Elasticsearch基础学习-常用查询和基本的JavaAPI操作ES
关于ES数据库的和核心倒排索引的介绍
- 一、Elasticsearch概述
-
- 简介
- 关于全文检索引擎
- 关系型数据库的全文检索功能缺点
- 全文检索的应用场景
- Elasticsearch 应用案例
- 二、Elasticsearch学习准备
-
- 安装下载
- 关于es检索的核心-倒排索引
-
- 正向索引(forward index)
- 倒排索引(inverted index)
- 三、使用kibana执行ES的操作
-
- 索引创建
- 全部索引查询
- 单个索引查询
- 删除索引
- 创建文档
- Dynamic mapping 动态映射的说明
- 指定id创建文档
- 主键查询
- GET方式全查询
- POST方式全查询(推荐)
- 全量修改
- 局部修改
- 数据删除
- 条件查询
- 全量查询并且指定字段返回
- 分页查询
- 排序查询
- 多条件查询
- 多条件范围查询
- 全文检索
- 完全匹配
- 高亮查询
- 指定高亮标签查询
- 聚合查询
- 平均值
- 四、映射关系(mapping)
-
- 创建用户索引
- 创建映射
- 查询映射
- 新增文档数据
- 数据查询
- 映射type字段text与keyword的区别
-
- 1.官方文档对于_mapping 的说明
- 2.官方文档对于keyword的说明
- 3.官方文档对于text的说明
- text与keyword总结
- 五、JavaAPI操作Elasticsearch
-
- 最新8.13版本Elasticsearch和Kibana的安装使用
-
- 下载安装
- Elasticsearch配置
- Kibana配置
- es和kibana的前台启动:
- es和kibana的后台启动
- Spring项目配置启动
-
- Maven configuration (依赖配置)
- Initialization (初始化项目)
- Java操作ES(参照官方文档)
-
- 创建索引
- 创建多个索引并同时增加文档记录
- 根据id查询文档并装载到对象中
- 根据id查询文档输出为json
- Simple search query 简单的搜索查询
- Nested search queries 嵌套搜索查询
- simple aggregation query 简单的聚合查询
- 六、框架集成-SpringData(暂缓,springdataes对于最新的es版本有问题)
-
- 6.1 SpringData整体介绍
-
- 6.1.1 SpringData框架简介
- 6.1.2 overview 官方概述
- 6.1.3 Features 特性
- 6.2 项目快速构建
-
- 6.2.1 官方快速创建项目
- 6.2.1 Maven配置
一、Elasticsearch概述
简介
Elasticsearch是一个基于lucene、分布式、通过Restful方式进行交互的近实时搜索平台框架。
ELK技术栈是Elasticsearch、Logstash、Kibana三大开元框架首字母大写简称。
而Elasticsearch 是一个开源的高扩展的分布式全文搜索引擎, 是整个 ELK技术栈的核心。
- Elasticsearch是一个基于lucene、分布式、通过Restful方式进行交互的近实时搜索平台框架。
- Logstash是中央数据流引擎,用于从不同目标(文件/数据存储/mq)收集不同格式的数据,经过过滤后支持输出到不同目的地
- Kibana可以将es的数据通过友好的页面展示出来,提供实时分析的功能
模型图

关于全文检索引擎
这里说到的全文搜索引擎指的是目前广泛应用的主流搜索引擎。它的工作原理是计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。
关系型数据库的全文检索功能缺点
首先就mysql而言,数据库用来存储文本字段本身就与关系型的思想相悖,而且全文检索时需要全表扫描,大数据量下即使对sql语句进行优化,响应时间也很难以满足需求。即使建立索引,而且是可能大量的建立索引来优化,反而维护更麻烦,insert和update每次又都会重新构建索引,反而增加了数据库的压力。
全文检索的应用场景
- 检索的数据对应是大量的非结构化的文本型数据
- 文件的记录量至少是十万以上级别
- 支持交互式文本的全文检索查询
- 对于检索结果的相关性具有较高的要求,且检索的实时性要求很高
Elasticsearch 应用案例
GitHub: 2013 年初,抛弃了 Solr,采取 Elasticsearch 来做 PB 级的搜索。 “GitHub 使用Elasticsearch 搜索 20TB 的数据,包括 13 亿文件和 1300 亿行代码”。
维基百科:启动以 Elasticsearch 为基础的核心搜索架构
百度:目前广泛使用 Elasticsearch 作为文本数据分析,采集百度所有服务器上的各类指标数据及用户自定义数据,通过对各种数据进行多维分析展示,辅助定位分析实例异常或业务层面异常。目前覆盖百度内部 20 多个业务线(包括云分析、网盟、预测、文库、直达号、钱包、 风控等),单集群最大 100 台机器, 200 个 ES 节点,每天导入 30TB+数据。
新浪:使用 Elasticsearch 分析处理 32 亿条实时日志。
阿里:使用 Elasticsearch 构建日志采集和分析体系。
二、Elasticsearch学习准备
安装下载
es安装参考:ElasticSearch下载安装和环境配置(Linux和Windows环境)
kibana安装参考:Kibana的下载与安装配置以及连接ElasticSearch测试
关于es检索的核心-倒排索引
在搜索引擎中每个文件都对应一个文件ID,文件内容被表示为一系列关键词的集合(实际上在搜索引擎索引库中,关键词也已经转换为关键词ID)。例如“文档1”经过分词,提取了20个关键词,每个关键词都会记录它在文档中的出现次数和出现位置。
正向索引(forward index)
得到正向索引的结构如下:通过key,去找value。
“文档1”的ID > 单词1:出现次数,出现位置列表;单词2:出现次数,出现位置列表;…………。
“文档2”的ID > 此文档出现的关键词列表。

正向索引的弊端:假设使用正向索引检索关键词"索引测试",那么需要扫描全库索引检索,然后根据某个权重策略进行排序返回给用户。问题就在于数据量十分庞大时的全库扫描无法满足实时的检索需求
倒排索引(inverted index)
搜索引擎会将正向索引重新建为倒排索引,即把文件ID对应到关键词的映射转换为关键词到文件ID的映射,每个关键词都对应着一系列的文件,这些文件中都出现这个关键词。
得到倒排索引的结构如下:从词的关键字,去找文档ID。
“关键词1”:“文档1”的ID,“文档2”的ID,…………。
“关键词2”:带有此关键词的文档ID列表。

三、使用kibana执行ES的操作
传统HTTP请求与kibana对于es数据库的操作对比
使用postman:PUT请求http://192.168.0.184:9200/book
kibana使用命令:PUT /books
总的来说就是kibana已经指定了es的ip和端口,只需要执行命令即可
索引创建
PUT /books
{
"acknowledged" : true, //响应结果
"shards_acknowledged" : true,//分配结果
"index" : "books"//索引名
}

全部索引查询
GET _cat/indices?v

返回字段说明:
- health 当前服务器健康状态: green(集群完整) yellow(单点正常、集群不完整) red(单点不正常)
- status 索引打开、关闭状态
- index 索引名
- uuid 索引统一编号(随机生成)
- pri 主分片数量
- rep 副本数量
- docs.count 可用文档数量
- docs.deleted 文档删除状态(逻辑删除)
- store.size 主分片和副分片整体占空间大小
- pri.store.size 主分片占空间大小
单个索引查询
GET /books

删除索引
delete /books

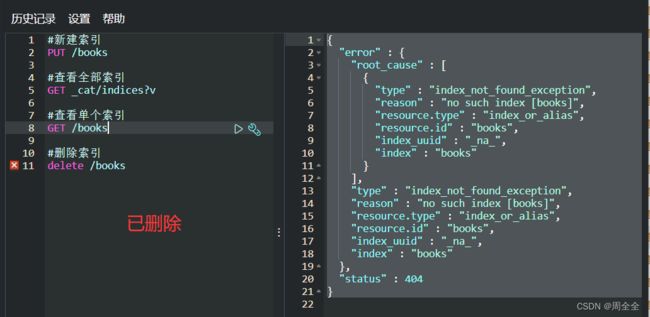
创建文档
POST /books/_doc
{
"title":"一只特立独行的喵",
"type":"纸书",
"cover":"https://img2.doubanio.com/view/subject/s/public/s1670642.jpg",
"price":25.5
}
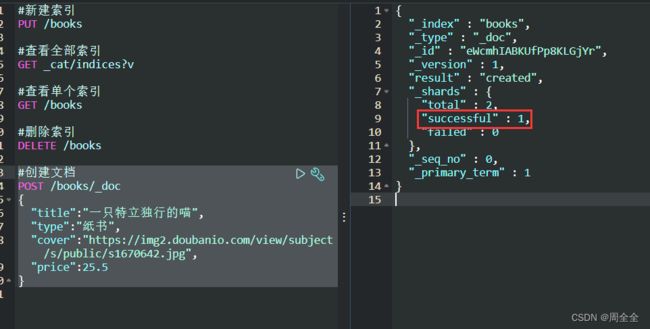
返回结果说明:
{
"_index": "shopping",//索引
"_type": "_doc",//类型-文档
"_id": "eWcmhIABKUfPp8KLGjYr",//唯一标识,可以类比为 MySQL 中的主键,随机生成也可指定
"_version": 1,//版本
"result": "created",//结果,这里的 create 表示创建成功
"_shards": {//
"total": 2,//分片 - 总数
"successful": 1,//分片 - 总数
"failed": 0//分片 - 总数
},
"_seq_no": 0,
"_primary_term": 1
}
Dynamic mapping 动态映射的说明
上一步的创建文档中,我们并未创建索引的mapping,类似于并未创建mysql中的数据表结构,但是仍然可以将数据存入数据库中。此处在官方文档的解释如下,简单来说就是es的Dynamic mapping机制允许用户在为建立mapping时,根据新增文档的字段和数据类型动态的添加新字段
Dynamic mapping allows you to experiment with and explore data when you’re just getting started.
Elasticsearch adds new fields automatically, just by indexing a document. You can add fields to the top-level mapping, and to inner object and nested fields.
动态映射允许您在刚刚开始时对数据进行实验和探索。通过索引文档,Elasticsearch 自动添加新字段。您可以向顶级映射、内部对象和嵌套字段添加字段。
Use dynamic templates to define custom mappings that are applied to dynamically added fields based on the matching condition.
使用动态模板定义应用于根据匹配条件动态添加字段的自定义映射。
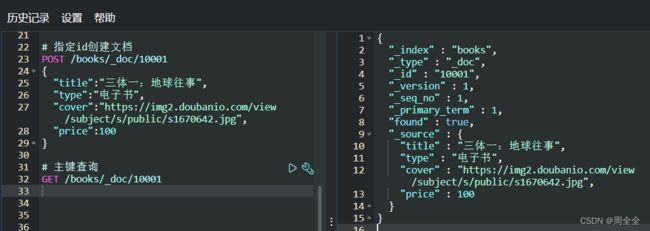
指定id创建文档
POST /books/_doc/10001
{
"title":"三体一:地球往事",
"type":"电子书",
"cover":"https://img2.doubanio.com/view/subject/s/public/s1670642.jpg",
"price":100
}

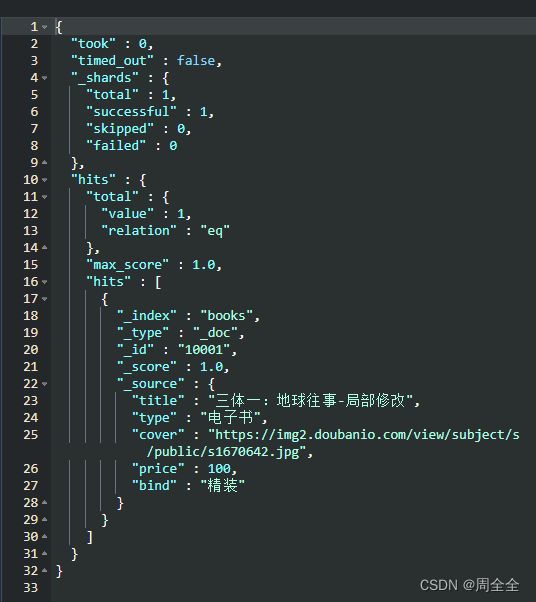
主键查询
GET /books/_doc/10001
GET方式全查询
GET /books/_doc/_search (弃用)
GET /books/_search (推荐)

POST方式全查询(推荐)
POST /books/_search
{
"query":{
"match_all":{
}
}
}

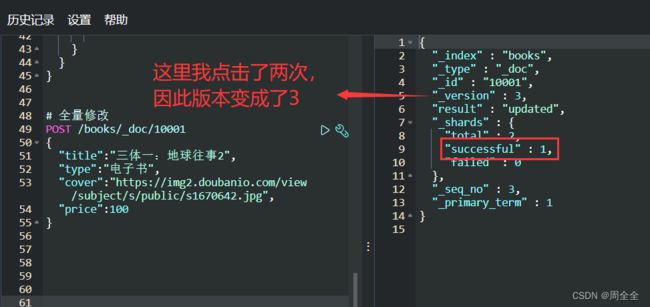
全量修改
POST /books/_doc/10001
{
"title":"三体一:地球往事2",
"type":"电子书",
"cover":"https://img2.doubanio.com/view/subject/s/public/s1670642.jpg",
"price":100
}
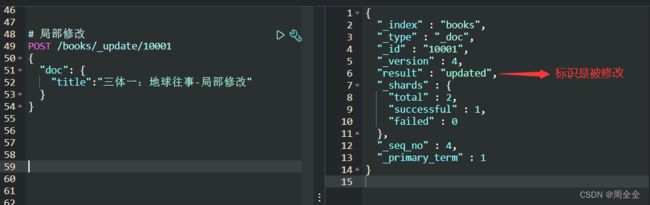
局部修改
POST /books/_update/10001
{
"doc": {
"title":"三体一:地球往事-局部修改"
}
}
数据删除
删除一个文档不会立即从磁盘上移除,它只是被标记成已删除(逻辑删除)。

条件查询
首先增加多条数据记录来作为查询数据

请求带参数查询(不推荐)
如果包含中文参数会出现乱码情况,而且暴露出来参数方式容易被攻击,类似于redis的缓存击穿问题
请求体带参查询
POST /books/_search
{
"query": {
"match": {
"price":100
}
}
}
全量查询并且指定字段返回
{
"query": {
"match_all": {
}
},
"_source":["title"]
}

分页查询
POST /books/_search
{
"query": {
"match_all": {
}
},
"from": 0,
"size": 2
}

排序查询
POST /books/_search
{
"query": {
"match_all": {
}
},
"sort": [
{
"price": { #价格降序排序
"order": "desc"
}
}
]
}

多条件查询
查询电子书并且价格为100的
POST /books/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"type": "电子书"
}
},{
"match": {
"price": "100"
}
}
]
}
}
}

多条件范围查询
查询电子书并且价格为100的
POST /books/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"type": "纸书"
}
},
{
"match": {
"type": "电子书"
}
}
],
"filter": {
"range": {
"price": {
"gte": 100
}
}
}
}
}
}

全文检索
这功能像搜索引擎那样,如title输入“三体球”,返回结果带回title有“三体”和“球”的。
POST /books/_search
{
"query": {
"match": {
"title":"三体球"
}
}
}

完全匹配
#完全匹配检索
POST /books/_search
{
"query": {
"match_phrase": {
"title":"球状闪电"
}
}
}

高亮查询
对title中的“三体”字段高亮展示
POST /books/_search
{
"query": {
"match": {
"title":"三体"
}
},
"highlight": {
"fields": {
"title": {}
}
}
}

指定高亮标签查询
对title中的“三体”字段高亮展示
{
"query": {
"match_phrase": {
"title": "三体"
}
},
"highlight": {
"pre_tags": [ #前缀
""
],
"post_tags": [ #后缀
""
],
"fields": {
"title": {} #高亮字段
}
}
}

聚合查询
聚合允许使用者对 es 文档进行统计分析,类似与关系型数据库中的 group by,当然还有很多其他的聚合,例如取最大值max、平均值avg等等。
{
"size":0,//如果加上这段会去除查询出来的原始数据
"aggs":{//聚合操作
"price_group":{//名称,自定义
"terms":{//分组
"field":"price"//分组字段
}
}
}
}

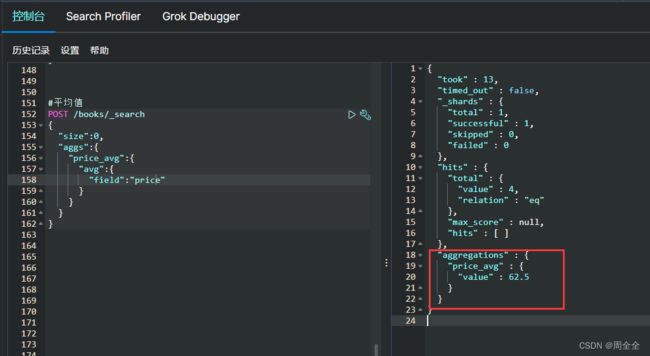
平均值
POST /books/_search
{
"size":0,
"aggs":{
"price_avg":{
"avg":{
"field":"price"
}
}
}
}
四、映射关系(mapping)
Elasticsearch是面向文档型数据库,每条数据记录就是一个文档。与关系型数据库 MySQL 存储数据类比,ES 里的 Index 可以看做一个库,而 Types 相当于表, Documents 则相当于表的行。需要注意的是这里 Types 的概念已经被逐渐弱化, Elasticsearch 6.X 中,一个 index 下已经只能包含一个type, Elasticsearch 7.X 中, Type 的概念已经被删除了。
Elasticsearch 里存储文档数据和关系型数据库 MySQL 存储数据对比关系图

由类比可知,建立了索引后就相当于mysql中的database建立,那么建立索引库(index)中的映射就是相当于mysql中建立数据库表结构
建立数据库表需要设置字段的名称,类型,长度,约束等。
建立索引库也需要知道该索引下有哪些字段类型以及字段的约束信息,这就叫做映射(mapping)。
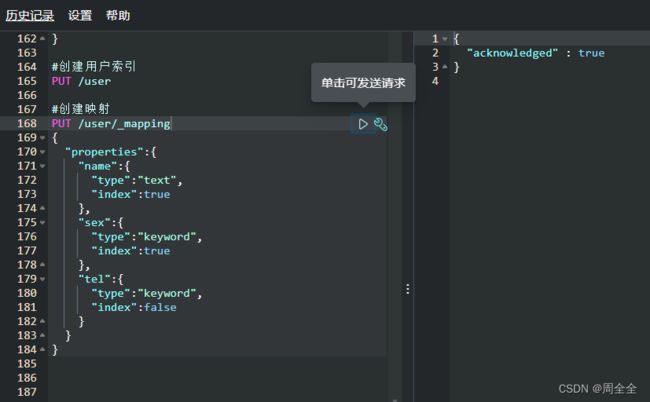
创建用户索引

创建映射
用户索引下增加name,sex,tel三个字段
PUT /user/_mapping
{
"properties":{
"name":{
"type":"text",
"index":true
},
"sex":{
"type":"keyword",
"index":true
},
"tel":{
"type":"keyword",
"index":false
}
}
}
查询映射
GET /user/_mapping

新增文档数据
PUT /user/_doc/101
{
"name":"周全",
"sex":"男生",
"tel":"15423659874"
}
数据查询
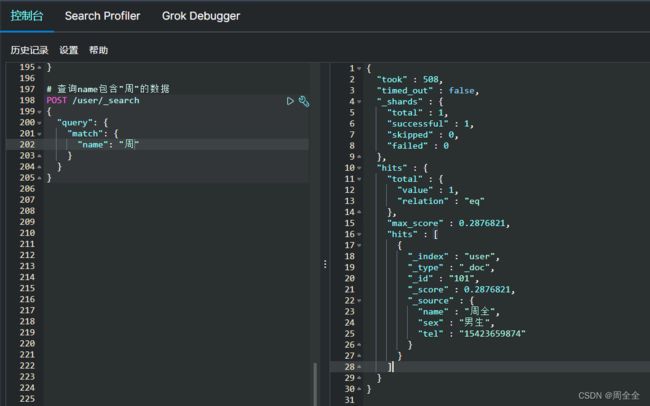
1.查询name包含"周"的数据
注意:此时的name字段的type为text,而不是keyword
POST /user/_search
{
"query": {
"match": {
"name": "周"
}
}
}
2.查询sex包含"男"的数据
由于创建映射时,“sex”的类型设置为了“keyword”,因此必须在完全匹配时才能得出匹配数据

完全匹配:

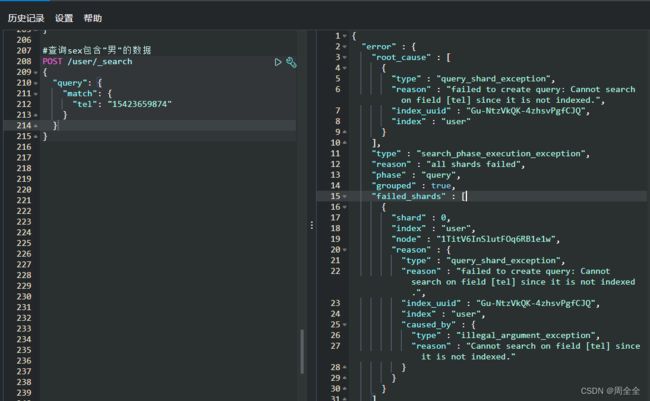
3.查询电话数据
查询失败原因:创建映射时,tel的“index”设置为了false(默认是true),因此不参与检索
"reason" : "failed to create query: Cannot search on field [tel] since it is not indexed."
映射type字段text与keyword的区别
1.官方文档对于_mapping 的说明
Explicit mapping 显式映射
Explicit mapping allows you to precisely choose how to define the mapping definition, such as:
显式映射允许您精确地选择如何定义映射定义,例如:
- Which string fields should be treated as full text fields.
应将哪些字符串字段视为全文字段 - Which fields contain numbers, dates, or geolocations.
哪些字段包含数字、日期或地理位置 - The format of date values. 日期值
- Custom rules to control the mapping for dynamically added fields
控制映射的自定义规则动态添加字段.
2.官方文档对于keyword的说明
The keyword family includes the following field types:
- keyword, which is used for structured content such as IDs, email addresses, hostnames, status codes, zip codes, or tags.
- constant_keyword for keyword fields that always contain the same value.
- wildcard for unstructured machine-generated content. The wildcard type is optimized for fields with large values or high cardinality.
大致含义:就是keyword这是用于结构化内容,如 id,电子邮件地址,主机名,对于总是包含相同值的关键字字段。
Keyword fields are often used in sorting, aggregations, and term-level queries, such as term. Avoid using keyword fields for full-text search. Use the text field type instead.
关键字字段通常用于排序、聚合和术语级查询(如 term)。避免在全文搜索中使用关键字字段。改为使用文本字段类型。
3.官方文档对于text的说明
(1) 文本系列包含字段类型
The text family includes the following field types:
- text, the traditional field type for full-text content such as the body of an email or the description of a product.
- match_only_text, a space-optimized variant of text that disables scoring and performs slower on queries that need positions. It is best suited for indexing log messages.
大意:text,传统的字段类型为全文内容,例如电子邮件正文或产品说明
(2) Text field type 文本字段类型
A field to index full-text values, such as the body of an email or the description of a product. These fields are analyzed, that is they are passed through an analyzer to convert the string into a list of individual terms before being indexed. The analysis process allows Elasticsearch to search for individual words within each full text field. Text fields are not used for sorting and seldom used for aggregations (although the significant text aggregation is a notable exception).
索引全文值的字段,如电子邮件正文或产品说明。对这些字段进行分析,即在进行索引之前通过分析器将字符串转换为单个术语的列表。分析过程允许 Elasticsearch 在每个全文字段中搜索单独的单词。文本字段不用于排序,也很少用于聚合(尽管重要的文本聚合是一个明显的例外)。
text fields are best suited for unstructured but human-readable content. If you need to index unstructured machine-generated content, see Mapping unstructured content.
文本字段最适合非结构化但可读的内容。如果需要索引非结构化机器生成的内容,请参见映射非结构化内容。
If you need to index structured content such as email addresses, hostnames, status codes, or tags, it is likely that you should rather use a keyword field.
如果你需要索引电子邮件地址、主机名、状态代码或标签等结构化内容,你可能更应该使用关键字字段。
text与keyword总结
keyword主要用于结构化内容的字段,并且总是会有相同值的字段。因为通常需要用于聚合、排序和术语级查询(如 term),所以避免参与全文检索
text字段类型用于全文内容,例如电子邮件正文或产品说明,并且es会通过分析器对字符串进行分词,可以在全文检索中搜索单独的单词。文本字段最适合非结构化但可读的内容并且不用于排序,也很少用于聚合
五、JavaAPI操作Elasticsearch
最新8.13版本Elasticsearch和Kibana的安装使用
下载安装
下载地址:https://www.elastic.co/cn/start
Elasticsearch配置
踩到的坑,由于8.1.3版本新增了几个配置参数,默认没改动,然后启动后死活连不上数据库,报错如下:
[WARN ][o.e.x.s.t.n.SecurityNetty4HttpServerTransport] [es-node0] received plaintext http traffic on an https channel, closing connection Netty4HttpChannel{localAddress=/192.168.0.184:9200, remoteAddress=/192.168.0.146:51975}
解决方案:
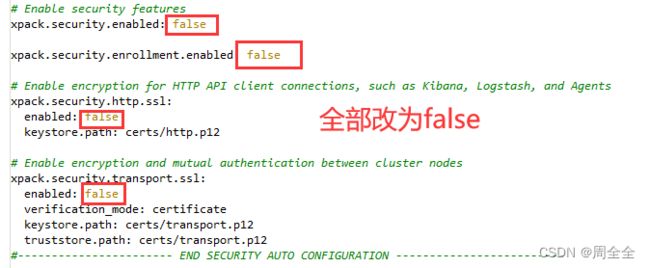
elasticsearch.yml
# Enable security features
xpack.security.enabled: false
xpack.security.enrollment.enabled: false
# Enable encryption for HTTP API client connections, such as Kibana, Logstash, and Agents
xpack.security.http.ssl:
enabled: false
keystore.path: certs/http.p12
# Enable encryption and mutual authentication between cluster nodes
xpack.security.transport.ssl:
enabled: false
verification_mode: certificate
keystore.path: certs/transport.p12
truststore.path: certs/transport.p12
#----------------------- END SECURITY AUTO CONFIGURATION -------------------------
#默认的集群名称,在集群配置多个节点时需要保持一致,单机可暂不关注
cluster.name: elasticsearch
node.name: es-node0
cluster.initial_master_nodes: ["es-node0"]
# 指定数据存储位置
path.data: /usr/local/software/elasticsearch-8.1.3/data
#日志文件位置
path.logs: /usr/local/software/elasticsearch-8.1.3/logs
#默认只允许本机访问,修改为0.0.0.0后则可以允许任何ip访问
network.host: 0.0.0.0
#设置http访问端口,9200是http协议的RESTful接口,注意端口冲突可修改
http.port: 9200
# 跨域问题配置
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-headers: Authorization,X-Requested-With,Content-Length,Content-Type
Kibana配置
kibana.yml
server.host: "192.168.0.184"
elasticsearch.hosts: ["http://192.168.0.184:9200"]
i18n.locale: "zh-CN"
es和kibana的前台启动:
注意:ctrl+c后会退出!
es和kibana的后台启动
以下脚本写完自测可以执行。
注意所属组和可执行权限问题,脚本放置与bin同级目录
es自定义后台启动与关闭脚本:
startes-single.sh
cd /usr/local/software/elasticsearch-7.6.1
./bin/elasticsearch -d -p pid
stopes-single.sh
cd /usr/local/software/elasticsearch-7.6.1
if [ -f "pid" ]; then
pkill -F pid
fi
kibanas自定义后台启动与关闭脚本
【注意:Kibana不建议使用root用户直接运行,如使用root,需加上–allow-root。建议新建普通用户,使用普通用户运行。】
(喵个咪,脚本懂得不多,还专门学了好一会子才写出来)
start-kibana.sh
#首先判断是否已经启动kibana
mypid=$(netstat -tunlp|grep 5601|awk '{print $7}'|cut -d/ -f1);
if [ -n "$mypid" ];then
echo ${mypid}" listening on port 5601,it is being killed !!!"
kill -9 $mypid
fi
echo ${mypid}" kibana is being start ..."
cd /usr/local/software/kibana-7.8.0-linux-x86_64/bin
nohup ./kibana > myout.log 2>&1 &
stop-kibana.sh
#杀死特定端口进程
mypid=$(netstat -tunlp|grep 5601|awk '{print $7}'|cut -d/ -f1);
if [ -z "$mypid" ];then
echo "No process is listening on port 5601"
fi
if [ -n "$mypid" ];then
echo ${mypid}" is being killed!!!!"
fi
kill -9 $mypid
结束脚本的语句分解:

Spring项目配置启动
Maven configuration (依赖配置)
这里配置es官方文档客户端和es库的依赖,注意版本要与es数据库的保持一致!
org.elasticsearch
elasticsearch
8.1.3
co.elastic.clients
elasticsearch-java
8.1.3
com.fasterxml.jackson.core
jackson-databind
2.12.3
jakarta.json
jakarta.json-api
2.0.1
Initialization (初始化项目)
A RestHighLevelClient instance needs a REST low-level client builder to be built as follows:
官网给出的快速使用client的示例:
// Create the low-level client
RestClient restClient = RestClient.builder(
new HttpHost("localhost", 9200)).build();
// Create the transport with a Jackson mapper
ElasticsearchTransport transport = new RestClientTransport(
restClient, new JacksonJsonpMapper());
// And create the API client
ElasticsearchClient client = new ElasticsearchClient(transport);
这里本人将RestHighLevelClient交给spring管理,在使用时直接注入即可
-
项目架构

-
配置类源码
package com.zhou.config;
import co.elastic.clients.elasticsearch.ElasticsearchClient;
import co.elastic.clients.json.jackson.JacksonJsonpMapper;
import co.elastic.clients.transport.ElasticsearchTransport;
import co.elastic.clients.transport.rest_client.RestClientTransport;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @author zhouquan
* @description ElasticSearchClient配置类
* @date 2022-05-02 17:28
**/
@Configuration
public class ElasticSearchClientConfig {
/**
* @deprecated 7.6版本的
* @return
*/
// @Bean
// public RestHighLevelClient restHighLevelClient() {
// RestHighLevelClient client = new RestHighLevelClient(
// RestClient.builder(
// new HttpHost("192.168.0.184", 9200, "http")));
//
// return client;
// }
/**
* 8.13版本
* @return
*/
@Bean
public ElasticsearchClient elasticsearchClient() {
// Create the low-level client
RestClient restClient = RestClient.builder(
new HttpHost("192.168.0.184", 9200)).build();
// Create the transport with a Jackson mapper
ElasticsearchTransport transport = new RestClientTransport(
restClient, new JacksonJsonpMapper());
// And create the API client
ElasticsearchClient client = new ElasticsearchClient(transport);
return client;
}
}
- 测试类源码
package com.zhou;
import co.elastic.clients.elasticsearch.ElasticsearchClient;
import co.elastic.clients.elasticsearch.indices.CreateIndexResponse;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import javax.annotation.Resource;
import java.io.IOException;
/**
* @author zhouquan
* @description todo
* @date 2022-05-02 10:06
**/
@SpringBootTest
public class ElasticSearchTest {
@Resource
private ElasticsearchClient client;
/**
* 创建索引
* @throws IOException
*/
@Test
void createIndex() throws IOException {
CreateIndexResponse products = client.indices().create(c -> c.index("products"));
System.out.println(products.acknowledged());
}
}
4.pojo类源码
package com.zhou.pojo;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.springframework.stereotype.Component;
import java.io.Serializable;
/**
* @author zhouquan
* @description 测试pojo类
* @date
**/
@Component
@AllArgsConstructor
@NoArgsConstructor
@Data
public class Product implements Serializable {
private String name;
private String sku;
private Double price;
}
Java操作ES(参照官方文档)
创建索引
/**
* 创建索引
*
* @throws IOException
*/
@Test
void createIndex() throws IOException {
//这种方式使用了Effective Java 中推广的构建器模式,但是必须实例化构建器类并调用 build ()方法有点冗长
CreateIndexResponse createResponse = client.indices().create(
new CreateIndexRequest.Builder()
.index("my-index")
.aliases("foo", new Alias.Builder().isWriteIndex(true).build())
.build()
);
/*(推荐)
So every property setter in the Java API Client also accepts a lambda expression
that takes a newly created builder as a parameter and returns a populated builder.
javaapi Client 中的每个属性 setter 也接受一个 lambda 表达式,
该表达式接受一个新创建的构建器作为参数,并返回一个填充的构建器
*/
CreateIndexResponse products = client.indices().create(c -> c
.index("my-index")
.aliases("zhouquan", a -> a.isWriteIndex(true))
);
System.out.println(products.acknowledged());
}

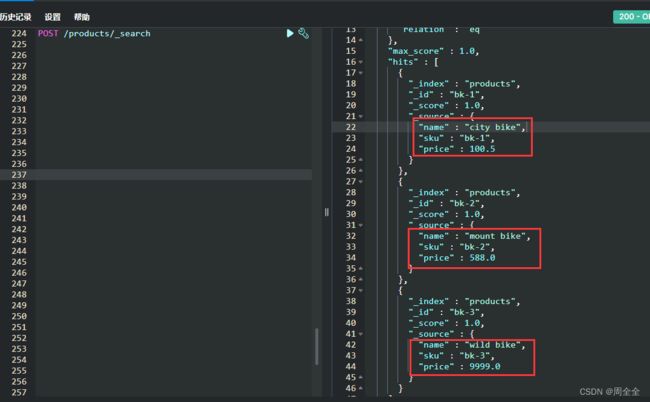
创建多个索引并同时增加文档记录
/**
* Bulk: indexing multiple documents
* 批量创建多个索引文档
*
* @throws IOException
*/
@Test
void createBulkIndex() throws IOException {
/*
A BulkRequest contains a collection of operations, each operation being a type with several variants.
To create this request, it is convenient to use a builder object for the main request,
and the fluent DSL for each operation.
BulkRequest 包含一组操作,每个操作都是一个具有多个变量的类型。
为了创建这个请求,对主请求使用 builder 对象和对每个操作使用 fluent DSL 是很方便的。
*/
List<Product> products = Arrays.asList(
new Product("city bike", "bk-1", 100.5),
new Product("mount bike", "bk-2", 588D),
new Product("wild bike", "bk-3", 9999D));
BulkRequest.Builder builder = new BulkRequest.Builder();
for (Product product : products) {
builder.operations(op -> op
.index(idx -> idx
.index("products")
.id(product.getSku())
.document(product))
);
}
BulkResponse bulkResponse = client.bulk(builder.build());
// Log errors, if any
if (bulkResponse.errors()) {
log.error("Bulk had errors");
for (BulkResponseItem item: bulkResponse.items()) {
if (item.error() != null) {
log.error(item.error().reason());
}
}
}
@Data
class Product {
public String name;
public String sku;
public Double price;
public Product(String name, String sku, Double price) {
this.name = name;
this.sku = sku;
this.price = price;
}
}
索引创建成功

数据查询
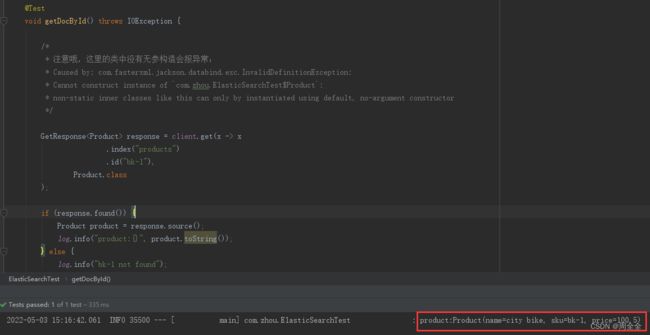
根据id查询文档并装载到对象中
/**
* Reading documents by id
* 直接根据id获取文档
*
* @throws IOException
*/
@Test
void getDocById() throws IOException {
/*
* 注意哦,这里的类中没有无参构造会报异常:
* Caused by: com.fasterxml.jackson.databind.exc.InvalidDefinitionException:
* Cannot construct instance of `com.zhou.ElasticSearchTest$Product`:
* non-static inner classes like this can only by instantiated using default, no-argument constructor
*/
GetResponse<Product> response = client.get(x -> x
.index("products")
.id("bk-1"),
Product.class
);
if (response.found()) {
Product product = response.source();
log.info("product:{}", product.toString());
} else {
log.info("bk-1 not found");
}
}
根据id查询文档输出为json
- Raw JSON data is just another class that you can use as the result type for the get request. In the example below we use Jackson’s ObjectNode. We could also have used any JSON representation that can be deserialized by the JSON mapper associated to the ElasticsearchClient.
原始 JSON 数据只是另一个类,您可以使用它作为 get 请求的结果类型。在下面的示例中,我们使用 Jackson 的 ObjectNode。我们还可以使用任何可以由与 ElasticsearchClient 关联的 JSON 映射器反序列化的 JSON 表示。
GetResponse<ObjectNode> nodeGetResponse = client.get(x -> x
.index("products")
.id("bk-1"),
ObjectNode.class
);
if (nodeGetResponse.found()) {
ObjectNode source = nodeGetResponse.source();
log.info(source.toPrettyString());
} else {
log.info("product not found");
}

Simple search query 简单的搜索查询
There are many types of search queries that can be combined. We will start with the simple text match query, searching for bikes in the products index.
有许多类型的搜索查询可以组合在一起。我们将从简单的文本匹配查询开始,在产品索引中搜索自行车。
/**
* Simple search query
* 简单的搜索查询,根据检索词匹配出所有满足条件的记录
*
* @throws IOException
*/
@Test
void searchQueryBySearchWord() throws IOException {
String searchWord = "bike";
SearchResponse<Product> productSearchResponse = client.search(s -> s
.index("products")
.query(q -> q
.match(m -> m
.field("name")
.query(searchWord)
)
),
Product.class
);
TotalHits total = productSearchResponse.hits().total();
boolean isExactResult = total.relation() == TotalHitsRelation.Eq;
if (isExactResult) {
log.info("There are " + total.value() + " results");
} else {
log.info("There are more than " + total.value() + " results");
}
//遍历查询出来的数据
productSearchResponse.hits().hits().stream().forEach(x -> log.info(x.source().toString()));
}

Nested search queries 嵌套搜索查询
Elasticsearch allows individual queries to be combined to build more complex search requests. In the example below we will search for bikes with a maximum price of 1000.
Elasticsearch 允许将单个查询组合起来,以构建更复杂的搜索请求。在下面的例子中,我们将搜索自行车的最高价格大于1000。
/**
* Nested search queries 嵌套搜索查询
* 匹配出满足name为bike且价格高于1000的数据
*
* @throws IOException
*/
@Test
void nestedQuery() throws IOException {
String searchWord = "bike";
double price = 1000D;
//全文匹配“name”字段包含检索词“bike”
Query matchQuery = MatchQuery.of(m -> m
.field("name")
.query(searchWord)
)._toQuery();
//范围匹配“price”字段大于1000
Query rangeQuery = RangeQuery.of(r -> r
.field("price")
// Elasticsearch range query accepts a large range of value types.
// We create here a JSON representation of the maximum price.
.gt(JsonData.of(price))
)._toQuery();
SearchResponse<Product> productSearchResponse = client.search(s -> s
.index("products") //Name of the index we want to search.
.query(q -> q
//The search query is a boolean query that combines the text search and max price queries.
.bool(b -> b
//Both queries are added as must as we want results to match all criteria.
.must(matchQuery, rangeQuery)
)
),
Product.class
);
TotalHits total = productSearchResponse.hits().total();
boolean isExactResult = total.relation() == TotalHitsRelation.Eq;
if (isExactResult) {
log.info("There are " + total.value() + " results");
} else {
log.info("There are more than " + total.value() + " results");
}
//遍历查询出来的数据
productSearchResponse.hits().hits().stream().forEach(x -> log.info(x.source().toString()));
}

simple aggregation query 简单的聚合查询
此处的需求为:根据名称字段与用户提供的文本匹配的产品创建一个产品索引的价格直方图
/**
* A simple aggregation 一个简单的聚合
* 匹配出满足name为bike且价格高于1000的数据
*
* @throws IOException
*/
@Test
void aggregationQuery() throws IOException {
String searchText = "bike";
Query query = MatchQuery.of(m -> m
.field("name")
.query(searchText)
)._toQuery();
SearchResponse<Void> response = client.search(b -> b
.index("products")
.size(0)/* Set the number of matching documents to zero as we only use the price histogram.
将原始数据返回设置为零,因为我们只是用价格直方图 */
.query(query)
/* Create an aggregation named "price-histogram". You can add as many named aggregations as needed.
创建一个名为“价格直方图”的聚合,可以根据需要添加任意多的命名聚合。*/
.aggregations("price-histogram", a -> a
.histogram(h -> h
.field("price")
.interval(100.0)
)
),
Void.class //We do not care about matches (size is set to zero), using Void will ignore any document in the response.
);
List<HistogramBucket> buckets = response.aggregations()
.get("price-histogram")
.histogram() //Cast it down to the histogram variant results. This has to be consistent with the aggregation definition.
.buckets().array(); //Bucket 可以表示为数组或映射,这将强制转换为数组变量(默认值)。
//遍历输出
buckets.stream().forEach(bucket -> log.info("There are " + bucket.docCount() + " bikes under " + bucket.key()));
}

六、框架集成-SpringData(暂缓,springdataes对于最新的es版本有问题)
官网:https://spring.io/projects/spring-data-elasticsearch
6.1 SpringData整体介绍
6.1.1 SpringData框架简介
Spring Data是一个用于简化数据库、非关系型数据库、索引库访问,并支持云服务的开源框架。其主要目标是使得对数据的访问变得方便快捷,并支持 map-reduce框架和云计算数据服务。Spring Data可以极大的简化JPA(Elasticsearch…)的写法,可以在几乎不用写实现的情况下,实现对数据的访问和操作。除了CRUD 外,还包括如分页、排序等一些常用的功能。
6.1.2 overview 官方概述
Spring Data for Elasticsearch is part of the umbrella Spring Data project which aims to provide a familiar and consistent Spring-based programming model for for new datastores while retaining store-specific features and capabilities.
Spring Data for Elasticsearch 是 Spring Data 项目的一部分,该项目旨在为新数据存储提供一个熟悉和一致的基于 Spring 的编程模型,同时保留存储特定的特性和功能。
The Spring Data Elasticsearch project provides integration with the Elasticsearch search engine. Key functional areas of Spring Data Elasticsearch are a POJO centric model for interacting with a Elastichsearch Documents and easily writing a Repository style data access layer.
Spring Data Elasticsearch 项目提供了与 Elasticsearch 搜索引擎的集成。Spring Data Elasticsearch 的关键功能区域是一个以 POJO 为中心的模型,用于与 elasticchsearch 文档进行交互,并轻松地编写一个类似于仓库的数据访问层。
6.1.3 Features 特性
-
Spring configuration support using Java based @Configuration classes or an XML namespace for a ES clients instances.
Spring 配置支持使用基于 Java 的@Configuration 类或者 ES 客户端实例的 XML 名称空间。
-
ElasticsearchTemplate helper class that increases productivity performing common ES operations. Includes integrated object mapping between documents and POJOs.
提高执行常见 ES 操作的效率的 ElasticsearchTemplate 帮助类。包括文档和 pojo 之间的集成对象映射。
-
Feature Rich Object Mapping integrated with Spring’s Conversion Service
集成 Spring 转换服务的特征丰富对象映射 -
Annotation based mapping metadata but extensible to support other metadata formats
基于注释的映射元数据,但可扩展以支持其他元数据格式
-
Automatic implementation of Repository interfaces including support for custom finder methods.
自动实现 Repository 接口,包括对自定义查找器方法的支持。 -
CDI support for repositories
对存储库的 CDI 支持
6.2 项目快速构建
6.2.1 官方快速创建项目
官方网站提供了快速初始化项目的功能,配置完成会自动下载项目的压缩包
解压到指定目录下

打开项目并启动

6.2.1 Maven配置
官方比较坑爹的是选择依赖的时候有些依赖并没有,因此需要自己配置即可