- 数据结构奇妙旅程之深入解析快速排序
山间漫步人生路
数据结构排序算法算法
快速排序(QuickSort)是一种高效的排序算法,它使用了分治法的策略来将一个数组排序。其基本思想是选择一个基准元素,通过一趟排序将待排序的数据分割成独立的两部分,其中一部分的所有数据都比基准元素小,另一部分的所有数据都比基准元素大,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。工作原理选择基准:从待排序的序列中选一个元素作为基准(pivo
- php 把一个数组分成有n个元素的二维数组的算法
风清扬-独孤九剑
phpphp算法
一、第一种解法0){$columns_map[$position]++;//这个地方格外注意,$position与$columns比较$position=($position<$columns-1)?++$position:0;$array_length--;}foreach($columns_mapas$val){$newarray[]=array_splice($array,0,$val);}
- 【算法分析与设计】去除重复字母
五敷有你
算法分析与设计javajavascript开发语言算法数据结构
个人主页:五敷有你系列专栏:算法分析与设计⛺️稳中求进,晒太阳题目给你一个字符串s,请你去除字符串中重复的字母,使得每个字母只出现一次。需保证返回结果的字典序最小(要求不能打乱其他字符的相对位置)。示例示例1:输入:s="bcabc"输出:"abc"示例2:输入:s="cbacdcbc"输出:"acdb"思路贪心+单调栈实现【字符串删除一个字符使其字典序最小的贪心策略】:对于两个长度相同的字符串,
- v-for 实例
琪33
v-for实例v-for实例{{item}}{{index+1}}:{{student.name}}-{{student.age}}varapp=newVue({el:'#app',data:{items:[53,23,76,14,54,36,28],students:[{name:'jspang',age:32},{name:'Panda',age:30},{name:'PanPaN',age:
- 用XMLHttpRequest发送和接收JSON数据
潭池先生
jsonXMLHttpRequest前端
百度的AI回答了一个案例:varxhr=newXMLHttpRequest();varurl="your_endpoint_url";//替换为你的API端点vardata=JSON.stringify({key1:"value1",key2:"value2"});xhr.open("POST",url,true);xhr.setRequestHeader("Content-Type","appl
- helm 部署 Kube-Prometheus + Grafana + 钉钉告警部署 Kube-Prometheus
zxj19880502
grafanaprometheus
背景角色IPK8S版本容器运行时k8s-master-1172.16.16.108v1.24.1containerd://1.6.8k8s-node-1172.16.16.109v1.24.1containerd://1.6.8k8s-node-2172.16.16.110v1.24.1containerd://1.6.8安装kube-prometheusmkdir-p/data/yaml/kub
- yarn的安装和使用全网最详细教程
zxj19880502
yarnnpm
一、yarn的简介:Yarn是facebook发布的一款取代npm的包管理工具。二、yarn的特点:速度超快。Yarn缓存了每个下载过的包,所以再次使用时无需重复下载。同时利用并行下载以最大化资源利用率,因此安装速度更快。超级安全。在执行代码之前,Yarn会通过算法校验每个安装包的完整性。超级可靠。使用详细、简洁的锁文件格式和明确的安装算法,Yarn能够保证在不同系统上无差异的工作。三、yarn的
- 图论记录之最短路迪杰斯特拉
Just right
算法图论java开发语言
简述思想这个思想能用一句话来概括,精简到的极致:每次找到一个最短距离的点并更新起点到各个点的最短距离如果要可视化的话,B站搜索Dijksra算法,有视频讲解伪代码写到这里,其实是想整一个动画的,这样效果更好点,但由于种种原因所以就拖一下intdijkstr(){dist[1]=0;其余的点的距离全部初始化为真无穷,不要写成int的最大值迭代n次将不在s中的,且距离最近的点给tsj即先到t,再加上t
- 大创项目推荐 深度学习 opencv python 公式识别(图像识别 机器视觉)
laafeer
python
文章目录0前言1课题说明2效果展示3具体实现4关键代码实现5算法综合效果6最后0前言优质竞赛项目系列,今天要分享的是基于深度学习的数学公式识别算法实现该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!学长这里给一个题目综合评分(每项满分5分)难度系数:3分工作量:4分创新点:4分更多资料,项目分享:https://gitee.com/dancheng-senior/postgraduate1课题
- vue 通信方式
hx_1199
vue.js前端
1、props和$emit父组件向子组件传递数据是通过props传递的,子组件传递给父组件是通过$emit触发事件来做到的。父组件this.$emit("update:page",newVal)-->importChildfrom'./child'exportdefault{name:"Father",components:{Child,},data(){return{articleList:['
- 排序算法太多?常用排序都在这了,一篇文章总结和实现所有面试会考的排序算法(基于Python实现)
宇宙之一粟
不归路之Python#IT面试题收集与总结数据结构与算法算法数据结构排序算法pythonjava
文章目录排序算法1.常见的排序算法1.1选择排序1.1.1思想1.1.2实现**1.1.3选择排序分析**1.2冒泡排序**1.2.1思想****1.2.2实现****1.2.3冒泡排序分析**1.3插入排序**1.3.1思想****1.3.2实现****1.3.3插入排序分析**1.4归并排序☆☆★**1.4.1思想****1.4.2实现****1.4.3归并排序分析**1.5快速排序☆★★**
- 【数据结构】实验一 实现顺序表各种基本运算的算法
张鱼·小丸子
数据结构实验c++数据结构
题目:实现顺序表各种基本运算的算法要求:1、建立一个顺序表,输入n个元素并输出;2、查找线性表中的最大元素并输出;3、在线性表的第i个元素前插入一个正整数x;4、删除线性表中的第j个元素;5、将线性表中的元素按升序排列;6、将线性表中的元素就地逆序(只允许用一个暂存单元);#include#defineSIZE1000usingnamespacestd;typedefstruct{int*a;//
- python清华大学出版社答案_Python机器学习及实践
weixin_39805119
python清华大学出版社答案
第1章机器学习的基础知识1.1何谓机器学习1.1.1传感器和海量数据1.1.2机器学习的重要性1.1.3机器学习的表现1.1.4机器学习的主要任务1.1.5选择合适的算法1.1.6机器学习程序的步骤1.2综合分类1.3推荐系统和深度学习1.3.1推荐系统1.3.2深度学习1.4何为Python1.4.1使用Python软件的由来1.4.2为什么使用Python1.4.3Python设计定位1.4.
- Numpy、Pandas库的使用
貮叁
量化投资分析pythonpython数据分析
目录Numpy1、概述2、基础操作2.1生成一个numpy的array数组:2.2自定义一个新的数据类型:np.dtype()3、并行化思想4、量化分析应用4.1索引选取和切片选择4.2数据转换与规整4.3逻辑条件进行数据筛选4.4通用序列函数4.5文件保存与读取Pandas1、简介2、Series和DataFrame的使用2.1Series2.2DataFrame3、量化分析应用3.1形成一个p
- java实体中返回前端的double类型四舍五入(格式化)
婲落ヽ紅顏誶
java
根据业务,需要通过后端给前端返回部分double类型的数值,一般需要保留两位小数,使用jackson转换对象packagecom.ruoyi.common.core.config;importcom.fasterxml.jackson.core.JsonGenerator;importcom.fasterxml.jackson.databind.JsonSerializer;importcom.f
- Java回溯知识点(含面试大厂题和源码)
一成码农
java面试开发语言
回溯算法是一种通过遍历所有可能的候选解来寻找所有解的算法,如果候选解被确认不是一个解(或至少不是最后一个解),回溯算法会通过在上一步进行一些变化来丢弃这个解,即“回溯”并尝试另一个候选解。回溯法通常用递归方法来实现,在解决排列、组合、选择问题时非常有效。回溯算法的核心要点:路径:也就是已经做出的选择。选择列表:也就是你当前可以做的选择。结束条件:也就是到达决策树底层,无法再做出选择的条件。回溯算法
- Azkaban各种类型的Job编写
__元昊__
一、概述原生的Azkaban支持的plugin类型有以下这些:command:Linuxshell命令行任务gobblin:通用数据采集工具hadoopJava:运行hadoopMR任务java:原生java任务hive:支持执行hiveSQLpig:pig脚本任务spark:spark任务hdfsToTeradata:把数据从hdfs导入TeradatateradataToHdfs:把数据从Te
- 第七章 索引及执行计划,存储引擎
执笔为剑
#MySQL运维篇编辑器mysql
第七章索引及执行计划,存储引擎1,索引及执行计划1,作用:提供类似书目录的作用,目的是优化查询2,所用的种类(根据算法)B树索引Hash索引R树FulltextGIS3,B树基于不同的查找算法分类介绍B-tree:在范围查询方面提供了更好的性能(>showengines;#存储引擎作用在表上,不同的表可能有不同的存储引擎mysql>select@@default_storage_engine;#查
- Kotlin非常用关键字使用记录
Developings
kotlin开发语言android
1,typealias声明一个类型别名。样例:typealiasMyBean=ItemBeandataclassItemBean(valtitle:String,valintent:Intent)valbean=MyBean("11",Intent())实现了将ItemBean数据模型取了一个别名MyBean,后续我们可以像使用别名一样使用他们2,crossinline禁止传递给内联函数的lamb
- 设置mysql 数据库和表 的编码方式UTF-8
盖盖衍上
中间件数据库mysqloracle
要设置MySQL数据库表和字段的编码方式为UTF-8,可以使用下面的SQL语句:1.设置数据库默认编码为UTF-8:ALTERDATABASEyour_database_nameCHARACTERSETutf8mb4COLLATEutf8mb4_unicode_ci;2.创建表时指定编码为UTF-8:CREATETABLEyour_table_name(column1VARCHAR(100)CHA
- 若依框架集成seata分布式事务的一些幺蛾子
半山惊竹
分布式
一、bug连环炮A服务调用B服务,B服务异常,A服务插入的数据没有回退,前面没有思路,就查了下,说是没有切换为seata的数据源,我就在启动类加了一个@EnableAutoDataSourceProxy注解,结果就开始报错了:2024-03-1910:49:30.653[http-nio-8080-exec-2]INFOc.a.n.client.config.impl.CacheData-Line
- Java面试题:解释JVM的内存结构,并描述堆、栈、方法区在内存结构中的角色和作用,Java中的多线程是如何实现的,Java垃圾回收机制的基本原理,并讨论常见的垃圾回收算法
杰哥在此
Java系列javajvm算法面试
Java内存模型与多线程的深入探讨在Java的世界里,内存模型和多线程是开发者必须掌握的核心知识点。它们不仅关系到程序的性能和稳定性,还直接影响到系统的可扩展性和可靠性。下面,我将通过三个面试题,带领大家深入理解Java内存模型、多线程以及并发编程的相关原理和实践。面试题一:请解释JVM的内存结构,并描述堆、栈、方法区在内存结构中的角色和作用。关注点:JVM内存结构的基本组成堆、栈、方法区的功能和
- OpenCV鼠标操作(画红色方框截取图像)
苍天饶过谁?
OpenCV学习opencv计算机外设人工智能C++
Pointsp(-1,-1);Pointep(-1,-1);Mattemp;staticvoidon_draw(intevent,intx,inty,intflags,void*user_data){Matimage=*((Mat*)user_data);if(event==EVENT_LBUTTONDOWN){sp.x=x;sp.y=y;}elseif(event==EVENT_LBUTTONU
- 优化选址问题 | 基于和声搜索算法求解基站选址问题含Matlab源码
天天酷科研
优化选址问题(LP)matlab和声搜索算法基站选址问题
目录问题代码问题和声搜索算法(HarmonySearch,HS)是一种模拟音乐创作过程中乐师们凭借自己的记忆,通过反复调整各乐器的音调,直至达到最美和声状态为启发,通过反复调整解向量的各分量来寻求全局最优解的智能优化算法。下面是一个基于和声搜索算法求解基站选址问题的Matlab伪代码框架。请注意,这个框架是一个基本的实现,你可能需要根据你的具体问题和约束条件进行调整和优化。代码%和声搜索算法求解基
- COMP315 JavaScript Cloud Computing for E Commerce
zhuyu0206girl
javascript开发语言ecmascript
Assignment1:Javascript1IntroductionAcommontaskincloudcomputingisdatacleaning,whichistheprocessoftakinganinitialdatasetthatmaycontainerroneousorincompletedata,andremovingorfixingthoseelementsbeforeform
- 单链表的基本操作
stoAir
c++c语言数据结构算法
链表文章目录链表创建链表单链表实现一:实现二:错例循环链表单独创建逐节点创建约瑟夫环问题删除节点实现方式一:实现方式二:删除节点并建立新链表逆置链表实现:链表排序实现一:实现二:实现三:链表查询(跳表)structList{intdata;structList*next;}创建链表单链表实现一:structList*listCreate(){intdata;structList*head=NULL
- Flink算子通用状态应用测试样例
公子乂
flinkjavaservlet
Flink算子通用状态应用测试样例1.获取Flink执行环境finalStreamExecutionEnvironmentenv=StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);2.创建数据源,生成随机数据DataStream>source=env.addSource(newSourceFunct
- 【循环神经网络rnn】一篇文章讲透
CX330的烟花
rnn人工智能深度学习算法python机器学习数据结构
目录引言二、RNN的基本原理代码事例三、RNN的优化方法1长短期记忆网络(LSTM)2门控循环单元(GRU)四、更多优化方法1选择合适的RNN结构2使用并行化技术3优化超参数4使用梯度裁剪5使用混合精度训练6利用分布式训练7使用预训练模型五、RNN的应用场景1自然语言处理2语音识别3时间序列预测六、RNN的未来发展七、结论引言众所周知,CNN与循环神经网络(RNN)或生成对抗网络(GAN)等算法结
- 为什么 /proc/meminfo 节点获取的 MemTotal 小于物理内存
源码注释器
笔记linux
系统启动过程中打印的内存容量524288K(512M)跟物理内存容量一致Memory:489736K/524288Kavailable(9216Kkernelcode,685Krwdata,1896Krodata,1024Kinit,170Kbss,18168Kreserved,16384Kcma-reserved)开机后,读节点返回的内存容量小于512Mcat/proc/meminfoMemTo
- vue 在style标签中引入js变量控制样式
古迪红尘
VUEvue.jsjavascript前端
1.基本的绑定样式示例data(){return{colorData:'blue',}}详细用法可参考下面的博客:https://www.jianshu.com/p/2b82ee1e6199
- Enum用法
不懂事的小屁孩
enum
以前的时候知道enum,但是真心不怎么用,在实际开发中,经常会用到以下代码:
protected final static String XJ = "XJ";
protected final static String YHK = "YHK";
protected final static String PQ = "PQ";
- 【Spark九十七】RDD API之aggregateByKey
bit1129
spark
1. aggregateByKey的运行机制
/**
* Aggregate the values of each key, using given combine functions and a neutral "zero value".
* This function can return a different result type
- hive创建表是报错: Specified key was too long; max key length is 767 bytes
daizj
hive
今天在hive客户端创建表时报错,具体操作如下
hive> create table test2(id string);
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. MetaException(message:javax.jdo.JDODataSto
- Map 与 JavaBean之间的转换
周凡杨
java自省转换反射
最近项目里需要一个工具类,它的功能是传入一个Map后可以返回一个JavaBean对象。很喜欢写这样的Java服务,首先我想到的是要通过Java 的反射去实现匿名类的方法调用,这样才可以把Map里的值set 到JavaBean里。其实这里用Java的自省会更方便,下面两个方法就是一个通过反射,一个通过自省来实现本功能。
1:JavaBean类
1 &nb
- java连接ftp下载
g21121
java
有的时候需要用到java连接ftp服务器下载,上传一些操作,下面写了一个小例子。
/** ftp服务器地址 */
private String ftpHost;
/** ftp服务器用户名 */
private String ftpName;
/** ftp服务器密码 */
private String ftpPass;
/** ftp根目录 */
private String f
- web报表工具FineReport使用中遇到的常见报错及解决办法(二)
老A不折腾
finereportweb报表java报表总结
抛砖引玉,希望大家能把自己整理的问题及解决方法晾出来,Mark一下,利人利己。
出现问题先搜一下文档上有没有,再看看度娘有没有,再看看论坛有没有。有报错要看日志。下面简单罗列下常见的问题,大多文档上都有提到的。
1、没有返回数据集:
在存储过程中的操作语句之前加上set nocount on 或者在数据集exec调用存储过程的前面加上这句。当S
- linux 系统cpu 内存等信息查看
墙头上一根草
cpu内存liunx
1 查看CPU
1.1 查看CPU个数
# cat /proc/cpuinfo | grep "physical id" | uniq | wc -l
2
**uniq命令:删除重复行;wc –l命令:统计行数**
1.2 查看CPU核数
# cat /proc/cpuinfo | grep "cpu cores" | u
- Spring中的AOP
aijuans
springAOP
Spring中的AOP
Written by Tony Jiang @ 2012-1-18 (转)何为AOP
AOP,面向切面编程。
在不改动代码的前提下,灵活的在现有代码的执行顺序前后,添加进新规机能。
来一个简单的Sample:
目标类:
[java]
view plain
copy
print
?
package&nb
- placeholder(HTML 5) IE 兼容插件
alxw4616
JavaScriptjquery jQuery插件
placeholder 这个属性被越来越频繁的使用.
但为做HTML 5 特性IE没能实现这东西.
以下的jQuery插件就是用来在IE上实现该属性的.
/**
* [placeholder(HTML 5) IE 实现.IE9以下通过测试.]
* v 1.0 by oTwo 2014年7月31日 11:45:29
*/
$.fn.placeholder = function
- Object类,值域,泛型等总结(适合有基础的人看)
百合不是茶
泛型的继承和通配符变量的值域Object类转换
java的作用域在编程的时候经常会遇到,而我经常会搞不清楚这个
问题,所以在家的这几天回忆一下过去不知道的每个小知识点
变量的值域;
package 基础;
/**
* 作用域的范围
*
* @author Administrator
*
*/
public class zuoyongyu {
public static vo
- JDK1.5 Condition接口
bijian1013
javathreadConditionjava多线程
Condition 将 Object 监视器方法(wait、notify和 notifyAll)分解成截然不同的对象,以便通过将这些对象与任意 Lock 实现组合使用,为每个对象提供多个等待 set (wait-set)。其中,Lock 替代了 synchronized 方法和语句的使用,Condition 替代了 Object 监视器方法的使用。
条件(也称为条件队列或条件变量)为线程提供了一
- 开源中国OSC源创会记录
bijian1013
hadoopsparkMemSQL
一.Strata+Hadoop World(SHW)大会
是全世界最大的大数据大会之一。SHW大会为各种技术提供了深度交流的机会,还会看到最领先的大数据技术、最广泛的应用场景、最有趣的用例教学以及最全面的大数据行业和趋势探讨。
二.Hadoop
&nbs
- 【Java范型七】范型消除
bit1129
java
范型是Java1.5引入的语言特性,它是编译时的一个语法现象,也就是说,对于一个类,不管是范型类还是非范型类,编译得到的字节码是一样的,差别仅在于通过范型这种语法来进行编译时的类型检查,在运行时是没有范型或者类型参数这个说法的。
范型跟反射刚好相反,反射是一种运行时行为,所以编译时不能访问的变量或者方法(比如private),在运行时通过反射是可以访问的,也就是说,可见性也是一种编译时的行为,在
- 【Spark九十四】spark-sql工具的使用
bit1129
spark
spark-sql是Spark bin目录下的一个可执行脚本,它的目的是通过这个脚本执行Hive的命令,即原来通过
hive>输入的指令可以通过spark-sql>输入的指令来完成。
spark-sql可以使用内置的Hive metadata-store,也可以使用已经独立安装的Hive的metadata store
关于Hive build into Spark
- js做的各种倒计时
ronin47
js 倒计时
第一种:精确到秒的javascript倒计时代码
HTML代码:
<form name="form1">
<div align="center" align="middle"
- java-37.有n 个长为m+1 的字符串,如果某个字符串的最后m 个字符与某个字符串的前m 个字符匹配,则两个字符串可以联接
bylijinnan
java
public class MaxCatenate {
/*
* Q.37 有n 个长为m+1 的字符串,如果某个字符串的最后m 个字符与某个字符串的前m 个字符匹配,则两个字符串可以联接,
* 问这n 个字符串最多可以连成一个多长的字符串,如果出现循环,则返回错误。
*/
public static void main(String[] args){
- mongoDB安装
开窍的石头
mongodb安装 基本操作
mongoDB的安装
1:mongoDB下载 https://www.mongodb.org/downloads
2:下载mongoDB下载后解压
- [开源项目]引擎的关键意义
comsci
开源项目
一个系统,最核心的东西就是引擎。。。。。
而要设计和制造出引擎,最关键的是要坚持。。。。。。
现在最先进的引擎技术,也是从莱特兄弟那里出现的,但是中间一直没有断过研发的
- 软件度量的一些方法
cuiyadll
方法
软件度量的一些方法http://cuiyingfeng.blog.51cto.com/43841/6775/在前面我们已介绍了组成软件度量的几个方面。在这里我们将先给出关于这几个方面的一个纲要介绍。在后面我们还会作进一步具体的阐述。当我们不从高层次的概念级来看软件度量及其目标的时候,我们很容易把这些活动看成是不同而且毫不相干的。我们现在希望表明他们是怎样恰如其分地嵌入我们的框架的。也就是我们度量的
- XSD中的targetNameSpace解释
darrenzhu
xmlnamespacexsdtargetnamespace
参考链接:
http://blog.csdn.net/colin1014/article/details/357694
xsd文件中定义了一个targetNameSpace后,其内部定义的元素,属性,类型等都属于该targetNameSpace,其自身或外部xsd文件使用这些元素,属性等都必须从定义的targetNameSpace中找:
例如:以下xsd文件,就出现了该错误,即便是在一
- 什么是RAID0、RAID1、RAID0+1、RAID5,等磁盘阵列模式?
dcj3sjt126com
raid
RAID 1又称为Mirror或Mirroring,它的宗旨是最大限度的保证用户数据的可用性和可修复性。 RAID 1的操作方式是把用户写入硬盘的数据百分之百地自动复制到另外一个硬盘上。由于对存储的数据进行百分之百的备份,在所有RAID级别中,RAID 1提供最高的数据安全保障。同样,由于数据的百分之百备份,备份数据占了总存储空间的一半,因而,Mirror的磁盘空间利用率低,存储成本高。
Mir
- yii2 restful web服务快速入门
dcj3sjt126com
PHPyii2
快速入门
Yii 提供了一整套用来简化实现 RESTful 风格的 Web Service 服务的 API。 特别是,Yii 支持以下关于 RESTful 风格的 API:
支持 Active Record 类的通用API的快速原型
涉及的响应格式(在默认情况下支持 JSON 和 XML)
支持可选输出字段的定制对象序列化
适当的格式的数据采集和验证错误
- MongoDB查询(3)——内嵌文档查询(七)
eksliang
MongoDB查询内嵌文档MongoDB查询内嵌数组
MongoDB查询内嵌文档
转载请出自出处:http://eksliang.iteye.com/blog/2177301 一、概述
有两种方法可以查询内嵌文档:查询整个文档;针对键值对进行查询。这两种方式是不同的,下面我通过例子进行分别说明。
二、查询整个文档
例如:有如下文档
db.emp.insert({
&qu
- android4.4从系统图库无法加载图片的问题
gundumw100
android
典型的使用场景就是要设置一个头像,头像需要从系统图库或者拍照获得,在android4.4之前,我用的代码没问题,但是今天使用android4.4的时候突然发现不灵了。baidu了一圈,终于解决了。
下面是解决方案:
private String[] items = new String[] { "图库","拍照" };
/* 头像名称 */
- 网页特效大全 jQuery等
ini
JavaScriptjquerycsshtml5ini
HTML5和CSS3知识和特效
asp.net ajax jquery实例
分享一个下雪的特效
jQuery倾斜的动画导航菜单
选美大赛示例 你会选谁
jQuery实现HTML5时钟
功能强大的滚动播放插件JQ-Slide
万圣节快乐!!!
向上弹出菜单jQuery插件
htm5视差动画
jquery将列表倒转顺序
推荐一个jQuery分页插件
jquery animate
- swift objc_setAssociatedObject block(version1.2 xcode6.4)
啸笑天
version
import UIKit
class LSObjectWrapper: NSObject {
let value: ((barButton: UIButton?) -> Void)?
init(value: (barButton: UIButton?) -> Void) {
self.value = value
- Aegis 默认的 Xfire 绑定方式,将 XML 映射为 POJO
MagicMa_007
javaPOJOxmlAegisxfire
Aegis 是一个默认的 Xfire 绑定方式,它将 XML 映射为 POJO, 支持代码先行的开发.你开发服 务类与 POJO,它为你生成 XML schema/wsdl
XML 和 注解映射概览
默认情况下,你的 POJO 类被是基于他们的名字与命名空间被序列化。如果
- js get max value in (json) Array
qiaolevip
每天进步一点点学习永无止境max纵观千象
// Max value in Array
var arr = [1,2,3,5,3,2];Math.max.apply(null, arr); // 5
// Max value in Jaon Array
var arr = [{"x":"8/11/2009","y":0.026572007},{"x"
- XMLhttpRequest 请求 XML,JSON ,POJO 数据
Luob.
POJOjsonAjaxxmlXMLhttpREquest
在使用XMlhttpRequest对象发送请求和响应之前,必须首先使用javaScript对象创建一个XMLHttpRquest对象。
var xmlhttp;
function getXMLHttpRequest(){
if(window.ActiveXObject){
xmlhttp:new ActiveXObject("Microsoft.XMLHTTP
- jquery
wuai
jquery
以下防止文档在完全加载之前运行Jquery代码,否则会出现试图隐藏一个不存在的元素、获得未完全加载的图像的大小 等等
$(document).ready(function(){
jquery代码;
});
<script type="text/javascript" src="c:/scripts/jquery-1.4.2.min.js&quo
 MinHash each set/document into a hash table Only compute Jaccard similarity of any pair of sets in the same bucket
MinHash each set/document into a hash table Only compute Jaccard similarity of any pair of sets in the same bucket Question
Question

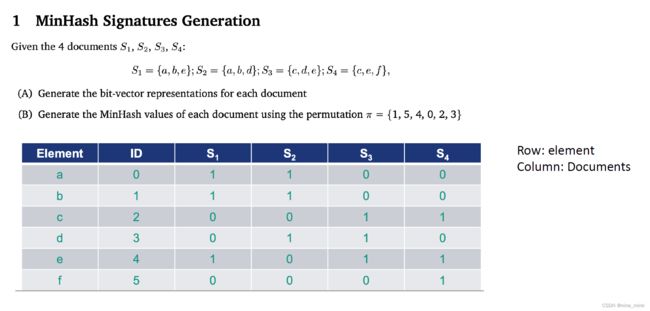











 (A)Answer
(A)Answer

