读书笔记17:Adversarial Attacks on Neural Networks for Graph Data
https://arxiv.org/pdf/1805.07984.pdf
看过之后有一个思考,adversarial attack的目标是事先选定一个class,然后选择攻击方式,尽可能使得模型把样本分类成这个类别,并且class probability和原class的probability拉开差距,但是可不可以将目标设定为最小化原分类class的probability,也就是只将目标定位为使target被错误分类,而不管最终究竟将target分成什么类,这样还可能增加attack的效果,因为通过attack使得target被错分为不同的class_new的难度可能是不同的,指定一个class的话可能难以达成目标,但是不指定的话模型就可以随意进行错分,只要不分成原class就行。
这篇文章介绍了graph convolution model上的adversarial attack,通过这种研究,可以使得graph convolution的优势和缺点都表现出来。
首先,摘要部分,先介绍背景,深度学习模型在node classification这种任务上取得了不错的成绩,但是并没有研究探索用adversarial attack来验证这些模型的稳定性,但是像web这种领域,adversaries是很常见的。本文引入第一个研究attributed graph上进行adversarial attack的工作,主要关注使用graph convolution的模型。本文在node的feature和graph的结构上生成adversarial perturbation,由此将事件之间的依赖性(应该指的是对graph structure的操作)也被考虑在内。此外,perturbation都是微小的,重要的数据特征都是保留的,为了应对离散域的问题(应该指的是graph的结构,后文还会看到是什么意思),提出了NETTACK算法,这个算法采用incremental computation的方式(指的是当输入有一些小的改变的时候,不需要重新计算全部输出,只要将依赖于这一点点输入该变量的输出改变计算出来即可,这个估计是针对perturbation设计的)。最后从实验的角度介绍算法的性能,实验结果表明node classification的准确率即使在采用很少的一点perturbation的情况下也会明显下降。此外,本文采取的attack是可迁移的,学习出来的attack可以在只提供一点graph信息的情况下成功的对其他的node classification model进行成功的攻击。
introduction第一段先介绍graph data有多普遍,有多重要,然后引出graph data上最常用的模型之一就是节点分类的模型并对此模型简介。第二段过渡,指出近些年graph上深度学习的模型开始兴起,并且效果很好。第三段紧接着介绍说这种graph上的深度模型不仅仅依赖于每一个node本身的特征进行分类,而且还依赖于这些node之间的联系。第四段继续深入,提到说很多研究发现现在的深度模型都很容易被欺骗,由此打开了新世界的大门,对抗模型开始兴起,但是在graph deep learning这个领域还没有相关的研究。由此引出第五段和第六段,本文的模型正好填补这个空白,探索graph上的深度模型能否轻易被欺骗,这些模型有多可靠。第六段指出这个问题的答案不经过实际探索是很难得到的,一方面relation effect可能会增加网络的稳定性,因为每一个node的预测都不是仅仅基于自身的,而是基于很多node一起的;另一方面,node之间的relation也会使得“牵一发而动全身”,影响了一个node,与之相连的都会受到影响。接下来的两段分别介绍了这个问题带来的机遇与挑战。
技术部分,本文关注的graph deep learning主要是关注基于graph convolution的node classification(transductive的,训练时训练集和测试node都会参与)。卷积层可以表示为![]() ,本文考虑只有一层hidden layer的,表示为
,本文考虑只有一层hidden layer的,表示为![]() ,
,
接着介绍attack model,首先,模型的目标是对![]() 进行一个小的perturbation使其变成
进行一个小的perturbation使其变成![]() ,对A^0进行的是对结构的改变,称为structure attack,而对X进行的是feature attack。进行攻击是有目标的,例如想改变v0的预测值,那么这个v0就是target,直接对v0进行perturbation是direct attack,而通过对一些不包括v0在内的一个node set(是整个graph的node set的一个子集)进行攻击是influencer attack,也就是间接地通过节点间的相互影响对v0进行攻击。attack的任务可以被写作
,对A^0进行的是对结构的改变,称为structure attack,而对X进行的是feature attack。进行攻击是有目标的,例如想改变v0的预测值,那么这个v0就是target,直接对v0进行perturbation是direct attack,而通过对一些不包括v0在内的一个node set(是整个graph的node set的一个子集)进行攻击是influencer attack,也就是间接地通过节点间的相互影响对v0进行攻击。attack的任务可以被写作 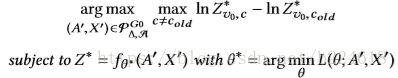
也就是攻击的目标在于使得目标节点的预测值和被攻击前的正确预测值之间的差距最大化,还有一点要注意的是预测模型的参数由θ变成了θ*,也就是要在perturbated的新模型上重新训练预测模型,使得这使得问题变成了一个bi-level的优化问题,增加了训练难度。一个简化的版本就是模型的θ不随着perturbation改变,θ是固定的。bi-level优化可以理解为尽可能的让预测模型能够成功预测,同时又让attack尽可能的捣乱。
adversarial attack的一个要求是改变要不明显,图像领域的衡量标准可以是改变完的图像肉眼看起来和原来差不多,但是graph上就很难这样用观察来衡量,或者用图像领域的标准来衡量改变是否符合要求。文章接下来就介绍unnoticeable perturbation,也就是不引人注意的扰动。作者分析这个问题从三个角度,第一个是一个简单直接的想法:
![]()
也就是节点feature的改变量和邻接矩阵的改变量的总和不能大于一个上限。但是作者认为,在一些复杂的情况下,这个上限可能需要定的比较大,但是我们依然希望能得到一些看起来很真实(就像图像领域的adversarial样本看起来要很真实),因此就需要开发新的衡量标准。
作者设计这个的时候从两个方面进行考虑,一个是图的结构,另一个是节点的特征。从图的结构入手考虑,就是graph structure preserving perturbation,作者认为graph structure的最主要的特征是degree distribution,通过这个可以很容易的将graph区分开。作者指出真实的网络中,degree distribution经常以一种类似于power-law的形式(一个变量和另一个变量的幂指数成正比),作者希望生成的perturbation也能和输入一样遵循类似的规则。这个衡量的过程大致是这样的:首先估计出原始graph的distribution的power-law like的参数α(也就是power-law的指数),一个获取这个指数的近似公式如下:
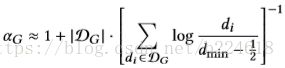
其中d_min是参与统计distribution的最小degree数,D_G是包含了每一个node的degree的集合。这个公式既可以估计原graph的α,也可以估计改变后的graph的α,同样,将两个graph的D_G合并起来也可以用同样的方式估计一个联合的![]() 。给定一个参数α_x,样本D_x的log-likelihood可以表示为
。给定一个参数α_x,样本D_x的log-likelihood可以表示为
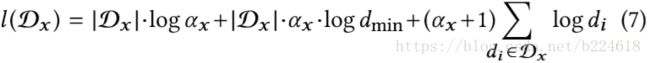
用log-likelihood score,可以进行显著性测试,估计两个graph是不是来自于同一个power-law distribution。建立两个对立的假设
![]()
最终的测试统计量可以写作
![]()
当样本的尺寸很大的时候,这个会服从一个单参数的卡方分布(这一部分统计的内容不是太懂,但是理解了这个是用来衡量两个graph的degree distribution分布的)。最终,可接受的perturbation要满足![]() 。
。
考虑节点特征来衡量的话是feature statistics preserving perturbation。为实现这个约束,本文采取了一个随机行走模型,首先建立一个graph ![]() ,F是feature的集合,
,F是feature的集合,![]() ,像一个邻接矩阵一样,标志着feature两两之间是否共同出现(co-occurence)在同一个graph中。将一个feature i加入到node u的feature set中要满足unnoticeable的条件,需要满足下式:
,像一个邻接矩阵一样,标志着feature两两之间是否共同出现(co-occurence)在同一个graph中。将一个feature i加入到node u的feature set中要满足unnoticeable的条件,需要满足下式:
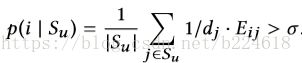
这个式子的含义是,从node u的feature set的所有feature出发,在graph C上进行一步随机行走,要是有相当大的概率能够到达feature i,那么将feature i加入到node u的feature set中就可以认为是unnoticeable的。一般来讲,![]() ,是从node u的feature set进行随机行走能够到达feature i的最大概率的一半。当然,如果feature i本身就在node u的feature set中,那么i出现肯定是可以接受的。总结一下,只有如下条件满足才行
,是从node u的feature set进行随机行走能够到达feature i的最大概率的一半。当然,如果feature i本身就在node u的feature set中,那么i出现肯定是可以接受的。总结一下,只有如下条件满足才行
![]()
但是根据这种法则生成对抗样本是很困难的,因为graph数据的不连续性,而且有的时候参数θ的数目巨大(这个指的应该是node classification中的graph convolution需要尺寸较大的weight matrix),因此,本文采取的是先在一个surrogate model上进行attack,得到一个attacked graph,这个graph接着被用来训练最终的模型。作者还指出这个方式事实上可以直接被视作迁移能力的检查,因为关注的是代理模型(surrogate model)。
为了得到一个易于处理但是依然能够保留graph convolution操作的surrogate model,前面说的
![]()
中的非线性用一个简单的线性激活函数代替,得到
![]()
由于模型的目标是使得目标节点的log-probablities的变化量最大,softmax可以忽略(应该是说是否使用softmax进行归一化不影响使得log-probabilities最大化这个操作)。也就是把log-probablities直接简化成![]() ,给定一个训练好的surrogate model,参数是W,那么surrogate loss表示为
,给定一个训练好的surrogate model,参数是W,那么surrogate loss表示为
![]()
也就是在输出的v0的所有class probability中,找到一个class,这个class和v0原来的分类结果不能是一个,而且这个class的class probability要在所有class probability中和原分类结的class probability相距最大,将这个类别的class probability和原class的probability之差作为loss,而下式就指出了目标就是选择各种可能的graph,使得这个loss最大,也就是事先已经选定了一个class,作为错误分类的目标,并使得分到这个类别的class probability尽可能的和原class的probability拉开差距。
而攻击的目标就变成了
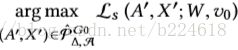
也就是在满足unnoticeable change的前提下尽可能的增大attack前后对target的预测值的差距。但是这个problem也不容易被实现,作者接着引入了scalable greedy approximation scheme。首先定义两个scoring function,用来衡量添加或删除feature或者edge之后得到的surrogate loss。
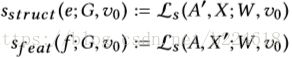
也就是一个structure方面的score,一个是feature方面的score。A'是A添加或删除一个edge得到的,X是X中的node u添加或删除一个feature得到的。整个attack的过程大致是这样的:给定一个当前状态![]() ,建立一个
,建立一个![]() ,包含了所有满足要求(unnoticeable)的(u,v),也就是edge(u,v)在0,1之间变化,表示着edge(u,v)的有无。在
,包含了所有满足要求(unnoticeable)的(u,v),也就是edge(u,v)在0,1之间变化,表示着edge(u,v)的有无。在![]() 中,选择一个使得log-probablities改变量最大的,也就是s_struct最大,同理在建立一个
中,选择一个使得log-probablities改变量最大的,也就是s_struct最大,同理在建立一个![]() ,进行相同的更新操作。更新之后graph就变成
,进行相同的更新操作。更新之后graph就变成![]() ,一直更新,直到超过衡量unnoticeable change的budget △。这个算被总结如下:
,一直更新,直到超过衡量unnoticeable change的budget △。这个算被总结如下:

要使得这个算法能够实际应用,有两个条件是要满足的,一个是s_struct和s_feat的计算要高效,另一个是能够高效的检查哪一个edge和feature的添加或删除是满足unnoticeable的。
score function的快速计算依赖于一个定理,当添加或者删除一个edge(m,n)的时候,有
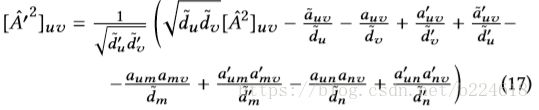
而
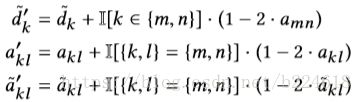
这个公式使得![]() 能够在一个常量级时间段内得以计算,并且是以一种incremental的方式,只需要对改变量进行计算。
能够在一个常量级时间段内得以计算,并且是以一种incremental的方式,只需要对改变量进行计算。
而对于feature attack来说,情况就简单得多,因为事先通过规则固定了要将target错分成哪一类,因此,选择最合适的node和feature只要对每一个node的feature进行求导即可

之后选择一个指向允许方向的,绝对值最大的,这个指向允许方向的意思是,每个feature的取值只有0,1,因此如果feature是0,那么梯度指向正值,那就是可以的方向,可以将这个feature的值改成1了,如果梯度指向负值,那不行,feature不能取负的。并且在algorithm1中可以看到,structure和feature的attack并不是两者同时进行,而是看哪个带来的score的上升比较大,就取哪一种攻击方式,攻击一次整个graph就变了,因此再实施第二种攻击其实是不合理的,因为情况变了要重新计算。还有一个注意的是,在简化问题使得问题变得tractable的时候,W是没有变化的,也就是说并不像之前所说的是一个bi-level问题,而是固定了模型。
最后介绍的是candidate set的快速计算,也就是attack的时候,结构的改变和feature的改变受到限制而得到的一些可以进行的改变而得到的集合,前面提到过的。由于budget △限制和feature的unnoticeable change限制都很好用incremental的方式来进行检测,需要处理的就是structure attack的constraint的快速检测,这就又依赖于一个定理
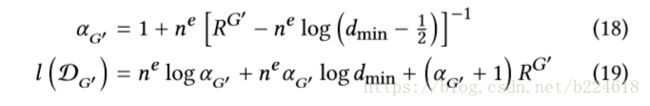
其中
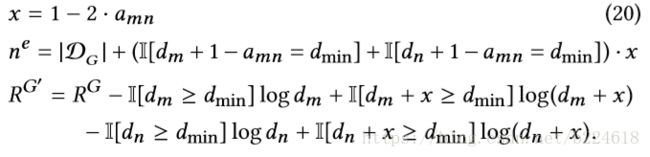
定理的证明不是重点,重要的是有了这条定理,![]() 也可以以一种incremental的方式计算,新graph的degree distribution的改变是否超出要求,也就好判断了。
也可以以一种incremental的方式计算,新graph的degree distribution的改变是否超出要求,也就好判断了。