深度学习-Tensorflow Keras使用函数式API构建复杂模型
在深度学习中,并非所有的网络结构都是顺序神经网络,还存在非顺序神经网络,比如有多个输入或者输出的网络,比较典型的是“Wide&Deep”网络(Heng-Tze Cheng et al.,Wide & Deep Learning for Recommender Systems), 此时就需要使用函数式API来构建复杂的网络了。
Wide&Deep网络
如下图Wide&Deep网络,将所有或者部分输入直接连接到输出层,这种架构能使神经网络学习深度模式(使用深度路径)和简单规则(通过短路径),而常规的MLP使所有的数据流经整个层。
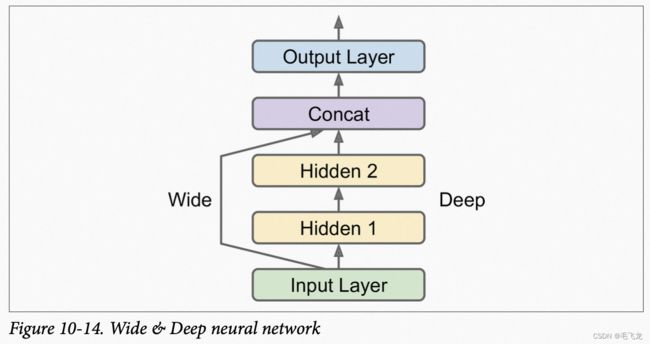
使用Keras,该网络可以表述为:
input_ = keras.layers.Input(shape=X_train.shape[1:])
hidden1 = keras.layers.Dense(30, activation="relu")(input_)
hidden2 = keras.layers.Dense(30, activation="relu")(hidden1)
concat = keras.layers.concatenate([input_, hidden2])
output = keras.layers.Dense(1)(concat)
model = keras.models.Model(inputs=[input_], outputs=[output])我们来看没一行代码:
- 首先,我们创建了一个Input对象,这是模型需要的输入类型规范,包括shape和dtpye
- 我们创建了一个包含30个神经元的Dense层(hidden1),其输入为Input_层,这一步就像调用函数一样,因此称之为函数式API
- 我们创建了第二个包含30个神经元的Dense层(hidden2),其输入为hidden_层
- 接下来,我们创建一个Concatenate层,使用它来合并输入层和第二个隐藏层的输出
- 然后我们创建具有单个神经元切没有激活函数的输出层,将合并层的结果传递给他。
- 最后,我吗创建了一个Keras Model,指定要使用的输入和输出。
一旦构建了Keras模型,一切都和之前一样,编译模型、训练、评估和使用它进行预测。
model.compile(loss="mean_squared_error", optimizer=keras.optimizers.SGD(lr=1e-3))
history = model.fit(X_train, y_train, epochs=20,
validation_data=(X_valid, y_valid))
mse_test = model.evaluate(X_test, y_test)
y_pred = model.predict(X_new)
Wide&Deep网络 多输入
如果想通过宽路径输入特征的子集,而通过深路径送入特征的另一个子集,在这种情况下,需要使用多输入。比如假设我吗要通过宽路径输入5个特征(特征0到4),通过深路径送入6个特征(特征2到7)。
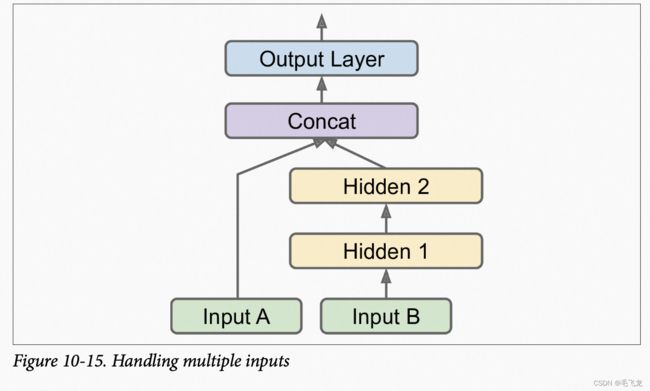
模型网络层定义代码如下:
input_A = keras.layers.Input(shape=[5], name="wide_input")
input_B = keras.layers.Input(shape=[6], name="deep_input")
hidden1 = keras.layers.Dense(30, activation="relu")(input_B)
hidden2 = keras.layers.Dense(30, activation="relu")(hidden1)
concat = keras.layers.concatenate([input_A, hidden2])
output = keras.layers.Dense(1, name="output")(concat)
model = keras.models.Model(inputs=[input_A, input_B], outputs=[output])此时,我们在调用fit()方法时,必须要传入一对矩阵(X_train_A, X_train_B),而不是传入单个矩阵X_train,调用evaluate()或predict()方法时也一样。
model.compile(loss="mse", optimizer=keras.optimizers.SGD(lr=1e-3))
X_train_A, X_train_B = X_train[:, :5], X_train[:, 2:] # train_A 0到4列,train_B 2到6列
X_valid_A, X_valid_B = X_valid[:, :5], X_valid[:, 2:]
X_test_A, X_test_B = X_test[:, :5], X_test[:, 2:]
X_new_A, X_new_B = X_test_A[:3], X_test_B[:3] # 只选取3个样本查看结果
history = model.fit((X_train_A, X_train_B), y_train, epochs=20,
validation_data=((X_valid_A, X_valid_B), y_valid))
mse_test = model.evaluate((X_test_A, X_test_B), y_test)
y_pred = model.predict((X_new_A, X_new_B))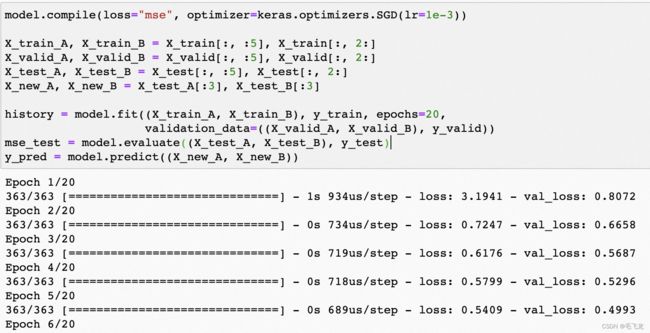
Wide&Deep网络 多输出
在许多场景中,可能需要多少个输出
- 想在图片中定位和分类主要物体,既涉及回归任务(查找物体的中心坐标、宽度和高度),又是分类任务
- 基于同一个数据的多个独立任务。比如,对面部图片进行多分类任务,使用一个输出对面部表情进行分类,使用另一个任务识别他们是否戴着眼镜。虽然也可以针对每个独立的任务单独训练一个神经网络,但是在多数情况下,通过一个网络训练多个独立任务往往能得到更好的结果。
- 正则化技术应用。

input_A = keras.layers.Input(shape=[5], name="wide_input")
input_B = keras.layers.Input(shape=[6], name="deep_input")
hidden1 = keras.layers.Dense(30, activation="relu")(input_B)
hidden2 = keras.layers.Dense(30, activation="relu")(hidden1)
concat = keras.layers.concatenate([input_A, hidden2])
output = keras.layers.Dense(1, name="main_output")(concat)
# 添加一个辅助输出,在训练的时候,也可以计入Loss
aux_output = keras.layers.Dense(1, name="aux_output")(hidden2)
model = keras.models.Model(inputs=[input_A, input_B],
outputs=[output, aux_output])这种情况下,每个输出都需要有自己的损失函数,因此,当我们在编译模型的时候, 应该传递一系列损失。默认情况下,Keras将计算所有的这些损失,并将他们简单累加得到用于训练的最终损失。由于我们更加关心主要输出而不是辅助输出(因为它仅仅用于正则化),因此我们需要给主要输出更大的权重。
model.compile(loss=["mse", "mse"], loss_weights=[0.9, 0.1], optimizer=keras.optimizers.SGD(lr=1e-3))
history = model.fit([X_train_A, X_train_B], [y_train, y_train], epochs=20,
validation_data=([X_valid_A, X_valid_B], [y_valid, y_valid]))
当评估模型时,Keras将返回总损失以及所有单个损失,同样当预测时,Keras 将为每个输出返回预测值。
# 评估时返回总损失,以及单个任务损失
total_loss, main_loss, aux_loss = model.evaluate(
[X_test_A, X_test_B], [y_test, y_test])
# 预测时,为每个任务输出预测值
y_pred_main, y_pred_aux = model.predict([X_new_A, X_new_B])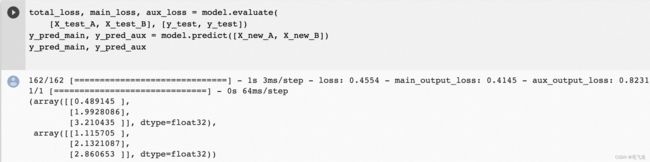
注:X_new_A只有3个样本,因此输入结果为一个长度为3的数组。