【NLP】spaCy笔记
目录
参考
spaCy实践
语法方面
准备工作
展示全部词例(token)
只对前10个词例(token),输出token的索引值、词元、词性等
不再考虑全部词性,只关注文本中出现的实体(entity)词汇
把一段文字拆解为语句(按.分隔)
搞清其中每一个词例(token)之间的依赖关系
语义方面
使用spaCy的词嵌入模型 查看单词对应的向量
查看spacy的语义近似度判别能力
scipy计算相似度的余弦函数
计算guess_word取值(guess_word = king - queen + woman)
用上面计算的 guess_word 取值,与字典词语逐个核对近似性,打印最近似的10个候选词
把高维度的词向量(300维)压缩到二维平面,并用TSNE可视化
参考
spaCy官方文档
如何用Python处理自然语言?(Spacy与Word Embedding)

spaCy实践
语法方面
-
准备工作
import spacy#读入Spacy软件包
from spacy.lang.en import English
nlp = spacy.load('en_core_web_sm')#让Spacy使用英语模型,将模型存储到变量nlp;注:anaconda中可以使用spacy.load('en')但pycharm中无法使用,故修改
text = "The sequel, Yes, Prime Minister, ran from 1986 to 1988. In total there were 38 episodes, of which all but one lasted half an hour. Almost all episodes ended with a variation of the title of the series spoken as the answer to a question posed by the same character, Jim Hacker. Several episodes were adapted for BBC Radio, and a stage play was produced in 2010, the latter leading to a new television series on UKTV Gold in 2013."
doc = nlp(text)#用nlp模型分析文本,将结果命名为doc;doc看似与原文本没区别,实际上spacy在后台已经进行了很多分析
-
展示全部词例(token)
#1、展示全部词例(token)
for token in doc:
print('"'+token.text+'"')#输出形式:"for",注意引号的使用-
只对前10个词例(token),输出token的索引值、词元、词性等
#2、只对前10个词例(token),输出token的索引值、词元、词性等
for token in doc[:10]:
print("{0}\t{1}\t{2}\t{3}\t{4}\t{5}\t{6}\t{7}".format(
token.text,#文本
token.idx,#索引值(即在原文中的定位)
token.lemma_,#词元
token.is_punct,#是否为标点符号
token.is_space,#是否为空格
token.shape_,
token.pos_,#词性
token.tag_#标记
))-
不再考虑全部词性,只关注文本中出现的实体(entity)词汇
#3、不再考虑全部词性,只关注文本中出现的实体(entity)词汇
for ent in doc.ents:
print(ent.text,ent.label_) spacy命名实体识别_超简例_结果
spacy命名实体识别_超简例_结果
-
把一段文字拆解为语句(按.分隔)
#4、把一段文字拆解为语句(按.分隔)
for sent in doc.sents:
print(sent)
#注意这里doc.sents并不是列表类型,而是
#假设我们需要从中筛选出某一句话,需要先将其转化为列表
doc=list(doc.sents)
print('1',doc[0])
-
搞清其中每一个词例(token)之间的依赖关系
#下面要展示的功能,分析范围局限在第一句话
#将第一句抽取出来,并且重新用nlp模型处理,存入到新的变量newdoc中
newdoc = nlp(list(doc.sents)[0].text)
#搞清其中每一个词例(token)之间的依赖关系
for token in newdoc:
print("{0}/{1} <--{2}-- {3}/{4}".format(
token.text, token.tag_, token.dep_, token.head.text, token.head.tag_))
语义方面
我们利用的工具,叫做词嵌入(word embedding)模型。
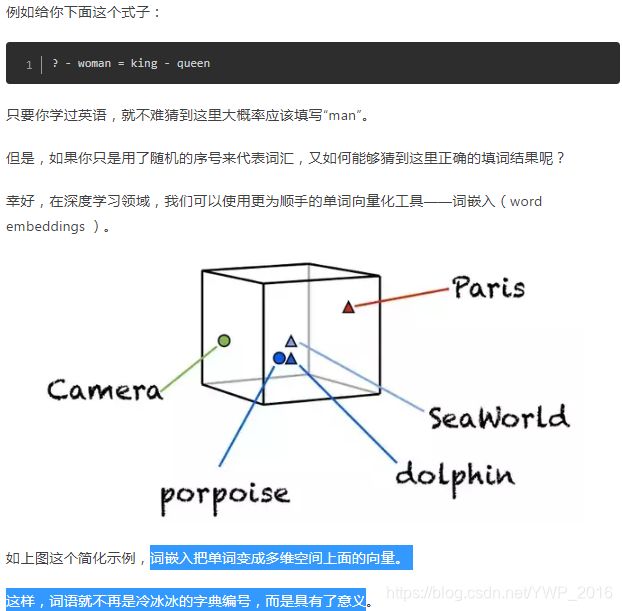 引入“词嵌入模型”的概念
引入“词嵌入模型”的概念
-
使用spaCy的词嵌入模型 查看单词对应的向量
nlp = spacy.load('en_core_web_lg')#使用词嵌入模型,我们需要Spacy读取一个新的文件
print(nlp.vocab['minister'].vector)#打印“minister”这个单词对应的向量取值
结果显示,单词用总长度为300的浮点数组成向量来表示。
Spacy读入的这个模型,是采用word2vec,在海量语料上训练的结果。
-
查看spacy的语义近似度判别能力
import spacy#读入Spacy软件包
nlp = spacy.load('en_core_web_lg')#使用词嵌入模型,我们需要Spacy读取一个新的文件
#将4个变量,赋值为对应单词的向量表达结果
dog = nlp.vocab["dog"]
cat = nlp.vocab["cat"]
apple = nlp.vocab["apple"]
orange = nlp.vocab["orange"]
#看看“狗”和“猫”/“苹果”的相似度结果
print(dog.similarity(cat))#0.80168545
print(dog.similarity(apple))#0.26339024
#看来Spacy利用词嵌入模型,对语义有了一定的理解-
scipy计算相似度的余弦函数
import spacy#读入Spacy软件包
nlp = spacy.load('en_core_web_lg')#使用词嵌入模型,我们需要Spacy读取一个新的文件
dog = nlp.vocab["dog"]
cat = nlp.vocab["cat"]
apple = nlp.vocab["apple"]
orange = nlp.vocab["orange"]
#若计算词典中可能不存在的向量,Spacy自带的similarity()函数,就显得不够用了。
#从scipy中,找到相似度计算需要用到的余弦函数
from scipy.spatial.distance import cosine
print(1-cosine(dog.vector,cat.vector))#0.8016855120658875
#除了保留几位小数外,计算结果与Spacy自带的similarity()运行结果没有差别
#我们把它做成一个小函数,专门处理向量输入
def vector_similarity(x,y):
return 1-cosine(x,y)
print(vector_similarity(dog.vector, apple.vector))#0.2633902430534363-
计算guess_word取值(guess_word = king - queen + woman)
import spacy#读入Spacy软件包
nlp = spacy.load('en_core_web_lg')#使用词嵌入模型,我们需要Spacy读取一个新的文件
#? - woman = king - queen,即guess_word = king - queen + woman
#编写下面函数,计算guess_word取值
def make_guess_word(words):
[first,second,third]=words
return nlp.vocab[first].vector - nlp.vocab[second].vector + nlp.vocab[third].vector
make_guess_word(['king','queen','woman'])
print(make_guess_word(['king','queen','woman']))#得一堆向量值
-
用上面计算的
guess_word取值,与字典词语逐个核对近似性,打印最近似的10个候选词
import spacy#读入Spacy软件包
nlp = spacy.load('en_core_web_lg')#使用词嵌入模型,我们需要Spacy读取一个新的文件
from scipy.spatial.distance import cosine
def vector_similarity(x, y):
return 1 - cosine(x, y)
#编写下面函数,计算guess_word取值
def make_guess_word(words):
[first,second,third]=words
return nlp.vocab[first].vector - nlp.vocab[second].vector + nlp.vocab[third].vector
make_guess_word(['king','queen','woman'])
def get_similar_word(words,scope=nlp.vocab):
guess_word=make_guess_word(words)
similarities=[]
for word in scope:
if not word.has_vector:
continue
similarity=vector_similarity(guess_word,word.vector)
similarities.append((word,similarity))#注意两层(),否则报错TypeError: append() takes exactly one argument (2 given)
similarities = sorted(similarities, key=lambda item: -item[1])
print([word[0].text for word in similarities[:10]])
#尝试:#? - woman = king - queen,即guess_word = king - queen + woman
words = ["king", "queen", "woman"]#输入右侧词序列
get_similar_word(words)#然后执行对比函数
#结果:['MAN', 'Man', 'mAn', 'MAn', 'MaN', 'man', 'mAN', 'WOMAN', 'womAn', 'WOman']
#尝试:? - England = Paris - London,即guess_word = Paris - London + England
words = ["Paris", "London", "England"]#把这几个单词输入
get_similar_word(words)#让Spacy来猜
#结果:['france', 'FRANCE', 'France', 'Paris', 'paris', 'PARIS', 'EUROPE', 'EUrope', 'europe', 'Europe']
-
把高维度的词向量(300维)压缩到二维平面,并用TSNE可视化
#把词向量的300维的高空间维度,压缩到一张纸(二维)上,看看词语之间的相对位置关系。
import numpy as np
import spacy
text = "The sequel, Yes, Prime Minister, ran from 1986 to 1988. In total there were 38 episodes, of which all but one lasted half an hour. Almost all episodes ended with a variation of the title of the series spoken as the answer to a question posed by the same character, Jim Hacker. Several episodes were adapted for BBC Radio, and a stage play was produced in 2010, the latter leading to a new television series on UKTV Gold in 2013."
nlp = spacy.load('en_core_web_lg')
doc = nlp(text)
embedding = np.array([])#把词嵌入矩阵先设定为空。一会儿慢慢填入
word_list = []#需要演示的单词列表,也先空着
#再次让Spacy遍历texts,加入到单词列表中。注意这次我们要进行判断:如果是标点,丢弃;如果词汇已经在词语列表中,丢弃
#即 若不是标点符号且不在词语列表,则保留
for token in doc:
if not(token.is_punct) and not (token.text in word_list):
word_list.append(token.text)
print(word_list)#注意打印内容:word_list,若打印print(word_list.append(token.text))>>>None
#把每个词汇对应的空间向量,追加到词嵌入矩阵中
for word in word_list:
embedding = np.append(embedding , nlp.vocab[word].vector)
#此时嵌入矩阵的维度为(18900,):所有向量都被放在了一个长串上面。这显然不符合我们的要求
# 我们将不同的单词对应的词向量,拆解到不同行上面去
embedding = embedding.reshape(len(word_list), -1)
print(embedding.shape) #看看此时词嵌入矩阵的维度:(63, 300)
from sklearn.manifold import TSNE #从scikit-learn软件包中,读入TSNE模块
tsne = TSNE()#建立一个同名小写的tsne,作为调用对象(tsne的作用,是把高维度的词向量(300维)压缩到二维平面上)
low_dim_embedding = tsne.fit_transform(embedding)#执行压缩转换过程,low_dim_embedding ,就是63个词汇降低到二维的向量表示
#降维后的词向量可视化
import matplotlib.pyplot as plt #绘图工具包
#下面这个函数,用来把二维向量的集合,绘制出来
def plot_with_labels(low_dim_embs, labels, filename='tsne.pdf'):
assert low_dim_embs.shape[0] >= len(labels), "More labels than embeddings"
plt.figure(figsize=(18, 18)) # in inches
for i, label in enumerate(labels):
x, y = low_dim_embs[i, :]
plt.scatter(x, y)
plt.annotate(label,
xy=(x, y),
xytext=(5, 2),
textcoords='offset points',
ha='right',
va='bottom')
plt.savefig(filename)
plot_with_labels(low_dim_embedding, word_list)
#可视化图在路径下,.pdf文件

