又一大语言模型上线!一次可读35万汉字!
国内大模型创业公司,正在技术前沿创造新的记录。10 月 30 日,百川智能正式发布 Baichuan2-192K 长窗口大模型,将大语言模型(LLM)上下文窗口的长度一举提升到了 192K token。
这相当于让大模型一次处理约 35 万个汉字,长度达到了 GPT-4(32K token,约 2.5 万字)的 14 倍,Claude 2.0(100K token,约 8 万字) 的 4.4 倍。
换句话说,Baichuan2-192K 可以一次性读完一本《三体 2》,是全球处理上下文窗口长度最长的大模型。此外,它也在文本生成质量、上下文理解、问答能力等多个维度的评测中显著领先对手。
能够一次理解超长文本的大模型,究竟能做哪些事?百川智能进行了一番简单演示。
上传一整部《三体 2:黑暗森林》的 PDF 文件,百川大模型统计出来是 30 万字。接下来,如果你询问有关这本小说里的任何问题,大模型都可以给出简洁准确的答案。

有时候我们寻求 AI 的帮助,并不是希望他们发挥想象力,而是要提取准确信息。有了 Baichuan2-192K,我们可以快速解读几十页,甚至几百页的合同文件,让 AI 快速给出简明摘要,四舍五入就是量子速读了:
那么如果我突然接到新任务,有一堆文件要看呢?
直接打包一起上传就可以了,百川大模型可以轻松把五篇新闻整合成一篇。
大模型能够理解的内容变长之后,应用的方向会越来越多。众所周知,长文本建模能力是很多场景能够应用落地的前提条件。这一次,百川做到了业内领先。
从几万字到几十万字,头部创业公司都在抢滩「长窗口」
如果你关注大模型在文本理解方向的应用,或许会注意到一个现象:一开始,大家用来测评模型能力的文本可能都是一些财报、技术报告,这些文本通常有十几页到几十页不等,字数通常也就几万字。但后来,测试文本逐渐演变为几个小时的会议记录,或者几十万字的长篇小说,竞争越来越激烈,难度也越来越大。

与此同时,宣称能理解更长上下文的大模型公司也越来越受关注。比如前段时间,宣称能实现 100K token 上下文窗口的大模型 ——Claude 背后的公司 Anthropic 先后拿到了微软和谷歌数十亿美元的融资,将大模型军备竞赛推向了新的层面。
为什么这些公司都在挑战长文本?
首先从应用的角度来看,使用大模型来提高生产力的很多工作者都不免要处理很长的文本,比如律师、分析师、咨询师等,上下文窗口越大,这些人能用大模型做的事情就越广泛;其次,从技术的角度来看,窗口所能容纳的信息越多,模型在生成下一个字时可以参考的信息就越多,「幻觉」发生的可能性就越小,生成的信息就越准确,这是大模型技术落地的必要条件。所以,在想办法提升模型性能的同时,各家公司也在比拼谁能把上下文窗口做得更大,从而投放到更多的应用场景。
从前面展示的一些例子中可以看到,Baichuan2-192K 在文本生成质量和上下文理解方面表现都很出色。而且,在这些定性结果之外,我们还可以从一些定量评估数据中看到这一点。
Baichuan2-192K:文件越长,优势越明显
在文本生成质量评估中,一个很重要的指标叫「困惑度」:当我们将符合人类自然语言习惯的高质量文档作为测试集时,模型生成测试集中文本的概率越高,模型的困惑度就越小,模型也就越好。
用来测试百川大模型困惑度的测试集名叫 PG-19。这个数据集由 DeepMind 的研究人员制作,用来制作该数据集的资料来自古腾堡计划的图书,因此 PG-19 具有书本级的质量。
测试结果如下图所示。可以看到,在初始阶段(横轴左侧,上下文长度比较短的阶段),Baichuan2-192K 的困惑度便处于较低的水准。随着上下文长度的增加,它的优势变得愈发明显,甚至呈现出困惑度持续下降的状态。这说明,在长上下文的场景中,Baichuan2-192K 更能保持书本级的文本生成质量。
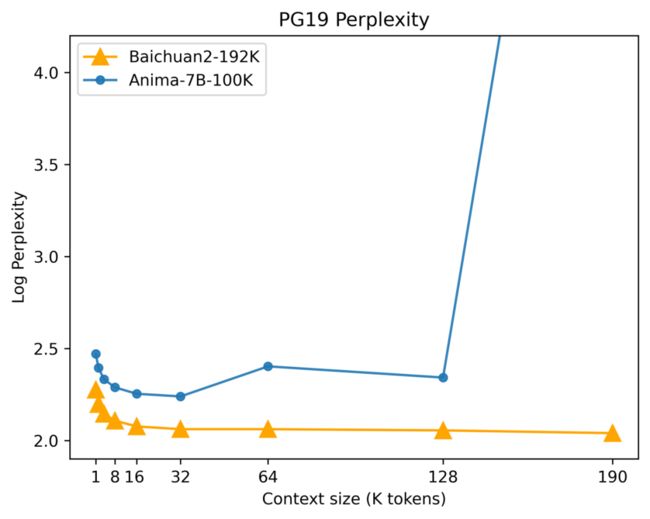
在上下文理解能力上,Baichuan2-192K 的表现也非常亮眼。
这项能力的评估采用了权威的长窗口文本理解评测基准 LongEval。LongEval 是由加州大学伯克利分校联合其他高校发布的针对长窗口模型评测的榜单,主要衡量模型对长窗口内容的记忆和理解能力,模型得分越高越好。
从下图的评估结果中可以看到,随着上下文长度的增加,Baichuan2-192K 一直能够保持稳定的高性能,在窗口长度超过 100K 之后也是如此。相比之下,Claude 2 在窗口长度超过 80K 后整体效果下降就已经非常严重。

此外,模型还在 Dureader、NarrativeQA、TriviaQA、LSHT 等多个中英文长文本问答、摘要的评测集上经历了测试。结果显示,Baichuan2-192K 同样表现优异,在大部分长文本评测任务中都远超其他模型。
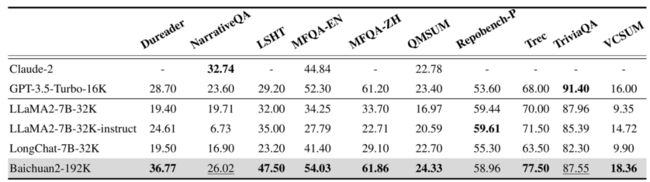
简而言之,处理的内容越长,百川的大模型相对性能就越好。
技术交流群
建了技术答疑、交流群!想要进交流群的同学,可以直接加微信号:mlc2060。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
方式①、添加微信号:mlc2060,备注:技术交流
方式②、微信搜索公众号:机器学习社区,后台回复:技术交流
