diffusion model (八) Dalle3 技术小结
paper:https://cdn.openai.com/papers/dall-e-3.pdf
创建时间: 2023-10-25
相关阅读
- diffusion model(一)DDPM技术小结 (denoising diffusion probabilistic)
- diffusion model(二)—— DDIM技术小结
- diffusion model(三)—— classifier guided diffusion model
- diffusion model(四)文生图diffusion model(classifier-free guided)
- diffusion model(五)stable diffusion底层原理(latent diffusion model, LDM
- diffusion model(六)Dalle2技术小结
- diffusion model(七) diffusion model是一个zero-shot 分类器
Motivation
目前的文生图模型所生成的图片很难对应prompt的一些细节的描述,并且经常会忽视某些单词。作者假设造成生成与prompt不一致的原因是因为训练样本中image caption的噪声导致。针对上述问题,作者训练了一个image-captioner对之前训练样本的caption进行重写,随后重新训练text-to-image模型。
OpenAI没有公开Dalle3的架构,这个技术报告仅包含部分data engineering的工作
Method
method部分主要阐述作者如何对公开数据集的caption进行改写。
data Recaptioning
作者认为现在的large-scale数据集有这么一个特点:图片描述基本只包含主体而忽视了背景、常识关系等更为细节的描述。作者认为,图片比较重要的细节应当包括:
- 物体存在的场景。如:在厨房的水槽(场景为厨房)、人行道上的标志
- 物体在场景的位置、物体的数量
- 物体的颜色,大小
- 图片中的文本
基于以上考虑,作者重新构建了训练样本的caption。
不妨将数据集中的图片-文本pair记作 ( t , i ) (t, i) (t,i)其中 i i i是图片, t t t是文本描述。
base captioner training
此处将image用CLIP的image encode提取图片表征,送入到image captioner模型中作为上下文,随后用Language Model的任务进行训练即可。训练数据为text-to-image的图片文本对。公式化如下:
L ( t , i ) = ∑ j log P ( t j ∣ t j − k , … , t j − 1 ; z j ; F ( i ) ; Θ ) (1) L ( t , i ) = \sum _ { j } \log P ( t _ { j } \vert t _ { j - k } , \dots , t _ { j - 1 } ; z _ { j } ; F ( i ) ; \Theta ) \tag{1} L(t,i)=j∑logP(tj∣tj−k,…,tj−1;zj;F(i);Θ)(1)
其中:
-
L ( t , i ) L(t, i) L(t,i)是目标函数
-
F ( ⋅ ) F(\cdot) F(⋅)是
CLIP的image encoder部分模型。 -
Θ \Theta Θ是模型需要训练的参数
论文没说用的什么模型,也没有描述如何将图片特征融入到image captioner模型中。
一般来说图片特征融入的方式有:
- 作为soft visual token。将图片的embedding对齐到language model的输入层,与其它文本token concat起来。
- 作为language model里面cross-attention的key, value
- 将其与language model里面self-attention的key,value进行concat。如: [ k ] → [ k , F ( i ) ] [k] \rightarrow [k, F(i)] [k]→[k,F(i)]
- …
训练完成,我们可以得到一个image caption模型。给定图片,模型会生成图片的描述。但是,该模型生成的caption依旧有上面提出的“忽视了背景、常识关系等更为细节的描述”的问题。因此需要对captioner进行进一步微调。
base captioner fine-tune
在微调阶段,同样分为两步
(一)short captioner
作者构建了一个较小的图片-文本对数据集,在这个数据集上文本仅包含对图片主体部分的描述(称为"short synthetic captions")。随后对Step1的captioner进行微调。
(二) descriptive captioner
在该阶段作者又构建了一个数据集。这个数据集的文本包含"背景、常识关系等更为细节的描述”(称为“descriptive synthetic captions”)。随后对Step1的captioner进行微调。
the validity of re-captioner
为了评估re-captioner方案的有效性。作者训练了3个text-to-image模型,效果如下图所示。
- 模型一:仅用ground-truth的caption
- 模型二:用95% “short synthetic captions”,和5%ground-truth的caption
- 模型三:用95% “descriptive synthetic captions”,和5%ground-truth的caption
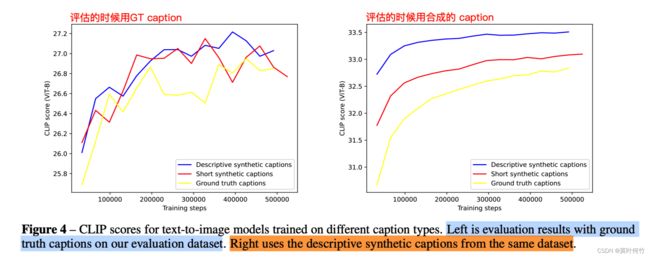
可能有读者会问为什么混合的比例是95%。作者分别进行了混合比例(65%,80%,90%,95%)的对比实验。(作者说65%的效果远低于其它,就没有放图)。

从上述的实验结果可以看出,“descriptive synthetic captions”比例越多,指标越好。但是这也带来了一个问题:
“训练数据的caption都是非常的descriptive与用户实际使用的prompt差异过大,这将导致out of domain的问题“
为了解决问题DALLE3接入了large language model(LLM)。实现方式是:用LLM来将用户的prompt进行改写使其尽可能的“descriptive”
prompt如下:
you are a part of team of bots that creates image. You work with an assistant bot that will draw anything you say in square brackets . For example , outputting "a beautiful morning in the woods with the sun peaking through the trees" will trigger your partner bot to output an image of a forest morning , as described .
You will be prompted by people looking to create detailed , amazing images. The way to accomplish this is to take their short prompts and make them extremely detailed and descriptive .
There are a few rules to follow: - You will only ever output a single image description per user request .
- Sometimes the user will request that you modify previous captions . In this case , you should refer to your previous conversations with the user and make the modifications requested .
- When modifications are requested , you should not simply make the description longer. You should refactor the entire description to integrate the suggestions .
- Other times the user will not want modifications , but instead want a new image. In this case , you should ignore your previous conversation with the user.
- Image descriptions must be between 15 -80 words. Extra words will be ignored .
{" role ": "user", " content ": "Create an imaginative image descriptive caption or modify an earlier \ caption for the user input: "a man holding a sword \""} , {" role ": " assistant ", " content ": "a pale figure with long white hair stands in the center of a dark \ forest , holding a sword high above his head.
the blade glows with a blue light , casting a soft glow on the trees and bushes surrounding him ."}, {" role ": "user", " content ": "Create an imaginative image descriptive caption or modify an earlier caption \ for the user input: "make the light red"}, {" role ": " assistant ", " content ": "a pale figure with long white hair stands in the center of a dark forest , \ holding a sword high above his head.
the blade glows with a red light , casting a warm glow on the trees and bushes surrounding him ."}, {" role ": "user", " content ": "Create an imaginative image descriptive caption or modify an earlier caption for the \ user input: "draw a frog playing dominoes "}, {" role ": " assistant ", " content ": "a frog sits on a worn table playing a game of dominoes with an elderly raccoon .
the table is covered in a green cloth , and the frog is wearing a jacket and a pair of jeans. The scene is set in a forest , with a large tree in the background ."}
Result
作者从CLIP score, Drawbench, T2I-CompBench, Human Evaluations四个方面对Dalle3和其它生成模型进行了评估。
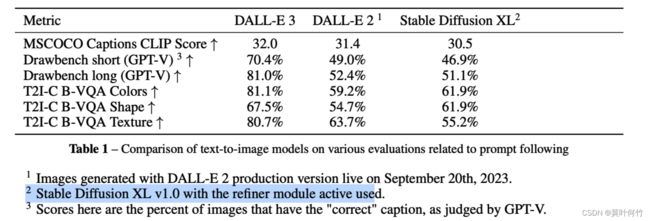
注意:Dalle3并不是在Dalle2基础上用了re-caption的方式进行微调,还加入了其它的优化,但作者没有开源。论文的指标是整体的指标。
就如原文写到:
“DALL-E 3 has many improvements over DALL-E 2, many of which are not covered in this document and could not be ablated for time and compute reasons. The evaluation metrics discussed in this document should not be construed as a performance comparison resulting from simply training on synthetic captions.”

一些生成的sample:
小结
这篇dalle3的技术报告看似写了19页,但没太多实质性的内容。OpenAI真的往close方向越走越远!有趣的是,没多久google也在arxiv发了一篇类似方案的paper《A Picture is Worth a Thousand Words: Principled Recaptioning Improves Image Generation》,还在paper里的related word注明比dalle3有更多细节:
Concurrently with our work, Dall-E 3 [25] proposes to use an automatic captioning system to regenerate the captions used to train a T2I model. Our work uses an open model (Stable Diffusion) and we provide more details and focus more on analysis and evaluation, but otherwise the main ideas are very similar.