代码阅读(1):adversarial-yolo
原文地址:https://arxiv.org/abs/1904.08653
代码地址:https://github.com/marvis/pytorch-yolo2
一、算法原理
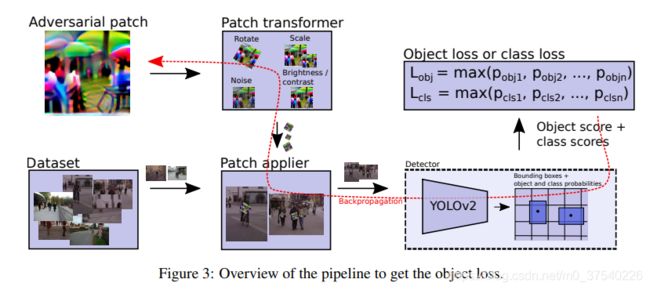
本文通过训练和添加对抗补丁,实现了一种untargeted攻击,可以使YOLOv2无法识别添加了补丁的人。本文的算法思想如下:
首先将随机生成的对抗补丁贴在图片上,此处应注意本文的对抗补丁的位置并不是任意的,一般是贴在需要被攻击的目标(此处是人)的中心。为了准确的将补丁贴到对应位置,adversarial-yolo算法会从label中找到图片中的目标位置,再向这些位置添加补丁。
添加补丁前,adversarial-yolo会对补丁进行旋转、加噪声、改变亮度等操作,这些操作是为了增加补丁在现实环境中的性能。
在添加完补丁后,将图像传入YOLO模型进行检测,使用YOLO的输出和补丁的一些性质计算loss,loss分三部分,如下:
- dev_loss:yolo输出的置信度
- nps_loss:non-printability score,表示patch不可打印的程度。
- tv_loss:total variation,越小图像越平滑。
dev_loss是最重要的一个loss,说白了,它就是分类置信度(某个网格中存在目标的概率)和目标置信度(某个网格中的目标是某特定类的概率,比如人)的乘积的最大值,这个loss反映的是YOLO模型输出的置信度,我们的目标是要最小化这个置信度,故将其直接用于loss。
nps_loss指补丁无法被打印的程度,它的计算方法如下。c表示所有打印机能打印出的颜色。设置这个loss的目的是为了让生成的补丁能更准确的被打印出来,提高其在现实场景攻击的性能。

tv_loss为相邻像素点的欧式距离,表示图像的平滑程度,平滑变换的图像看上去显得比较真实,也能增加攻击的鲁棒性。
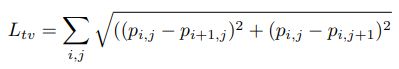
最后的loss = α * tv_loss + β * nps_loss + dev_loss,对这个总loss进行后向传播,就可以更新补丁了。
二、关键代码
1、数据读取补丁的生成和处理
此处对应项目中的load_data.py文件下对于数据读取和补丁添加与处理相对的内容,主要有以下代码:
# 用于对补丁进行各种变换
class PatchTransformer(nn.Module):
...
# 向图片上添加补丁
class PatchApplier(nn.Module):
...
# 读取Inria数据集中的数据,这个数据集可在‘http://pascal.inrialpes.fr/data/’中下载
# 主要类别就是human
class InriaDataset(Dataset):
...关于这些代码的细节不是很重要,这里就不写了,感兴趣可以自行研究一下。
2、Loss的计算
本部分代码对应load_data.py中的相应部分。
上面说到,文章中loss的计算被分为了三个部分,首先是dev_loss的计算。dev_loss实际上就是YOLO输出的置信度,要解释如何计算dev_loss,首先需要理解YOLOv2的输出格式。本文所使用的YOLO模型最终会输出一个[batch, 5, 85, 19, 19]大小的tensor,其中batch即输入的组数,剩下四个量的意义为:
- 5指的是5个anchor boxes(默认)
- 85是每个格子的输出向量,由bx,by,bw,bh,pc和80个分类的预测概率组成,其中第一个分类(索引号为5)是person
- 19为输出的特征图大小,因为yolo的格子数一般默认定义为19x19
我们所需要的loss就是分类置信度(pc)和一个分类(此处是human)的预测概率。故代码中首先将YOLO的输出变为了[batch, 85, 1805],因为我们需要的东西都在这85组值里,然后提取两个概率:
# 分类置信度,即pc,是85组数里的第5个(序号4),用sigmond处理转化为概率
output_objectness = torch.sigmoid(output[:, 4, :])
# 抛弃掉前五个值,只留后面的目标置信度
output = output[:, 5:5 + self.num_cls , :]
# 用softmax处理转化为概率
normal_confs = torch.nn.Softmax(dim=1)(output)
# 找到我们需要的那一组,此处cls_id==0,类别是human
confs_for_class = normal_confs[:, self.cls_id, :]之后将这两个概率相乘取最大值就是我们需要的dev_loss了。
confs_if_object = confs_for_class * output_objectness
max_conf, max_conf_idx = torch.max(confs_if_object, dim=1)此部分注释过的代码如下:
class MaxProbExtractor(nn.Module):
# cls_id表示分类的结果,num_cls代表分类数量,设置的是0,80 可更改
def __init__(self, cls_id, num_cls, config):
super(MaxProbExtractor, self).__init__()
self.cls_id = cls_id
self.num_cls = num_cls
self.config = config
def forward(self, YOLOoutput):
# get values neccesary for transformation
if YOLOoutput.dim() == 3:
YOLOoutput = YOLOoutput.unsqueeze(0)
# yolo的输出为[batch, 5,85, 19, 19]
batch = YOLOoutput.size(0)
assert (YOLOoutput.size(1) == (5 + self.num_cls ) * 5)
h = YOLOoutput.size(2)
w = YOLOoutput.size(3)
# 以下三行把输出转化为方便我们处理的格式
output = YOLOoutput.view(batch, 5, 5 + self.num_cls , h * w) # [batch, 5, 85, 361]
output = output.transpose(1, 2).contiguous() # [batch, 85, 5, 361]
output = output.view(batch, 5 + self.num_cls , 5 * h * w) # [batch, 85, 1805]
# 输出向量的85个值中,4号值是pc,也就是格子中存在目标的置信度
output_objectness = torch.sigmoid(output[:, 4, :]) # [batch, 1805]
# 抛弃掉前五个值,只保留后面的80个cls置信度
output = output[:, 5:5 + self.num_cls , :] # [batch, 80, 1805]
normal_confs = torch.nn.Softmax(dim=1)(output)
# 提取出自己感兴趣的分类的置信度,此处cls_id为0,故分类是person
confs_for_class = normal_confs[:, self.cls_id, :]
# 使用分类置信度和目标置信度的乘积作为对抗样本的loss
confs_if_object = output_objectness #confs_for_class * output_objectness
confs_if_object = confs_for_class * output_objectness
confs_if_object = self.config.loss_target(output_objectness, confs_for_class)
# 输出最大的置信度和其中心格子的编号
max_conf, max_conf_idx = torch.max(confs_if_object, dim=1)
return max_conf接下来是nps_loss,计算方法是列出一个打印机可打印颜色的文档,本项目中该文件的位置为/non_printability/30values.txt,接着求出补丁里的像素与可打印颜色表中值的最小距离作为nps_loss,此部分代码如下:
class NPSCalculator(nn.Module):
def __init__(self, printability_file, patch_side):
super(NPSCalculator, self).__init__()
self.printability_array = nn.Parameter(self.get_printability_array(printability_file, patch_side),requires_grad=False)
def forward(self, adv_patch):
# 计算补丁中的颜色与可打印性数组中的颜色之间的欧几里德距离
color_dist = (adv_patch - self.printability_array+0.000001)
color_dist = color_dist ** 2
color_dist = torch.sum(color_dist, 1)+0.000001
color_dist = torch.sqrt(color_dist)
# 每组中最小的距离是我们需要的
color_dist_prod = torch.min(color_dist, 0)[0]
# 相加即为我们要求的nps_loss
nps_score = torch.sum(color_dist_prod, 0)
nps_score = torch.sum(nps_score, 0)
# torch.numel() 返回一个tensor变量内所有元素个数
return nps_score/torch.numel(adv_patch)
# 这个函数读取可打印颜色表生成可以跟补丁像素相减的矩阵
def get_printability_array(self, printability_file, side):
printability_list = []
with open(printability_file) as f:
for line in f:
printability_list.append(line.split(","))
printability_array = []
for printability_triplet in printability_list:
printability_imgs = []
red, green, blue = printability_triplet
printability_imgs.append(np.full((side, side), red))
printability_imgs.append(np.full((side, side), green))
printability_imgs.append(np.full((side, side), blue))
printability_array.append(printability_imgs)
printability_array = np.asarray(printability_array)
printability_array = np.float32(printability_array)
pa = torch.from_numpy(printability_array)
return pa最后是tv_loss,比较容易理解,按照上面的公式计算即可。代码如下:
class TotalVariation(nn.Module):
def __init__(self):
super(TotalVariation, self).__init__()
def forward(self, adv_patch):
tvcomp1 = torch.sum(torch.abs(adv_patch[:, :, 1:] - adv_patch[:, :, :-1]+0.000001),0)
tvcomp1 = torch.sum(torch.sum(tvcomp1,0),0)
tvcomp2 = torch.sum(torch.abs(adv_patch[:, 1:, :] - adv_patch[:, :-1, :]+0.000001),0)
tvcomp2 = torch.sum(torch.sum(tvcomp2,0),0)
tv = tvcomp1 + tvcomp2
return tv/torch.numel(adv_patch)3、训练过程
训练过程需要把我们上面说的各个步骤结合起来。首先需要随机生成一个补丁,将其变换后添加至图片上,随后计算loss,最后根据loss进行后向过程更新补丁。
注释的关键代码如下:
class PatchTrainer(object):
def __init__(self, mode):
self.config = patch_config.patch_configs[mode]()
self.darknet_model = Darknet(self.config.cfgfile)
self.darknet_model.load_weights(self.config.weightfile)
self.darknet_model = self.darknet_model.eval().cuda()
self.patch_applier = PatchApplier().cuda()
self.patch_transformer = PatchTransformer().cuda()
self.prob_extractor = MaxProbExtractor(0, 80, self.config).cuda()
self.nps_calculator = NPSCalculator(self.config.printfile, self.config.patch_size).cuda()
self.total_variation = TotalVariation().cuda()
self.writer = self.init_tensorboard(mode)
def train(self):
# 设置输入图片大小
img_size = self.darknet_model.height
# 设置训练batch大小
batch_size = self.config.batch_size
# 设置训练循环数字
n_epochs = 1000
# 最大标签数
max_lab = 14
time_str = time.strftime("%Y%m%d-%H%M%S")
# 通过torch.full等函数生成patch,可以生成灰度和彩色的补丁
adv_patch_cpu = self.generate_patch("gray")
# 读取一个生成好的patch
adv_patch_cpu = self.read_image("saved_patches/patchnew0.jpg")
# 为adv_patch_cpu赋值requires_grad为True,对于需要求导的tensor,其requires_grad属性必须为True
adv_patch_cpu.requires_grad_(True)
# 此函数参数为dataset:应用数据库 batch_size:输入组大小 shuffle:是否打乱数据。默认设置为False。
train_loader = torch.utils.data.DataLoader(InriaDataset(self.config.img_dir, self.config.lab_dir, max_lab, img_size,
shuffle=True),
batch_size=batch_size,
shuffle=True,
num_workers=10)
# 每一训练循环长度
self.epoch_length = len(train_loader)
print('One epoch is {len(train_loader)}',len(train_loader))
#设置优化函数,
'''
params (iterable) – 待优化参数的iterable或者是定义了参数组的dict
lr (float, 可选) – 学习率(默认:1e-3)
betas (Tuple[float, float], 可选) – 用于计算梯度以及梯度平方的运行平均值的系数(默认:0.9,0.999)
eps (float, 可选) – 为了增加数值计算的稳定性而加到分母里的项(默认:1e-8)
weight_decay (float, 可选) – 权重衰减(L2惩罚)(默认: 0
则下述代码的含义为优化输入的patch
'''
optimizer = optim.Adam([adv_patch_cpu], lr=self.config.start_learning_rate, amsgrad=True)
# 当网络的评价指标不在提升的时候,可以通过降低网络的学习率来提高网络性能
scheduler = self.config.scheduler_factory(optimizer)
# 计时器
et0 = time.time()
# 遍历设置的整个循环
for epoch in range(n_epochs):
ep_det_loss = 0
ep_nps_loss = 0
ep_tv_loss = 0
ep_loss = 0
bt0 = time.time()
# Tqdm为进度条api
for i_batch, (img_batch, lab_batch) in tqdm(enumerate(train_loader), desc='Running epoch {epoch}',
total=self.epoch_length):
# autograd.detect_anomaly() 用于检测loss等值
with autograd.detect_anomaly():
# 将数据输入cuda
img_batch = img_batch.cuda()
lab_batch = lab_batch.cuda()
adv_patch = adv_patch_cpu.cuda()
# 对对抗adv_patch进行转换,例如加随机噪声,加亮度等等
adv_batch_t = self.patch_transformer(adv_patch, lab_batch, img_size, do_rotate=True, rand_loc=False)
# 在所有的训练图片上添加patch
p_img_batch = self.patch_applier(img_batch, adv_batch_t)
# 上下采样模块
p_img_batch = F.interpolate(p_img_batch, (self.darknet_model.height, self.darknet_model.width))
# 显示当前的添加了patch的图像,调试用的,平时注释
img = p_img_batch[1, :, :,]
img = transforms.ToPILImage()(img.detach().cpu())
# 生成yolo的原始处理结果
output = self.darknet_model(p_img_batch)
# 获取原始的三个loss
max_prob = self.prob_extractor(output)
print("max_prob",max_prob)
nps = self.nps_calculator(adv_patch)
tv = self.total_variation(adv_patch)
# 设置loss的权重超参数
nps_loss = nps*0.01
tv_loss = tv*2.5
# 对所有batch的置信度求平均作为最终det_loss
det_loss = torch.mean(max_prob)
# 最终的loss
loss = det_loss + nps_loss + torch.max(tv_loss, torch.tensor(0.1).cuda())
# 用于显示的loss
ep_det_loss += det_loss .cpu().numpy()
ep_nps_loss += nps_loss.detach().cpu().numpy()
ep_tv_loss += tv_loss.detach().cpu().numpy()
ep_loss += loss
# 执行后向过程,更新patch
loss.backward()
optimizer.step()
optimizer.zero_grad()
adv_patch_cpu.data.clamp_(0,1) #keep patch in image range
bt1 = time.time()
# 显示一些中间的结果
if i_batch % 5 == 0:
iteration = self.epoch_length * epoch + i_batch
self.writer.add_scalar('total_loss', loss.detach().cpu().numpy(), iteration)
self.writer.add_scalar('loss/det_loss', det_loss.detach().cpu().numpy(), iteration)
self.writer.add_scalar('loss/nps_loss', nps_loss.detach().cpu().numpy(), iteration)
self.writer.add_scalar('loss/tv_loss', tv_loss.detach().cpu().numpy(), iteration)
self.writer.add_scalar('misc/epoch', epoch, iteration)
self.writer.add_scalar('misc/learning_rate', optimizer.param_groups[0]["lr"], iteration)
self.writer.add_image('patch', adv_patch_cpu, iteration)
if i_batch + 1 >= len(train_loader):
print('\n')
else:
del adv_batch_t, output, max_prob, det_loss, p_img_batch, nps_loss, tv_loss, loss
torch.cuda.empty_cache()
bt0 = time.time()
et1 = time.time()
# 显示训练完成的最终结果
ep_det_loss = ep_det_loss/len(train_loader)
ep_nps_loss = ep_nps_loss/len(train_loader)
ep_tv_loss = ep_tv_loss/len(train_loader)
ep_loss = ep_loss/len(train_loader)
scheduler.step(ep_loss)
if True:
print(' EPOCH NR: ', epoch),
print('EPOCH LOSS: ', ep_loss)
print(' DET LOSS: ', ep_det_loss)
print(' NPS LOSS: ', ep_nps_loss)
print(' TV LOSS: ', ep_tv_loss)
print('EPOCH TIME: ', et1-et0)
del adv_batch_t, output, max_prob, det_loss, p_img_batch, nps_loss, tv_loss, loss
torch.cuda.empty_cache()
et0 = time.time()
# 随机生成一个补丁
def generate_patch(self, type):
...
# 读取一个已经训练好的补丁
def read_image(self, path):
...