elasticsearch 集群、节点、索引、分片、副本概念
原文链接:
https://www.jianshu.com/p/297e13045605
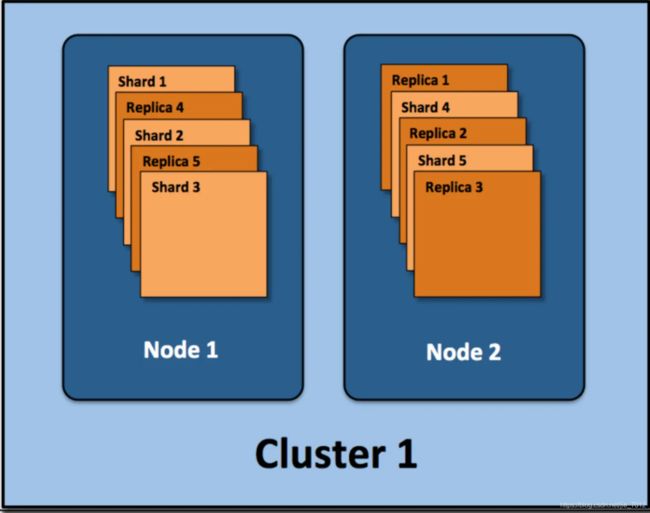
集群(cluster): 由一个或多个节点组成, 并通过集群名称与其他集群进行区分
节点(node): 单个 ElasticSearch 实例. 通常一个节点运行在一个隔离的容器或虚拟机中
索引(index): 在 ES 中, 索引是一组文档的集合
分片(shard): 因为 ES 是个分布式的搜索引擎, 所以索引通常都会分解成不同部分, 而这些分布在不同节点的数据就是分片. ES自动管理和组织分片, 并在必要的时候对分片数据进行再平衡分配, 所以用户基本上不用担心分片的处理细节.
副本(replica): ES 默认为一个索引创建 5 个主分片, 并分别为其创建一个副本分片. 也就是说每个索引都由 5 个主分片成本, 而每个主分片都相应的有一个 copy。对于分布式搜索引擎来说, 分片及副本的分配将是高可用及快速搜索响应的设计核心.主分片与副本都能处理查询请求,它们的唯一区别在于只有主分片才能处理索引请求.副本对搜索性能非常重要,同时用户也可在任何时候添加或删除副本。额外的副本能给带来更大的容量, 更高的呑吐能力及更强的故障恢复能力。
如上图,有集群两个节点,并使用了默认的分片配置. ES自动把这5个主分片分配到2个节点上, 而它们分别对应的副本则在完全不同的节点上。其中 node1 有某个索引的分片1、2、3和副本分片4、5,node2 有该索引的分片4、5和副本分片1、2、3。
当数据被写入分片时,它会定期发布到磁盘上的不可变的 Lucene 分段中用于查询。随着分段数量的增长,这些分段会定期合并为更大的分段。 此过程称为合并。 由于所有分段都是不可变的,这意味着所使用的磁盘空间通常会在索引期间波动,因为需要在删除替换分段之前创建新的合并分段。 合并可能非常耗费资源,特别是在磁盘I / O方面。
分片是 Elasticsearch 集群分发数据的单元。 Elasticsearch 在重新平衡数据时可以移动分片的速度,例如发生故障后,将取决于分片的大小和数量以及网络和磁盘性能。
注1:避免使用非常大的分片,因为这会对群集从故障中恢复的能力产生负面影响。 对分片的大小没有固定的限制,但是通常情况下很多场景限制在 50GB 的分片大小以内。
注2:当在ElasticSearch集群中配置好你的索引后, 你要明白在集群运行中你无法调整分片设置. 既便以后你发现需要调整分片数量, 你也只能新建创建并对数据进行重新索引(reindex)(虽然reindex会比较耗时, 但至少能保证你不会停机).
主分片的配置与硬盘分区很类似, 在对一块空的硬盘空间进行分区时, 会要求用户先进行数据备份, 然后配置新的分区, 最后把数据写到新的分区上。
注3:尽可能使用基于时间的索引来管理数据保留期。 根据保留期将数据分组到索引中。 基于时间的索引还可以轻松地随时间改变主分片和副本的数量,因为可以更改下一个要生成的索引。
二、索引和分片是否是空闲的
对于每个 Elasticsearch 索引,有关映射和状态的信息都存储在集群状态中。它保存在内存中以便快速访问。 因此,在群集中具有大量索引可能导致较大的群集状态,尤其是在映射较大的情况下。 这可能会变得很慢,因为所有更新都需要通过单个线程完成,以便在更改集群中分布之前保证一致性。
每个分片都有需要保存在内存中的数据并使用堆空间。 这包括在分片级别保存信息的数据结构,但也包括在分段级别的数据结构,以便定义数据驻留在磁盘上的位置。 这些数据结构的大小不固定,并且会根据使用场景不同而有所不同。然而,分段相关开销的一个重要特征是它与分段的大小不严格成比例。 这意味着与较小的分段相比,较大的分段每个数据量的开销较小。 差异可能很大。为了能够为每个节点存储尽可能多的数据,管理堆的使用并尽可能减少开销变得很重要。 节点拥有的堆空间越多,它可以处理的数据和分片就越多。
因此,索引和分片在集群视角下不是空闲的,因为每个索引和分片都存在一定程度的资源开销。
分配的每个分片都是有额外的成本的:
每个分片本质上就是一个Lucene索引, 因此会消耗相应的文件句柄, 内存和CPU资源
每个搜索请求会调度到索引的每个分片中. 如果分片分散在不同的节点倒是问题不太. 但当分片开始竞争相同的硬件资源时, 性能便会逐步下降
ES 使用词频统计来计算相关性. 当然这些统计也会分配到各个分片上。如果在大量分片上只维护了很少的数据, 则将导致最终的文档相关性较差。
注1:小的分片会造成小的分段,从而会增加开销。我们的目的是将平均分片大小控制在几 GB 到几十 GB 之间。对于基于时间的数据的使用场景来说,通常将分片大小控制在 20GB 到 40GB 之间。
注2:由于每个分片的开销取决于分段的数量和大小,因此通过 forcemerge 操作强制将较小的分段合并为较大的分段,这样可以减少开销并提高查询性能。 理想情况下,一旦不再向索引写入数据,就应该这样做。 请注意,这是一项比较耗费性能和开销的操作,因此应该在非高峰时段执行。
注3:我们可以在节点上保留的分片数量与可用的堆内存成正比,但 Elasticsearch 没有强制的固定限制。 一个好的经验法则是确保每个节点的分片数量低于每GB堆内存配置20到25个分片。 因此,具有30GB堆内存的节点应该具有最多600-750个分片,但是低于该限制可以使其保持更好。 这通常有助于集群保持健康。
注4:如果担心数据的快速增长, 建议根据这条限制: ElasticSearch推荐的最大JVM堆空间 是 30~32G, 所以把分片最大容量限制为 30GB, 然后再对分片数量做合理估算。例如, 如果的数据能达到 200GB, 则最多分配7到8个分片。
注5:如果是基于日期的索引需求, 并且对索引数据的搜索场景非常少. 也许这些索引量将达到成百上千, 但每个索引的数据量只有1GB甚至更小. 对于这种类似场景, 建议是只需要为索引分配1个分片。如果使用ES的默认配置(5个分片), 并且使用 Logstash 按天生成索引, 那么 6 个月下来, 拥有的分片数将达到 890 个. 再多的话, 你的集群将难以工作--除非提供了更多(例如15个或更多)的节点。想一下, 大部分的 Logstash 用户并不会频繁的进行搜索, 甚至每分钟都不会有一次查询. 所以这种场景, 推荐更为经济使用的设置. 在这种场景下, 搜索性能并不是第一要素, 所以并不需要很多副本。 维护单个副本用于数据冗余已经足够。不过数据被不断载入到内存的比例相应也会变高。如果索引只需要一个分片, 那么使用 Logstash 的配置可以在 3 节点的集群中维持运行 6 个月。当然你至少需要使用 4GB 的内存, 不过建议使用 8GB, 因为在多数据云平台中使用 8GB 内存会有明显的网速以及更少的资源共享.