TimesFormer Ubuntun环境搭建及训练自己数据集
一 TimesFormer配置
1 代码下载
git clone https://github.com/facebookresearch/TimeSformer
cd TimeSformer # 进入文件夹
2 环境配置
(1)创建虚拟环境
conda create -n Timesformer python=3.8 -y
conda activate Timesformer
(2) torch及cuda配置
命令行nvidia-smi 查看自己显卡版本,我自己的为11.7,如下所示
![]()
其中需要下载torch、torchvision、torchaudio。
对应版本及下载链接如下:
下载镜像源
版本比对
本地下载到对应的文件夹下,我下的版本如下所示,后上传至Ubuntun系统上,速度快一点。

下载后传到Linux系统上,使用如下指令进行安装
pip install torch-1.13.0+cu117-cp38-cp38-linux_x86_64.whl
pip install torchvision-0.14.0+cu117-cp38-cp38-linux_x86_64.whl
pip install torchaudio-0.13.0+cu117-cp38-cp38-linux_x86_64.whl
(3)模型环境配置
# 按照官方步骤安装剩下的包
pip install 'git+https://github.com/facebookresearch/fvcore'
pip install simplejson
pip install einops
pip install timm
conda install av -c conda-forge
pip install psutil
pip install scikit-learn
pip install opencv-python
pip install tensorboard
pip install matplotlib
pip install sklearn
3 数据集配置
本人采用的是UCF101数据集,数据集自行百度下载。
处理数据集代码如下:
import os
import csv
import shutil
from tqdm import tqdm
from sklearn.model_selection import train_test_split
out_dir = "/home/dxczq/vision/result" # 全路径
video_path = "/home/dxczq/vision/UCF-101" # 全路径
file_name = ".csv"
video_name = ".avi"
name_list = ["train","test","val"]
if not os.path.exists(out_dir):
os.mkdir(out_dir)
os.mkdir(os.path.join(out_dir, 'train'))
os.mkdir(os.path.join(out_dir, 'val'))
os.mkdir(os.path.join(out_dir, 'test'))
for file in os.listdir(video_path):
file_path = os.path.join(video_path, file)
video_files = [name for name in os.listdir(file_path)]
train_and_valid, test = train_test_split(video_files, test_size=0.2, random_state=42)
train, val = train_test_split(train_and_valid, test_size=0.2, random_state=42)
train_dir = os.path.join(out_dir, 'train', file)
val_dir = os.path.join(out_dir, 'val', file)
test_dir = os.path.join(out_dir, 'test', file)
if not os.path.exists(train_dir):
os.mkdir(train_dir)
if not os.path.exists(val_dir):
os.mkdir(val_dir)
if not os.path.exists(test_dir):
os.mkdir(test_dir)
for video in tqdm(train):
shutil.copy(os.path.join(video_path,file,video),os.path.join(train_dir,video))
for video in tqdm(test):
shutil.copy(os.path.join(video_path,file,video),os.path.join(test_dir,video))
for video in tqdm(val):
shutil.copy(os.path.join(video_path,file,video),os.path.join(val_dir,video))
if not os.path.exists(os.path.join(out_dir,"csv")):
os.mkdir(os.path.join(out_dir,"csv"))
for name in name_list:
with open(os.path.join(out_dir,"csv",name+file_name),'wb') as f:
print("创建"+os.path.join(out_dir,"csv",name+file_name))
csv_path = os.path.join(out_dir,"csv")
for ii in os.listdir(path=csv_path):
if ii.split(".")[0] in name_list:
path1 = os.path.join(csv_path,ii)
with open(path1, 'w', newline='') as f:
for dd in os.listdir(out_dir):
if dd==ii.split(".")[0]:
for zz in os.listdir(os.path.join(out_dir,dd)):
for mm in os.listdir(os.path.join(out_dir,dd,zz)):
writer = csv.writer(f)
writer.writerow([os.path.join(out_dir,dd,zz,mm),zz])
## 创建类别label标号文件
labels= []
for label in sorted(os.listdir(video_path)):
labels.append(label)
label2index = {label: index for index, label in enumerate(sorted(set(labels)))}
label_file = os.path.join(out_dir, str(len(os.listdir(video_path))) + 'class_labels.txt')
with open(label_file, 'w') as f:
for id, label in enumerate(sorted(label2index)):
f.writelines(str(id) + ' ' + label + '\n')
#替换csv文件中类别名为数字
csv_file = os.path.join(out_dir,"csv")
def txt_read(files):
txt_dict = {}
fopen = open(files)
for line in fopen.readlines():
line = str(line).replace("\n","") #注意,必须是双引号,找了大半个小时,发现是这个问题。。
txt_dict[line.split(' ',1)[1]] = line.split(' ',1)[0]
#split()函数用法,逗号前面是以什么来分割,后面是分割成n+1个部分,且以数组形式从0开始
#初学python,感觉这样表达会理解一点。。
fopen.close()
return txt_dict
txt_dict = txt_read(label_file)
# print(txt_dict)
for ii in os.listdir(csv_file):
path1 = os.path.join(csv_file,ii)
r = csv.reader(open(path1))
lines = [l for l in r]
for i in range(len(lines)):
cs = lines[i][1]
value = txt_dict[cs]
lines[i][1] = value
writer = csv.writer(open(path1, 'w'))
writer.writerows(lines)
最终得到的csv文件格式为:
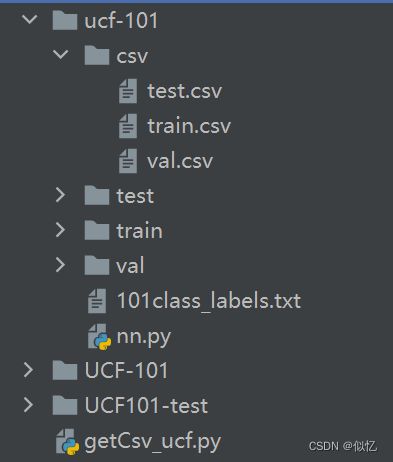
其中得到的csv文件夹为训练所需材料。
4 运行代码
(1)首先在tools里将run_net.py复制到主目录底下。
(2)更./configs/Kinetics/TimeSformer_divST_8x32_224.yaml文件
TRAIN:
ENABLE: True
DATASET: kinetics # 固定
BATCH_SIZE: 8 # 可按需更改
EVAL_PERIOD: 5
CHECKPOINT_PERIOD: 5
AUTO_RESUME: False
DATA:
PATH_TO_DATA_DIR: /data/dongbin/resultTest/csv/ # 存放的csv文件
NUM_FRAMES: 8
SAMPLING_RATE: 32
TRAIN_JITTER_SCALES: [256, 320]
TRAIN_CROP_SIZE: 224
TEST_CROP_SIZE: 224
INPUT_CHANNEL_NUM: [3]
TIMESFORMER:
ATTENTION_TYPE: 'divided_space_time'
SOLVER:
BASE_LR: 0.01
MAX_EPOCH: 60
MOMENTUM: 0.9
WEIGHT_DECAY: 1e-4
OPTIMIZING_METHOD: sgd
MODEL:
MODEL_NAME: vit_base_patch16_224
NUM_CLASSES: 101 # 类别总数
ARCH: vit
LOSS_FUNC: cross_entropy
DROPOUT_RATE: 0.5
TEST:
ENABLE: True
DATASET: kinetics
BATCH_SIZE: 8
NUM_ENSEMBLE_VIEWS: 1
NUM_SPATIAL_CROPS: 3
DATA_LOADER:
NUM_WORKERS: 8
PIN_MEMORY: True
NUM_GPUS: 1 # 根据自己GPU选择
NUM_SHARDS: 1
RNG_SEED: 42
OUTPUT_DIR: .
启动
python run_net.py --cfg /home/dxczq/vision/TimeSformer-main/configs/Kinetics/TimeSformer_divST_8x32_224.yaml
由于python版本为3.8,源码为3.6,cuda版本不一,会出现以下BUG:
(1)
问题1:
TimeSformer-main/timesformer/models/resnet_helper.py", line 15, in <module>
from torch.nn.modules.linear import _LinearWithBias
ImportError: cannot
import name '_LinearWithBias' from 'torch.nn.modules.linear'
找到resnet_helper.py,修改导入包为:
if float(torch.__version__.split('.')[0]) == 0 or (float(torch.__version__.split('.')[0]) == 1 and float(torch.__version__.split('.')[1])) < 9:
from torch.nn.modules.linear import _LinearWithBias
else:
from torch.nn.modules.linear import NonDynamicallyQuantizableLinear as _LinearWithBias
问题2:
TimeSformer-main/timesformer/models/vit_utils.py", line 14, in <module>
from torch._six import container_abcs
ImportError: cannot import name 'container_abcs' from 'torch._six'
解决方法为更改对应导入包为:
import collections.abc as container_abcs
int_classes = int
string_classes = str
问题3:
TimeSformer-main/timesformer/datasets/multigrid_helper.py", line 6, in <module>
from torch._six import int_classes as _int_classes
ImportError: cannot import name 'int_classes' from 'torch._six'
解决方案为:
替换为:
int_classes = int
string_classes = str
之后会运行会显示如下:
Downloading: "https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-vitjx/jx_vit_base_p16_224-80ecf9dd.pth"
to /home/dxczq/.cache/torch/hub/checkpoints/jx_vit_base_p16_224-80ecf9dd.pth
建议本地下载后导入到对应文件夹中。
之后运行会报以下错误,原因为生成csv文件最终格式为
/result/test/Diving/v_Diving_g20_c02.avi,25
源码则要求为:
/result/test/Diving/v_Diving_g20_c02.avi 25
故在TimeSformer-main/timesformer/config/defaults.py中修改
_C.DATA.PATH_LABEL_SEPARATOR = ""--》_C.DATA.PATH_LABEL_SEPARATOR = ","
之后即可运行
python run_net.py --cfg /home/dxczq/vision/TimeSformer-main/configs/Kinetics/TimeSformer_divST_8x32_224.yaml