基于 Flink CDC 高效构建入湖通道
01Flink CDC 核心技术解析
Flink CDC 是基于数据库日志的 CDC 技术,实现了全增量一体化读取的数据集成框架。配合 Flink 优秀的管道能力和丰富的上下游生态,Flink CDC 可以高效实现海量数据的实时集成。
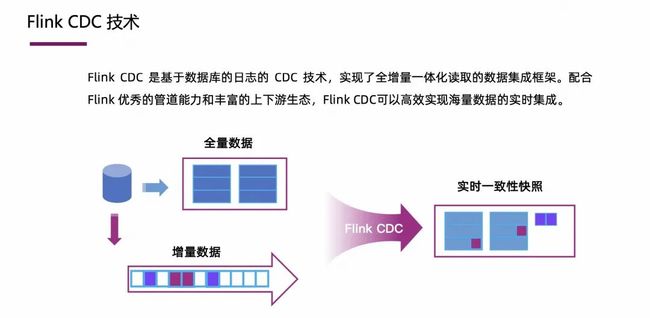
如上图所示,数据库表里有历史的全量数据和实时写入的增量数据,Flink CDC 框架的能力就是在保证 Exactly-once 语义的情况下,将全量和增量数据不丢不重地同步到下游系统里。
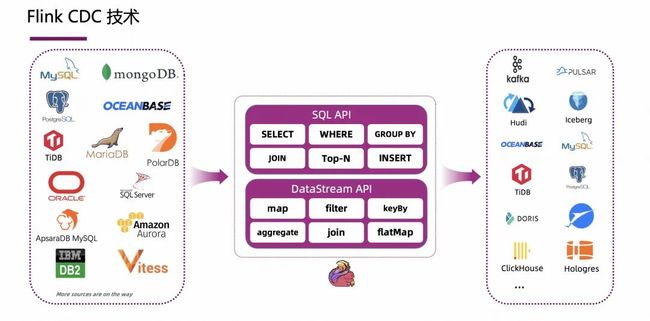
Flink CDC 可以借助 Flink 丰富的上下游生态,目前 Flink CDC 自己上下游生态是非常完备的,比如 Flink CDC 具有丰富的数据源,如 MySQL、Oracle、MongoDB、OceanBase、TiDB、SqlServer,以及兼容 MySQL 协议的 MariaDB、PolarDB 等,写入的下游则更加丰富,支持写入 Kafka、Pulsar 消息队列,也支持写入 Hudi、Iceberg、Paimon 等数据湖,也支持写入各种数据仓库。
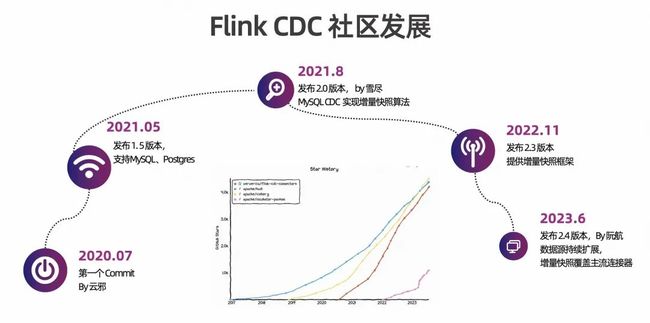
下面介绍下 Flink CDC 的社区发展。
-
2020 年 7 月,Flink CDC 社区正式发起;
-
2021 年 5 月,发布了 1.5 版本,可以支持 MySQL 和 Postgres;
-
2021 年 8 月,发布了 2.0 版本,可以支持 MySQL CDC 实现增量快照算法;
-
2022 年 11 月,发布了 2.3 版本,提供了增量快照框架;
-
2023 年 6 月,发布 2.4 版本,实现主流数据源持续扩展,增量快照覆盖主流连接器。
今年 6 月社区发布了 Flink CDC 2.4 版本,可以通过下图的代码 commits 分布了解该版本的一些重点功能和改进。
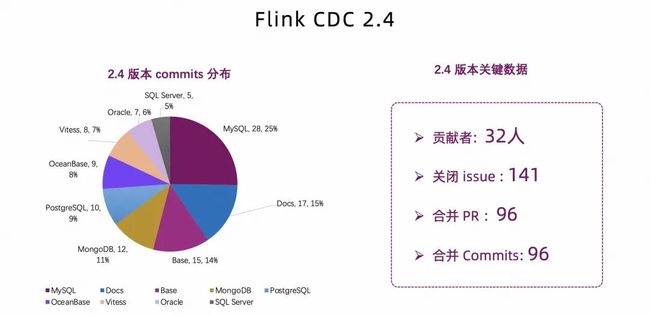
如 MySQL 和 MongoDB 等受到大家的重点关注和贡献,PostgreSQL 和 OceanBase 相关的贡献也比较多。这期间一共有 32 位来自各个公司的贡献者参与到版本的开发中来,解决了 141 个 issue,合并近 100 个 PR。
Flink CDC 2.4 版本的核心 feature 如下:
-
新增 Vitess 数据源支持,这个数据源海外用户较多,国内用户很少,这个特性是来自海外的贡献者;
-
PostgreSQL 和 SQL Server 支持增量快照,可以实现高并发、无锁读取等高级特性;
-
MySQL CDC 支持非 PK 表,即支持无主键表;
-
OceanBase 支持 MySQL Mode 和 Oracle Mode;
-
升级 Debezium 依赖的版本至 1.9.7.Final,修复多个已知问题;
-
Connector 版本兼容 Flink 1.13 至 1.17 多个版本;
-
增量快照框架支持自动释放空闲 reader。

Flink CDC 在发布 2.4 版本后,增量快照支持矩阵如下图所示:
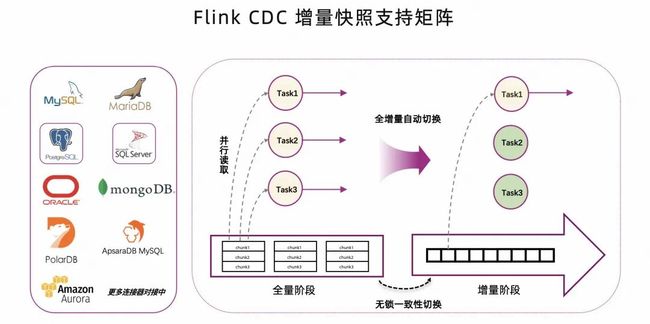
增量快照算法的核心优势在数据比较大的全量阶段,可以实现并行读取;在写入比较少的增量阶段,可以单并发读取。比如图中的 Task2 & Task3 是全增量自动切换后,支持资源自动释放,整个切换过程是通过无锁算法实现的一致性切换。
另外,上图还能说明在一些经典的 TP 类型数据库与大数据系统存在一些鸿沟,比如由于大数据系统往往要处理包括历史数据的海量数据,但由于数据摄入工具的原因导致海量数据不能高效拉取过来,而 Flink CDC 能够很好地在这个鸿沟之上构建数据通道。
总结 Flink CDC 的增量快照框架有如下四个优点:
-
支持并行读取,并行读取的好处是可以做水平扩容,即让用户扩展资源来提升读取效率;
-
支持无锁读取,也就是无需对线上数据库加锁,对业务无入侵;
-
支持全增量一体化,即全量和增量自动衔接,无需人工介入;
-
Exactly-once 语义,准确一次语义,同步过程中确保数据不丢不重。
02CDC 数据入湖入仓的挑战
CDC 数据入湖入仓的挑战大概有以下几点:
-
历史数据规模大,数据库历史数据规模大,上 100T+规模的历史业务数据;
-
增量数据实时性要求高,数据库增量数据业务价值高,且价值随时间递减,需要实时处理;
-
数据的保序性,CDC 数据的加工结果通常需要强调一致性语义,通常需要 ETL 工具支持全局保序;
-
Schema 动态变化,增量数据随时间增长,数据库中数据对应 Schema 会不断演进。
2.1 CDC 数据入湖架构
传统的架构一般分为两个部分,也就是把离线跟实时这两部分分开,这两部分所对应的架构具有其自身的技术特征和业务特性,也可能与公司的业务组织架构相关,比如离线和实时业务分属两个团队,自然会出现这种 Lambda 架构。
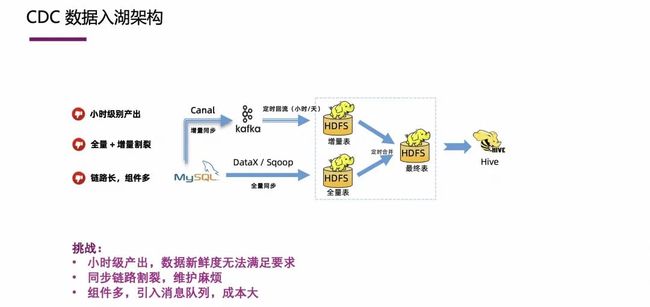
这种传统的方案具有一些弊端,比如数据实时性不够、同步链路割裂维护麻烦、组件多,引入消息队列带来的成本过大等等。
2.2 CDC 数据 ETL 架构
CDC 数据在入湖入仓之前,往往会有 ETL 的需求,即需要做数据清洗、大小写转换或是数据打宽等等。
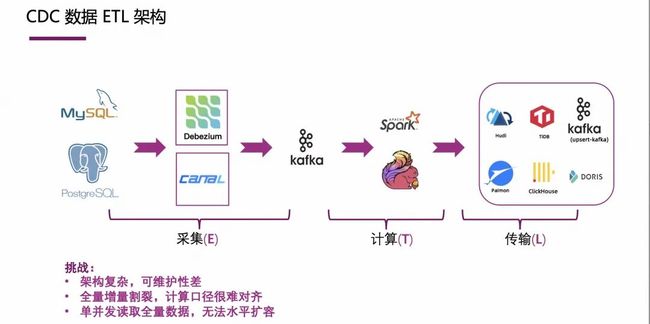
在早期的一些架构中,会先进行采集、计算等数据加工,然后再将数据写入到下游的一些存储中。如上图所示,这种 ETL 架构的挑战有:
-
组件很多,架构复杂,维护代价是比较高;
-
全量和增量基本割裂,数据采集计算口径很难对齐;
-
单并发读取全量数据,无法水平扩容。
03基于 Flink CDC 的入湖入仓方案
介绍完传统的数据入湖入仓方案,再来看看更加简洁高效的 CDC 入湖入仓方案。
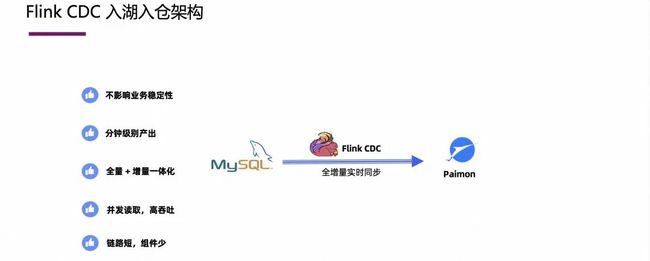
3.1 Flink CDC 入湖入仓架构
Flink CDC 入湖入仓的架构很简洁,如下图所示,比如 MySQL 到 Paimon 的入湖链路,只需要 Flink CDC 一个组件即可,不需要冗长的 Pipeline。
对比上文传统的入湖入仓架构,Flink CDC 架构有如下优势:
-
不影响业务稳定性。这体现在全量数据只读一次;
-
实时性好,支持分钟级别产出;
-
全量+增量一体化,避免了手工操作;
-
全量并发读取,高吞吐;
-
链路短组件少,学习和运维成本低。
3.2 Flink CDC ETL 分析
Flink CDC 是依托 Flink 生态的引擎,CDC 数据接入后可以保证在数据库 CDC 数据的语义下对数据进行加工,比如对 CDC 数据做一些 Group By 等聚合和双流 Join 等打宽操作。
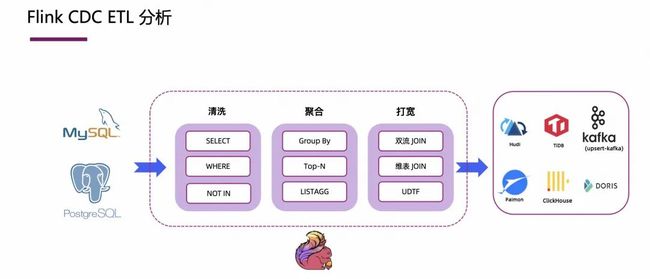
在这些操作中,用户只需要编写 Flink SQL,就能获得相当于在一个数表的物化视图上操作的体验,实现对数据库里全量和增量的数据进行 SQL 操作,这些操作只需要在 Flink SQL 里就能完整实现。这将 CDC 数据做 ETL 加工的门槛极大地降低,只需要用户会写 SQL 就可以实现。
下图为使用 Flink CDC 做 ETL 的架构图,在整个 Pipeline 中,只需要一个 Flink 组件就可以了。这种架构的的优势是:
-
全增量一体化;
-
ETL 可以做到实时加工;
-
支持并发读取;
-
链路短组减少,维护成本低。
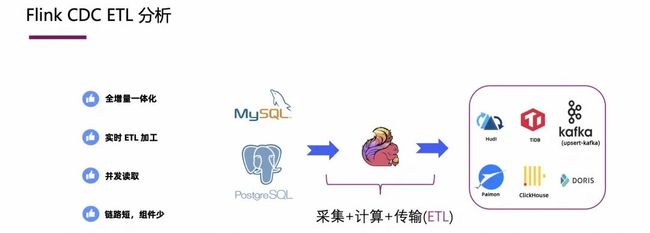
3.3 存储友好的写入设计
Flink CDC 在全量读取的设计中,尤其是增量快照框架,考虑到了很多方面,特别是对于数据切片这部分。充分考虑了数据的一致性和下游的存储特性。比如,Checkpoint 的粒度对于下游存储来讲是很关键因素,如果 Checkpoint 是一个表的粒度,那么一站表的全部数据是很大的,在 flush 或者 commit 的时候,内存里面就要 buffer 很多数据,这就对下游的 sink 节点的写入很不友好。
那么在增量快照框架中,将 Checkpoint 的粒度优化到分片级别,并且切片的大小是开放给用户配置的,用户可以配置一个分片(chunk)可以读取大概多少数据。通过这种细粒度的控制,下游 sink 节点的的写入变得更加友好,不会给内存太大压力。
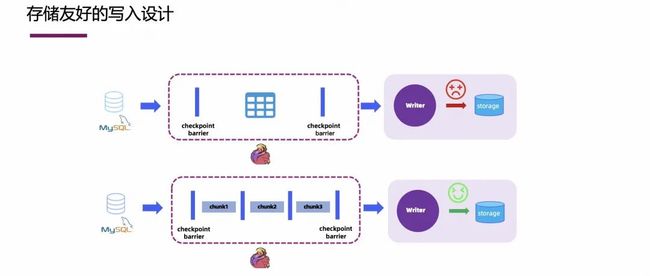
3.4 Flink CDC 实现异构数据源集成
基于 Flink CDC 可以轻松实现异构数据源的集成。当数据库不止一种,针对不同的业务数据库,往往需要把这些库中的数据进行融合,这个时候只需要几行 Flink SQL 就能搞定。
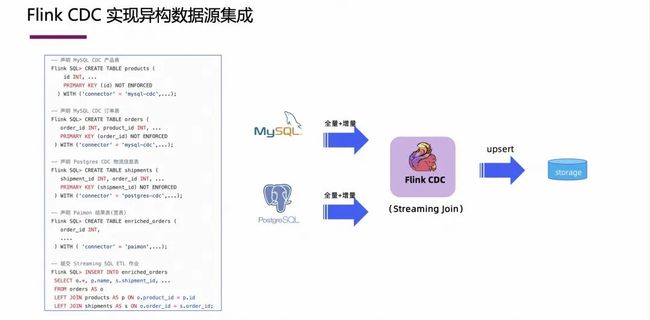
如上图右侧所示,有些业务数据在 MySQL 里,有些数据在 PostgreSQL 里,用户需要做的就是写几行 Flink SQL,定义不同类型的 CDC 表,然后在这里面做一些 Join 再 insert 到结果表中即可。上图左侧展示的是产品表、订单表和物流表之间的打宽,这个也是在 Flink SQL 中就能完成,整个例子中,用户不需要理解 Postgres 的 slot 机制,也不用理解 MySQL Binlog 的机制,只需要理解 Flink SQL 的几个语法即可。
3.5 Flink CDC 实现分库分表集成
对于一些规模加大的业务系统,为了支持高并发请求,分库分表的种架构是非常常见的。Flink CDC 天然支持这种架构的数据表同步,用户只需要在 DDL 中填写满足库名、表名的正则表达式,就可以把满足该正则表达式的分库分表中的历史数据和增量数据同步到下游。
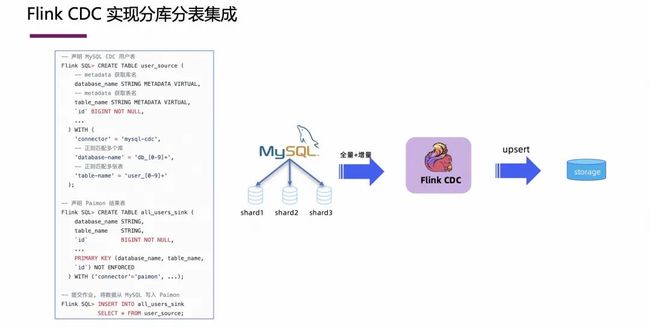
这个例子中,只需要写几行 Flink SQL,就能高效地实现分库分表的数据集成。
04Flink CDC + Paimon 最佳实践
在介绍 Flink CDC + Paimon 的最佳实践之前,首先来介绍下 Paimon 的整体架构。
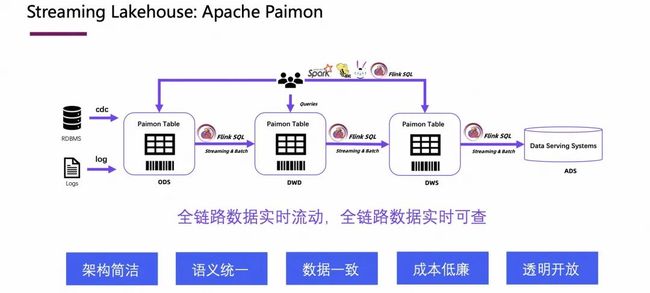
在这张图里,可以看到 Paimon 作为湖存储,CDC 是很重要的一部分。CDC 相当于给 Paimon 把一些数据库系统或是些日志系统里的做第一步的数据接入。
如上图所示,围绕 Paimon 构建的整个数湖仓链路中,数据的实时性是很高的,基本上可以满足近实时业务的需求;数据在各层之间的流动可以通过写 Flink SQL 实现;也可以通过写 Flink 或其他计算引擎将数据读取出来进行分析,是很开放的架构。另外,通过这个架构也可以发现,整个架构的还是比较简洁的,可以通过 Flink SQL 实现语义的统一,也能够保障数据的一致性。
4.1 社区实践
Paimon 社区在 CDC 的支持上,相较于其他开源社区,支持是非常完善的,提供了一系列高级功能支持,比如:
-
支持 Schema Evolution
-
支持 自动建表,字段自动映射
-
一条命令行自动生成同步 Pipeline

Paimon 也支持 MySQL 的整库同步,并且在整库同步作业中,提供了 Schema Evolution 的支持。此外,Paimon 也提供了针对 Kafka 消息队列中的数据同步支持,也支持整库同步。
总的来说,Paimon 社区对于 CDC 的集成功能是非常完备的。
4.2 内部实践
在阿里云内部,我们开发 CTAS/CDAS 语法来实现整库同步和 Schema Evolution 的支持。对比刚刚 Paimon 社区的实践,可以理解为,阿里云内部的实践是上一行 SQL 生成一个 Pipeline,两者所提供的核心功能是差不多的,如自动建表、自动映射等等。

在阿里云内部的实践中也包括 CDC 数据实时入湖入仓,日志数据实时入湖入仓和 CDC 数据 ETL 分析等等。通过 CTAS 和 CDAS 的⼀⾏语法,就可以实现将 MySQL 或 Kafka 数据的整库同步到下游系统。
对于 CDC ETL 分析,阿里云内部实践时也有一些推荐的优化方案,如下图所示,用户可以先将数据同步到消息队列中,在下游有很多个实时作业消费同一张表的数据时,只需要读取一次数据库,这样对数据库的压力会大大减少。

Q&A
Q:CDC 如果可以在不同系统之间移动,我们在开发的过程中有一个需求,就是数据在 IP 端会有挪到 PP 里面的需求,MySQL CDC 在这方面是否会有支持?
A:目前如果数据不需要支持 Schema Evolution,是可以实现这个需求的;如果数据需要支持 Schema Evolution,那么需要利用 Binlog 的机制来协助实现。
Q:请问 Flink CDC 和 Paimon CDC 的区别是什么?Paimon CDC 是通过 Flink CDC 实现的么?
A:Paimon 读取外部数据库的 CDC 数据能力是通过 Flink CDC 实现的,此外 Paimon 自己的表是可以产生 CDC 数据的,也就是说给 Paimon 输入的数据可以是 MySQL CDC 产生的数据,另外一方面 Paimon 表自己也会产生属于该表的 CDC 数据。
Q:在我们使用 CDAS 或 CTAS,对表结构变更是实时的吗?还是在 Checkpoint 里进行的?
A:目前已有实践都是实时的,不会依赖 Checkpoint 机制。因为以来 Checkpoint 机制就可能产生一个问题,即 Checkpoint 上需要消耗几分钟的调整时间,这对于 CDC 数据场景来讲是不足以接受的。