单表 1000 万条数据,TDengine 助力麦当劳中国实现 PERCENTILE 秒级查询优化
PERCENTILE 函数用于统计表中某列的值百分位数,某一百分位所对应数据的值就称为这一百分位的百分位数, 比如 90% 的分位数的值,代表有 90% 的数小于该分位数的值,10% 的数大于该分位数的值。0 和 100 也就相当于集合的最小值跟最大值。在具体业务中,我们经常用这一函数来衡量服务响应延迟,以最常用的 p99 为例,它衡量了 99% 的情况下能达到的最大延迟,99% 的请求都低于这个数值,即绝大多数情况下的最差情况。
今天我们为大家分享一个关于 TDengine 在 PERCENTILE 函数性能优化上的真实案例。
麦当劳中国
这一案例主角是麦当劳中国,其在运维领域用 TDengine 来存储服务器监控相关数据,目前麦当劳中国的服务器数量约 800 个,单个服务器最高时每天产生 1000 万条数据,每天服务器产生的总数据量高达 35 亿条。每个服务器的数据各存于一个子表中,每天都需进行数据统计汇总。由于麦当劳中国业务上的查询主要以 percentile 函数为主,因此这一函数的性能也是其最关注的问题。
其查询流程如下:
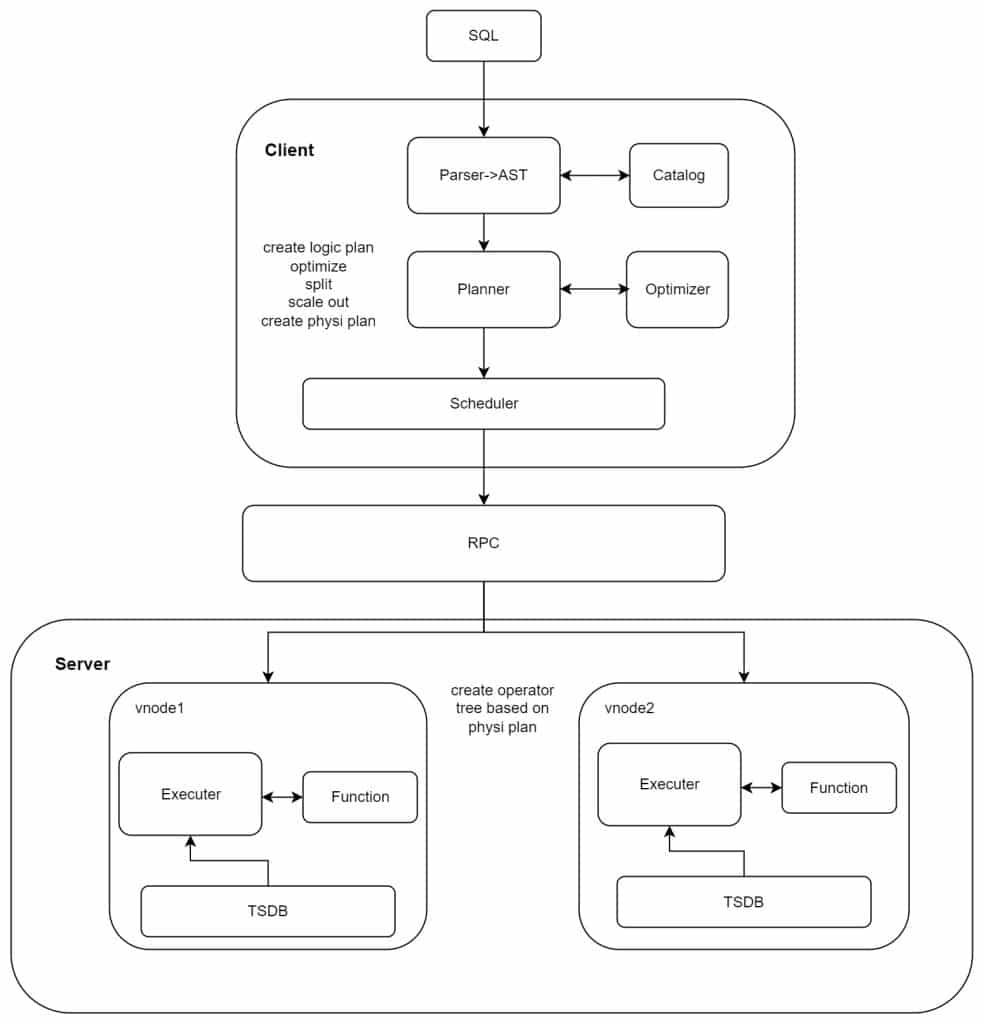
- Parser 将 SQL 语句转化为抽象语法树 AST,并且通过 catalog 模块获取元数据信息进行校验。
- Planner 通过 AST 转化为逻辑执行计划(LogicPlan), 然后经过 Optimizer 对逻辑计划进行简化、重写, filter/limit 下推等优化,将逻辑计划通过分布式计划拆分,转换为可执行的物理计划(Physical Plan)。
- Scheduler 通过 PRC 模块将物理执行计划放到消息中,调度到各个 vnode。
- vnode 查询线程是通过物理计划创建算子树(Operator Tree),通过执行器(Executer)从 root 节点上游算子向下执行。数据流方向则相反,从 datasink 逐级向上返回,例如,需要先从 table scan 算子在 TSDB 读取数据,然后再从 Aggregate 算子调用 Function 模块进行聚合计算。
- 对于查询超级表时要进行分布式执行,并且需要 second stage 聚合的操作,根据物理计划(由客户端 queryPolicy 决定)在 vnode/qnode/client 再次进行聚合计算,然后再返回查询结果给客户端。
查询描述如下:
SELECT COUNT(*), AVG(duration), PERCENTILE(duration,90) as line_90, PERCENTILE(duration,95) as line_95, PERCENTILE (duration,99) as line_99, PERCENTILE (duration,99.99) as line_9999 FROM tb_0 WHERE ts >='2020-01-01 00: 00:00.00.0000' and ts <= '2020-01-02 00:00:00.000';- 查询内容:响应时间的百分位占比
- 查询值 count、avg、P90、P95、P99、P99.99 固定同时查询
- 查询对象:每个服务的子表,不对超级表进行查询
- 查询条件:1 天的时间段左右(可变,任意时间段)
- 并发量:个位数并发查询
麦当劳中国希望在此业务背景下,单表 1000 万条数据查询响应时间能够在秒内实现,这也是本次PERCENTILE 函数性能优化的重点。
优化过程简述
在针对整个查询以及函数的执行流程以及逻辑进行详细分析后,我们发现单独查询 1 个 PERCENTILE 耗时在 1.1s,2 个 PERCENTILE 耗时在 1.8s,3 个 PERCENTILE 在 2.5s 左右,而无论几个 PERCENTILE 执行,table scan 部分都是公共的,因此通过相减可以推断出单独一个 PERCENTILE 消耗在 AGGREGATE 以及 PROJECTION 部分的耗时,即 1 个 PERCENTILE 耗时 0.7s,2 个 1 耗时 1.4s,这个几乎是线性增长的,而 table scan 部分在 0.4s, 总体上多个 PERCENTILE 耗时就是:
table_scan_cost(0.4s) + process_cost(0.7s) * N
因为 table scan 这部分涉及到 tsdbread 的存储,因此可以优化的点在于是否可以将单个耗时减少 0.7s, 或者减少执行次数 N。由于函数实际执行时间优化起来相对困难,函数算法基本上也是业界比较成熟的算法,在不对算法优化的情况下,可能只能通过一些代码技巧来做优化。减少执行次数 N 的关键在于看多次函数执行时是否有共用的地方可以进行合并。
通过观察麦当劳中国的几个 PERCENTILE 查询,我们总结出了一个特点,它们所涉及的数据列都是同一列,数据范围都是固定的,这种情况下我们可以合并数据进行分桶的部分。通过这种优化方式执行时间变为:
table_scan_cost + process_cost * N -> table_scan_cost + process_cost * 1
这样一来,即使执行多个 PERCENTILE 时间也不会随个数线性增长,测试结果也验证了这一优化的成功性。但当前结果稳定在 1.1s 左右,加上 count 和 avg,总时间在 1.2s,仍然还未能达到麦当劳中国要求的执行时间优化到 1s 内。
最终结果
这时我们将重点放在“单个耗时减少 0.7s”上,经过分析明确了多出的 300ms 耗时主要在第一遍 table sacn 以及计算上。
麦当劳中国在查询上除了使用 PERCENTILE,还使用了其他的多个函数,比如 COUNT,AVG 等其他函数。通过日志查看具体物理计划以及执行器的逻辑,发现 PERCENTILE 对于两遍扫描以及计算是这样的:
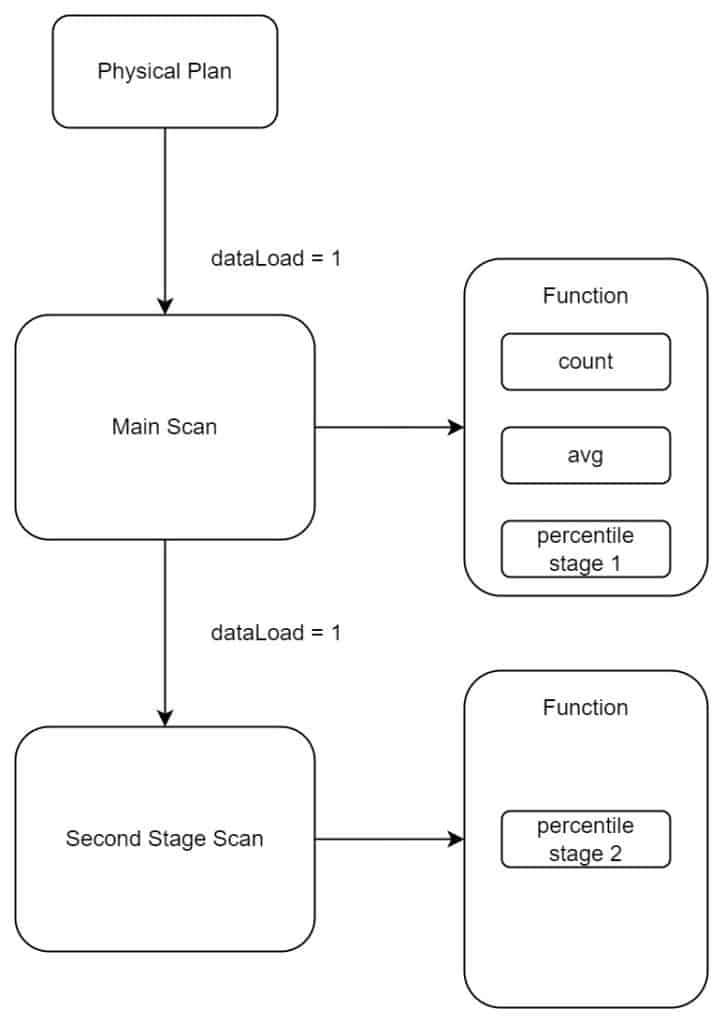
在第一遍 main scan 时,物理计划指定 dataLoad 为 1,也就是需要实际加载数据,而不去读 sma 的值,这是因为其他函数的实际计算,以及 PERCENTILE 的第一阶段计算,都会在 main scan 执行,而很多函数的计算实际上是不能依赖 sma 的,所以为了保证大部分函数能够计算,就需要加载实际数据进行计算。对于第二遍扫描 second stage scan,PERCENTILE 函数第二个阶段的执行,需要加载实际数据去做分桶并计算最终的结果,不能使用 sma,因此 dataload 仍然是 1。
针对这种情况,因为 PERCENTILE 第一阶段可以使用 sma 加速,因此我们将执行逻辑改为下面这种方式:
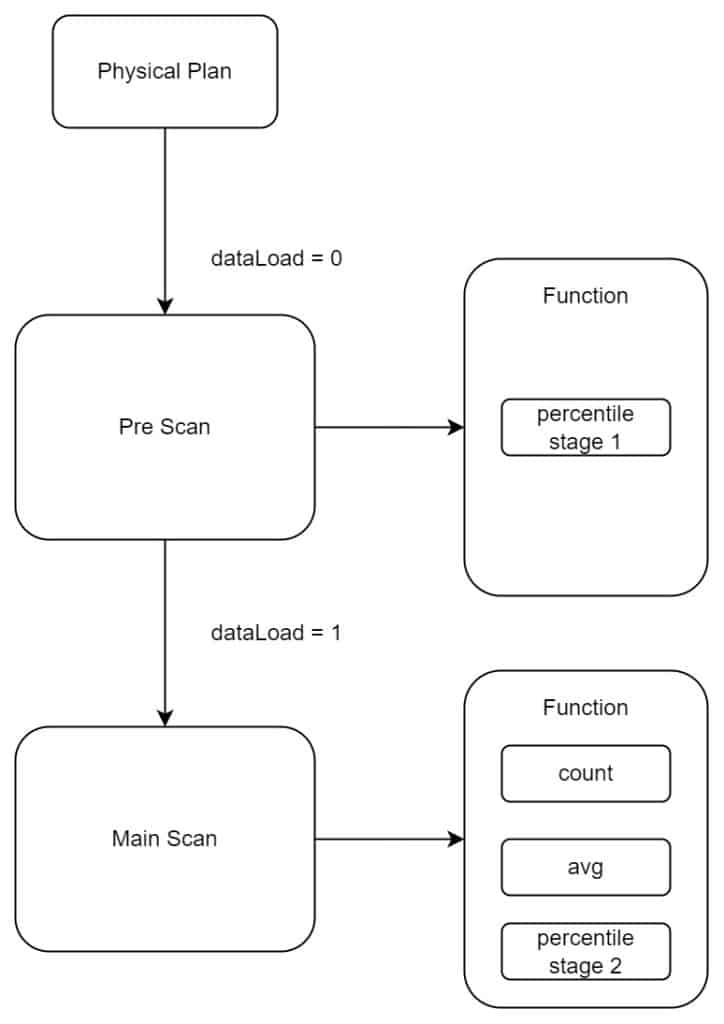
也就是说,在创建计划时,检测到有 PERCENTILE 函数参与运算时,将第一遍扫表设置为 Pre Scan,并且设置 dataLoad 为 0,因此 PERCENTILE 第一阶段计算可以使用 sma, 而不是实际拉取数据。第二遍扫表则当作 Main Scan,将其他函数的计算跟 PERCENTILE 第二阶段放在一起,不影响之前的逻辑。
经过这两次优化操作,最终我们消除了多出的 300ms,加上 count、avg 函数后,查询时间在 0.8s 左右,成功帮助麦当劳中国将单表 1000 万条数据查询响应时间控制在了秒内。
写在最后
PERCENTILE 秒级查询优化对于麦当劳中国来说是一项重要的技术升级,可以帮助他们更灵活、更实时地管理和优化业务运营,也为麦当劳中国与 TDengine 的更长远合作打下了基础。希望这一优化工作的经验分享能给到你帮助,如果大家还有更多的技术问题想要交流,可以添加小Tvx:tdengine,和 TDengine 资深研发进行沟通。
了解更多 TDengine Database的具体细节,可在GitHub上查看相关源代码。