Object Detection 目标检测性能评价指标IoU和mAP
文章目录
-
-
- 0 引言
- 1 IoU
- 2 mAP
-
0 引言
最近学习目标检测的算法,不免碰到一些相关专业词,虽然之前学习了机器学习和深度学习的理论知识,看着熟悉,但是具体的不够清楚,因此着重学习一下mAP,IoU, NMS等知识点。
1 IoU
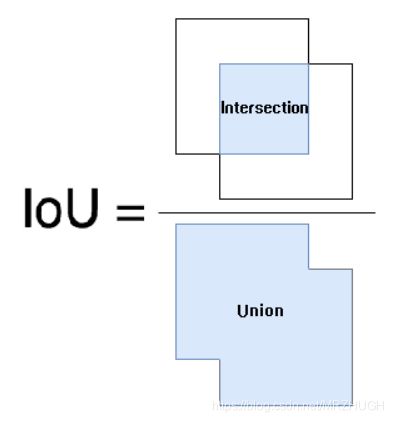
交并比IoU(Intersection-over-Union)是目标检测中使用的一个概念,是产生的候选框(candidate bound)与原标记框(ground truth bound)的交叠率(如图),即它们的交集与并集的比值。
其中,最理想的情况是完全重叠,即比值为1;
当然,相交区域越大越准确。
import numpy as np
def compute_iou(box1, box2, wh=False):
"""
compute the iou of two boxes.
Args:
box1, box2: [xmin, ymin, xmax, ymax] (wh=False) or [xcenter, ycenter, w, h] (wh=True)
wh: the format of coordinate.
Return:
iou: iou of box1 and box2.
"""
if wh == False:
xmin1, ymin1, xmax1, ymax1 = box1
xmin2, ymin2, xmax2, ymax2 = box2
else:
xmin1, ymin1 = int(box1[0]-box1[2]/2.0), int(box1[1]-box1[3]/2.0)
xmax1, ymax1 = int(box1[0]+box1[2]/2.0), int(box1[1]+box1[3]/2.0)
xmin2, ymin2 = int(box2[0]-box2[2]/2.0), int(box2[1]-box2[3]/2.0)
xmax2, ymax2 = int(box2[0]+box2[2]/2.0), int(box2[1]+box2[3]/2.0)
# 获取矩形框交集对应的左上角和右下角的坐标(intersection)
xx1 = np.max([xmin1, xmin2])
yy1 = np.max([ymin1, ymin2])
xx2 = np.min([xmax1, xmax2])
yy2 = np.min([ymax1, ymax2])
# 计算两个矩形框面积
area1 = (xmax1-xmin1) * (ymax1-ymin1)
area2 = (xmax2-xmin2) * (ymax2-ymin2)
inter_area = (np.max([0, xx2-xx1])) * (np.max([0, yy2-yy1])) # 计算交集面积
iou = inter_area / (area1+area2-inter_area+1e-6) # 计算交并比
return iou
2 mAP
mAP(mean Average Precision)是衡量算法的准确率的指标,要理解mAP先要理解AP,而理解AP涉及到Precision(准确率/查准率)和Recall(召回率/查全率)。而准确率和召回率的公式计算涉及到常见的TP,FP,FN,TN,下表可以先简单的了解。
| 术语 | 含义 |
|---|---|
| TP(True positives) | 被正确地划分为正例的个数,即实际为正例且被分类器划分为正例的实例数 |
| FP(False positives) | 被错误地划分为正例的个数,即实际为负例但被分类器划分为正例的实例数 |
| FN(False negatives) | 被错误地划分为负例的个数,即实际为正例但被分类器划分为负例的实例数 |
| TN(True negatives) | 被正确地划分为负例的个数,即实际为负例且被分类器划分为负例的实例数 |
| Precision | 衡量在所有预测为真的预测中,正确预测的比例 |
| Recall | 衡量在所有正确的预测中,预测为真的比例 |
它们之间的关系,用公式表示一目了然:
P r e c i s i o n = T P ( T P + F P ) Precision=\frac{TP}{(TP+FP)} Precision=(TP+FP)TP
R e c a l l = T P ( T P + F N ) Recall=\frac{TP}{(TP+FN)} Recall=(TP+FN)TP
现在就理清了,要想求mAP,最应该先求的是TP,FP,FN:
- TP: I o U > 0.5 IoU>0.5 IoU>0.5的检测框数量(注:同一个GT(Ground Truth)只计算一次)
- FP: I o U ≤ 0.5 IoU\le0.5 IoU≤0.5的检测框数量,或检测到同一个GT的多余检测框数量、
- FN:没有检测到GT的数量
然后针对数据集中每一张图片,需要求出这张图片在这一类别中的P和R,进而求AP的话,针对数据集中某一个类别,就是PR曲线(Precision-Recall曲线)下的面积;最后再求mAP,针对整个数据集而言,即各类别AP的平均值。
特别注意:
因为mAP是数据集中所有类别AP值的平均,所以要计算mAP,首先得确定某一类别的AP值怎么求?而不同数据集的某类别的AP计算方法大同小异,主要分为三种:
- 在VOC2010以前,只需要选取当 R e c a l l > = 0 , 0.1 , 0.2 , . . . , 1 Recall >= 0, 0.1, 0.2, ..., 1 Recall>=0,0.1,0.2,...,1共11个点时的Precision最大值,然后AP就是这11个Precision的平均值,mAP就是所有类别AP值的平均。
- 在VOC2010及以后,需要针对每一个不同的Recall值(包括0和1),选取其大于等于这些Recall值时的Precision最大值,然后计算PR曲线下面积作为AP值,mAP就是所有类别AP值的平均。
- COCO数据集,设定多个IoU阈值(0.5-0.95,0.05为步长),在每一个IoU阈值下都有某一类别的AP值,然后求不同IoU阈值下的AP平均,就是所求的最终的某类别的AP值。
补充:
这里求mAP,并没有用到TN,其实在求常见的评价指标-正确率(accuracy)会用到TN,就是被分对的样本数除以所有的样本数,通常来说,正确率越高,分类器越好。
a c c u r a c y = ( F P + T N ) P + N accuracy=\frac{(FP+TN)}{P+N} accuracy=P+N(FP+TN)
顺便补充:错误率(error rate)与正确率相反,描述被分类错分的比例,两者互斥,故error rate = 1 - accuracy。
e r r o r _ r a t e = ( F P + F N ) P + N error\_rate = \frac{(FP+FN)}{P+N} error_rate=P+N(FP+FN)
灵敏度(sensitive):表示的是所有正例中被分对的比例,衡量了分类器对正例的识别能力。
s e n s i t i v e = T P P sensitive=\frac{TP}{P} sensitive=PTP
特效度(specificity):表示的是所有负例中被分对的比例,衡量了分类器对负例的识别能力。
s p e c i f i c i t y = T N N specificity=\frac{TN}{N} specificity=NTN
参考:
- https://blog.csdn.net/sinat_34474705/article/details/80045294