NICE: Improving Panoptic Narrative Detection and Segmentation with Cascading Collaborative Learning
全局叙事定位 NICE: Improving Panoptic Narrative Detection and Segmentation with Cascading Collaborative Learning 论文阅读笔记
- 一、Abstract
- 二、引言
- 三、相关工作
-
- 3.1 Referring Expression Comprehension and Segmentation
- 3.2 Panoptic Narrative Detection and Segmentation
- 3.3 多任务学习
- 四、A Unified Cascading Framework for PND and PNS
-
- 4.1 特征提取
-
- 4.1.1 视觉编码器
- 4.1.2 文本编码器
- 4.2 坐标引导聚合 Coordinate Guided Aggregation
- 4.3 重心驱动定位 Barycenter Driven Localization
- 4.4 训练损失
-
- 4.4.1 分割损失
- 4.2.2 检测损失
- 五、实验
-
- 5.1 数据集
- 5.2 实施细节
-
- 5.2.1 实验设置
- 5.2.2 指标
- 5.3 与 SOTA 方法的比较
- 5.4 消融实验
-
- 单任务 vs. 多任务
- With vs. without CGA 模块
- 重心的选择
- 融合尺度 vs. 单尺度
- With vs. without stuff
- 用于 bounding boxes 的不同方法
- 5.5 拓展 NICE 的边界
-
- 5.5.1 仅采用 bounding boxes 训练 NICE
- 5.5.2 RES 和 REC 的 Zero-shot 研究
- 5.6 定量分析
-
- 5.6.1 可视化
- 5.6.2 预测冲突
- 5.6.3 指代能力
- 六、结论
写在前面
又是一周的结束,时间过得很快呀,继续凎论文吧。这是上一篇博文的后续,相当于 v2 版本呀,作者团队很厉害。
- 论文地址:https://arxiv.org/abs/2310.10975
- 代码地址:https://github.com/Mr-Neko/NICE
- 预计提交于:某个顶会
- Ps:2023 年每周一篇博文阅读笔记,主页 更多干货,欢迎关注呀,期待 6 千粉丝有你的参与呦~
一、Abstract
全景叙事检测及分割 Panoptic Narrative Detection (PND) and Segmentation (PNS) 旨在识别和定位图像中的多个用长自然语言描述的目标。本文提出一种联合的框架 NICE,来共同学习这两种任务。现有的视觉定位任务通常使用两分支的思路,但由于多对多的对齐问题可能会造成识别冲突。于是本文基于 mask 的重心引入两种级联的模型,称之为坐标引导聚合 Coordinate Guided Aggregation (CGA) 和重心驱动定位 Driven Localization (BDL),分别用于分割和检测。具体来说,CGA 提供重心用于检测,减少了 BDL 对大量候选 boxes 的依赖;而 BDL 则利用其自身属性区分不同的实例。大量的实验表明 NICE 很有效。
二、引言
全景叙事检测及分割 Panoptic Narrative Detection (PND) and Segmentation (PNS) 是两个相对于指代表达式理解/分割的新颖任务。PND 和 PNS 需要定位到一段自然语言描述中的所有目标。

如上图所示,自然语言和视觉信息间存在多对多的对齐,于是任务则更难一些。最近的一些方法将 PND 和 PNS 视为两种任务。一方面在 PND 中,使用多步骤处理,将图像中的区域特征和语言描述视为一个区域-句子匹配问题;另一方面,最近的 PNS 采用端到端的方法,直接使用像素 masks 匹配名词短语。虽然定位方法略有不同,PND 和 PNS 还是两个密切相关的任务,在视觉场景上还能互补。于是有一些方法设计一种统一的多模态框架来实现这两个任务,但并未考虑计算成本以及多对多的属性冲突。
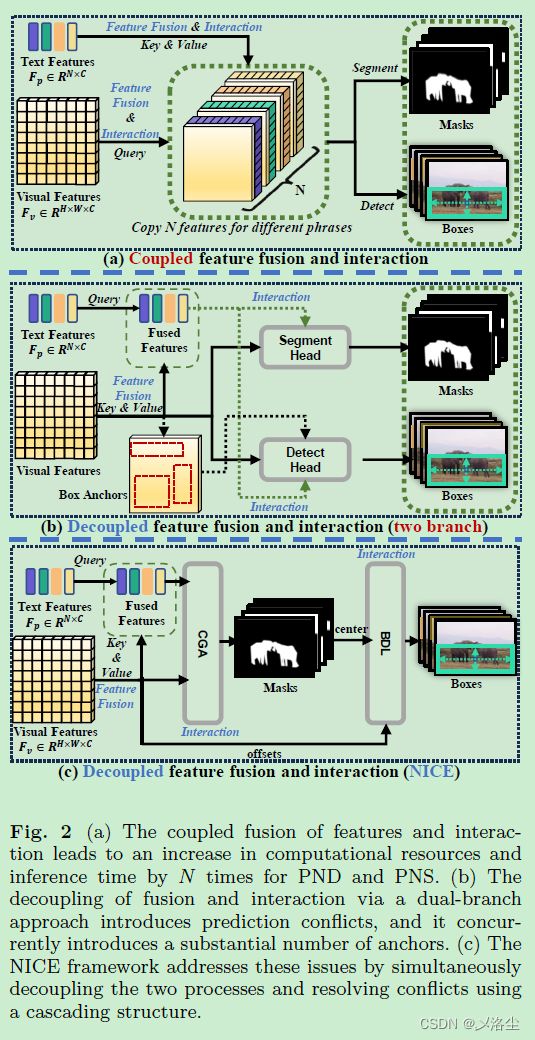
如上图所示,(a) 类方法需要复用视觉特征多次,才能分割大量的名词短语,因而计算和存储成本大。(b) 类方法改进了特征融合,但受限于 box anchor,且未能利用上 PND 和 PNS 的协同潜力。 从 PNS 中观察到,每个 PNS 上的点都能提供精确的位置, 于是在检测头后面加上一个分割策略,使得 PND 能够有效消除大量 anchors 和协同作用的害处。
如图 1(C 所示,本文提出 一个统一的级联框架 uNIfied Cascading framEwork (NICE) 用于共同学习 PNG 和 PND, 利用一个序列策略进行先检测后分割。其核心在于为每个名词短语建立一个可学习的 kernel,来预测 mask 和 bounding box。
为解决预测冲突的问题,引入两个级联的模块:坐标引导聚合 Coordinate Guided Aggregation (CGA)、重心驱动定位 Barycenter Driven Localization (BDL),旨在解决分割和检测的同时实现跨模态对齐。将分割 mask 的重心作为参考点来确保这两个任务对齐。此外,mask 的位置信息驱动着 BDL 生成精确的 bouding boxes,通过 masks 提供的位置信息来取得 bounding box 的重心 offset,从而得到检测结果。本文贡献总结如下:
- 提出一种多模态框架用于 PND 和 PNS,以一种序列、级联的方式执行分割和检测;
- 引入两种级联模块,CGA 和 BDL, 分别用于分割和检测,解决了预测冲突以及促进合作推理。
- 实验表明提出的 NICE 框架效果很好。
三、相关工作
3.1 Referring Expression Comprehension and Segmentation
Referring Expression Segmentation (RES) 和 Referring Expression Comprehension (REC) 旨在基于相对短的文本定位到图像中的相关目标。对于 REC 而言,早期的目标先通过检测模型得到大量的候选区域,然后与文本相比较,从中选出一个最合适的。最近的一些方法通过执行多模态特征融合来执行端到端的训练和检测。对于 RES,之前的方法类似 REC,最近一些方法通过采用单阶段的网络来优化分割 masks,性能提升较明显。
3.2 Panoptic Narrative Detection and Segmentation
全景叙述检测和分割 Panoptic Narrative Detection (PND) 、Panoptic Narrative Segmentation (PNS) 旨在基于输入的文本描述定位和分割多个全景目标。不同于 REC 和 RES 任务,仅需定位单个目标,多任务处理是 PND 和 PNS 的核心。
3.3 多任务学习
分割和检测任务的本质在于语义信息的理解,因此多任务学习上场了。早期的方法首先通过检测获得 Boxes,然后在 boxes 内分割。这些方法太依赖于检测的性能。最近,一些双分支的端到端方法提出共同学习 REC 和 RES 任务,但还是需要复杂的处理过程,于是本文采用动态核的方式来建立一个统一的框架,从而避免复杂的过程,同时减少 anchors 的数量。
四、A Unified Cascading Framework for PND and PNS

首先采用单独的视觉和文本编码器处理图像和文本描述,之后 CGA 模块来促进图-文间交互,使得预测头能够输出 masks。最后,BDL 模块在 masks 的引导下生成 boxes。
4.1 特征提取
4.1.1 视觉编码器
给定图像 I ∈ R H 0 × W 0 × 3 \mathbf{I}\in\mathbb{R}^{H^0\times W^0\times3} I∈RH0×W0×3,应用 FPN 和 ResNet-101 Backbone 提取多尺度视觉特征, F V p ∈ R H p × W p × C , p ∈ { 2 , 3 , 4 , 5 } \mathbf{F_V}^p\in\mathbb{R}^{H^p\times W^p\times C},p\in\{2,3,4,5\} FVp∈RHp×Wp×C,p∈{2,3,4,5},其中 H p = H 0 2 p H^p=\frac{H^0}{2^p} Hp=2pH0, W p = W 0 2 p W^p=\frac{W^0}{2^p} Wp=2pW0。考虑到位置信息的重要性,单独给 F v 5 F_v^5 Fv5 加上位置编码。之后采用语义 FPN 块聚合这些特征,从而得到最后的 F V ∈ R H p × W p × C \mathbf{F_V}\in \mathbb{R}^{H^p\times W^p\times C} FV∈RHp×Wp×C,其中 H p = H 0 8 H^p=\frac{H^0}{8} Hp=8H0, W p = W 0 8 W^p=\frac{W^0}{8} Wp=8W0。
4.1.2 文本编码器
给定一个句子 S \mathbf{S} S,采用预训练的 BERT 模型来提取 token embeddings F s = { s t } t = 0 ∣ S ∣ \mathbf{F_s} = \{s_{t}\}_{t=0}^{|S|} Fs={st}t=0∣S∣,其中 s t s_{t} st 表示 第 t t t 个 token 的 embedding。接下来基于标注信息来筛选出名词短语,然后在每个名词短语的 token embeddings 上采用平均池化来构建短语特征。这些短语特征之后通过一个线性层投影到视觉特征相同的维度,最后得到短语 embedding F P = { f n } n = 0 N ∈ R N × C \mathbf{F}_\mathbf{P}=\{f_n\}_{n=0}^N\in\mathbb{R}^{N\times C} FP={fn}n=0N∈RN×C,其中 f n f_n fn 表示第 n n n 个名词短语的特征, N N N 为名词的数量。
接下来所有的视觉特征和短语特征送入 L L L 层独立层,每一层由一个 Guided Aggregation (CGA) 和 Barycenter Driven Localization (BDL) 组成。
4.2 坐标引导聚合 Coordinate Guided Aggregation
利用短语表示和视觉特征的注意力交互图为每个短语生成一个一对一的 mask,因此去除了匹配或者后处理的需求。尽管很方便,但是很难区分共享相同类别的目标。于是引入坐标引导聚合 Coordinate Guided Aggregation 模块,在 bounding boxes 坐标信息的引导下,来限制分割模块。
更确切来说,为进一步增强文本驱动的内核表达能力,首先是其与视觉特征交互,然后聚合更多的视觉线索,之后采用 cross-attention 来实现。采用 kernel 作为 query,用于视觉特征的注意力权重计算如下:
M ℓ − 1 = { 0 , where M ℓ − 1 ≥ τ − ∞ , where M ℓ − 1 < τ \mathcal{M}^{\ell-1}=\begin{cases}0,&\text{where}\quad\mathbf{M}^{\ell-1}\geq\tau\\-\infty,&\text{where}\quad\mathbf{M}^{\ell-1}<\tau&\end{cases} Mℓ−1={0,−∞,whereMℓ−1≥τwhereMℓ−1<τ
A j = Softmax ( ( K ℓ − 1 W Q j ) ( F v W K j ) T d k + M ℓ − 1 ) \mathbf{A}^j=\text{Softmax}{ \left ( \frac { ( \mathbf{K}^{\ell-1}\mathbf{W}_Q^j)(\mathbf{F}_v\mathbf{W}_K^j)^T}{\sqrt{d_k}}+\mathcal{M}^{\ell-1}\right)} Aj=Softmax(dk(Kℓ−1WQj)(FvWKj)T+Mℓ−1)其中 τ \tau τ 为控制 M ℓ − 1 \mathcal{M}^{\ell-1} Mℓ−1 的阈值, M ℓ − 1 ∈ [ 0 , 1 ] N × H × W \mathcal{M}^{\ell-1}\in[0,1]^{N\times H\times W} Mℓ−1∈[0,1]N×H×W 表示第 ( ℓ − 1 ) (\ell-1) (ℓ−1) 层的 masks。 W Q j ∈ R C × C h \mathrm{W}_Q^j\in\mathbb{R}^{C\times\frac Ch} WQj∈RC×hC 和 W K j ∈ R C × C h \mathbf{W}_K^j\in\mathbb{R}^{C\times\frac Ch} WKj∈RC×hC 为投影矩阵的权重, d k d_k dk 为尺度因子,下标 j j j 表示第 j j j 个头,头的数量 h h h 设为 8。
特别的, K 0 \mathrm{K}^{0} K0 在初始化短语 embedding F p \mathrm{F}^{p} Fp 后获得,而 M 0 \mathrm{M}^{0} M0 则通过下式得到:
M 0 = S i g m o i d ( K 0 ∗ F v ) \mathbf{M}^{0}=\mathrm{Sigmoid}\left(\mathbf{K}^{0}*\mathbf{F}_{\mathbf{v}}\right) M0=Sigmoid(K0∗Fv)其中 M ℓ − 1 \mathcal{M}^{\ell-1} Mℓ−1 限制了核与视觉特征的交互,因此去除了不相关语义的信息。基于这些注意力权重,从语义上聚合头 j j j 的相关视觉特征,并进行拼接得到更新后的核:
H e a d j = A j ( K ℓ − 1 W V j ) \mathrm{Head}^j=\mathbf{A}^j(\mathbf{K}^{\ell-1}\mathbf{W}_V^j) Headj=Aj(Kℓ−1WVj)
K ℓ = F F N ( L N ( [ H e a d 1 , ⋯ , H e a d h ] W O ) + K ℓ − 1 ) \mathbf{K}^{\ell}=\mathrm{FFN}\left(\mathrm{LN}\left(\left[\mathrm{Head}^{1},\cdots,\mathrm{Head}^{h}\right]\mathrm{W}_{O}\right)+\mathbf{K}^{\ell-1}\right) Kℓ=FFN(LN([Head1,⋯,Headh]WO)+Kℓ−1)其中 W V j ∈ R C × C h \mathrm{W}_V^j\in\mathbb{R}^{C\times\frac Ch} WVj∈RC×hC, W O ∈ R C × C \mathrm{W}_O\in\mathbb{R}^{C\times C} WO∈RC×C 为投影矩阵。 L N ( ⋅ ) \mathrm{LN}(\cdot) LN(⋅) 表示 layer Normlization。之后应用捷径分支和一个前项传播网络 F F N ( ⋅ ) \mathrm{FFN}(\cdot) FFN(⋅)。
最后,这些文本驱动的动态核将用于驱动视觉特征得到最终的 masks:
M ℓ = S i g m o i d ( K ℓ ∗ F v ) \mathbf{M}^{\ell}=\mathrm{Sigmoid}\left(\mathbf{K}^{\ell}*\mathbf{F}_{\mathbf{v}}\right) Mℓ=Sigmoid(Kℓ∗Fv)
此外,在检测到的 boxes 的辅助下,进一步来限制分割边界,从而区分不同的实例。其中最直接的方式是找到 mask 的最小外接矩形,使得 mask 尽量在 Box 内部,于是可以实现一步检测和分割。然而这种限制过于严格,导致检测性能非常依赖于分割的整体边界。于是使用 soft 限制,即 mask 的中心来连接两个模块。
4.3 重心驱动定位 Barycenter Driven Localization
通过 CGA 模块生成的 mask 可以粗糙地标定目标位置,这可以作为 PND 的线索,因此提出 BDL,建立在 CGA 之上,使得 BDL 能够充分利用 CGA 提供的位置信息。
本文观察到,一旦目标的位置确定下来后,就可以将其视为一个点,于是接下来直接确定其尺寸即可。于是使用视觉特征 F v \mathrm{F_v} Fv 预测每个与重心相关联的 offset:
O = Sigmoid ( BottleNeck ( F v ) ) \mathbf{O}=\text{Sigmoid}\left(\text{BottleNeck}\left(\mathbf{F_v}\right)\right) O=Sigmoid(BottleNeck(Fv))其中 BottleNeck \text{BottleNeck} BottleNeck 为级联的卷积网络, O ∈ [ 0 , 1 ] H × W × 4 \mathbf{O}\in{[0,1]^{H\times W\times 4}} O∈[0,1]H×W×4 为 offset 矩阵。在这一情况下,只使用一次视觉特征来一次预测出所有的 boxes。
通常情况下,目标中心与 mask 的中心是相同的。因此首先找到 mask 的重心:基于第 ℓ \ell ℓ 层 CGA 的输出 masks M ℓ \mathbf{M}^{\ell} Mℓ,重心计算如下:
D x ℓ , n = ∬ M ℓ x n M ℓ ( x n , y n ) d x d y ∑ x n , y n W , H M ℓ ( x n , y n ) D y ℓ , n = ∬ M ℓ y n M ℓ ( x n , y n ) d x d y ∑ x n , y n W , H M ℓ ( x n , y n ) \begin{gathered} \mathrm{D}_{\mathbf{x}}\ell,n =\frac{\iint_{M^{\ell}}x^{n}\mathbf{M}^{\ell}\left(x^{n},y^{n}\right)dxdy}{\sum_{x^{n},y^{n}}^{W,H}\mathbf{M}^{\ell}\left(x^{n},y^{n}\right)}\\ \mathbf{D_{y}}^{\ell,n} =\frac{\iint_{M^{\ell}}y^{n}\mathbf{M}^{\ell}\left(x^{n},y^{n}\right)dxdy}{\sum_{x^{n},y^{n}}^{W,H}\mathbf{M}^{\ell}\left(x^{n},y^{n}\right)} \end{gathered} Dxℓ,n=∑xn,ynW,HMℓ(xn,yn)∬MℓxnMℓ(xn,yn)dxdyDyℓ,n=∑xn,ynW,HMℓ(xn,yn)∬MℓynMℓ(xn,yn)dxdy其中 n n n 表示第 n n n 个名词短语, D ℓ ∈ R N × 2 \mathrm{D}^{\ell}\in\mathbb{R}^{N\times 2} Dℓ∈RN×2 为 mask 重心的二维坐标。
最后,通过组合重心坐标以及相应的 offset ,为所有的名词短语预测 bounding boxes:
{ x 1 = D x ℓ , n − l y 1 = D y ℓ , n − t x 2 = D x ℓ , n + r y 2 = D y ℓ , n + b \begin{cases}x^1=\mathbf{D_x}^{\ell,n}-l\\y^1=\mathbf{D_y}^{\ell,n}-t\\x^2=\mathbf{D_x}^{\ell,n}+r\\y^2=\mathbf{D_y}^{\ell,n}+b\end{cases} ⎩ ⎨ ⎧x1=Dxℓ,n−ly1=Dyℓ,n−tx2=Dxℓ,n+ry2=Dyℓ,n+b其中 l l l、 t t t、 r r r、 b b b 源于 O x , y \mathbf{O}_{x,y} Ox,y,表示重心到指代 Bounding boxes 的边缘距离。 D x ℓ , n \mathbf{D_x}^{\ell,n} Dxℓ,n 和 D y ℓ , n \mathbf{D_y}^{\ell,n} Dyℓ,n 表示重心的坐标, x 1 x_1 x1、 y 1 y_1 y1、 x 2 x_2 x2、 y 2 y_2 y2 则表示 bounding boxes 的左上角和右下角点的坐标。
4.4 训练损失
4.4.1 分割损失
给定 GT mask Y ∈ R N × H × W \mathbf{Y}\in\mathbb{R}^{N\times H\times W} Y∈RN×H×W 和预测 M ∈ R N × H × W \mathbf{M}\in\mathbb{R}^{N\times H\times W} M∈RN×H×W,利用 BCE 损失 L b c e \mathcal{L}_{bce} Lbce 和 Dice 损失来优化分割:
L ‾ b c e = − 1 H × W ∑ i = 0 H × W 1 N ∑ n = 0 N L b c e ( M n , i , Y n , i ) \begin{aligned}\overline{\mathcal{L}}_{bce}&=-\frac{1}{H\times W}\sum_{i=0}^{H\times W}\frac{1}{N}\sum_{n=0}^{N}\mathcal{L}_{bce}\left(\mathbf{M}^{n,i},\mathbf{Y}^{n,i}\right)\end{aligned} Lbce=−H×W1i=0∑H×WN1n=0∑NLbce(Mn,i,Yn,i)
L ‾ d i c e = 1 N ∑ n = 0 N 1 − 2 ∣ M n ⋂ Y n ∣ ∣ M n ∣ + ∣ Y n ∣ \overline{\mathcal{L}}_{dice}=\frac{1}{N}\sum_{n=0}^{N}1-\frac{2|\mathbf{M}^{n}\bigcap\mathbf{Y}^{n}|}{|\mathbf{M}^{n}|+|\mathbf{Y}^{n}|} Ldice=N1n=0∑N1−∣Mn∣+∣Yn∣2∣Mn⋂Yn∣
4.2.2 检测损失
使用 Smooth L1 损失和 gIoU 损失来限制预测的 boxes:
L s ( B n , i , G n , i ) = { 0.5 ( B n , i − G n , i ) 2 , ∣ x ∣ < ξ ∣ B n , i − G n , i ∣ − 0.5 , o t h e r w i s e \mathcal{L}_s\left(\mathbf{B}^{n,i},\mathbf{G}^{n,i}\right)=\begin{cases}0.5\left(\mathbf{B}^{n,i}-\mathbf{G}^{n,i}\right)^2,&|x|<\xi\\|\mathbf{B}^{n,i}-\mathbf{G}^{n,i}|-0.5,&otherwise\end{cases} Ls(Bn,i,Gn,i)={0.5(Bn,i−Gn,i)2,∣Bn,i−Gn,i∣−0.5,∣x∣<ξotherwise其中 x = B n , i − G n , i x=\mathbf{B}^{n,i}-\mathbf{G}^{n,i} x=Bn,i−Gn,i, B n ∈ R 4 \mathbf{B}^{n}\in\mathbb{R}^{4} Bn∈R4 表示第 n n n 个短语预测的 box, G n \mathbf{G}^{n} Gn 为相应的 GT, i ∈ { x , y , w , h } i\in \{x,y,w,h\} i∈{x,y,w,h} 。在训练时设置 ξ \xi ξ 为 0.5。对于所有的短语,其总损失为:
L ‾ s m o o t h = 1 4 N ∑ n = 0 N ∑ i L s ( B n , i , G n , i ) \overline{\mathcal{L}}_{smooth}=\frac{1}{4N}\sum_{n=0}^{N}\sum_{i}\mathcal{L}_{s}\left(\mathbf{B}^{n,i},\mathbf{G}^{n,i}\right) Lsmooth=4N1n=0∑Ni∑Ls(Bn,i,Gn,i)由于 Smooth L1 损失的优化不等同于优化 IoU,于是添加 gIoU 损失:
L ‾ g I o U = 1 N ∑ n = 0 N 1 − B n ⋂ G n B n ⋃ G n + A c n − B n ⋃ G n A c n \overline{\mathcal{L}}_{gIoU}=\frac{1}{N}\sum_{n=0}^{N}1-\frac{\mathbf{B}^{n}\bigcap\mathbf{G}^{n}}{\mathbf{B}^{n}\bigcup\mathbf{G}^{n}}+\frac{A_{c}^{n}-\mathbf{B}^{n}\bigcup\mathbf{G}^{n}}{A_{c}^{n}} LgIoU=N1n=0∑N1−Bn⋃GnBn⋂Gn+AcnAcn−Bn⋃Gn其中 A c n A_{c}^{n} Acn 为 B n \mathbf{B}^{n} Bn 和 G n \mathbf{G}^{n} Gn 的最小闭合区域。
于是总体训练损失为:
L = λ 1 L ‾ b c e + λ 2 L ‾ d i c e + λ 3 L ‾ s m o o t h + λ 4 L ‾ g I o U L=\lambda_{1}\overline{\mathcal L}_{bce}+\lambda_{2}\overline{\mathcal L}_{dice}+\lambda_{3}\overline{\mathcal L}_{smooth}+\lambda_{4}\overline{\mathcal L}_{gIoU} L=λ1Lbce+λ2Ldice+λ3Lsmooth+λ4LgIoU
五、实验
5.1 数据集
Panoptic Narrative Grounding (PNG),133103 张训练图像和 8380 张测试图像组成,整体包含 875083 个 masks 和 box 标注。
5.2 实施细节
5.2.1 实验设置
ResNet-101 作为 Backbone,预训练在 COCO 数据集上,对于文本 Backbone,采用 BERT 模型。在训练阶段,冻结视觉 Backbone,输入的图像分辨率 640 × 640 640\times640 640×640,输出特征图分辨率 80 × 80 × 256 80\times80\times 256 80×80×256。文本特征维度 768,8 头,隐藏层维度 2048。模型总体三层。最后平衡损失的超参数 λ 1 = 1 \lambda_1=1 λ1=1、 λ 2 = 1 \lambda_2=1 λ2=1、 λ 3 = 1 \lambda_3=1 λ3=1、 λ 4 = 1 \lambda_4=1 λ4=1。从所有的层中选择 masks 和最后一层的 boxes 用于训练。初始学习率 η = 1 e − 4 \eta=1e^{-4} η=1e−4,在 5 个 epoches 后降低 50 % 50\% 50%,在第 10 个 epoch 时,固定为 η = 5 e − 7 \eta=5e^{-7} η=5e−7。Batch_size 48,4 块 3090,大概 20 小时。Adam 优化器。
5.2.2 指标
Average Recall、IoU。
5.3 与 SOTA 方法的比较
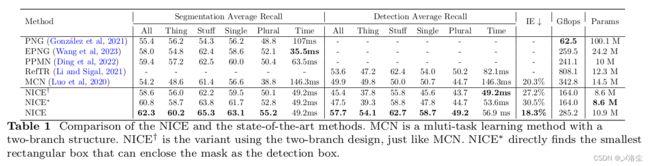
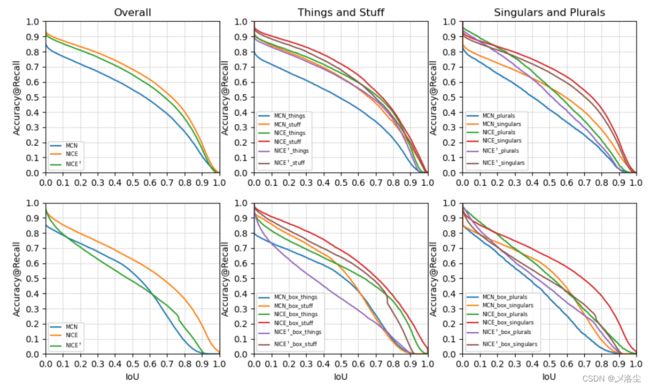
5.4 消融实验
单任务 vs. 多任务
With vs. without CGA 模块

重心的选择
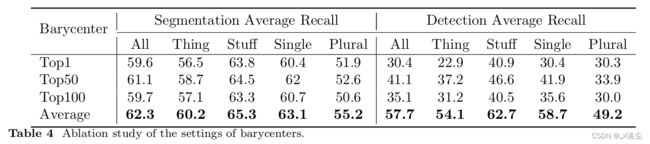
融合尺度 vs. 单尺度

With vs. without stuff

用于 bounding boxes 的不同方法
同表 1。
5.5 拓展 NICE 的边界
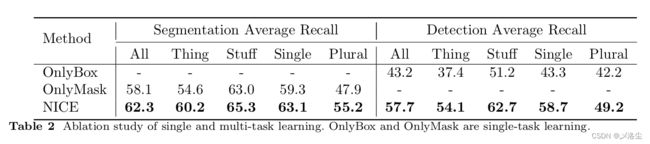
5.5.1 仅采用 bounding boxes 训练 NICE
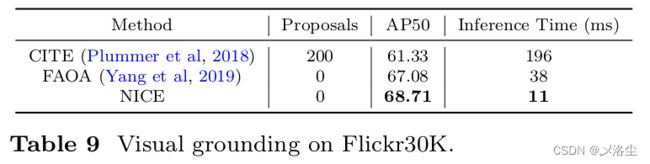
5.5.2 RES 和 REC 的 Zero-shot 研究

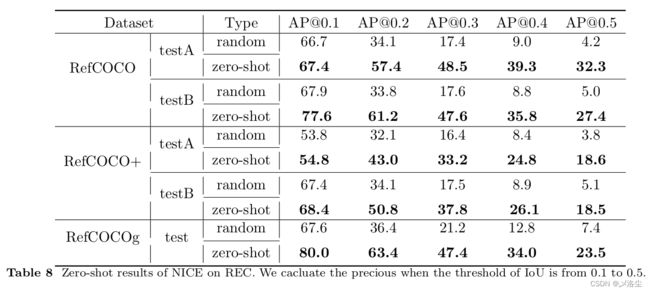
5.6 定量分析
5.6.1 可视化

5.6.2 预测冲突

5.6.3 指代能力

六、结论
本文提出一个统一的级联框架 NICE,用于全景叙事检测和分割。基于分割 mask 的重心提出了坐标引导聚合 Coordinate Guided Aggregation (CGA) 和重心驱动定位 Barycenter Driven Localization (BDL)。实验表明 NICE 效果很好。
写在后面
总算是一拖再拖把这篇博客写完了,期间电脑显示器还凉了,一波三折折又折。负重前行,继续加油吧