梯度下降算法_批量梯度下降(BGD)、随机梯度下降(SGD)、小批量梯度下降(MBGD)

梯度下降法作为机器学习中较常使用的优化算法,其有着3种不同的形式:批量梯度下降(Batch Gradient Descent)、随机梯度下降(Stochastic Gradient Descent)、小批量梯度下降(Mini-Batch Gradient Descent)。其中小批量梯度下降法也常用在深度学习中进行模型的训练。接下来,我们将对这3种不同的梯度下降法进行理解。
1. 批量梯度下降(Batch Gradient Descent,BGD)
使用整个训练集的优化算法被称为批量(batch)或确定性(deterministic)梯度算法,因为它们会在一个大批量中同时处理所有样本。
批量梯度下降法是最原始的形式,它是指在每一次迭代时使用所有样本来进行梯度的更新。具体的算法可以参考我之前的文章——温故知新——梯度下降。
优点:
(1)在训练过程中,使用固定的学习率,不必担心学习率衰退现象的出现。
(2)由全数据集确定的方向能够更好地代表样本总体,从而更准确地朝向极值所在的方向。当目标函数为凸函数时,一定能收敛到全局最小值,如果目标函数非凸则收敛到局部最小值。
(3)它对梯度的估计是无偏的。样例越多,标准差越低。
(4)一次迭代是对所有样本进行计算,此时利用向量化进行操作,实现了并行。
缺点:
(1)尽管在计算过程中,使用了向量化计算,但是遍历全部样本仍需要大量时间,尤其是当数据集很大时(几百万甚至上亿),就有点力不从心了。
(2)每次的更新都是在遍历全部样例之后发生的,这时才会发现一些例子可能是多余的且对参数更新没有太大的作用。
从迭代的次数上来看,BGD迭代的次数相对较少。其迭代的收敛曲线示意图可以表示如下:
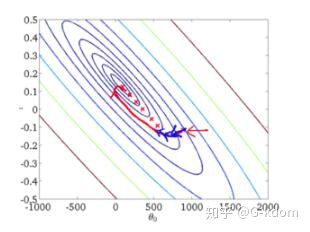
2. 随机梯度下降(Stochastic Gradient Descent,SGD)
随机梯度下降法不同于批量梯度下降,随机梯度下降是在每次迭代时使用一个样本来对参数进行更新(mini-batch size =1)。
对于一个样本的损失函数为:

计算损失函数的梯度:

参数更新为:
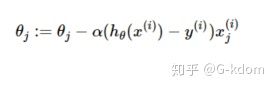
优点:
(1)在学习过程中加入了噪声,提高了泛化误差。
(2)由于不是在全部训练数据上的损失函数,而是在每轮迭代中,随机优化某一条训练数据上的损失函数,这样每一轮参数的更新速度大大加快。
缺点:
(1)不收敛,在最小值附近波动。
(2)不能在一个样本中使用向量化计算,学习过程变得很慢。
(3)单个样本并不能代表全体样本的趋势。
(4)当遇到局部极小值或鞍点时,SGD会卡在梯度为0处。
从迭代的次数上来看,SGD迭代的次数较多,在解空间的搜索过程看起来很盲目。其迭代的收敛曲线示意图可以表示如下:
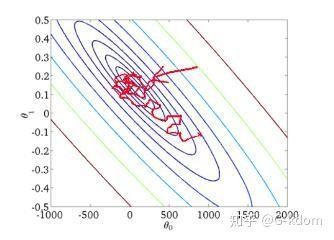
("拿小本本get下面的重点内容")
3. 小批量梯度下降(Mini-batch Gradient Descent,MBGD)
大多数用于深度学习的梯度下降算法介于以上两者之间,使用一个以上而又不是全部的训练样本。传统上,这些会被称为小批量(mini-batch)或小批量随机(mini-batch stochastic)方法,现在通常将它们简单地成为随机(stochastic)方法。对于深度学习模型而言,人们所说的“随机梯度下降, SGD”,其实就是基于小批量(mini-batch)的随机梯度下降。
什么是小批量梯度下降?具体的说:在算法的每一步,我们从具有

计算损失函数的梯度:

参数更新:
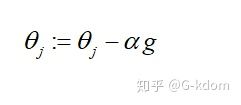
mini-batch的SGD算法中一个关键参数是学习率。在实践中,有必要随着时间的推移逐渐降低学习率—学习率衰减(learning rate decay)。
为什么要进行学习率衰减呢?
在梯度下降初期,能接受较大的步长(学习率),以较快的速度进行梯度下降。当收敛时,我们希望步长小一点,并且在最小值附近小幅摆动。假设模型已经接近梯度较小的区域,若保持原来的学习率,只能在最优点附近徘徊。如果降低学习率,目标函数能够进一步降低,有助于算法的收敛,更容易接近最优解。
常用的学习率衰减的方法:

其中
小批量大小(mini-batch size)通常由以下几个因素决定:(引自“AI圣经—花书”)
(1)更大的批量会计算更精确的梯度,但是回报却是小于线性的。
(2)极小的批量通常难以充分利用多核结构。当批量低于某个数值时,计算时间不会减少。
(3)批量处理中的所有样本可以并行处理,内存消耗和批量大小会成正比。对于很多硬件设备,这是批量大小的限制因素。
(4)在使用GPU时,通常使用2的幂数作为批量大小可以获得更少的运行时间。一般,2的幂数取值范围是32~256。16有时在尝试大模型时使用。
在一定范围内,一般来说 Batch_Size 越大,其确定的下降方向越准,引起训练震荡越小。跑完一次 epoch(全数据集)所需的迭代次数减少,对于相同数据量的处理速度进一步加快,但是要想达到相同的精度,其所花费的时间大大增加了,从而对参数的修正也就显得更加缓慢。当Batch_Size 增大到一定程度,其确定的下降方向已经基本不再变化,也可能会超出内存容量。
优点:
(1)计算速度比Batch Gradient Descent快,因为只遍历部分样例就可执行更新。
(2)随机选择样例有利于避免重复多余的样例和对参数更新较少贡献的样例。
(3)每次使用一个batch可以大大减小收敛所需要的迭代次数,同时可以使收敛到的结果更加接近梯度下降的效果。
缺点:
(1)在迭代的过程中,因为噪音的存在,学习过程会出现波动。因此,它在最小值的区域徘徊,不会收敛。
(2)学习过程会有更多的振荡,为更接近最小值,需要增加学习率衰减项,以降低学习率,避免过度振荡。
(3)batch_size的不当选择可能会带来一些问题。
下图显示了以上三种梯度下降算法的收敛过程:
