线程篇——线程池
线程池
为什么需要线程池
经过前面对线程的学习,我们会发现创建线程看起来很简单,new Thread()就完事儿了。但是Java的线程与操作系统的线程是一一对应的,创建线程需要调用操作系统内核的API,然后操作系统需要为它分配一系列的资源,同样销毁线程也需要调用操作系统内核的API。而系统调用,就意味着会面临上下文切换,并且线程的创建与回收也会对应着内存的分配与回收,因此可以说创建线程是一件成本相对较高的事情,要避免频繁的创建与销毁。
那我们就需要有个地方,可以保存创建好的线程,需要的时候去里面拿就行了,用完了放回去,以便下次可以继续使用。
线程池的优点
- 在执行大量异步任务时提供改进的性能,这是因为减少了每个任务的调用开销;
- 提供了一种方法来限制和管理执行任务集合时消耗的资源,包括线程
- 同时,每个ThreadPoolExecutor还维护一些基本统计信息,例如已完成任务的数量。
线程池的设计
我们希望的线程池
我们认为的线程池往往是这样的:

需要的时候我们去线程池获取线程,然后执行我们的业务逻辑,执行完了就把线程归还给线程池。
但是很遗憾,我们会发现并发包中线程池相关的工具类,没有一个是这么设计的。
实际上的线程池
实际上我们通常是这样使用线程池的:
public static void main(String[] args) {
//创建线程池
ExecutorService executorService = new ThreadPoolExecutor(4, 4,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
//执行任务
for (int i = 0; i < 5; i++) {
executorService.execute(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + "say " +
":hello~~");
}
});
}
}
实际上线程池的使用方是生产者,而线程池本身是消费者,来执行任务。
其实这里有两个角色:
- 工作线程
- 任务队列
简易版的线程池实现
简化版的线程池模型

代码实现简易版线程池
public class UseCase {
public static void main(String[] args) {
//创建线程池
FakeThreadPool fakeThreadPool = new FakeThreadPool(new LinkedBlockingDeque<>(2), 10);
//执行任务
for (int i = 0; i < 5; i++) {
fakeThreadPool.execute(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + "say " +
":hello~~");
}
});
}
}
}
class FakeThreadPool {
//任务队列
BlockingQueue<Runnable> taskQueue;
//工作线程
List<WorkThread> workThreads = new ArrayList<>();
public FakeThreadPool(BlockingQueue<Runnable> taskQueue, int workerNums) {
this.taskQueue = taskQueue;
for (int i = 0; i < workerNums; i++) {
WorkThread worker = new WorkThread(taskQueue);
worker.start();
workThreads.add(worker);
}
}
void execute(Runnable task) {
//简单的说明下原理 用add并且没处理任务数量超过可容纳限度的情况
taskQueue.add(task);
}
}
class WorkThread extends Thread {
//任务队列
BlockingQueue<Runnable> taskQueue;
public WorkThread(BlockingQueue<Runnable> taskQueue) {
this.taskQueue = taskQueue;
}
@Override
public void run() {
//循环从任务队列中获取任务并执行
while (true) {
try {
Runnable task = taskQueue.take();
task.run();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
在我们模拟的线程池中,初始化的时候入参传入任务队列与工作线程的容量,构造函数里就让工作线程一直从任务队列中取任务然后执行,然后再在excute方法中往任务队列中去添加任务。
线程池相关工具类
Executor框架
先看下Executor接口中跟线程池相关的类图:

- Executor 是一个基础的接口,其初衷是将任务提交和任务执行细节解耦,它只有一个方法,就是执行Runnable
void execute(Runnable command)
- ExecutorService接口是对Executor的进一步扩展,不仅提供对线程任务的管理功能,比如 shutdown、shutdownNow等方法,也提供了更加全面的提交任务机制,如返回Future而不是 void 的 submit 方法。
<T> Future<T> submit(Callable<T> task);
- JDK提供了几种基础实现,比如ThreadPoolExecutor、ScheduledThreadPoolExecutor、ForkJoinPool。这些线程池的设计特点在于其高度的可调节性和灵活性,以尽量满足复杂多变的实际应用场景。
- 还有一个Executors,它从简化使用的角度,为我们提供了各种方便的静态工厂方法。
核心的ThreadPoolExecutor
在Java提供的线程池相关工具类中,最核心的是ThreadPoolExecutor。从名字可以看出,它更侧重的是Executor。
我们知道很多线程池,比如 Executors.newCachedThreadPool(无界线程池)、 Executors.newFixedThreadPool(固定大小的线程池) 、 Executors.newSingleThreadExecutor(单一线程池) 、Spring的ThreadPoolTaskExecutor,但是实际上,它们都是调用的ThreadPoolExecutor的构造函数创建的,所以下面学习下ThreadPoolExecutor。
ThreadPoolExecutor参数
在Java提供的线程池相关工具类中,最核心的就是ThreadPoolExecutor。从名字可以看出,它更侧重的是Executor,我们来看下它的构造函数源码:
/**
* Params:corePoolSize – the number of threads to keep in the pool, even if they are idle, unless allowCoreThreadTimeOut is set
* maximumPoolSize – the maximum number of threads to allow in the pool
* keepAliveTime – when the number of threads is greater than the core, this is the maximum time that excess idle threads will wait for new tasks before terminating.
* unit – the time unit for the keepAliveTime argument
* workQueue – the queue to use for holding tasks before they are executed. This queue will hold only the Runnable tasks submitted by the execute method.
* threadFactory – the factory to use when the executor creates a new thread
* handler – the handler to use when execution is blocked because the thread bounds and queue capacities are reached
*/
ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
-
corePoolSize:核心线程数(线程池中要保留的线程数,哪怕它们处于空闲状态也不会被回收)
-
maximumPoolSize:最大线程池容量
-
keepAliveTime:空闲的非核心线程的最大空闲时间
-
unit:keepAliveTime的单位
-
workQueue:任务队列
-
threadFactory:创建线程的线程工厂
-
handler:任务的拒绝策略
ThreadPoolExecutor提供了四种拒绝策略:
-
AbortPolicy
默认的拒绝策略,会抛出RejectedExecutionException异常
-
CallerRunsPolicy
让提交任务的线程自己去执行任务
-
DiscardOldestPolicy
丢弃最老的任务
-
DiscardPolicy
直接丢弃任务,不抛出任何异常
ctl
在刚的excute方法中看到一个很重要的参数:ctl,它是ThreadPoolExecutor核心成员变量之一,定义如下:
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
ctl是个AtomicInteger原子类型的int整数,主要有两个作用,用高3位表示线程池的状态,低29位来表示线程的数量:
- workerCount:线程池中正在运行任务的线程数量
- runState:线程池的运行状态
ThreadPoolExecutor的线程创建流程
我们看下excute方法的源码:
int c = ctl.get();
//如果工作线程数量小于核心线程数量,就创建新的线程
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
//线程池的状态可能会变化
c = ctl.get();
}
//判断线程池状态,如果状态正常并且可以入队
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
//再次判断线程池状态,如果状态异常,就从队列中移除任务并且拒绝任务
if (! isRunning(recheck) && remove(command))
reject(command);
//如果可运行的线程数为0,就创建非核心线程,注意这个时候addWorker并没有传入任务,说明只会创建线程但是不会执行
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
//走到这里说明队列满了并且核心线都在运行,这个时候就尝试创建非核心线程去执行任务,如果创建失败就拒绝任务
else if (!addWorker(command, false))
reject(command);
实际上,excute被分为三种情况:
如果现在的线程数量<核心线程数量,那么就会调用线程工厂创建一个新的线程去执行任务(也就是说哪怕现在线程池中有空闲的线程,只要线程数量<核心线程数,就会创建新线程)
如果现在线程数量>=核心线程数量(这里会双重检查),就会往等待队列中去放
如果线程数量>=核心线程数量并且等待队列也满了,那么就会去创建非核心线程,直到线程数量>最大线程池容量,就会按照设定的拒绝策略去拒绝
流程图

至于为什么会有corePoolSize、maximumPoolSize、workQueue,我个人理解是可以更好的按照需求去定制不同的线程池,制定线程池的空闲线程回收策略。比如当corePoolSize=maximumPoolSize,那么线程池就固定这个大小,比如corePoolSize:2,workQueue是无界队列,那么这个线程池就没有容量上限,又比如corePoolSize:2,workQueue有界队列2,maximumPoolSize:6,那么如果一直只有五个线程在工作,那么第六个非核心线程的空闲时间超过设定的keepAliveTime,这个线程就可以被回收掉。
Worker
worker是被包装了下真正执行任务的线程,它本身继承了AQS,又实现了Runnable,本身是个可执行的任务,并且实现了不可重入互斥锁,防止在执行任务的时候受到setCorePoolSize动态调整线程池参数的影响。
private final class Worker
extends AbstractQueuedSynchronizer
implements Runnable
{
//执行任务的线程
final Thread thread;
//要执行的任务
Runnable firstTask;
Worker(Runnable firstTask) {
setState(-1); // 初始化的时候将锁状态初始化-1
this.firstTask = firstTask;
//将worker自己作为要执行的Runnable任务传给ThreadFactory去创建线程
this.thread = getThreadFactory().newThread(this);
}
...
}
线程池执行任务的excute方法中,我们看到真正执行任务的代码是t.start () 执行 Worker,而Woker在初始化时,this.thread = getThreadFactory ().newThread (this),Worker(this) 是作为新建线程的构造器入参的,所以 t.start () 会执行到 Worker 的 run 方法上:
public void run() {
runWorker(this);
}
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // 允许中断
boolean completedAbruptly = true;
try {
// task 为空的情况:
// 1:任务入队列了,极限情况下,发现没有运行的线程,于是新增一个线程;
// 2:线程执行完任务执行,再次回到 while 循环。
// 如果 task 为空,会使用 getTask 方法阻塞从队列中拿数据,如果拿不到数据,会阻塞住
while (task != null || (task = getTask()) != null) {
w.lock();
//如果线程池在stop 中,但是线程没有到达中断状态,就帮助线程中断
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
//执行 before 钩子函数
beforeExecute(wt, task);
Throwable thrown = null;
try {
//执行任务
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
//执行 after 钩子函数,如果这里抛出异常,会覆盖 catch 的异常
afterExecute(task, thrown);
}
} finally {
//任务执行完成,解锁,并且统计已完成的任务数量
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
//异常的善后工作
processWorkerExit(w, completedAbruptly);
}
}
执行方法的流程大概如下:

线程池的生命周期
根据源码中对ctl的注释,ThreadPoolExecutor线程池的生命周期状态共有以下几种:
- RUNNING:接受新任务或者处理队列里的任务
- SHUTDOWN:不接受新任务,但仍在处理已经在队列里面的任务
- STOP:不接受新任务,也不处理队列中的任务,对正在执行的任务进行中断
- TIDYING:所以任务都被中断,workerCount 是 0,整理状态
- TERMINATED:terminated() 已经完成的时候
ThreadPoolExecutor线程池的生命周期状态流转图:

Spring的线程池ThreadPoolTaskExecutor
这个是spring实现的线程池,我们来看下它的继承关系:
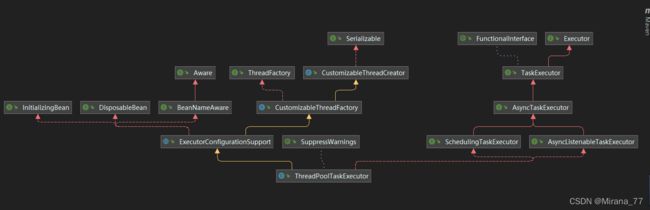
简单的阅读了下源码,它内部的线程池也是通过ThreadPoolExecutor实现的(模板模式,ThreadPoolExecutor作为ThreadPoolTaskExecutor的成员变量),对它做了些扩展,如:支持传入TaskDecorator对Runnable任务进行包装;支持用submit提交任务,获取任务的返回值(类型Future),也支持通过submitListenable提交任务,此时返回类型是ListenableFuture。
使用线程池的注意事项
其实CachedThreadPool、FixedThreadPool、SingleThreadExecutor这三种线程池都不太建议使用,它们各有各的优缺点,而且大部分是无界队列,而且都不支持自定义拒绝策略与线程工厂。如阿里巴巴开发规范中推荐的,不要使用Executors的线程池,自己通过ThreadPoolExecutor来按需求创建线程池。
使用默认的拒绝策略也需要注意,因为抛出的RejectedExecutionException异常是运行时异常,编译器并不会强制去处理。而使用excute方法提交任务时,如果任务执行的过程中出现运行时异常,执行任务的线程也会终止,但是如果不加处理也不会收到任何通知。所以,最好参考下面的方法处理:
try{
//业务
}catch (RuntimeException runtimeException){
//按需处理
}catch (Throwable e){
//按需处理
}
那么当我们使用自定义线程池,创建多少线程合适呢?
这时可以根据我们要执行的是CPU密集型任务还是耗时IO型任务。
CPU密集型任务:
如加密、计算hash等
最佳线程数设置为CPU数量的1-2倍即可
耗时IO型任务:
如读写数据库、文件、网络读写等
此时最佳线程数一般会大于cpu核心数很多倍,以JVM线程监控显示繁忙情况为依据,保证线程空闲可以接上,参考Brain Goetz推荐的计算方法:
线程数=CPU核心数*(1+平均等待时间/平均工作时间)
你以为对线程池的学习这就结束了咩?不,还有好多嘞~
比如:
JDK的线程池为什么设计成核心线程数满了就先入队再到扩充到最大线程数?
我就是想先直接到最大线程数再入队怎么做?(事实上tomcat跟dubbo都是这么设计的)
如何优雅的关闭线程池?