元素)
unordered_set::find(某元素),没找到返回end()迭代器
unordered_set::count(某元素)
举例:
常用操作
unordered_set<char> rec;
//如果想利用已有数组对哈希集合进行初始化,可以利用迭代器进行构造:
vector<int> nums = {1, 3, 7, 9};
unordered_set<char> rec(nums.begin(), nums.end());
//没有找到某个元素
rec.find(str[i])==rec.end() 等价于 rec.count(str[i]) == 0
//插入某元素
rec.insert(str[i]); 等价于 rec.emplace(str[i]);
//删除某元素
rec.erase(str[i]);
还可以用于指针元素:
unordered_set<ListNode *> rec;
rec.count(head)
rec.insert(head);
if (mySet.find(i) == endSet.end())
常见的key值类型:int、 float 、char、 string、 指针类型
默认不行的key类型:vector、list等,需要自己手写
注意:map、unordered_map、set、unordered_set都没有push_back()函数一说,可以用insert()和emplace()插入键值对。
string 字符串
头文件#include
初始化:string str;
初始化中,string str;等价于string str=””;都是空字符串,末尾是否加’/0’取决于编译器,并且这个’/0’只作为字符串结尾标识,不算为一个元素。如果字符串中某个位置有’/0’,则输出该字符串时候,该位置会输出一个空格,后面的字符串正常输出。
常用ASCII码:‘0’ 48 ; ‘A’ 65 ; ‘a’ 97
string常见用法:
返回当前字符串长度size()和length()
str.empty() 返回当前字符串是否为空
str.push_back(字符); //字符串之后插入一个字符,不能用 emplace_back 代替!
str.pop_back(); //从尾部删除一个字符
注意队列和栈直接 push() 和 pop() ,不用加 _back,数组和字符串需要加 _back
一般可使用三种方法访问字符串中的单一字符:下标操作符 [ ] 和成员函数 at(i) 均返回指定的下标位置的字符。注意下标从0~size()-1
还可以通过迭代器访问,string::iterator it =str.begin()~str.end() ,*it为字符内容
在任意位置插入元素的insert():
insert(下标i,“要插入的字符串”)
尾插法:在当前字符串尾部追加其他字符串的 append() 函数:
str.append(str2); //在str后面追加一个str2
str.append(“123456”, 6); //在str后面追加上字符串123456中的前六个元素
str.append(5,‘m’); //在str后面追加5个m
str.append(str2.begin(),str2.end()); //使用迭代器给str追加上str2的元素
在任意位置删除元素的erase():
erase(int起始下标i,要删除字符数目) //erase(0,12);
erase(int 起始下标i) //erase(7);默认删除到最后
erase(string::iterator it) //如erase(str.begin()+1),删除迭代器指向的元素,函数返回值是指向删除元素的下一个元素的迭代器
erase(it1,it2) //删除[it1,it2)区间内的元素
将字符串清空的clear()
字符串和字符之间的运算符+和+=
按照字典序大小比较的<、>、<=、>=、==、!=
寻找特定字符或字符串的find(),从头开始寻找,返回第一次匹配字符串的位置。
find(str,pos)是用来寻找从pos开始(包括pos处字符)匹配str的位置。
rfind(str)是从字符串右侧开始匹配str,并返回在字符串中的位置(下标);
rfind(str,pos)是从pos开始(包括pos处字符),向前(左)查找符合条件的字符串。
以上四种用法,若找到则返回对应的字符串位置的int型首下标,找不到返回 string.npos,这在C++中表示一个非常大的整型。
如下所示:
string str = "abcpbcpbcp";
cout<<str.size()<<endl; //10
cout<<str.find("bc")<<endl; //1
cout<<str.rfind("bc")<<endl; //7
cout<<str.find("bc", 1)<<endl; //1
cout<<str.rfind("bc",7)<<endl; //7
此外还有find_first_of ()函数,参数与find函数基本相同。作用:在一个字符串str1中查找另一个字符串str2,如果str1中含有str2中的任何字符,则就会查找成功,返回str2所含字符中任何一个首次在str1中出现的位置。
而find函数则不同,查找完整的字符串str2所在的首位置,否则返回string.npos;
返回字符串str的子串str.substr(起始下标i,总长度n) 或 str.substr(起始下标i)//默认到末尾
string常用且常错的几个用法:(练习824. 山羊拉丁文)
1.表示cnt个a的字符串,可以用string(cnt,‘a’)的初始化表示,或者用for循环生成
比如: str += sting1[i] + string(cnt++,‘a’) + ’ '; //cnt个a的字符串
2. str.push_back(sentence[i]); 等价于str += sentence[i]; ,都是将一个字符添加到字符串末尾
3. 删除字符串中的某个字符,可以用 str.erase(起始下标,长度数目); str.erase(起始下标) //默认删到最后
str.erase(迭代器it) //删除it指向的元素,返回指向下一个元素的迭代器 str.erase(起始迭代器it1,结束迭代器it2) // [it1,it2 )
错误用法(删除末尾字符):
str.erase(str.end()) //越界了,end不存在元素
可以修改为str.erase(ans.end()-1);或者str.pop_back();
4.往字符串中插入某个字符,str.insert(起始下标,“字符串”);
5.返回子字符串 str.substr(起始下标,总长度):
6.查找特定字符或字符串的起始下标 int i = str.find(“字符串”或‘字符’);
如果 i == string::npos,则表示未找到
初始化:
初始化有两种方式,其中使用等号的是拷贝初始化,不使用等号的是直接初始化。
string str1 = "hello world"; // str1 = "hello world"
string str2("hello world"); // str2 = "hello world"
string str3 = str1; // str3 = "hello world"
string str4(str2); // str4 = "hello world"
string str5(10,'h'); // str5 = "hhhhhhhhhh"
string str6 = string(10,'h'); // str6 = "hhhhhhhhhh"
string str7(str1,6); // str7 = "world" 从字符串str1第6个字符开始到结束,拷贝到str7中
string str8 = string(str1,6); // str8 = "world"
string str9(str1,0,5); // str9 = "hello" 从字符串str1第0个字符开始,拷贝5个字符到str9中
string str10 = string(str1,0,5); // str10 = "hello"
char c[] = "hello world";
string str11(c,5); // str11 = "hello" 将字符数组c的前5个字符拷贝到str11中
string str12 = string(c,5); // str12 = "hello"
从键盘输入字符串:
//输入两个数字字符串,空格间隔,进行运算
string str1,str2;
while(cin>>str1>>str2){....}
//读取一行字符串,去掉字符串中的空格
//若直接按照while(cin>>str)进行输入,遇到空格就会停止输入,与要求不符。
//所以,需要用到getline()函数来获取一行字符串,回车结束
string str;
while(getline(cin,str)){...}
find函数样例:
796. 旋转字符串
题目:给定两个字符串, s 和 goal。如果在若干次旋转操作之后,s 能变成 goal ,那么返回 true 。s 的 旋转操作 就是将 s 最左边的字符移动到最右边。
例如, 若 s = ‘abcde’,在旋转一次之后结果就是’bcdea’
[思路] 首先,如果 s 和 goal 的长度不一样,那么无论怎么旋转,s 都不能得到goal,返回 false。字符串s+s 包含了所有 s 可以通过旋转操作得到的字符串,只需要检查 goal 是否为 s+s 的子字符串即可。
问题转换为:查找s+s字符串中是否包含goal字符串
bool rotateString(string s, string goal) {
if(s.size()!=goal.size())
{
return false;
}
if((s+s).find(goal) != string::npos) //一定要用string::npos
{
return true;
}
return false;
}
在不知道s与goal长度的情况下,更精简的版本:
bool rotateString(string s, string goal) {
return s.size()==goal.size() && (s+s).find(goal) != string::npos;
}
【补充】手动实现find函数以及KMP字符串匹配算法:28. 实现 strStr()
KMP 算法
是一个快速查找匹配串的算法,它的作用是如何快速在「原字符串」中找到「匹配字符串」。
「KMP 匹配」过程:
前缀:对于字符串 abcxxxxefg,我们称 abc 属于 abcxxxxefg 的某个前缀。
后缀:对于字符串 abcxxxxefg,我们称 efg 属于 abcxxxxefg 的某个后缀。
首先匹配串会检查之前已经匹配成功的部分中里是否存在相同的「前缀」和「后缀」。如果存在,则跳转到「前缀」的下一个位置继续往下匹配。
朴素解法不考虑剪枝的话复杂度是 O(m∗n) ,而 KMP 算法的复杂度为 O(m+n),KMP 为什么相比于朴素解法更快?
因为 KMP 利用已匹配部分中相同的「前缀」和「后缀」来加速下一次的匹配。
并且 KMP 的原串指针不会进行回溯(没有朴素匹配中回到下一个「发起点」的过程)。
stoi() 函数: 字符串转整型
stoi()中放入(string)类型的参数,可以把string转换成int类型。
stoi函数会做范围检查,所以数字的类型不能超过int范围,不然会报错,而且在转换的过程中会发生int强制类型转换,所以当有小数点或题目输入字符串长度大于等于10位时,一定要注意!
一个可行的解决方法是使用stoll函数代替stoi,将string转化为long long int。
比如下面这种情况就会发生强制类型转换
int n=stoi("1.234");
cout<<n;
//此时会输出1。
用法:
stoi(字符串名) 或 stoi(字符串名,起始位置,n进制),将 n 进制的字符串转化为十进制
n进制的字符串指的是我们把字符串里存的内容当成几进制来看
示例:
string str = "1010";
int a = stoi(str, 0, 2); //将字符串 str 从 0 位置开始到末尾的 2 进制转换为十进制
int a = stoi(str); //简写
类似函数:
stol等:将string转化为其他类型
atoi等:不接受string作为输入参数,需将string转化为char*。同时,atoi不进行范围检查,超出类型上/下界时直接输出上/下界。
replace函数:替换字符串中的给定值
头文件#include
replace的执行要遍历由区间[frist,last)限定的整个队列,以把old_value替换成new_value,因此复杂度为O(n)。
下面说下replace()函数常用的五种用法,另外有4种用法编译器可能会有警告,因此不推荐使用:
1)用str替换 指定字符串从 起始位置pos开始 长度为len 的字符
声明:
string& replace (size_t pos, size_t len, const string& str);
用例:
string str = "he is@ a@ good boy";
str = str.replace(str.find("a"), 2, "#"); //从第一个a位置开始的两个字符替换成#
cout << str << endl; //he is@ # good boy
2)用str替换 迭代器起始位置 和 结束位置 的字符
声明:
string& replace (const_iterator i1, const_iterator i2, const string& str);
用例:
string str = "he is@ a@ good boy";
str = str.replace(str.begin(), str.begin() + 5, "#"); //用#替换从begin位置开始的5个字符
cout << str << endl; //#@ a@ good boy
3)用substr的指定子串(给定起始位置和长度)替换从指定位置上的字符串
声明:
string& replace (size_t pos, size_t len, const string& str, size_t subpos, size_t sublen);
用例:
string str = "he is@ a@ good boy";
string substr = "12345";
str = str.replace(0,5, substr, substr.find("1"), 4); //用substr的指定字符串替换str指定字符串
cout << str << endl; //1234@ a@ good boy
4)用重复n次的c字符替换从指定位置pos长度为len的内容
声明:
string& replace (size_t pos, size_t len, size_t n, char c);
用例:
char ch = '#';
str = str.replace(0, 6, 3, ch); //用重复 3 次的 str1 字符替换的替换从位置 0~6 的字符串
cout << str << endl; //### a@ good boy
5)用重复n次的c字符替换从指定迭代器位置(从i1开始到结束)的内容
声明:
string& replace (const_iterator i1, const_iterator i2, size_t n, char c);
用例:
char ch = '#';
str = str.replace(str.begin(), str.begin() + 6, 3, ch); //用重复3次的str1字符替换的替换从指定迭代器位置的内容
cout << str << endl; //### a@ good boy
to_string()函数:整型转字符串
C++中的 to_string(value)系列函数将数值value转换成字符串形式。value不能为字符类型。
std::string pi = "pi is " + std::to_string(3.1415926);
//输出: pi is 3.1415926
C++ int与string的相互转换
总结:
- const char* 字符串 以 “\0”结尾。
- char[] 字符串 以 “\0”结尾。
- string 字符串 不以 “\0”结尾。
- char[n] = “string”, 当string 长度+“\0”>n时,会因空间不足出错。
- string.c_str() 转 const char* 时, 会在字符串末尾 自动补“\0”
- char* 转string 时, 会自动把末尾的 “\0” 去掉。
【附】C语言的atoi()函数:
atoi()函数——将char* 转换成int类型
功 能: 把字符串char* 类型转换成整型数int类型并返回结果,注意:不适用于string类,string类型需要先用c_str()函数进行转换再用atoi()函数。
用 法: int atoi(const char *nptr);
atoi()会扫描参数nptr字符串,跳过前面的空格字符,直到遇上数字或正负号才开始做转换,而再遇到非数字或字符串时(‘\0’)才结束转化,并将结果返回(返回转换后的整型数)。
举例:
#include str.c_str()函数
C 库函数 int atoi(const char *str) 把参数 str 所指向的字符串转换为一个整数(类型为 int 型)。但不适用于string类串,可以使用string对象中的c_str()函数进行转换。
c_str()函数返回一个指向正规c字符串的指针,内容与string串相同。将string对象转换为C中的字符串样式。
std::string str="123";
int a =str-'0'; //错误,不可以直接用一个字符串减去‘0’
int n = atoi(*str); //错误
int n = atoi(str.c_str()); //正确,可以将string转为int
单词分割
将一个string句子分割出各个单词,并进行存储。
【思路】for循环遍历句子,遇到单词存入临时字符串,不是单词就输出临时字符串,并将临时字符串重新置零;注意句子末尾可能没有标点,因此最后一个单词需要额外注意。可以让i=length,相当于变相句子末尾加一个标点。
例题:819. 最常见的单词
string word;
unordered_map<string, int> frequencies;
int length = paragraph.size();
for (int i = 0; i <= length; i++)
{
if (i < length && isalpha(paragraph[i])) //判断是字母
{
word.push_back(tolower(paragraph[i]));//转为小写
}
else if (word.size() > 0)
{
frequencies[word]++;//将切割好的单词存入哈希表或者数组中
word = ""; //等价于word.clear()
}
}
【拓展】string_view
string_view 是C++17所提供的用于处理只读字符串的轻量对象。这里后缀 view 的意思是只读的视图。
通过调用 string_view 构造器可将字符串转换为 string_view 对象。
string 可隐式转换为 string_view。
string_view 是只读的轻量对象,它对所指向的字符串没有所有权。
string_view通常用于函数参数类型,可用来取代 const char* 和 const string&。
string_view 代替 const string&,可以避免不必要的内存分配。
string_view的成员函数即对外接口与 string 相类似,但只包含读取字符串内容的部分。
string_view::substr()的返回值类型是string_view,不产生新的字符串,不会进行内存分配。
string::substr()的返回值类型是string,产生新的字符串,会进行内存分配。
string_view字面量的后缀是 sv。(string字面量的后缀是 s)
例题:648. 单词替换
//将 dictionary 中所有词根放入哈希集合中
unordered_set<string_view> dictionarySet;
for (auto &root : dictionary) {
dictionarySet.emplace(root);
}
vector<string_view> words;
stack 栈
后进先出
头文件 #include
stack<typename> name;
函数:
返回当前栈是否为空的empty()
返回当前元素个数的size()
向栈顶添加新元素push()或者emplace()
栈顶元素出栈pop()
获得栈顶元素top(),不能像队列那样访问队首和队尾
例题:
//leetcode 1249. 移除无效的括号
//从字符串中删除最少数目的 '(' 或者 ')' (可以删除任意位置的括号),使得剩下的「括号字符串」有效。
//思路:搭配括号,直接遍历s,遇到‘(’,将他的位置入栈;
//遇到‘)’有两种可能,栈里有“(”,就出栈,没有‘(’即栈为空直接删除当前符号,此时s长度和下标需要--;
//遍历完后如果栈不为空,说明存在‘(’没有匹配,故依次pop栈顶元素,逐个删除。
string minRemoveToMakeValid(string s) {
stack<int> record;
int n = s.size();
for(int i=0;i<n;++i)
{
if(s[i]=='('||s[i]==')')
{
if(s[i]=='(')
{
record.push(i);
}
else if(record.empty())
{
s.erase(i,1);
--n;
--i;//删掉字符串中某个字符后,该字符后面的元素下标都会自动-1,故需要将计数标签-1,继续访问“该i位置”的元素
}
else
{
record.pop();
}
}
}
while(!record.empty())
{
int k=record.top();//top不是pop,pop()是void类型
record.pop();
s.erase(k,1);
}
return s;
此题有两点注意:
1)删掉字符串中某个字符后,该字符后面的元素下标都会自动-1,故需要将计数标签-1,才会继续访问“该i位置”的元素。否则会跳过一个元素。
2)top不是pop,pop()是void类型,容易手误。
queue 队列
先进先出
头文件#include
queue<typename> name;
常用函数:
当前队列是否为空的 empty()
返回队列元素个数的 size()
添加新元素push() 或者emplace()
删除队首元素pop()
获得队首元素的引用front()
获得队尾元素的引用back()
交换两个同类型队列中的元素 swap(queue &other_q)
函数解释:
front():返回 queue 中第一个元素的引用。如果 queue 是常量,就返回一个常引用;如果 queue 为空,返回值是未定义的。
back():返回 queue 中最后一个元素的引用。如果 queue 是常量,就返回一个常引用;如果 queue 为空,返回值是未定义的。
push(const T& obj):在 queue 的尾部添加一个元素的副本。这是通过调用底层容器的成员函数 push_back() 来完成的。
push(T&& obj):以移动的方式在 queue 的尾部添加元素。这是通过调用底层容器的具有右值引用参数的成员函数 push_back() 来完成的。
emplace():用传给 emplace() 的参数调用 T 的构造函数,在 queue 的尾部生成对象。
swap(queue &other_q):将当前 queue 中的元素和参数 queue 中的元素交换。它们需要包含相同类型的元素。也可以调用全局函数模板 swap() 来完成同样的操作。
和 stack 一样,queue 也没有迭代器。访问元素的唯一方式是遍历容器内容,并移除访问过的每一个元素
deque 双端队列
双端队列是一个可以在队列任意一端插入元素的队列。
头文件#include
用法:
常用构造函数:
deque<int> ideq;
deque<int> ideq(10);
常用函数一览:
a)元素访问:
ideq[i];
ideq.at[i];
ideq.front();
ideq.back();
ideq.begin();
ideq.end();
b)增加函数
ideq.push_front( x); //双端队列头部增加一个元素X
ideq.push_back(x); //双端队列尾部增加一个元素x
ideq.insert(pos,elem); //pos是vector的插入元素的位置
ideq.insert(pos, n, elem) //在位置pos上插入n个元素elem
ideq.insert(pos, begin, end);
c)删除函数
ideq.pop_front(); //删除双端队列中最前一个元素
ideq.pop_back(); //删除双端队列中最后一个元素
ideq.clear(); //清空双端队列中元素
ideq.erase(pos); //移除pos位置上的元素,返回下一个数据的位置
ideq.erase(begin, end); //移除[begin, end)区间的数据,返回下一个元素的位置
d)判断函数
ideq.empty() ; //向量是否为空,若true,则向量中无元素
e)大小函数
ideq.size(); //返回向量中元素的个数
样例:
deque<int> levelList;
levelList.push_back(node->val);
levelList.push_front(node->val);
priority_queue 优先级队列
头文件#include
优先级队列和queue不同的就在于我们可以自定义其中数据的优先级, 让优先级高的排在队列前面,优先出队
优先队列具有队列的所有特性,包括基本操作,只是在这基础上添加了内部的一个排序,它本质是一个堆实现的
根据C++参考手册,优先级队列的定义如下:
template<
class T,
class Container = std::vector<T>,
class Compare = std::less<typename Container::value_type>
> class priority_queue;
从定义可以看出,priority_queue 是一个模板类,有三个模板类型参数,分别是:
- 参数1: 优先级队列的元素类型 T ,如 pair
- 参数2: 优先级队列内部具体用哪种容器(Container) 存储参数1指定的元素类型,第2个模板参数是有默认类型参数的,默认类型参数是 vector ,T 取决于参数1指定的类型是什么。
- 参数3: 参数3需要指定一个实现了 operator< 操作符的类(叫做仿函数或者函数对象,实际上就是类,只是调用时写起来像函数一样),比较操作符的实现符合 严格弱顺序 strict weak order 语义。模板参数3也是有默认类型,默认是大顶堆
std::less,其中 Container 指的是参数2,Container::value_type指的是参数2容器内部元素值的类型。
如果感觉上面的模板介绍太详细,可以直接看下面这个常用的简洁版声明:
priority_queue<Type, Container, Functional>;
- Type是要存放的数据类型,常用数据类型如 int、string、pair
- Container是实现底层堆的容器,必须是数组实现的容器,如vector、deque
- Functional是比较方式/比较函数/优先级
map 和 set 底层存储结构都是红黑树,queue 默认底层存储结构是 deque 双端队列,priority_queue 默认底层存储结构是 vector。
优先级队列的基本操作:
特别注意,优先级队列用的是top(),没有 front() 和 back() 之说。
q.size();//返回q里元素个数
q.empty();//返回q是否为空,空则返回1,否则返回0
q.push(k);//在q的末尾插入k
q.pop();//删掉q的第一个元素
q.top();//返回q的第一个元素,特别注意,优先级队列没有 front() 和 back() 之说
1.一般默认数据类型情况的使用
//此时默认的容器是vector,默认的比较方式是大顶堆less, less >q; 因为本身默认就是大顶堆,所以 vector,less 可忽略
priority_queue<string> b;
priority_queue<pair<int, int>> q;
//上面等价于priority_queue, vector>, decltype(&cmp)> q(cmp);,其中cmp为自定义比较函数
//构造一个小顶堆,注意vector 和 greater都不加()
priority_queue <int,vector<int>,greater<int> > q;
priority_queue<string, vector<string>, greater<string>> priQueMinFirst;
## 常用函数:注意是top()不是front(),优先级队列没有front()、back()之说!!!
top() pop() push() empty() size()
## 自定义比较方式
......
需要记住 greater是小顶堆。当不用默认升序(排序)和默认大顶堆(优先级队列)时,需要自己添加小顶堆参数。
排序或优先级队列默认大顶堆 less,注意优先级队列中不写()
在排序中,大顶堆是小于号return a < b;(对应比较函数的形参顺序是a和b),每次将选出的最大元素放到数组末尾,排完顺序之后为升序序列。对于优先级队列而言,每次将选出的最大元素放到队首,出队列之后继续调整。
总结:默认大顶堆是小于号,每次选出最大值。小顶堆greater是大于号,每次选最小值。
在排序自定义比较函数中,默认是大顶堆,小于号,升序排序。自己可以实现小顶堆,大于号,降序排列。
2.自定义仿函数
对 map, set, priority_queue 类型均可以传入仿函数
当数据类型并不是基本数据类型,而是自定义的数据类型时,就不能用greater或less的比较方式了,而是需要自定义比较方式—仿函数
C++中的仿函数通过在一个单独定义的类中重载operator()运算符实现。
如果使用自定义比较的仿函数,那么使用时也要传入第二个模板类型参数。
struct fruit{
int index;
int price;
};
//自定义仿函数,希望水果价格高为优先级高
//大顶堆, 小于号
/* 针对某种类型的自定义比较仿函数,cpp 中 struct 相当于全部 public 的 class */
struct classcomp{
/* const 这里编译没有约束,但是对于明确的不可变参加上更严谨 */
bool operator() (const fruit& f1, const fruit& f2)
{
return f1.price < f2.price;
}
};
//此时优先队列的定义应该如下
// classcomp 必须是针对 fruit 类型的比较仿函数,第二个缺省存储结构也不能少
priority_queue<fruit, vector<fruit>, classcomp> q;
int main(){
vector<fruit> v = {{1, 11}, {3, 33}, {2, 22}, {5, 55}, {4, 44}};
for(...) q.push(v[i]);
cout<<q.top()<<endl;
return 0;
}
举例而言,自定义的比较函数创建的优先级队列:
struct mycomp
{
bool operator()(pair<int,int>& a, pair<int,int>& b){
//operator()重写仿函数
//小顶堆,大于号,值越小优先级越高,排在队首
return a.second > b.second;
}
};
priority_queue<pair<int,int>, vector<pair<int,int>>, mycomp> myque;
3.重载 operator< 运算符
重载运算符 让cpp代码的表达力有很大提升,比如map重载[ ]可以翻遍用[ ]获取指定key的value,还有如果定义了一些矩阵运算什么的,重载 * 就更加方便灵活了。
priority_queue 实现使用的默认比较是 operator< ,是大顶堆数据结构,即队列头元素值最大。
重载 operator< 运算符,这种方式通用性比较强,使得复杂结构变得像基本数据类型一样可比较,不用再传比较器,因为默认的大顶堆的比较这时已经生效了。
重载 operator< 运算符是在自己定义的结构体或类里加一个重载的bool operator<() 函数。需要注意的是该重载函数的参数类型与函数类型都要加 const 约束。在之后的优先级队列定义中,只传入第一个参数(自定义的结构体或类数据类型)即可,可以不用再传入第二个参数(容器)和第三个参数(比较器)了。
缺点:
如果有两个模板容器对同一自定义数据结构(结构体或者类)需要不同的比较器,那么重载 < 这种方法就没有上面的自定义比较器(比较函数或者仿函数)适用。
struct Node
{
int index;
int value;
// 注意点:这里的两个 const 都不可省略!!!因为编译约束
// const 常和 & 搭配使用
//注意结构体用 . 运算符,指针用 -> 运算符,容易搞混
bool operator < (const Node& compNode) const{ //该函数也可以写在结构体外面,作为一个独立的函数
return value > compNode.value; //小顶堆,大于号,每次选出最小元素放至队顶
} //左边的value 等价于 this->value
};
int main()
{
vector<Node> a = { {1, 11}, {3, 33}, {2, 22}, {5, 55}, {4, 44} };
//Node 类型重载了 < ,变得像 int 等基本数据类型一样可比较了
priority_queue<Node> q;
//还可以用 {一一对应的结构体的每个数据成员,逗号间隔} 表示结构体,比如:
q.push({3, 9});
for(int i = 0; i < a.size(); ++i) {
q.push(a[i]);
}
//按照从小到大的顺序输出所有节点
while(!q.empty()) {
auto f = q.top();
printf("index is %d, value is %d\n", f.index, f.value);
q.pop();
}
return 0;
}
对于 cpp 中需要自定义比较时,如果以后的操作比较都是定的,再用重载,否则还是用自定义比较函数和仿函数比较好。
练习:23. 合并K个升序链表
4.自定义比较函数 + decltype
优先级队列的模板及三个参数如下:
priority_queue<Type, Container, Functional>;
decltype 用于类型自动推断,传入&cmp函数指针,decltype自动推断出第3个模版参数类型应该是什么。总的来说,如果元素类型已经符合严格弱顺序排序,只要自定优先级队列的第1个模版参数即可。
当不在类中自定义仿函数,而是自定义一个比较函数时,在定义优先级队列时需要用到关键字“decltype(声明类型)”,这种自定义比较函数常用于需要以pair.second 的大小来排序的情况,比如下面这道题中,自定义了一个以pair.second 的大小来排序的比较函数cmp,随后的优先级队列定义应该如下:
priority_queue<pair<int, int>, vector<pair<int, int>>, decltype(&cmp)> q(cmp);
然后看一下这道题:
347. 前 K 个高频元素
给你一个整数数组 nums 和一个整数 k ,请你返回其中出现频率前 k 高的元素。你可以按 任意顺序 返回答案。
示例 1:
输入: nums = [1,1,1,2,2,3], k = 2
输出: [1,2]
【思路】堆
首先遍历整个数组,并使用哈希表记录每个数字出现的次数,并形成一个「出现次数数组」。
利用堆的思想:建立一个小顶堆,然后遍历「出现次数数组」:
-
如果堆的元素个数小于 k,就可以直接插入堆中。
-
如果堆的元素个数等于 k,则检查堆顶与当前出现次数的大小。如果堆顶更大,说明至少有 k 个数字的出现次数比当前值大,故舍弃当前值;否则,就弹出堆顶,并将当前值插入堆中。
遍历完成后,堆中的元素就代表了「出现次数数组」中前 k 大的值。
【注意点】
-
不能用 map
-
不能用 priority_queue
//自定义优先级队列的比较函数,以 second 来排序
static bool cmp(pair<int, int>& a, pair<int, int>& b){
return a.second > b.second;
}
vector<int> topKFrequent(vector<int>& nums, int k) {
unordered_map<int, int>mp;
vector<int> ans;
for(int a:nums){
mp[a] ++;
}
// pair 的第一个元素代表数组的值,第二个元素代表了该值出现的次数
//注意定义中q(cmp)不可省略
priority_queue<pair<int, int>, vector<pair<int, int>>, decltype(&cmp)> q(cmp);
for(auto v:mp){
if(q.size() == k){
if(q.top().second < v.second){
q.pop();
q.emplace(v.first, v.second);
}
}else{
q.emplace(v.first, v.second);
}
}
while(!q.empty()){
ans.emplace_back(q.top().first);
q.pop();
}
return ans;
}
下面这种写法是利用了模板来构造小顶堆,只需要将「出现次数数组」的first 与second 倒换过来就可以了。因为 pair 的系统排序是默认以 first 为主。这种写法可以不用再构造比较函数,也更简洁一些。
vector<int> topKFrequent(vector<int>& nums, int k) {
unordered_map<int, int>mp;
vector<int> ans;
for(int a:nums){
mp[a] ++;
}
//用模板来构造小顶堆,可以不必再构造比较函数
// pair 的第二个元素代表数组的值,第一个元素代表了该值出现的次数
priority_queue<pair<int, int>, vector<pair<int, int>>, greater<pair<int, int>>> q;
for(auto v:mp){
if(q.size() < k){
q.push({v.second, v.first});
}else{
q.push({v.second, v.first});
q.pop();
}
}
while(!q.empty()){
ans.emplace_back(q.top().second);
q.pop();
}
return ans;
}
【拓展】decltype 简介
decltype 是“declare type”的缩写,译为“声明类型”。. 既然已经有了 auto 关键字,为什么还需要 decltype 关键字呢?
因为 auto 并不适用于所有的自动类型推导场景,在某些特殊情况下 auto 用起来非常不方便,甚至压根无法使用,所以 decltype 关键字也被引入到 C++11 中。比如,auto 只能用于类的静态成员,不能用于类的非静态成员(普通成员),如果我们想推导非静态成员的类型,这个时候就必须使用 decltype 了。
auto 和 decltype 关键字都可以自动推导出变量的类型,但它们的用法是有区别的:
auto varname = value;
decltype (exp) varname = value;
其中,varname 表示变量名,value 表示赋给变量的值,exp 表示一个表达式。
auto 根据=右边的初始值 value 推导出变量的类型,而 decltype 根据 exp 表达式推导出变量的类型,跟=右边的 value 没有关系。
另外,auto 要求变量必须初始化,而 decltype 不要求。这很容易理解,auto 是根据变量的初始值来推导出变量类型的,如果不初始化,变量的类型也就无法推导了。decltype 可以写成下面的形式:
decltype(exp) varname;
decltype 能够根据变量、字面量、带有运算符的表达式推导出变量的类型。
C++ decltype 用法举例:
int a = 0;
decltype(a) b = 1; //b 被推导成了 int
decltype(10.8) x = 5.5; //x 被推导成了 double
decltype(x + 100) y; //y 被推导成了 double
当程序员使用 decltype(exp) 获取类型时,编译器将根据以下三条规则得出结果:
- 如果 exp 是一个不被括号( )包围的表达式,或者是一个类成员访问表达式,或者是一个单独的变量,那么 decltype(exp)的类型就和 exp 一致,这是最普遍最常见的情况。比如:
int n = 0;
const int &r = n;
Student stu;
decltype(n) a = n; //n 为 int 类型,a 被推导为 int 类型
decltype(r) b = n; //r 为 const int& 类型, b 被推导为 const int& 类型
decltype(Student::total) c = 0; //total 为类 Student 的一个 int 类型的成员变量,c 被推导为 int 类型
按照推导规则 1,对于一般的表达式,decltype 的推导结果就和这个表达式的类型一致。
- 如果 exp 是函数调用,那么 decltype(exp) 的类型就和函数返回值的类型一致。
//函数声明
int& func_int_r(int, char); //返回值为 int&
int&& func_int_rr(void); //返回值为 int&&
int func_int(double); //返回值为 int
const int& fun_cint_r(int, int, int); //返回值为 const int&
const int&& func_cint_rr(void); //返回值为 const int&&
//decltype类型推导
int n = 100;
decltype(func_int_r(100, 'A')) a = n; //a 的类型为 int&
decltype(func_int_rr()) b = 0; //b 的类型为 int&&
decltype(func_int(10.5)) c = 0; //c 的类型为 int
decltype(fun_cint_r(1,2,3)) x = n; //x 的类型为 const int &
decltype(func_cint_rr()) y = 0; // y 的类型为 const int&&
需要注意的是,exp 中调用函数时需要带上括号和参数,但这仅仅是形式,并不会真的去执行函数代码。
- 如果 exp 是一个左值,或者被括号( )包围,那么 decltype(exp) 的类型就是 exp 的引用;假设 exp 的类型为 T,那么 decltype(exp) 的类型就是 T&。
左值是指那些在表达式执行结束后依然存在的数据,也就是持久性的数据;
右值是指那些在表达式执行结束后不再存在的数据,也就是临时性的数据。
有一种很简单的方法来区分左值和右值,对表达式取地址,如果编译器不报错就为左值,否则为右值。
using namespace std;
class Base{
public:
int x;
};
int main(){
const Base obj;
//带有括号的表达式
decltype(obj.x) a = 0; //obj.x 为类的成员访问表达式,符合推导规则一,a 的类型为 int
decltype((obj.x)) b = a; //obj.x 带有括号,符合推导规则三,b 的类型为 int&。
//加法表达式
int n = 0, m = 0;
decltype(n + m) c = 0; //n+m 得到一个右值,符合推导规则一,所以推导结果为 int
decltype(n = n + m) d = c; //n=n+m 得到一个左值,符号推导规则三,所以推导结果为 int&
return 0;
}