点云学习笔记一(PointNet与PointNet++)
00. 写在前面
该篇文章主要介绍PointNet与PointNet++的原理与代码实现过程。
01. PointNet与PointNet++原理
1.1 PointNet
PointNet可以直接对点云数据进行处理,首先由Charles R.Q提出。该方法主要针对点云数据的三个固有属性:
无序性:即输入点的顺序变换不会影响模型的预测结果;
点的相互作用:点云中的每个点并不是孤立存在的,相邻的点集形成了有意义的子集。
变换不变性:在平移和旋转的变换下,模型的预测结果不变。
根据这三个性质,我们来看一下提出的PointNet结构:

这里使用了max pool满足了无序性的要求,因为max(a,b,c)=max(b,a,c)=...。但n*m的点云矩阵经过max pool就成了1*m的向量,显然这会损失很多点云信息。因此我们可以看到使用了两个mlp对n*m的点云矩阵升维,最终获得的向量就保存了相对较多的点云信息,名为global feature,然后就可以完成分类任务。同时考虑到点的相互作用,这里直接将global feature的向量接在每个点的向量之后,那么对每个点进行分类预测,就可以完成语义分割的任务。最后我们可以看到在输入点云时,使用了T-Net对每点云数据进行了仿射变换。T-Net是一个预测特征空间变换矩阵的子网络,它从输入数据中学习出与特征空间维度一致的变换矩阵,然后用这个变换矩阵与原始数据向乘,实现对输入特征空间的变换操作,使得后续的每一个点都与输入数据中的每一个点都有关系。通过这样的数据融合,实现对原始点云数据包含特征的逐级抽象(引用)。
1.2 PointNet++
PointNet++针对PointNet的局限做出了较大的改进。经过上文分析,我们可以发现PointNet存在的主要问题就是局部信息获取能力不足,因为只有global feature与单个点的简单拼接,所以预测的结果并不能较好地获取点云的局部特征。PointNet++给出的方法是set abstraction,即samping、grouping和PointNet。首先sampling选取几个点,名为centroid,随后以这些点为中心进行grouping,得到点簇,最后将用PointNet对这些点簇进行降成一维,得到它们的global feature,那么原来的N个点变成了N1个点簇。具体如下所示:
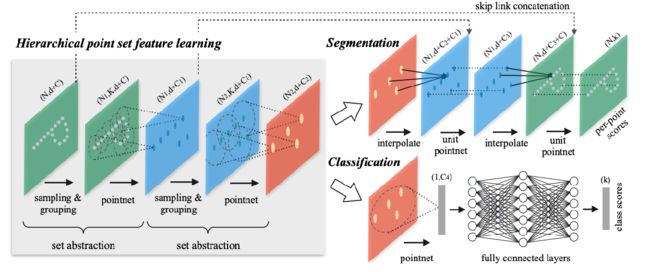
由上图可知,初始的N*d+C点云矩阵经过sampling和grouping后变为N1*K*d+C的矩阵。这里之所以多了一个维度是因为点簇形成时是可以有交错的,K是每个点簇中点的个数(当然点簇之间点的个数是大多是不同的),每个点簇也是一个矩阵。那么经过PointNet降维,每个点簇变成了1*d+C1的向量,最后输出维度为N1*d+C1。随后的分类与PointNet的操作类似,不再赘述,需要说的是分割操作。因为前文我们说分割就是对每个点的分类,但PointNet++使原来输入的N个点变为了N2个点,所以需要进行上采样,即升维,当然如果N2=N,也不要进行上采样了,但是这样的话意味着要算N*K个点,计算成本会很大,所以论文采用的方法是特征插值计算:

具体的过程较为复杂,可以参考(10条消息) 小白科研笔记:理解PointNet++中的three_interpolate前向计算和反向求导_Niuip的博客-CSDN博客。
最后还有一个用在grouping中的technique是MSG。因为点云自身的属性近密远疏,在形成点簇时经常会出现有些点簇的点很多而有些点簇没有几个点的情况,这显然不是我们想看到的。那么MSG是如何解决这个问题的呢。采用的方式就是对于采样获得的中心点,围绕着同一个中心点,如果使用三个不同的尺度的话,便是围绕着同一个中心点,然后以不同的球形半径进行局部区域的划分,划分之后的区域再经过PointNet层进行特征提取,之后进行级联,并将此级联特征加到中心点的特征维度上,作为该中心点的特征(引用)。
02.PointNet++分类代码解析
由上述内容可知PointNet++是PointNet的拓展,那么我们就只看一下PointNet++的代码,代码来自于https://github.com/erikwijmans/Pointnet2_PyTorch。需要预先说明的是,这个项目的代码是基于pytorch lightning库写的,建议先仔细了解下这个库,具体可以看https://mp.weixin.qq.com/s?__biz=MzI4MDYzNzg4Mw==&mid=2247548633&idx=1&sn=f1d0c91deab6b7c437ad421b7f13be84&chksm=ebb7060ddcc08f1bab86dd7f78807dc5208d7f7a9514346b69947c11bdc518e250f99af5c525&scene=27。该项目中主要有实现两个功能:分类和语义分割。我们先来看看分类的代码:
class PointNet2ClassificationSSG(pl.LightningModule):
def __init__(self, hparams):
super().__init__()
self.hparams = hparams
self._build_model()
def _build_model(self):
self.SA_modules = nn.ModuleList()
self.SA_modules.append(
PointnetSAModule(
npoint=512,
radius=0.2,
nsample=64,
mlp=[3, 64, 64, 128],
use_xyz=self.hparams["model.use_xyz"],
)
)
self.SA_modules.append(
PointnetSAModule(
npoint=128,
radius=0.4,
nsample=64,
mlp=[128, 128, 128, 256],
use_xyz=self.hparams["model.use_xyz"],
)
)
self.SA_modules.append(
PointnetSAModule(
mlp=[256, 256, 512, 1024], use_xyz=self.hparams["model.use_xyz"]
)
)
self.fc_layer = nn.Sequential(
nn.Linear(1024, 512, bias=False),
nn.BatchNorm1d(512),
nn.ReLU(True),
nn.Linear(512, 256, bias=False),
nn.BatchNorm1d(256),
nn.ReLU(True),
nn.Dropout(0.5),
nn.Linear(256, 40),
)
def _break_up_pc(self, pc):
xyz = pc[..., 0:3].contiguous()
features = pc[..., 3:].transpose(1, 2).contiguous() if pc.size(-1) > 3 else None
return xyz, features
def forward(self, pointcloud):
r"""
Forward pass of the network
Parameters
----------
pointcloud: Variable(torch.cuda.FloatTensor)
(B, N, 3 + input_channels) tensor
Point cloud to run predicts on
Each point in the point-cloud MUST
be formated as (x, y, z, features...)
"""
xyz, features = self._break_up_pc(pointcloud)
for module in self.SA_modules:
xyz, features = module(xyz, features)
return self.fc_layer(features.squeeze(-1))
def training_step(self, batch, batch_idx):
pc, labels = batch
logits = self.forward(pc)
loss = F.cross_entropy(logits, labels)
with torch.no_grad():
acc = (torch.argmax(logits, dim=1) == labels).float().mean()
log = dict(train_loss=loss, train_acc=acc)
return dict(loss=loss, log=log, progress_bar=dict(train_acc=acc))
def validation_step(self, batch, batch_idx):
pc, labels = batch
logits = self.forward(pc)
loss = F.cross_entropy(logits, labels)
acc = (torch.argmax(logits, dim=1) == labels).float().mean()
return dict(val_loss=loss, val_acc=acc)
def validation_end(self, outputs):
reduced_outputs = {}
for k in outputs[0]:
for o in outputs:
reduced_outputs[k] = reduced_outputs.get(k, []) + [o[k]]
for k in reduced_outputs:
reduced_outputs[k] = torch.stack(reduced_outputs[k]).mean()
reduced_outputs.update(
dict(log=reduced_outputs.copy(), progress_bar=reduced_outputs.copy())
)
return reduced_outputs
def configure_optimizers(self):
lr_lbmd = lambda _: max(
self.hparams["optimizer.lr_decay"]
** (
int(
self.global_step
* self.hparams["batch_size"]
/ self.hparams["optimizer.decay_step"]
)
),
lr_clip / self.hparams["optimizer.lr"],
)
bn_lbmd = lambda _: max(
self.hparams["optimizer.bn_momentum"]
* self.hparams["optimizer.bnm_decay"]
** (
int(
self.global_step
* self.hparams["batch_size"]
/ self.hparams["optimizer.decay_step"]
)
),
bnm_clip,
)
optimizer = torch.optim.Adam(
self.parameters(),
lr=self.hparams["optimizer.lr"],
weight_decay=self.hparams["optimizer.weight_decay"],
)
lr_scheduler = lr_sched.LambdaLR(optimizer, lr_lambda=lr_lbmd)
bnm_scheduler = BNMomentumScheduler(self, bn_lambda=bn_lbmd)
return [optimizer], [lr_scheduler, bnm_scheduler]
def prepare_data(self):
train_transforms = transforms.Compose(
[
d_utils.PointcloudToTensor(),
d_utils.PointcloudScale(),
d_utils.PointcloudRotate(),
d_utils.PointcloudRotatePerturbation(),
d_utils.PointcloudTranslate(),
d_utils.PointcloudJitter(),
d_utils.PointcloudRandomInputDropout(),
]
)
self.train_dset = ModelNet40Cls(
self.hparams["num_points"], transforms=train_transforms, train=True
)
self.val_dset = ModelNet40Cls(
self.hparams["num_points"], transforms=None, train=False
)
def _build_dataloader(self, dset, mode):
return DataLoader(
dset,
batch_size=self.hparams["batch_size"],
shuffle=mode == "train",
num_workers=4,
pin_memory=True,
drop_last=mode == "train",
)
def train_dataloader(self):
return self._build_dataloader(self.train_dset, mode="train")
def val_dataloader(self):
return self._build_dataloader(self.val_dset, mode="val")首先定义模型,因此咱们先来看_build_model函数,该函数同时创建了三个模块以及一个全连接层。需要对该模块进行一个详细的解析,因为涉及到PointNet++中很重要的步骤:sampling and grouping。
class _PointnetSAModuleBase(nn.Module):
def __init__(self):
super(_PointnetSAModuleBase, self).__init__()
self.npoint = None
self.groupers = None
self.mlps = None
def forward(
self, xyz: torch.Tensor, features: Optional[torch.Tensor]
) -> Tuple[torch.Tensor, torch.Tensor]:
r"""
Parameters
----------
xyz : torch.Tensor
(B, N, 3) tensor of the xyz coordinates of the features
features : torch.Tensor
(B, C, N) tensor of the descriptors of the the features
Returns
-------
new_xyz : torch.Tensor
(B, npoint, 3) tensor of the new features' xyz
new_features : torch.Tensor
(B, \sum_k(mlps[k][-1]), npoint) tensor of the new_features descriptors
"""
new_features_list = []
xyz_flipped = xyz.transpose(1, 2).contiguous()
new_xyz = (
pointnet2_utils.gather_operation(
xyz_flipped, pointnet2_utils.furthest_point_sample(xyz, self.npoint)
)
.transpose(1, 2)
.contiguous()
if self.npoint is not None
else None
)
for i in range(len(self.groupers)):
new_features = self.groupers[i](
xyz, new_xyz, features
) # (B, C, npoint, nsample)
new_features = self.mlps[i](new_features) # (B, mlp[-1], npoint, nsample)
new_features = F.max_pool2d(
new_features, kernel_size=[1, new_features.size(3)]
) # (B, mlp[-1], npoint, 1)
new_features = new_features.squeeze(-1) # (B, mlp[-1], npoint)
new_features_list.append(new_features)
return new_xyz, torch.cat(new_features_list, dim=1)
class PointnetSAModuleMSG(_PointnetSAModuleBase):
r"""Pointnet set abstrction layer with multiscale grouping
Parameters
----------
npoint : int
Number of features
radii : list of float32
list of radii to group with
nsamples : list of int32
Number of samples in each ball query
mlps : list of list of int32
Spec of the pointnet before the global max_pool for each scale
bn : bool
Use batchnorm
"""
def __init__(self, npoint, radii, nsamples, mlps, bn=True, use_xyz=True):
# type: (PointnetSAModuleMSG, int, List[float], List[int], List[List[int]], bool, bool) -> None
super(PointnetSAModuleMSG, self).__init__()
assert len(radii) == len(nsamples) == len(mlps)
self.npoint = npoint
self.groupers = nn.ModuleList()
self.mlps = nn.ModuleList()
for i in range(len(radii)):
radius = radii[i]
nsample = nsamples[i]
self.groupers.append(
pointnet2_utils.QueryAndGroup(radius, nsample, use_xyz=use_xyz)
if npoint is not None
else pointnet2_utils.GroupAll(use_xyz)
)
mlp_spec = mlps[i]
if use_xyz:
mlp_spec[0] += 3
self.mlps.append(build_shared_mlp(mlp_spec, bn))
class PointnetSAModule(PointnetSAModuleMSG):
r"""Pointnet set abstrction layer
Parameters
----------
npoint : int
Number of features
radius : float
Radius of ball
nsample : int
Number of samples in the ball query
mlp : list
Spec of the pointnet before the global max_pool
bn : bool
Use batchnorm
"""
def __init__(
self, mlp, npoint=None, radius=None, nsample=None, bn=True, use_xyz=True
):
# type: (PointnetSAModule, List[int], int, float, int, bool, bool) -> None
super(PointnetSAModule, self).__init__(
mlps=[mlp],
npoint=npoint,
radii=[radius],
nsamples=[nsample],
bn=bn,
use_xyz=use_xyz,
)根据PointNet++的原理,首先进行sampling,随即根据设定的点簇个数完成grouping。注释里有
xyz : (B, N, 3) tensor of the xyz coordinates of the features, new_xyz :(B, npoint, 3) tensor of the new features' xyz。
这里的N和npoint分别为点云中点的个数与点簇的个数。显然这里new_xyz是sampling后的centroid,那么下面需要根据这些centroid进行完成grouping。即将各个点簇放入PointNet,使其最终输出为一维的向量,这部分定义在了class _PointnetSAModuleBase的forward函数里。之后定义了两种不同的grouping方法,即MSG与SSG,令其继承于class _PointnetSAModuleBase。
根据上文对模块的解释,我们可以看到该段代码一共进行了三次sampling和grouping,最后定义了全连接层,得到输出的类别情况。随后该部分的计算在forward函数中体现,同时需要注意到forward里用_break_up_pc函数,这个函数对输入的点云数据进行了处理,因为点云数据的一般从左到右分别表示点云的坐标、颜色和法向量,这里将坐标与其他的feature进行了切割处理。模型建立完成后,需要读取数据,该部分主要的函数是prepare_data, _build_dataloader, train_loader和val_loader,至此数据集建立完毕。这里需要提的一点是prepare_data函数,我们可以看到在这个函数里对输入数据进行了transform,对应上文提到的PointNet的旋转平移不变性,使用T-Net对数据进行了转换。下面正式开始训练,函数为training_step,validation_step,validation_end,同时训练时需要通过configure_optimizers对优化器和学习率等进行设置。
至此,基本上已经完成了使PointNet++用SSG做grouping的分类任务,同理我们可以推出MSG的过程,因为仅有grouping的方式不同,所以我们可以看到:
class PointNet2ClassificationMSG(PointNet2ClassificationSSG):
def _build_model(self):
super()._build_model()
self.SA_modules = nn.ModuleList()
self.SA_modules.append(
PointnetSAModuleMSG(
npoint=512,
radii=[0.1, 0.2, 0.4],
nsamples=[16, 32, 128],
mlps=[[3, 32, 32, 64], [3, 64, 64, 128], [3, 64, 96, 128]],
use_xyz=self.hparams["model.use_xyz"],
)
)
input_channels = 64 + 128 + 128
self.SA_modules.append(
PointnetSAModuleMSG(
npoint=128,
radii=[0.2, 0.4, 0.8],
nsamples=[32, 64, 128],
mlps=[
[input_channels, 64, 64, 128],
[input_channels, 128, 128, 256],
[input_channels, 128, 128, 256],
],
use_xyz=self.hparams["model.use_xyz"],
)
)
self.SA_modules.append(
PointnetSAModule(
mlp=[128 + 256 + 256, 256, 512, 1024],
use_xyz=self.hparams["model.use_xyz"],
)
)另外由以上可知,在pytorch lightning的加持下,代码变得更加的清晰。
03.PointNet++语义分割代码解析
语义分割较分类的不同的地方在于语义分割就是对点云的每个点做分类处理。PointNet++与PointNet在做语义分割时有较大不同,因为PointNet++将点云做了下采样处理,如果要对每个点进行分类的话,需要对点进行上采样处理,具体代码如下:
class PointNet2SemSegSSG(PointNet2ClassificationSSG):
def _build_model(self):
self.SA_modules = nn.ModuleList()
self.SA_modules.append(
PointnetSAModule(
npoint=1024,
radius=0.1,
nsample=32,
mlp=[6, 32, 32, 64],
use_xyz=self.hparams["model.use_xyz"],
)
)
self.SA_modules.append(
PointnetSAModule(
npoint=256,
radius=0.2,
nsample=32,
mlp=[64, 64, 64, 128],
use_xyz=self.hparams["model.use_xyz"],
)
)
self.SA_modules.append(
PointnetSAModule(
npoint=64,
radius=0.4,
nsample=32,
mlp=[128, 128, 128, 256],
use_xyz=self.hparams["model.use_xyz"],
)
)
self.SA_modules.append(
PointnetSAModule(
npoint=16,
radius=0.8,
nsample=32,
mlp=[256, 256, 256, 512],
use_xyz=self.hparams["model.use_xyz"],
)
)
self.FP_modules = nn.ModuleList()
self.FP_modules.append(PointnetFPModule(mlp=[128 + 6, 128, 128, 128]))
self.FP_modules.append(PointnetFPModule(mlp=[256 + 64, 256, 128]))
self.FP_modules.append(PointnetFPModule(mlp=[256 + 128, 256, 256]))
self.FP_modules.append(PointnetFPModule(mlp=[512 + 256, 256, 256]))
self.fc_lyaer = nn.Sequential(
nn.Conv1d(128, 128, kernel_size=1, bias=False),
nn.BatchNorm1d(128),
nn.ReLU(True),
nn.Dropout(0.5),
nn.Conv1d(128, 13, kernel_size=1),
)
def forward(self, pointcloud):
r"""
Forward pass of the network
Parameters
----------
pointcloud: Variable(torch.cuda.FloatTensor)
(B, N, 3 + input_channels) tensor
Point cloud to run predicts on
Each point in the point-cloud MUST
be formated as (x, y, z, features...)
"""
xyz, features = self._break_up_pc(pointcloud)
l_xyz, l_features = [xyz], [features]
for i in range(len(self.SA_modules)):
li_xyz, li_features = self.SA_modules[i](l_xyz[i], l_features[i])
l_xyz.append(li_xyz)
l_features.append(li_features)
for i in range(-1, -(len(self.FP_modules) + 1), -1):
l_features[i - 1] = self.FP_modules[i](
l_xyz[i - 1], l_xyz[i], l_features[i - 1], l_features[i]
)
return self.fc_lyaer(l_features[0])
def prepare_data(self):
self.train_dset = Indoor3DSemSeg(self.hparams["num_points"], train=True)
self.val_dset = Indoor3DSemSeg(self.hparams["num_points"], train=False)可以看到,这段代码直接继承于分类的代码,针对不同的地方我们再仔细查看。同样我们先看_build_model函数,这里建立了四个模块,与前文相似这里就不赘述,这里主要需要看的就是self.FP_modules,需要分析一下:
class PointnetFPModule(nn.Module):
r"""Propigates the features of one set to another
Parameters
----------
mlp : list
Pointnet module parameters
bn : bool
Use batchnorm
"""
def __init__(self, mlp, bn=True):
# type: (PointnetFPModule, List[int], bool) -> None
super(PointnetFPModule, self).__init__()
self.mlp = build_shared_mlp(mlp, bn=bn)
def forward(self, unknown, known, unknow_feats, known_feats):
# type: (PointnetFPModule, torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor) -> torch.Tensor
r"""
Parameters
----------
unknown : torch.Tensor
(B, n, 3) tensor of the xyz positions of the unknown features
known : torch.Tensor
(B, m, 3) tensor of the xyz positions of the known features
unknow_feats : torch.Tensor
(B, C1, n) tensor of the features to be propigated to
known_feats : torch.Tensor
(B, C2, m) tensor of features to be propigated
Returns
-------
new_features : torch.Tensor
(B, mlp[-1], n) tensor of the features of the unknown features
"""
if known is not None:
dist, idx = pointnet2_utils.three_nn(unknown, known)
dist_recip = 1.0 / (dist + 1e-8)
norm = torch.sum(dist_recip, dim=2, keepdim=True)
weight = dist_recip / norm
interpolated_feats = pointnet2_utils.three_interpolate(
known_feats, idx, weight
)
else:
interpolated_feats = known_feats.expand(
*(known_feats.size()[0:2] + [unknown.size(1)])
)
if unknow_feats is not None:
new_features = torch.cat(
[interpolated_feats, unknow_feats], dim=1
) # (B, C2 + C1, n)
else:
new_features = interpolated_feats
new_features = new_features.unsqueeze(-1)
new_features = self.mlp(new_features)
return new_features.squeeze(-1)这部分代码主要负责上采样,使用插值得到与原始输入相同个数的点。
同样可以看到下面用MSG采样的语义分割代码,仅是采样方法不同,其他部分类似。
class PointNet2SemSegMSG(PointNet2SemSegSSG):
def _build_model(self):
self.SA_modules = nn.ModuleList()
c_in = 6
self.SA_modules.append(
PointnetSAModuleMSG(
npoint=1024,
radii=[0.05, 0.1],
nsamples=[16, 32],
mlps=[[c_in, 16, 16, 32], [c_in, 32, 32, 64]],
use_xyz=self.hparams["model.use_xyz"],
)
)
c_out_0 = 32 + 64
c_in = c_out_0
self.SA_modules.append(
PointnetSAModuleMSG(
npoint=256,
radii=[0.1, 0.2],
nsamples=[16, 32],
mlps=[[c_in, 64, 64, 128], [c_in, 64, 96, 128]],
use_xyz=self.hparams["model.use_xyz"],
)
)
c_out_1 = 128 + 128
c_in = c_out_1
self.SA_modules.append(
PointnetSAModuleMSG(
npoint=64,
radii=[0.2, 0.4],
nsamples=[16, 32],
mlps=[[c_in, 128, 196, 256], [c_in, 128, 196, 256]],
use_xyz=self.hparams["model.use_xyz"],
)
)
c_out_2 = 256 + 256
c_in = c_out_2
self.SA_modules.append(
PointnetSAModuleMSG(
npoint=16,
radii=[0.4, 0.8],
nsamples=[16, 32],
mlps=[[c_in, 256, 256, 512], [c_in, 256, 384, 512]],
use_xyz=self.hparams["model.use_xyz"],
)
)
c_out_3 = 512 + 512
self.FP_modules = nn.ModuleList()
self.FP_modules.append(PointnetFPModule(mlp=[256 + 6, 128, 128]))
self.FP_modules.append(PointnetFPModule(mlp=[512 + c_out_0, 256, 256]))
self.FP_modules.append(PointnetFPModule(mlp=[512 + c_out_1, 512, 512]))
self.FP_modules.append(PointnetFPModule(mlp=[c_out_3 + c_out_2, 512, 512]))
self.fc_lyaer = nn.Sequential(
nn.Conv1d(128, 128, kernel_size=1, bias=False),
nn.BatchNorm1d(128),
nn.ReLU(True),
nn.Dropout(0.5),
nn.Conv1d(128, 13, kernel_size=1),
)04.结语
经过上面对PointNet与PointNet++原理和代码的分析,我们可以知道这两种算法的原理其实并不复杂,下面我打算介绍一下PointNet++的实例应用,那里主要的部分当然就是代码分析了。
最后我也只是刚刚接触点云,对很多地方还不了解,所以如果有说错的地方,还请各位能够批评指正,谢谢。