机器学习笔记5-2:Transformer
*注:本博客参考李宏毅老师2020年机器学习课程. 视频链接
目录
- 1 Seq2seq
- 2 Encoder
- 3 Decoder
-
- 3.1 AT
-
- 汉字的产生
- 如何输出不定长向量
- 避免一步错,步步错
- 3.2 NAT
- 3.3 Training
- 3.4 Tips
-
- 3.4.1 Copy Mechanism(复制机制)
- 3.4.2 Guided Attention
- 3.4.3 Beam Search
- 3.4.4 Learning rate scheduling
- 3.4.5 Back-translation(BT)
本节可参考原文:Attention Is All You Need.
1 Seq2seq
在上一节中提到,模型的输入和输出有多种不同的类型,我们使用Self-Attention来处理输入和输出都是定长序列的情况。对于输入和输出都是不定长序列的问题,称为Seq2seq,这一届我们将会讲到如何处理这样的问题。以下是一些典型的Seq2seq问题:
- 语音识别、机器翻译、语音翻译、语音生成、人机对话、文法剖析;
- 多标签分类:一个物体对应多个类别的分类问题;
- 目标检测:一张图片中包含多个待检测目标的位置,参考End-to-End Object Detection with Transformers;
Seq2seq问题的解决方案一般都有Encoder和Decoder两个部分,Encoder接收输入数据,处理后传递给Decoder,Decoder再次对数据进行处理产生输出数据。
2 Encoder
Encoder要做的事情,就是输入一排向量,输出一排同样长的向量。因此可以使用Self-Attention来完成,此外,CNN、RNN也都能够胜任这件事情。在Transformer中使用到的就是Self-Attention。但是除此之外,Transformer还是用了一些其他的结构。
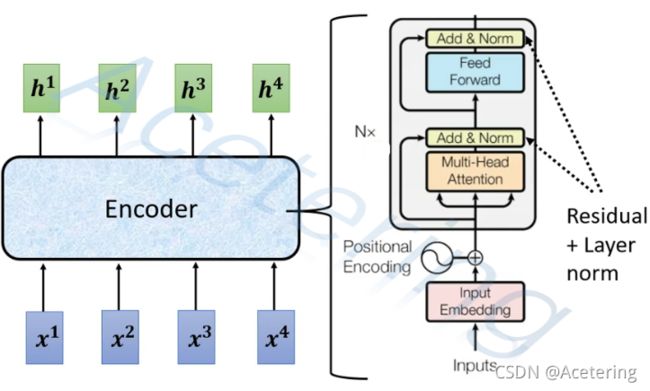
(图1,来自李宏毅2021春机器学习课程)
在图1中描述了Transformer的Encoder中的block的结构,从下往上依次进行:
- embeding:将一些嵌入层嵌入到原始的输入,以添加一些辅助信息;
- Positional Encoding:将这一组输入中每一个输入在序列中的位置信息添加到输入中,具体做法就是将一个位置相关的矩阵与输入做加法;
- Multi-Head Attention:也就是Self-Attention的进阶;
- Add:指的是残差连接,即将Self-Attention结构的输出与输入做加法,这样做可以减少梯度消失的情况;
- Norm:指的是Layer Normalization,见图2,具体的做法参考:Layer Normalization;
- Feed Forward:即全连接网络,但注意上一层的每个输出都要接入一个不同的FC网络;
- Add&Norm:与4和5一致;
整个块可能会重复n次。

(图2,来自李宏毅2021春机器学习课程)
上述网络结构是Attention Is All You Need原文中的结构,实际上我们设计网络结构不一定完全遵循上述结构,修改结构,调整参数,调换各个层之间的顺序,也许能得到更好的结果。深度学习的模型就是如此玄学。下面的一些文章中对Transformer的结构做了一些调整,得到了更好的结果:
- On Layer Normalization in the Transformer Architecture;
- PowerNorm: Rethinking Batch Normalization in Transformers
3 Decoder
常见的Decoder结构包括Autoregressive(AT)和Non Autoregressive(NAT)两种。
3.1 AT
AT结构的Decoder产生输出的过程如图3,我们假设有一个语音识别模型需要识别一段包含“机器学习”的语音片段。
- 第一步,为Decoder输入一个开始符号BEGIN,Decoder根据输入和Encoder的输出,产生一个输出,假设是汉字“机”;
- 第二步,将Decoder的输出“机”和Encoder的输出再次作为Decoder的输入,Decoder产生第二个输出,假设是汉字“器”;
- 重复上述步骤,将输出作为输入,如果模型性能较好,Decoder将完整输出“机器学习”四个汉字。
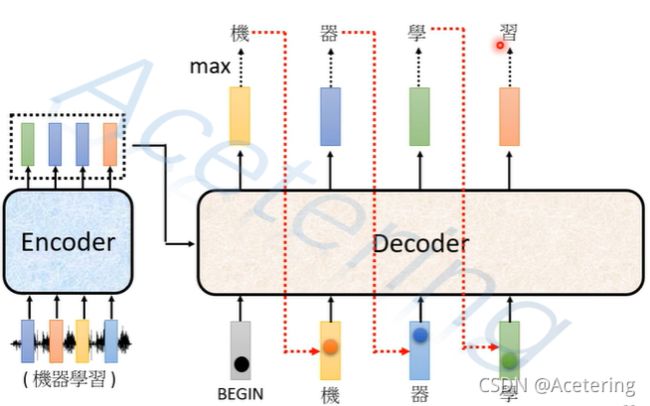
(图3,来自李宏毅2021春机器学习课程)
上述步骤中有3个问题:
- 如何让模型输出汉字?
- 如何让模型停止输出?
- 如果Decoder输出过程中产生了一个错误的输出,那么后续输出是否会“一步错,步步错”呢?
汉字的产生
我们先来看第一个问题。对于文字的输入和输出,一种常见的作法是,设置一个one-hot编码,将每一个字作为一个分量,例如我们希望模型能够识别常用的4000个汉字,那么我们需要设置一个长为4000的向量,假设“机”是第i个字,那么将该向量的第i个分量设置为1,其余为0.
如何输出不定长向量
对于Seq2seq的问题,由于输出长度的不确定性,让模型有能力输出不同长度的结果是很有必要的。我们可以在one-hot编码中规定一个特殊的分量,表示终止计算,当Decoder输出了这一特殊变量,就停止输出。
避免一步错,步步错
由于AT产生输出是依赖于上一个输出的,为了避免上一个错误的输出对于后来输出的影响,在训练模型时,可以手动添加一些错误的数据(noise),增强模型的健壮性。
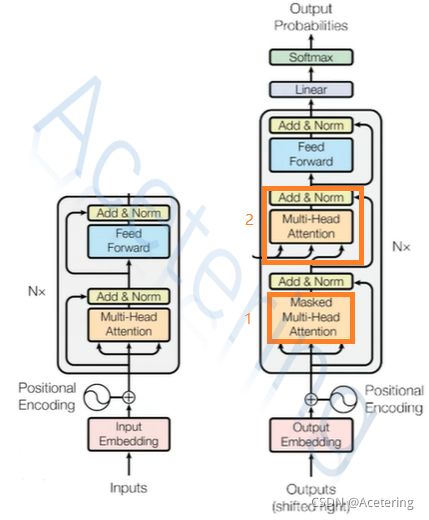
(图4,来自李宏毅2021春机器学习课程)
Decoder的网络结构与Encoder相似,如图4,图中与Encoder不同的地方在于:
- Masked Multi-Head Attention:与普通的self-attention不同,该结构在产生输出时,仅考虑左侧的输入,忽略右侧的输入,如图5;这样做的原因在于,Decoder产生输出是串行的,先产生左侧的输出,再产生右侧的输出。
- Cross Attention:该模块的输入来自于两部分:Decoder和Encoder,同样使用类似于Self-Attention的计算方法,但是 q q q来自于Decoder前半段的输出, k k k和 v v v来自Encoder的输出,如图6.关于Cross Attention,还有以下内容可以参考:
- 比较Cross Attention不同的连接方式:Layer-Wise Cross-View Decoding for Sequence-to-Sequence Learning
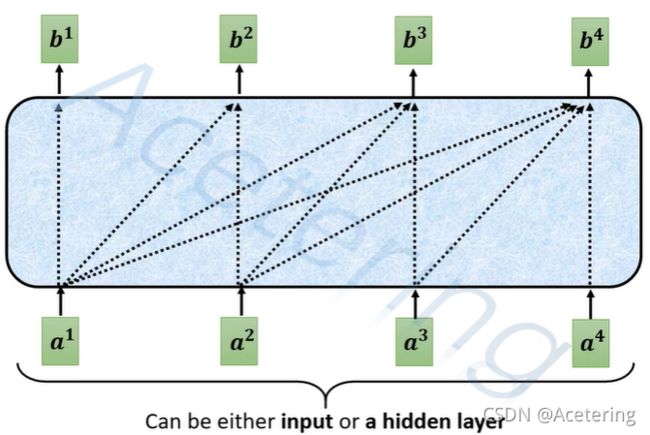
(图5,来自李宏毅2021春机器学习课程)
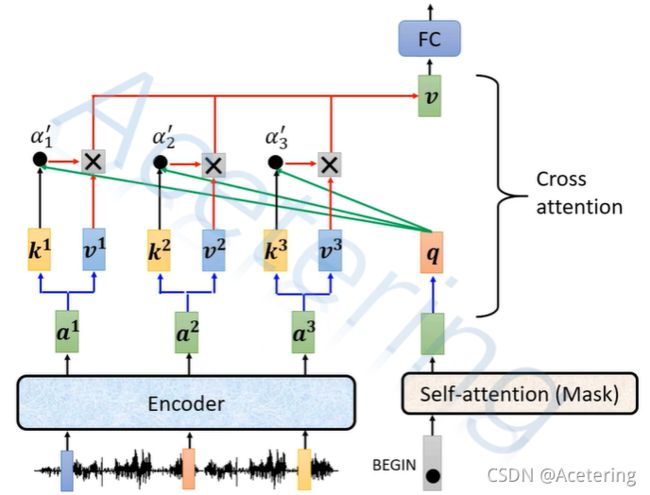
(图6,来自李宏毅2021春机器学习课程)
3.2 NAT
NAT最大的特点在于它能够并行产生输出,只需要一次输入就能够同时产生所有的输出,如图6.
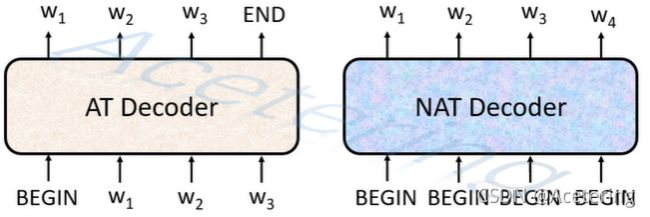
(图7,来自李宏毅2021春机器学习课程)
对于NAT Decoder,输入 n n n个BEGIN,就会产生 n n n个输出,由于使用了位置编码,所以不必担心同样的输入会产生同样的输出的情况。
使用NAT的问题在于,如何确定需要输入多少个BEGIN才能产生合适的数量的输出呢?
- 一种做法是,在Decoder之前再添加一个分类器,该分类器接收Encoder的输出,产生需要输入到Decoder的BEGIN的数量。
- 还有一种做法,输入数量足够多的BEGIN,并且让Decoder自己在合适的位置产生END,在后续步骤舍弃END右边的输出。
3.3 AT与NAT的比较
Decoder | 输出方式 |计算速度 |准确率|输出长度
--------|---------|--------|------|------
AT|串行|慢|高|不可控
NAT|并行|快|低|可控
注:所谓的输出长度可控,意指NAT能够通过手动改变分类器输出值来控制输出的长度,在TTS中表现为说话速度加快或减慢。
3.3 Training
训练时,将BEGIN和正确的输出(ground truth)依次输入Decoder,再将Decoder的输出与ground truth计算交叉熵,通过梯度下降算法最小化该损失函数。注意:由于Decoder需要输出END来结束计算,因此计算交叉熵时,应该在ground truth中添加一个END。
将ground truth作为输入来训练模型的方法称为Teacher Forcing。
训练时,使用交叉熵作为损失函数。测试时,使用BLEU score作为挑选模型的依据。BLEU score比较模型输出与ground truth,得出一个相似度的分数,这种计算无法微分,因此难以用作损失函数。
但是可以使用强化学习(Reinforcement Learning)的方法,将BLEU score作为award来优化模型,参考:Sequence Level Training with Recurrent Neural Networks.
3.4 Tips
3.4.1 Copy Mechanism(复制机制)
在某些任务中,模型需要复制输入中的一些内容,而不是创造它。例如在人机对话任务中,对于用户的姓名、讨论的事件、专有名词等;此外,在摘要任务中,复制是一件经常发生的事情,参考:Get To The Point: Summarization with Pointer-Generator Networks.
Incorporating Copying Mechanism in Sequence-to-Sequence Learning:这篇文章中描述了如何为实现这样的复制机制。
3.4.2 Guided Attention
有时模型训练完成之后会出现一些异常情况,例如对于语音生成任务,模型并没有从左到右使用到所有的数据,这时需要引导模型按照我们想要的方向去运作,就需要使用到Guided Attention技术。
3.4.3 Beam Search
由于在AT的Decoder中,输出是按序依次产生的,每次输出模型都需要在若干个可能的输出中选择一个。这种贪心算法可能无法取得全局的最优值(即全局的soft max 概率最高),Beam Search就是用来解决这种情况的。
然而,并非对于所有的任务来说,全局最优都是最好的结果,有时贪心算法能够取得更好的结果。
3.4.4 Learning rate scheduling
先线性增加学习速率,再以平方根减少学习速率,这样能够再早期的训练轮次中稳定训练效果。
3.4.5 Back-translation(BT)
训练文本翻译模型时,可以同时训练一个逆翻译模型,将目标文本重新转化为外文,再次将这个数据作为翻译模型的输入。