我们在前面两章中就已经说明了事务问题、分库策略、分库数量、迁移、框架选型,本文主要讲述分库数量、主键、排序、分页join的问题。
目的
- 多少行数据记录开始做分库分表
- 解决主键生成策略
- 解决排序、分页join
- 领域表设计
分库数量
1. 量级
分库数量首先和单库能处理的记录数有关,一般来说,Mysql 单库超过5000万条记录,Oracle单库超过1亿条记录,DB压力就很大。个人希望在500万~1000万时进行分库。
2. 硬件
在满足上述前提下,如果分库数量少,达不到分散存储和减轻DB性能压力的目的;如果分库的数量多,好处是每个库记录少,单库访问性能好,但对于跨多个库的访问,应用程序需要访问多个库,如果是并发模式,要消耗宝贵的线程资源;如果是串行模式,执行时间会急剧增加。
分库数量还直接影响硬件的投入,一般每个分库跑在单独物理机上,多一个库意味多一台设备。所以具体分多少个库,要综合评估,一般初次分库建议分4-8个库。
3. DDL
考虑是否会加字段,试过在表数据量在6000万的时候,mysql加一个字段就花了一两个小时。我还是建议在1000万的时候就要预备了,因为数据量增长会很快的,当然我们要鉴于自身系统的增长速度。
对一个很大的表进行DDL修改时,MySQL会锁住全表,这个时间会很长,这段时间业务不能访问此表,影响很大。在此操作过程中,都算为风险时间。将数据表拆分,总量减少,有助于降低这个风险。
主键生成策略
因为分库分表的情况下,对于订单号、userId不能使用自增的形式,最好在未分库分表前,做好订单号的规则,不使用uuid,因为会带字母。下面介绍雪花算法和算法的变体。实现还是推荐使用redis保证分布式唯一吧。
1.雪花算法
雪花算法解析 结构 snowflake的结构如下(每部分用-分开):
| 时间戳 | 机器id | 12bit流水号 |
|---|---|---|
| 0 - 0000000000 0000000000 0000000000 0000000000 0 | 00000 - 00000 | 000000000000 |
上面每个位的值为0/1
其核心思想是:
第一bit为未使用,接下来的41 bit为毫秒级时间(41位的长度可以使用69年),
然后是5bit datacenterId和5bit workerId(10位的长度最多支持部署1024个节点) ,
最后12bit 是毫秒内的计数(12位的计数顺序号支持每个节点每毫秒产生4096个ID序号)
一共加起来刚好64 bit,为一个Long型。(转换成字符串长度为18)。
2.自定义生成规则
大多数的号都用上述方法即可,只是其中一些场景会特殊规则,如放款/还款的支付流水号。
为了用于便于人为阅读,如财务核算时需要阅读流水号,导出数据进金蝶软件的场景,用于适应金蝶软件导入规则。
下述这种就太长了,只能用String存储,因为Long最大值为2^63-1=9223372036854775807。这个是个20位数字。
| 业务类型2位数 | 年月日时分秒毫秒 | 机器id | 计数位4位数 | 父级id的hash值 |
|---|---|---|---|---|
| 01 | 20190901 01 01 01 111 | 00000 | 1234 | 4831 |
第一节 两位是用于表示业务类型,足够一个系统有99个业务类型,如01表示用户还款,02表示用户借款。如果更多业务类型,可能该考虑拆系统,如果真的不够可以写3位。当然这个不是必要,第一节只是用来容易人为识别。
第二节 是时间,像支付宝支付的流水号就是有带时间的,这样用户或者客服可以直观看出这个单是什么时候生成,排查问题也比较方便
第三节 是机器id,由代码获取ip,然后自定义算法,生成一个5位数,记得不要写真实ip,不然就会被所有人发现了。
第四节 是计数位,表示同一个ip下在同一个毫秒下,可以有9999次计数
共28位,已经超出long的最大值,所以存String类型。
额外第五节
有些公司会有第五节,第五节 是父级id的hash值,意思是假如这个是还款支付流水号,最后四位可以是userId的hash值。
这样做是有原因的,最后4位可以方便的根据支付流水号定位到物理表坐标。因为如果这个是支付流水号,假如这个支付流水号只有前面四节,根据上一章的第四、五方案一致性hash,根据会算出分库和分表的所在位置。但是这样就不方便开发、运维人为上mysql server找到数据。所以会填上userId的hash值(如 id mode 64)作为第五节的前两位表示分库位置,userId / 64 mod 64作为分表坐标。
例如 用户id % 64 取余 最多可以分64张表,而目前可能用不到这么多,每相邻4个数字分配到一张表,共16张表,既 userID % 64 / 4 * 4 ,而这个地方存储 userID % 64 即可,不必存最终分表的结果(这个算法设计请阅读第一章)。
但是我认为第五节不是很合理,这种方式不方便后续做扩容,mod 64 可能不足以支撑业务时,可能要分128片(mod 128)的时候,可能分表的规则变更了,但是订单号已无法进行变更,这些订单号也不能去update,已经给财务那边做核算了。
所以我认为最好不与其他的相关联。
跨节点查询
包括跨节点Join、count,order by,group by以及聚合函数问题、跨分片的排序分页,其实分库后都没办法连表、join查询的,因为对两个数据库操作都是创建两个tcp连接,两个tcp连接之间是不会通信,所以只能查询出数据后,再程序中给两个数据库查出来的数据做聚合的代码操作。
以分页来举例
一般来讲,分页时需要按照指定字段进行排序。当排序字段就是分片字段的时候,我们通过分片规则可以比较容易定位到指定的分片,而当排序字段非分片字段的时候,如不是用户表的用户的userId,情况就会变得比较复杂了。
为了最终结果的准确性,我们需要在不同的分片节点中将数据进行排序并返回,并将不同分片返回的结果集进行汇总和再次排序,最后再返回给用户。如下图所示:

上面图中所描述的只是最简单的一种情况(取第一页数据),看起来对性能的影响并不大。但是,如果想取出第10页数据,情况又将变得复杂很多,如下图所示:
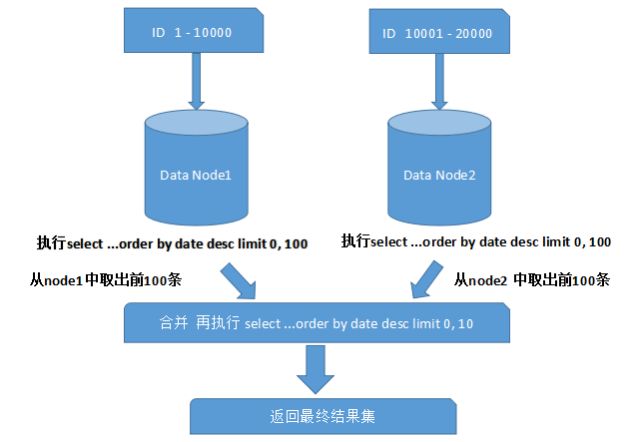
有些读者可能并不太理解,为什么不能像获取第一页数据那样简单处理(排序取出前10条再合并、排序)。其实并不难理解,因为各分片节点中的数据可能是随机的,为了排序的准确性,必须把所有分片节点的前N页数据都排序好后做合并,最后再进行整体的排序。很显然,这样的操作是比较消耗资源的,用户越往后翻页,系统性能将会越差。
那如何解决分库情况下的分页问题呢?有以下几种办法:
如果是在前台应用提供分页,则限定用户只能看前面n页,这个限制在业务上也是合理的,一般看后面的分页意义不大(如果一定要看,可以要求用户缩小范围重新查询)。
如果是后台批处理任务要求分批获取数据,则可以加大page size,比如每次获取5000条记录,有效减少分页数(当然离线访问一般走备库,避免冲击主库)。
分库设计时,一般还有配套大数据平台汇总所有分库的记录,有些分页查询可以考虑走大数据平台。
Join
如同分页一样,没有办法两个库之间join查询,只能通过两次查询后,在程序中进行聚合,或者先做一个表的查询,把得出的结果作为第二个表的查询条件。
尽量通过数据冗余或表分组来降低跨库 Join 的可能。
领域表设计
在开发过程中,尽量使用利用领域驱动,按照数据关联性划分数据模型,把关联度高度绑定在一起,在项目初期很有可能几个领域都在一个数据库中,如划分好用户模块、订单模块等。
因为用户主表和用户明细表会经常一起查询,这两个表都用一个字段作为分库分表作为Key,用户的主表和明细表都在一个库中。这样就可以减少Join和关联查询、分页查询等。
订单表可以用userId和订单id两个字段作为分库分表的Key,以后可以不用与用户表放在一个库。
2019-09-29
欢迎关注
我的公众号 :地藏思维
掘金:地藏Kelvin
:地藏Kelvin
CSDN:地藏Kelvin
我的Gitee: 地藏Kelvin https://gitee.com/dizang-kelvin