Unity性能优化要点分析(二) 渲染优化技术
本章摘录自UnityShader入门精要的第16章内容。
移动平台的特点
移动平台的GPU架构有很大不同,由于芯片架构的不同,一些游戏往往需要针对不同的芯片发布不同的版本,以便对每种芯片进行更有针对性的优化。尤其在Android平台上,不同设备使用的硬件,如图形芯片、屏幕分辨率等大相径庭,这对图形优化提出了更高的挑战。相比Android平台,IOS硬件条件相对统一
影响性能的因素
主要时两方面:CPU和GPU,CPU负责保证帧率,GPU负责分辨率相关的一些处理,据此把造成性能瓶颈的主要原因分成以下几个方面:
(1)CPU:
过多的drawcall;
复杂的脚本或者物理模拟;
(2)GPU:
顶点处理:过多的顶点;过多的逐顶点计算;
片元处理:过多的片元(既可能是由于分辨率造成的,也可能是由于overdraw造成的);过多的逐片元计算
(3)带宽:
使用了尺寸很大且未压缩的纹理;分辨率过高的帧缓存
drawcall概念和原理:CPU在每次通知GPU进行渲染之前,都需要提前准备好顶点数据(位置、法线、颜色、纹理坐标等),然后调用一系列API把它们放到GPU可以访问的指定位置,最后调用一个绘制命令告诉GPU可以进行渲染了,而每一次调用绘制命令的时候就会产生一个drawcall。过多的drawcall会造成CPU的性能瓶颈,这是因为每次调用drawcall时,CPU往往都需要改变很多渲染状态的设置,而这些操作时是非常耗时的。如果一帧中需要的drawcall数目过多的话,就会导致CPU大部分时间花费在了提交drawcall的工作上了。
当然其他原因也可能造成CPU的瓶颈,例如物体、布料模拟、蒙皮、粒子模拟等,这些计算量很大的操作。
而对于GPU来说,它负责整个渲染流水线,它的性能瓶颈和需要处理的顶点数目、屏幕分辨率、显存等因素有关。相关的优化策略可以从减少处理的数据规模(包括顶点数目和片元数目)、减少运算复杂度等方面入手。
后续涉及到的优化技术主要有:
(1)CPU优化:
使用批处理技术减少drawcall数目
(2)GPU优化:
减少需要处理的顶点数目:优化几何体;使用模型的LOD技术;使用遮挡剔除技术
减少需要处理的片元数目:控制渲染顺序;警惕透明物体;减少实时光照
减少计算复杂度:使用Shader的LOD技术;代码方面的优化
(3)节省内存带宽:减少纹理大小;利用分辨率缩放
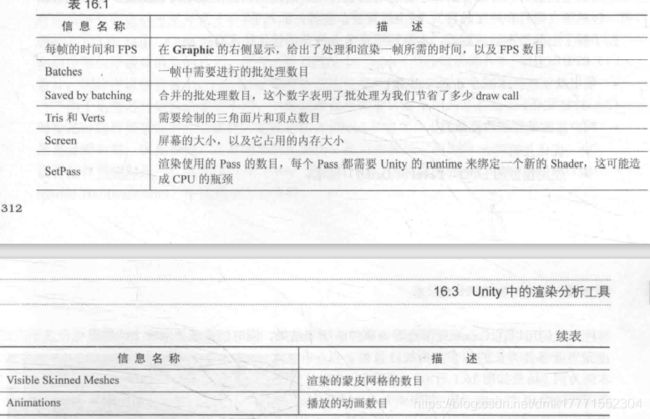
Unity中的渲染分析工具
渲染统计窗口(Rendering Statistics Window)
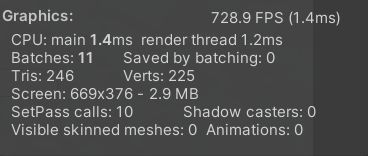
性能分析器(Profiler)

帧调试器(Frame Debugger)
帧调试器上显示了这一帧所需的所有的渲染事件
减少drawcall数目
使用批处理技术。Unity中支持两种批处理方式:动态批处理和静态批处理。
动态批处理的优点是一切处理都是Unity自动完成的,不需要做任何操作,而且物体时可以移动的,但是缺点时限制很多,非常容易破坏这种机制,导致 Unity无法动态批处理一些使用了相同材质的物体。而对于静态批处理来说,它的优点时自由度很高,限制很少;但缺点是可能会占用更多的内存,而且经过静态批处理后的所有物体都不可以再移动了(即使在脚本中尝试改变物体的位置也是无效的)
动态批处理
基本原理是每一帧把可以进行批处理的模型网格进行合并,再把合并后的模型数据传递给GPU,然后使用同一个材质对其渲染。除了实现方便,动态批处理的另一个好处是,经过批处理的物体仍然可以移动,这是由于在处理每帧时都会重新合并一次网格
动态批处理的条件限制:

静态批处理
实现原理是只在运行开始阶段,把需要进行静态批处理的模型合并到一个新的网格结构中,这意味着这些模型不可以在运行时刻被移动。由于它只进行一次合并操作,所以比动态批处理更加高效,但另一个缺点在于往往需要占用更多的内存在存储合并后的几何结构。这是因为如果在静态批处理前一些物体共享了相同的网格,那么内存中每一个物体都会对应一个该网格的复制品,即一个网格变成多个网格再发送给GPU,如果使用这一类网格的对象很多,那么这就会成为一个性能瓶颈了。
在内部实现上,Unity首先把这些静态物体变换到世界空间下,然后为它们构建一个更大的顶点和索引缓存。对于使用同一材质的物体,Unity只需要调用一个drawcall就可以绘制全部物体。而对于使用了不同材质的物体,静态批处理同样可以提升渲染性能。尽管这些物体仍需要调用多个drawcall,但静态批处理可以减少这些drawcall之间的状态切换,而这些切换往往是费时的操作。
共享材质
无论是动态批处理还是静态批处理,都要求模型之间需要共享一个材质。但不同的模型之间总会有不同的渲染属性,所以需要一些策略来尽可能合并材质。
如果两个材质之间只有使用的纹理不同,那么就可以把这些纹理合并到一张更大的纹理中,这种更大的纹理被称为一张图集。一旦使用了用一张纹理,就可以使用同一个材质,再使用不同的采样坐标对纹理采样即可。
但有时,除了纹理不同外,在材质上还有一些微小的参数变化。例如,颜色不同、某些浮点属性不同。但是不管是动态批处理还是静态批处理,它们的前提都是要使用同一个材质,也就是说它们指向的材质必须是同一个实体。这意味着只要我们调整了参数,就会影响到使用它的所有对象,那么如果想要使用微小的调整,一种办法是使用网格的顶点数据(最常见的就是顶点颜色数据)来存储这些参数。
经过批处理后的物体会被处理成更大的VBO(顶点缓冲对象)发送给GPU,VBO中的数据可以作为输入传递给顶点着色器,因此可以巧妙地对VBO中的数据进行控制,从而达到不用效果的目的。
需要注意的是,如果需要在脚本中访问共享材质,应该使用Renderer.sharedMaterial来保证修改的是和其他物体共享的材质,这样的修改会应用到所有使用该材质的物体上。另一个类似的API是Renderer.material,如果使用的是这个,那么Unity会创建一个该材质的复制品,从而破坏批处理在物体上的应用。
批处理的注意事项
尽可能使用静态批处理,但时刻小心对内存的消耗,并且记住经过静态批处理的物体不可以再被移动;
如果无法进行静态批处理,而要使用动态批处理的话,请小心上文中的各种条件限制,例如:尽可能让这样的物体少并且尽可能让这些物体包含少量的顶点属性和顶点数目;
对于游戏中的小道具,例如可以拾捡的金币,可以使用动态批处理;
对于包括动画的这类物体,无法全部使用静态批处理,但其中不动的部分,可以把这部分标志成Static;
由于批处理需要把多个模型变换到世界空间下再合并它们,因此如果在Shader中存在一些基于模型空间下的坐标运算,那么往往会得到错误的结果。解决办法是在Shader中使用DisableBatching标签来强制使该Shader的材质不会被批处理;
使用半透明材质的物体通常需要使用严格的从后往前的绘制顺序来保证透明混合的正确性,对于这类物体,Unity会首先保证它们的绘制顺序,再尝试对它们进行批处理。
减少需要处理的顶点数目
优化几何体
3d游戏在建模时尽可能减少模型中三角面片的数目,一些对于模型没有影响、或是肉眼非常难以察觉到区别的顶点都要尽可能去掉。为了尽可能减少模型中的顶点数目,美工人员往往需要优化网格结构。在很多三维建模软件中,都有相应的优化选项可以自动优化网格结构。
在Unity的渲染统计窗口中,可以查看到渲染当前帧需要的三角面片数目和顶点数目。需要注意的是Unity中显示的往往要多于建模软件中显示的顶点数,这是因为Unity是站在GPU的角度上去计算顶点数目的。在GPU看来,有时需要把一个顶点拆分成两个或者更多的顶点,这样做主要原因有两个:一个是为了分离纹理坐标,另一个是为了产生平滑的边界。它们的本质,其实都是因为对于GPU来说,顶点的每一个属性和顶点之间必须是一对一的关系。
模型的LOD技术
这种技术的原理是,当一个物体离摄像机很远时,模型上的很多细节是无法被察觉到的,因此,LOD允许当对象逐渐远离摄像机时,减少模型上的面片数量,从而提高性能。
在Unity中,我们可以使用LOD Group组件来为一个物体构建一个LOD,我们需要为同一个对象准备多个包含不同细节程序的模型,然后把它们赋给LOD Group组件中的不同等级,Unity就会自动判断当前位置上需要使用哪个等级的模型
遮挡剔除技术
遮挡剔除可以用来消除那些在其他物件后面看不到的物体,这意味着资源不会浪费在计算那些看不到的顶点上,从而提升性能。
需要注意的是需要把遮挡剔除和摄像机的视锥体剔除区分开,视锥体剔除只会剔除掉那些不在摄像机的视野范围内的对象,但不会判断视野中是否有物体被其他物体挡住。而遮挡剔除会使用一个虚拟的摄像机来遍历场景,从而构建一个潜在可见的对象集合的层级结构。
在运行时刻,每个摄像机将会使用这个数据来识别哪些物体可见,而哪些物体被其他物体挡住不可见。使用遮挡剔除技术,不仅可以减少处理的顶点数目,还可以减少overdraw,提高游戏性能。
要用这项技术需要一系列的额外处理工作,具体查看:
https://docs.unity3d.com/Manual/OcclusionCulling.html
减少需要处理的片元数目
另一个造成GPU瓶颈的是需要处理过多的片元,这部分优化的重点在于减少overdraw。简单来说,overdraw值得就是同一个像素被绘制了多次。
控制渲染顺序
为了最大限度地避免overdraw,一个重要的策略是控制渲染顺序,由于深度测试的存在,如果可以保证物体都是从前往后绘制的,那么就可以很大程度上减少overdraw,这是因为在后面绘制的物体由于无法通过深度测试,因此就不会再进行后面的渲染处理。
在Unity中,那些渲染队列数目小于2500(如"Background" "Geometry" 和 "AlphaTest")的对象都被认为是不透明的物体,这些物体总体上是从前往后绘制的,而使用其他的队列(如"Transparent" "Overlay"等)的物体,则是从后往前绘制的,这意味着,可以尽可能把物体的队列设置为不透明物体的渲染队列,而尽量避免使用半透明队列。
时刻警惕透明物体
半透明物体没有开启深度写入,意味着它们几乎一定会造成overdraw。
因此尽量避免场景中包含大面积的半透明效果,或者有很多层相互覆盖的半透明对象,或者是透明的例子效果。
对于上述GUI的这种情况,可以尽量减少窗口中GUI所占的面积,如果实在无能为力,可以把GUI的绘制和三维场景的绘制交给不同的摄像机,而其中负责三维场景的摄像机的视角范围尽量不要和GUI的相互重叠。
在移动平台上,透明度测试也会影响游戏性能,虽然透明度测试没有关闭深度测试,但由于它的实现使用了discard或clip操作,而这些操作会导致一些硬件的优化策略失效。例如PowerVR使用的基于瓦片的延迟渲染技术,为了减少overdraw它会在调用片元着色器前就判断哪些瓦片被真正渲染的,但是由于透明度测试在片元着色器中使用了discard函数改变了片元是否被渲染的结果,因此GPU就无法使用上述的优化策略了。
减少实时光照和阴影
实时光照对于移动平台是一种非常昂贵的操作。如果场景中包含了过多的点光源并且使用了多个Pass的Shader,那么很有可能会造成性能下降。例如,一个场景里如果包含了3个逐像素的点光源,而且使用了逐像素的Shader,那么很有可能将draw call数目提高3倍,同时还会增加overdraw。这是因为对于逐像素的光源来说,被这些光源照亮的物体需要被再渲染一次。更糟糕的是,无论是静态批处理还是动态批处理,对于这种额外处理逐像素光源的Pass都无法进行批处理,也就是说它们会中断批处理。
游戏场景的光照,可以使用烘培技术,把光照提前烘焙到一张光照纹理中,然后再运行时刻只需要根据纹理采样得到光照结果即可。
另一个模拟光源的方法是使用GodRay。场景中的很多小型光源的效果都是靠这种方法模拟,它们一般不是真的光源,很多情况是通过透明纹理模拟得到的。在移动平台上,一个物体使用的逐像素光源数目应该小于1(不包含平行光),如果一定要使用更多的实时光,可以选择用逐顶点光照来代替。
还可以把复杂的光照计算存储到一张查找纹理(LUT)中,在运行时刻,只需要使用光源方向、视角方向、法线方向等参数,对LUT采样得到光照结果即可。使用这样的查找纹理,不仅可以使用更出色的光照模型,例如更加复杂的BRDF模型,还可以利用查找纹理的大小来进一步优化性能,例如主要角色使用更大分辨率的LUT,一些NPC使用较小的LUT。
实时阴影同样是一个非常消耗性能的效果,不仅是CPU需要提交更多的drawcall,GPU也需要进行更多的处理。使用烘焙把静态物体的阴影信息存储到光照纹理中,而只对场景中的动态物体使用适当的实时阴影。
节省带宽
大量使用未经压缩的纹理以及过大的分辨率都会造成由于带宽而引发的性能瓶颈。
减少纹理大小
在使用纹理时,所有纹理的长宽比最好时正方形,而且长宽值最好是2的整数幂。
除此之外,尽可能使用多级渐远纹理技术和纹理压缩。

利用分辨率压缩

减少计算复杂度
Shader的LOD技术
控制使用的Shader等级。它的原理是只有Shader的LOD值小于某个设定的值,这个Shader才会被使用,而那些使用了超过设定值的Shader的物体将不会被渲染。

代码方面的优化
通常来讲,游戏需要计算的对象、顶点和像素的数目排序是对象数<顶点数<像素数,因此应该尽可能地把计算放在每个对象或逐顶点上;
尽可能使用低精度的浮点值进行运算。最高精度的gloat/highp适用于存储诸如顶点坐标等变量,但它的计算速度是最慢的,应该尽量避免在片元着色器中使用这种精度进行计算。而half/mediump适用于一些标量、纹理坐标等变量,它的计算速度大约是float的两倍。而fixed/lowp适用于绝大多数颜色变量和归一化后的方向矢量,在进行一些对精度要求不高的计算时,应该尽量使用这种精度的变量,它的计算速度大约时float的4倍,但要避免对这些低精度变量进行频繁的swizzle操作。还需要注意的时,应当尽量避免在不同精度之间的转换,这有可能会造成一定的性能下降。
对于绝大多数GPU来说,在使用插值寄存器把数据从顶点着色器传递到下一个阶段时,应该使用尽可能少的插值变量。但是如果要对两个纹理坐标进行插值时,对于PowerVR平台来说,使用类似tex2d(_MainTex, uv.zw)这样的语句来进行纹理采样时,GPU无法进行一个纹理的预读取,因为它会认为这些纹理采样是需要依赖其他数据的,并且两个纹理坐标的插值变量非常廉价,直接把不同的纹理坐标存储在不同的插值变量反而性能更好。
尽可能不要使用全屏的屏幕后处理效果,如果确实需要,应该尽量使用fixed/lowp进行低精度运算(纹理坐标除外,可以使用half/mediump),那些高精度的运算可以使用查找表LUT或者转移到顶点着色器中进行处理,除此之外,尽量把多个特效合并到一个Shader中。
还有一些代码优化规则:
尽可能不要使用分支语句和循环语句;
尽可能避免使用类似sin,tan, pow, log等较为复杂的数学运算,可以使用查找表作为替代;
尽可能不要使用discard操作,因为这会影响硬件的某些优化;
根据硬件条件进行缩放
有选择性的使用更高的分辨率,开启屏幕后处理特效,例子效果

