并发编程-线程池ForkJoinPool工作原理分析
由一道算法题引发的思考
2. 基于归并排序算法实现
2.1 什么是归并排序
2.2 归并排序动图演示


2.3 使用归并排序实现上面的算法题
public class MergeSort {
private final int[] arrayToSort; //要排序的数组
private final int threshold; //拆分的阈值,低于此阈值就不再进行拆分
public MergeSort(final int[] arrayToSort, final int threshold) {
this.arrayToSort = arrayToSort;
this.threshold = threshold;
}
/**
* 排序
*
* @return
*/
public int[] sequentialSort() {
return sequentialSort(arrayToSort, threshold);
}
public static int[] sequentialSort(final int[] arrayToSort, int threshold) {
//拆分后的数组长度小于阈值,直接进行排序
if (arrayToSort.length < threshold) {
//调用jdk提供的排序方法
Arrays.sort(arrayToSort);
return arrayToSort;
}
int midpoint = arrayToSort.length / 2;
//对数组进行拆分
int[] leftArray = Arrays.copyOfRange(arrayToSort, 0, midpoint);
int[] rightArray = Arrays.copyOfRange(arrayToSort, midpoint,
arrayToSort.length);
//递归调用
leftArray = sequentialSort(leftArray, threshold);
rightArray = sequentialSort(rightArray, threshold);
//合并排序结果
return merge(leftArray, rightArray);
}
public static int[] merge(final int[] leftArray, final int[] rightArray) {
//定义用于合并结果的数组
int[] mergedArray = new int[leftArray.length + rightArray.length];
int mergedArrayPos = 0;
int leftArrayPos = 0;
int rightArrayPos = 0;
while (leftArrayPos < leftArray.length && rightArrayPos < rightArray.length) {
if (leftArray[leftArrayPos] <= rightArray[rightArrayPos]) {
mergedArray[mergedArrayPos] = leftArray[leftArrayPos];
leftArrayPos++;
} else {
mergedArray[mergedArrayPos] = rightArray[rightArrayPos];
rightArrayPos++;
}
mergedArrayPos++;
}
while (leftArrayPos < leftArray.length) {
mergedArray[mergedArrayPos] = leftArray[leftArrayPos];
leftArrayPos++;
mergedArrayPos++;
}
while (rightArrayPos < rightArray.length) {
mergedArray[mergedArrayPos] = rightArray[rightArrayPos];
rightArrayPos++;
mergedArrayPos++;
}
return mergedArray;
}
}Fork/Join并行归并排序
public class MergeSortTask extends RecursiveAction {
private final int threshold; //拆分的阈值,低于此阈值就不再进行拆分
private int[] arrayToSort; //要排序的数组
public MergeSortTask(final int[] arrayToSort, final int threshold) {
this.arrayToSort = arrayToSort;
this.threshold = threshold;
}
@Override
protected void compute() {
//拆分后的数组长度小于阈值,直接进行排序
if (arrayToSort.length <= threshold) {
// 调用jdk提供的排序方法
Arrays.sort(arrayToSort);
return;
}
// 对数组进行拆分
int midpoint = arrayToSort.length / 2;
int[] leftArray = Arrays.copyOfRange(arrayToSort, 0, midpoint);
int[] rightArray = Arrays.copyOfRange(arrayToSort, midpoint, arrayToSort.length);
MergeSortTask leftTask = new MergeSortTask(leftArray, threshold);
MergeSortTask rightTask = new MergeSortTask(rightArray, threshold);
//调用任务
invokeAll(leftTask, rightTask);
// 合并排序结果
arrayToSort = MergeSort.merge(leftTask.getSortedArray(),
rightTask.getSortedArray());
}
public int[] getSortedArray() {
return arrayToSort;
}
}
public class Utils {
/**
* 随机生成数组
*
* @param size 数组的大小
* @return
*/
public static int[] buildRandomIntArray(final int size) {
int[] arrayToCalculateSumOf = new int[size];
Random generator = new Random();
for (int i = 0; i < arrayToCalculateSumOf.length; i++) {
arrayToCalculateSumOf[i] = generator.nextInt(100000000);
}
return arrayToCalculateSumOf;
}
}
public class ArrayToSortMain {
public static void main(String[] args) {
//生成测试数组 用于归并排序
int[] arrayToSortByMergeSort = Utils.buildRandomIntArray(20000000);
//生成测试数组 用于forkjoin排序
int[] arrayToSortByForkJoin = Arrays.copyOf(arrayToSortByMergeSort,
arrayToSortByMergeSort.length);
//获取处理器数量
int processors = Runtime.getRuntime().availableProcessors();
MergeSort mergeSort = new MergeSort(arrayToSortByMergeSort, processors);
long startTime = System.nanoTime();
// 归并排序
mergeSort.mergeSort();
long duration = System.nanoTime() - startTime;
System.out.println("单线程归并排序时间: " + (duration / (1000f * 1000f)) + "毫秒");
//利用forkjoin排序
MergeSortTask mergeSortTask = new MergeSortTask(arrayToSortByForkJoin,
processors);
//构建forkjoin线程池
ForkJoinPool forkJoinPool = new ForkJoinPool(processors);
startTime = System.nanoTime();
//执行排序任务
forkJoinPool.invoke(mergeSortTask);
duration = System.nanoTime() - startTime;
System.out.println("forkjoin排序时间: " + (duration / (1000f * 1000f)) + "毫秒");
}
}
2.4 并行实现归并排序的优化和注意事项
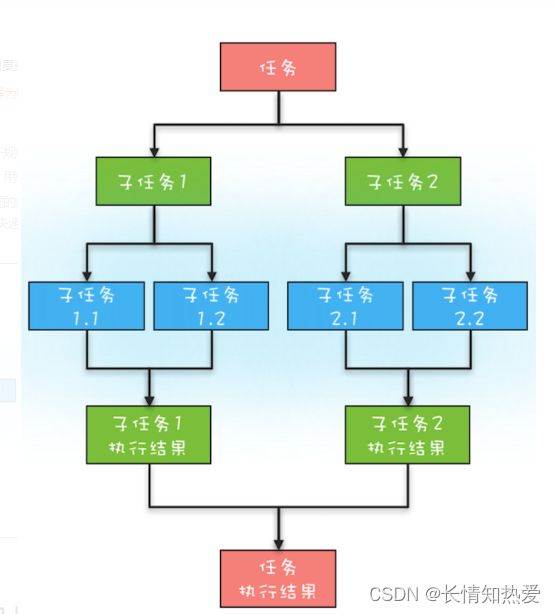
3. Fork/Join框架介绍
3.1 什么是Fork/Join

3.2 应用场景
3.3 Fork/Join使用
ForkJoinPool
构造器

//获取处理器数量
int processors = Runtime.getRuntime().availableProcessors();
//构建forkjoin线程池
ForkJoinPool forkJoinPool = new ForkJoinPool(processors);任务提交方式
任务提交是ForkJoinPool的核心能力之一,提交任务有三种方式:

和普通线程池之间的区别
工作窃取算法
ForkJoinPool采用工作窃取算法来提高线程的利用率,而普通线程池则采用任务队列来管理任务。在工作窃取算法中,当一个线程完成自己的任务后,它可以从其它线程的队列中获取一个任务来执行以此来提高线程的利用率
任务的分解和合并.
ForkJoinPool可以将一个大任务分解为多个小任务,并行地执行这些小任务,最终将它们的结果合并起来得到最终结果。而普通线程池只能按照提交的任务顺序一个一个地执行任务。
工作线程的数量
ForkJoinPool会根据当前系统的CPU核心数来自动设置工作线程的数量,以最大限度地发挥CPU的性能优势。而普通线程池需要毛动设置线程池的大小,如果设置不合理,可能会导致线程讨多成讨少从而影响程序的性能。
任务类型
ForkJoinPool适用于执行大规模任务并行化,而普通线程池适用于执行一些短小的任务,如处理请求等。
ForkJoinTask
ForkJoinTask是Fork/Join框架中的抽象类,它定义了执行任务的基本接口。用户可以通过继承ForkJoinTask类来实现自己的任务类,并重写其中的compute0方法来定义任务的执行逻辑。通常情况下我们不需要直接继承ForkJoinTask类,而只需要继承它的子类,Fork/Join框架提供了以下三人子类:
RecursiveAction: 用于递归执行但不需要返回结果的任务.
RecursiveTask: 用于递归执行需要返回结果的任务
CountedCompleter
调用方法
ForkJoinTask 最核心的是 fork0 方法和 oin0 方法,承载着主要的任务协调作用,一个用于任务提交,一个用于结果获取。
fork0提交任务
fork0方法用于向当前任务所运行的线程池中提交任务。如果当前线程ForkJoinWorkerThread类型,将会放入该线程的工作队列,否则放入common线程池的工作队列中。
join(获取任务执行结果
join0方法用于获取任务的执行结果。调用ioin(时,将阻塞当前线程直到对应的子任务完成运行并返回结果。
处理递归任务
计算斐波那契数列
public class Fibonacci extends RecursiveTask {
final int n;
Fibonacci(int n) {
this.n = n;
}
/**
* 重写RecursiveTask的compute()方法
*
* @return
*/
protected Integer compute() {
if (n <= 1)
return n;
Fibonacci f1 = new Fibonacci(n - 1);
//提交任务
f1.fork();
Fibonacci f2 = new Fibonacci(n - 2);
//合并结果
return f2.compute() + f1.join();
}
public static void main(String[] args) {
//构建forkjoin线程池
ForkJoinPool pool = new ForkJoinPool();
Fibonacci task = new Fibonacci(10);
//提交任务并一直阻塞直到任务 执行完成返回合并结果。
int result = pool.invoke(task);
System.out.println(result);
}
} 
栈溢出如何解决
我们可以使用迭代的方式计算Fibonacci数列,以避免递归过程中占用大量的栈空间。下面是一个使用 迭代方式计算Fibonacci数列的例子:
public class Fibonacci {
public static void main(String[] args) {
int n = 100000;
long[] fib = new long[n + 1];
fib[0] = 0;
fib[1] = 1;
for (int i = 2; i <= n; i++) {
fib[i] = fib[i - 1] + fib[i - 2];
}
System.out.println(fib[n]);
}
}处理递归任务注意事项
处理阻塞任务
public class BlockingTaskDemo {
public static void main(String[] args) {
//构建一个forkjoin线程池
ForkJoinPool pool = new ForkJoinPool();
//创建一个异步任务,并将其提交到ForkJoinPool中执行
CompletableFuture future = CompletableFuture.supplyAsync(() -> {
try {
// 模拟一个耗时的任务
TimeUnit.SECONDS.sleep(5);
return "Hello, world!";
} catch (InterruptedException e) {
e.printStackTrace();
return null;
}
}, pool);
try {
// 等待任务完成,并获取结果
String result = future.get();
System.out.println(result);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
} finally {
//关闭ForkJoinPool,释放资源
pool.shutdown();
}
}
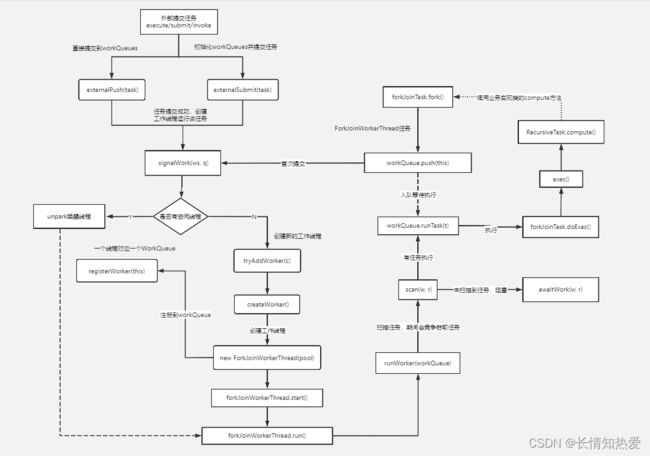
} 3.4 ForkJoinPool工作原理
工作线程ForkJoinWorkerThread

工作队列WorkQueue

ForkJoinPool的大部分操作都发生在工作窃取队列(work-stealing queues ) 中,该队列由内部 类WorkQueue实现。它是Deques的特殊形式,但仅支持三种操作方式:push、pop和poll(也称为窃取)。在ForkJoinPool中,队列的读取有着严格的约束,push和pop仅能从其所属线程调用,而poll则可以从其他线程调用。

3.5 ForkJoinPool执行流程