一次消息阻塞问题排查过程
前言
背景问题
最近产线环境偶发会出现用户收不到别人给他发送的IM消息,同事邀请我一起排查,现象是:他们的连接状态看着正常,自己能发送消息,但是收不到,退出重新登录能恢复,而且每次出现都是一大批消息,问题挺严重。
知识铺垫
在问题展开之前,有必要先介绍下公司的IM消息收发模型

- 消息服务投递消息到指定的mq队列上;
- 每台长连接服务,从一个指定的mq队列上消费消息;
- 长连接服务维护了具体的终端连接池,拿到消息后,从池子里找到消息要投递的终端连接,通过网络IO将消息推出去;
- 客户端收到消息数据后,解析并显示到UI上;
问题分析
第一次分析
第一次出现问题时,首先是从消息投递和接收环节进行分析,得到如下信息:
- 从消息服务看,找了一条具体丢失的消息,发现消息服务是正常投递到mq的;
- 从client来看,与服务器的长连接是正常保持的(有noop心跳),中间没有断开连接,但确实没有收到此条消息;
- 从mq的WEB监控端来看,队列没有消息堆积,队列的消息是正常被消费的,并且手动造一个消息,也能发出去;
- 从长连接服务来看,上游与mq之间的连接并没有断开,下游与终端的长连接也没有断开,但却没有消息消费和处理消息的日志,包括在mq监控上人为造的假消息也没有收到;
- 通过tcpdump抓包发现,长连接服务所在机器已经收到消息的数据包,但应用程序却没有收到消息。
原因推测: 由于线上没有开pprof,拿不到程序的运行情况,只能初步推测问题可能发生在长连接服务内部的mq consumer上。看起来像是mq consumer遇到了某种预料之外的异常情况,导致内部出现阻塞,支撑这种猜想的一个理由是:我们的mq client很老,大概是2015年的版本。
给出的处理办法:
- mq连接上加过期检测:假设mq consumer有这样的阻塞问题,给mq连接上人为加一个心跳消息,每隔1分钟手动produce一个消息到mq队列上,如果连续3个心跳都没有收到,则断开mq重连;
- 更新mq库到最新版本;
- 打开产线的pprof,以备下一次出现时,抓下程序的运行情况;
看着上面的推测有根有据的,但上线没过多久,再一次出现,问题现象完全相同。
像以前一样,每次怀疑开源公共库有问题时,最后都会被无情的打脸,这次也不例外。
第二次分析
这次出现后首先想到的点是:自己给mq手动加的心跳过期检测和断开重连逻辑,看起来没有漏洞,为何没有生效呢?
在公司与同事讨论时,没有想明白。回家的路上,在晚风的吹拂下,突然想到一个可能的点:会不会是自己的程序出现死锁或被阻塞了?
于是,回到家后立刻验证自己的想法,首先让运维同学帮忙生成了进程 的goroutine运行状态信息,发现mq消费者线程被阻塞在recvmsg.go:64这行代码上,阻塞了1461分钟,如下图所示:
goroutine 32 [chan send, 1461 minutes]:
ucasserver/pool.handlerDefaultMsg(0x0, 0x0, 0xc00151c7b8, 0x2, 0x0, 0x0, 0x0, 0xc00244a2c0, 0x1, 0x4, ...)
/home/jenkins/workspace/Git_go_ucasserver_KickOff/pool/recvmsg.go:64 +0x1af
ucasserver/pool.RecvMsg(0xc001ba6500, 0x131, 0x131, 0x0, 0x1)
/home/jenkins/workspace/Git_go_ucasserver_KickOff/pool/recvmsg.go:27 +0x165
ucasserver/mq.createConsume(0xc000536b80, 0x11, 0xc000098300, 0x57)
/home/jenkins/workspace/Git_go_ucasserver_KickOff/mq/init.go:75 +0x57b
created by ucasserver/mq.Init
/home/jenkins/workspace/Git_go_ucasserver_KickOff/mq/init.go:18 +0x61
这块代码正好是mq收到消息后向pool线程分发消息的位置:

这时有必要先介绍下长连接服务内部的消息分发模型:

- 左边棕色部分的mq consumer线程,主要负责收消息,对header作一些的简单的检测和判断后,就丢给具体pool里的receive channel(golang里的一种异步带缓冲队列);
- 右边绿色部分的pool是一个个终端连接的池子,并同时启了一个goroutine循环从receive channel读消息,读到后就找到具体的connection,调用connection的write 方法将数据写出去;
- 一个长连接服务里固定起了100个pool, 终端建立连接时,根据hash算法来将连接分配到指定的pool上;
结合上面代码阻塞的位置,有经验的小伙伴就能猜到,pool里的receive channel应该是满了,进一步,这100个pool线程里面是不是有一个不运行了?
带着这个疑问,我们就去代码里看,如果程序异常退出,应该会defer阶段打印一条日志handle send msg panic occurred的
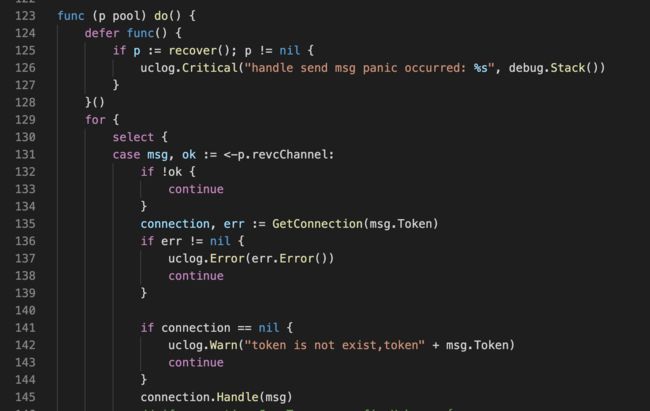
就去最近几天的日志里翻,果然被我们找到了:

这个pool线程崩在了gorilla/websocket/conn.go 610行,defer里这行日志打的有点粗糙,没有将panic的错误描述打出来。
不过这个难不到善于想办法的我们,找到gorilla库的源代码,看看conn.go 610行报了什么错:

熟悉websocket的同学看到这个描述就能想到问题所在,同一个连接上出现了多线程并发write, 接下来就完全看自己对服务代码的熟悉程度了。
原因和解法
涉及到公司里关键服务的源码,这里不便贴出,就直接说排查到的原因:
- 长连接服务里有三种消息:普通业务消息,noop心跳消息(与客户端的),close消息(告诉客户端连接关闭)
- 普通业务消息始终在指定的pool线程里,但noop和close这两个服务内部的特殊消息,是单独开了个线程去处理这块儿业务的,也就是这里会出现对同一个连接的并发写操作;
解法也比较简单:
- 涉及到对终端连接的所有读写操作,都归到同一个goroutine来处理,可以在select里加一个
case msg, ok := <-p.xxxChannel:, 专门用来接收和处理内部特殊消息。
总结
- 平时还是要多总结一些常见的并发问题,像map并发访问、连接并发读写、资源访问死锁等,这类问题是可以在设计方案阶段就避免的,而一旦出现就可能导致服务崩溃和僵死;
- 产线环境还是要留意打开pprof,原本出现第一次就应该找到原因的,由于拿不到关键信息就需要等故障再发生一次;
- 研发人员除了写代码,更多要关注下自身服务出故障时如何快速定位,日志应该输出哪些有用的信息,上产线时应该让运维监控哪些错误信息,很多同学都是出故障时才来补信息,很被动;
本文由博客一文多发平台 OpenWrite 发布!