大数据毕业设计选题推荐-旅游景点游客数据分析-Hadoop-Spark-Hive
✨作者主页:IT毕设梦工厂✨
个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。
☑文末获取源码☑
精彩专栏推荐⬇⬇⬇
Java项目
Python项目
安卓项目
微信小程序项目
文章目录
- 一、前言
- 二、开发环境
- 三、系统界面展示
- 四、部分代码设计
- 五、论文参考
- 六、系统视频
- 结语
一、前言
随着现代科技的发展和互联网的普及,大数据技术正在逐渐渗透到各行各业,包括旅游业。传统的旅游业数据分析主要依赖于抽样调查和实地考察,这种方法不仅需要大量的人力和物力,而且往往存在数据不准确的问题。然而,大数据技术的出现,使得我们可以更准确、更快速地分析游客数据,从而更好地规划旅游资源和服务。因此,基于大数据的旅游景点游客数据分析成为了一个重要的研究课题。
尽管大数据技术为旅游数据分析提供了新的可能性,但现有的解决方案仍存在一些问题。首先,许多数据分析模型过于依赖历史数据,对于新兴的旅游现象和趋势预测不够准确。其次,现有的数据分析方法往往忽视了游客行为的动态性和复杂性,无法反映游客的需求和偏好。此外,许多数据分析工具缺乏直观的可视化界面,使得结果难以理解。因此,我们需要一个更有效的基于大数据的旅游景点游客数据分析方法。
本课题的研究目的是开发一个基于大数据的旅游景点游客数据分析系统,该系统能够实现以下功能:
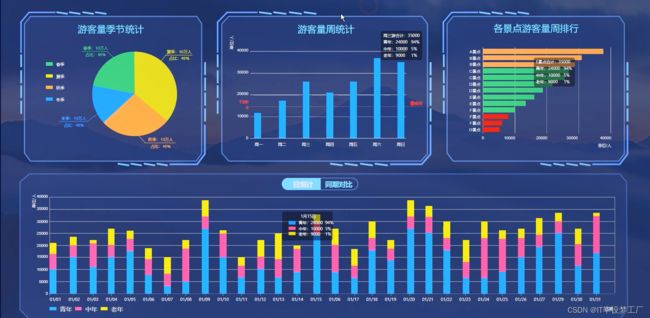
游客量季节统计分析:分析不同季节的游客数量,了解游客的需求旺季和淡季,以便更好地调配旅游资源。
游客量周统计分析:分析一周内每天的游客数量,了解游客的出行习惯,为景点的开放时间和休息安排提供参考。
景点游客量排行:对不同景点的游客数量进行排名,了解哪些景点受欢迎,哪些景点需要改进。
游客年龄段数据分析:分析不同年龄段的游客数量和比例,了解游客的构成和需求特点,以便更好地满足不同群体的需求。
游客量同期对比数据:比较不同年份同期的游客数量,了解景点的成长情况和市场变化趋势。
本课题的研究意义在于为旅游业提供一个更有效的游客数据分析方法,从而帮助旅游部门更好地规划和管理旅游资源和服务。具体来说,本课题的研究意义包括以下几个方面:
提高旅游管理的科学性和有效性:通过大数据分析,旅游部门可以更准确地了解游客的需求和行为特点,从而制定更科学、更有效的管理策略。
优化旅游资源配置:通过分析游客数量和行为数据,旅游部门可以更好地调配旅游资源,提高资源利用效率。
提高游客满意度:通过了解游客的需求和行为特点,旅游部门可以提供更符合游客喜好的服务和活动,从而提高游客满意度。
促进旅游业发展:通过大数据分析,旅游部门可以更好地了解市场趋势和新兴的旅游现象,从而制定更有效的营销策略和发展规划。
二、开发环境
- 大数据技术:Hadoop、Spark、Hive
- 开发技术:Python、Django框架、Vue、Echarts、机器学习
- 软件工具:Pycharm、DataGrip、Anaconda、VM虚拟机
三、系统界面展示
- 基于大数据的旅游景点游客数据分析系统界面展示:





四、部分代码设计
- 基于大数据的旅游景点游客数据分析项目实战-代码参考:
class MySpider:
def open(self):
self.con = sqlite3.connect("lvyou.db")
self.cursor = self.con.cursor()
sql = "create table lvyou (title varchar(512),price varchar(16),destination varchar(512),feature text)"
try:
self.cursor.execute(sql)
except:
self.cursor.execute("delete from Lvyou")
self.baseUrl = "https://huodong.ctrip.com/activity/search/?keyword=%25e9%25a6%2599%25e6%25b8%25af"
self.chrome = webdriver.Chrome()
self.count = 0
self.page = 0
self.pageCount = 0
def close(self):
self.con.commit()
self.con.close()
def insert(self, title, price, destination, feature):
sql = "insert into lvyou (title,price,destination,feature) values (?,?,?,?)"
self.cursor.execute(sql, [title, price, destination, feature])
def show(self):
self.con = sqlite3.connect("lvyou.db")
self.cursor = self.con.cursor()
self.cursor.execute("select title,price,destination,feature from lvyou")
rows = self.cursor.fetchall()
for row in rows:
print(row)
self.con.close()
def spider(self, url):
try:
self.page += 1
print("\nPage", self.page, url)
self.chrome.get(url)
time.sleep(3)
html = self.chrome.page_source
root = BeautifulSoup(html, "lxml")
div = root.find("div", attrs={"id": "xy_list"})
divs = div.find_all("div", recursive=False)
for i in range(len(divs)):
title = divs[i].find("h2").text
price = divs[i].find("span", attrs={"class": "base_price"}).text
destination = divs[i].find("p", attrs={"class": "product_destination"}).find("span").text
feature = divs[i].find("p", attrs={"class": "product_feature"}).text
print(title, '\n预付:', price, "\n", destination, feature)
if self.page == 1:
link = root.find("div", attrs={"class": "pkg_page basefix"}).find_all("a")[-2]
self.pageCount = int(link.text)
print(self.pageCount)
if self.page < self.pageCount:
url = self.baseUrl + "&filters=p" + str(self.page + 1)
self.spider(url)
self.insert(title, price, destination, feature)
except Exception as err:
print(err)
def process(self):
url = "https://huodong.ctrip.com/activity/search/?keyword=%25e9%25a6%2599%25e6%25b8%25af"
self.open()
self.spider(url)
self.close()
'''
spider = MySpider()
spider.open()
spider.spider("https://huodong.ctrip.com/activity/search/?keyword=%25e9%25a6%2599%25e6%25b8%25af")
spider.close()
'''
spider = MySpider()
while True:
print("1.爬取")
print("2.显示")
print("3.退出")
s = input("请选择(1,2,3):")
if s == "1":
print("Start.....")
spider.process()
print("Finished......")
elif s == "2":
spider.show()
else:
break
五、论文参考
- 计算机毕业设计选题推荐-基于大数据的旅游景点游客数据分析系统-论文参考:

六、系统视频
基于大数据的旅游景点游客数据分析-项目视频:
大数据毕业设计选题推荐-旅游景点游客数据分析-Hadoop
结语
大数据毕业设计选题推荐-旅游景点游客数据分析-Hadoop-Spark-Hive
大家可以帮忙点赞、收藏、关注、评论啦~
源码获取:私信我
精彩专栏推荐⬇⬇⬇
Java项目
Python项目
安卓项目
微信小程序项目