CAM模型可视化(可解释)
模型的可解释性问题一直是个关注的热点。注意,本文所说的“解释”,与我们日常说的“解释”内涵不一样:例如我们给孩子一张猫的图片,让他解释为什么这是一只猫,孩子会说因为它有尖耳朵、胡须等。而我们让CNN模型解释为什么将这张图片的分类结果为猫,只是让它标出是通过图片的哪些像素作出判断的。(严格来说,这样不能说明模型是否真正学到了我们人类所理解的“特征”,因为模型所学习到的特征本来就和人类的认知有很大区别。何况,即使只标注出是通过哪些像素作出判断就已经有很高价值了,如果标注出的像素集中在地面上,而模型的分类结果是猫,显然这个模型是有问题的)
可解释性和可视化有很大的区别,模型有很多的可视化方案:
直接可视化:最容易被想到的一种方式就是对特征图进行可视化,想法是对的,直接对 feature map 进行粗暴的 resize, 或者更为精细点的操作是进行反卷积,将 feature map 放大至和原图一样的大小,但是这样只能算是特征图的可视化,并非模型的可视化,模型的可视化要求其对分类有一定的解释性或者说依据。
CAM可视化:所以目前所说的模型可视化或者模型可解释说到是对某一类别具有可解释性,直接画出来特征图并不能说明模型学到了某种特征,这时候就用到了CAM(Class Activation Mapping)
1. 反卷积和导向反向传播
关于CNN模型的可解释问题,很早就有人开始研究了,姑且称之为CNN可视化吧。比较经典的有两个方法,反卷积(Deconvolution)和导向反向传播(Guided-backpropagation),通过它们,我们能够一定程度上“看到”CNN模型中较深的卷积层所学习到的一些特征。当然这两个方法也衍生出了其他很多用途,以反卷积为例,它在图像语义分割中有着非常重要的作用。
从本质上说,反卷积和导向反向传播的基础都是反向传播,其实说白了就是对输入进行求导,三者唯一的区别在于反向传播过程中经过ReLU层时对梯度的不同处理策略。在这篇论文(https://arxiv.org/pdf/1412.6806.pdf)中有着非常详细的说明,如下图所示:
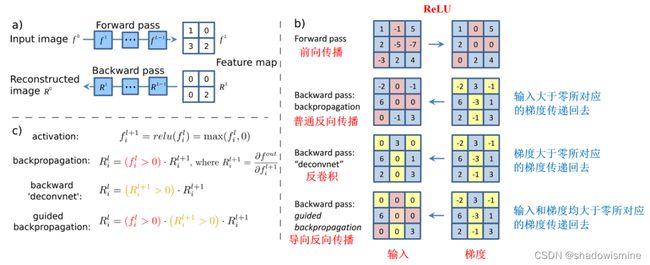
虽然过程上的区别看起来没有非常微小,但是在最终的效果上却有很大差别。如下图所示:

使用普通的反向传播得到的图像噪声较多,基本看不出模型的学到了什么东西。使用反卷积可以大概看清楚猫和狗的轮廓,但是有大量噪声在物体以外的位置上。导向反向传播基本上没有噪声,特征很明显的集中猫和狗的身体部位上。
虽然借助反卷积和导向反向传播我们“看到”了CNN模型神秘的内部,但是却并不能拿来解释分类的结果,因为它们对类别并不敏感,直接把所有能提取的特征都展示出来了。在刚才的图片中,模型给出的分类结果是猫,但是通过反卷积和导向反向传播展示出来的结果却同时包括了狗的轮廓。换句话说,我们并不知道模型到底是通过哪块区域判断出当前图片是一只猫的。要解决这个问题,我们必须考虑其他办法。
2. CAM
大家在电视上应该都看过热成像仪生成的图像,就像下面这张图片。

图像中动物或人因为散发出热量,所以能够清楚的被看到。接下来要介绍的CAM(Class Activation Mapping)产生的CAM图与之类似,当我们需要模型解释其分类的原因时,它以热力图的形式展示它的决策依据,如同在黑夜中告诉我们哪有发热的物体。
对一个深层的卷积神经网络而言,通过多次卷积和池化以后,它的最后一层卷积层包含了最丰富的空间和语义信息,再往下就是全连接层和softmax层了,其中所包含的信息都是人类难以理解的,很难以可视化的方式展示出来。所以说,要让卷积神经网络的对其分类结果给出一个合理解释,必须要充分利用好最后一个卷积层。
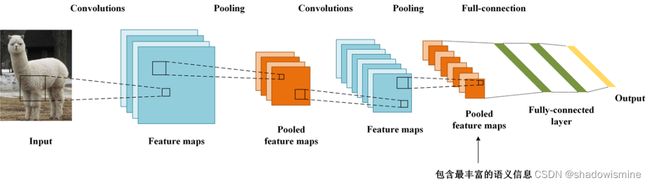
CAM借鉴了很著名的论文Network in Network(https://arxiv.org/abs/1312.4400)_中的思路,利用GAP(Global Average Pooling)替换掉了全连接层。可以把GAP视为一个特殊的average pool层,只不过其pool size和整个特征图一样大,其实说白了就是求每张特征图所有像素的均值。
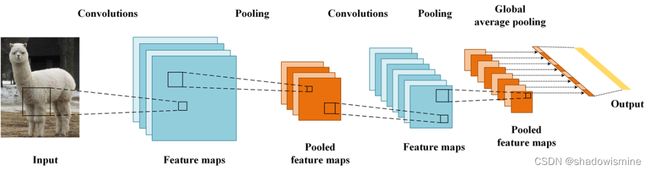
GAP的优点在NIN的论文中说的很明确了:由于没有了全连接层,输入就不用固定大小了,因此可支持任意大小的输入;此外,引入GAP更充分的利用了空间信息,且没有了全连接层的各种参数,鲁棒性强,也不容易产生过拟合;还有很重要的一点是,在最后的 mlpconv层(也就是最后一层卷积层)强制生成了和目标类别数量一致的特征图,经过GAP以后再通过softmax层得到结果,这样做就给每个特征图赋予了很明确的意义,也就是categories confidence maps。如果你当时不理解这个categories confidence maps是个什么东西,结合CAM应该就能很快理解。
我们重点看下经过GAP之后与输出层的连接关系(暂不考虑softmax层),实质上也是就是个全连接层,只不过没有了偏置项,如图所示:
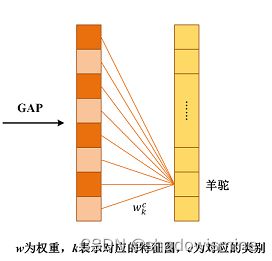
从图中可以看到,经过GAP之后,我们得到了最后一个卷积层每个特征图的均值,通过加权和得到输出(实际中是softmax层的输入)。需要注意的是,对每一个类别C,每个特征图k的均值都有一个对应的 ,记为
,记为![]() 。CAM的基本结构就是这样了,下面就是和普通的CNN模型一样训练就可以了。训练完成后才是重头戏:我们如何得到一个用于解释分类结果的热力图呢?其实非常简单,比如说我们要解释为什么分类的结果是羊驼,我们把羊驼这个类别对应的所有取出来,求出它们与自己对应的特征图的加权和即可。由于这个结果的大小和特征图是一致的,我们需要对它进行上采样,叠加到原图上去,如下所示。
。CAM的基本结构就是这样了,下面就是和普通的CNN模型一样训练就可以了。训练完成后才是重头戏:我们如何得到一个用于解释分类结果的热力图呢?其实非常简单,比如说我们要解释为什么分类的结果是羊驼,我们把羊驼这个类别对应的所有取出来,求出它们与自己对应的特征图的加权和即可。由于这个结果的大小和特征图是一致的,我们需要对它进行上采样,叠加到原图上去,如下所示。
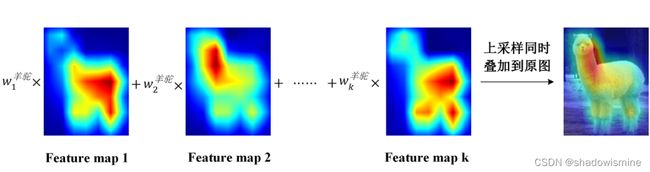
这样,CAM以热力图的形式告诉了我们,模型是重点通过哪些像素确定这个图片是羊驼了。
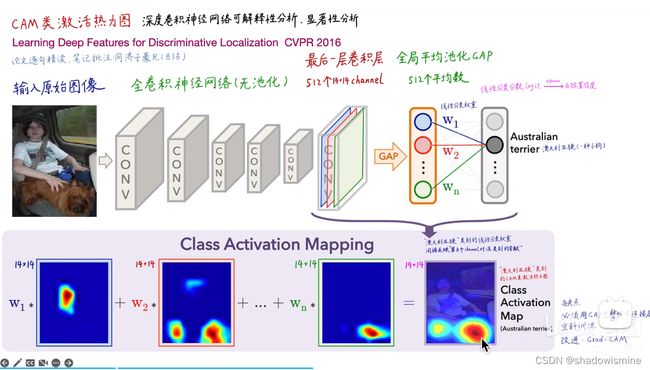
注意到没有池化层:因为池化层会丢失长宽信息,这是CAM无法接受的
CAM的缺点
1.必须要有GAP层,否则无法得到热力图,基于此有了gradCAM
2.只能分析最后一层卷积输出,无法分析中间层的特征图
3.仅限图像分类任务
3. Grad-CAM方法
前面看到CAM的解释效果已经很不错了,但是它有一个致命伤,就是它要求修改原模型的结构,导致需要重新训练该模型,这大大限制了它的使用场景。如果模型已经上线了,或着训练的成本非常高,我们几乎是不可能为了它重新训练的。于是乎,Grad-CAM横空出世,解决了这个问题。
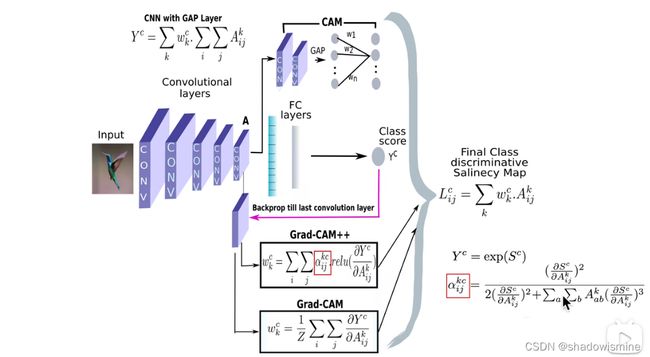
Grad-CAM的基本思路和CAM是一致的,也是通过得到每对特征图对应的权重,最后求一个加权和。但是它与CAM的主要区别在于求权重![]() 的过程。CAM通过替换全连接层为GAP层,重新训练得到权重,而Grad-CAM另辟蹊径,用梯度的全局平均来计算权重。事实上,经过严格的数学推导,Grad-CAM与CAM计算出来的权重是等价的。为了和CAM的权重做区分,定义Grad-CAM中第k个特征图对类别c的权重为
的过程。CAM通过替换全连接层为GAP层,重新训练得到权重,而Grad-CAM另辟蹊径,用梯度的全局平均来计算权重。事实上,经过严格的数学推导,Grad-CAM与CAM计算出来的权重是等价的。为了和CAM的权重做区分,定义Grad-CAM中第k个特征图对类别c的权重为![]() ,可通过下面的公式计算:
,可通过下面的公式计算:
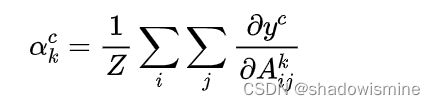
其中,Z为特征图的像素个数, 是对应类别c的分数(在代码中一般用logits表示,是输入softmax层之前的值),
是对应类别c的分数(在代码中一般用logits表示,是输入softmax层之前的值),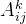 表示第k个特征图中,(i,j)位置处的像素值。求得类别对所有特征图的权重后,求其加权和就可以得到热力图。
表示第k个特征图中,(i,j)位置处的像素值。求得类别对所有特征图的权重后,求其加权和就可以得到热力图。
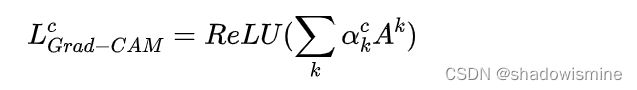
Grad-CAM的整体结构如下图所示:
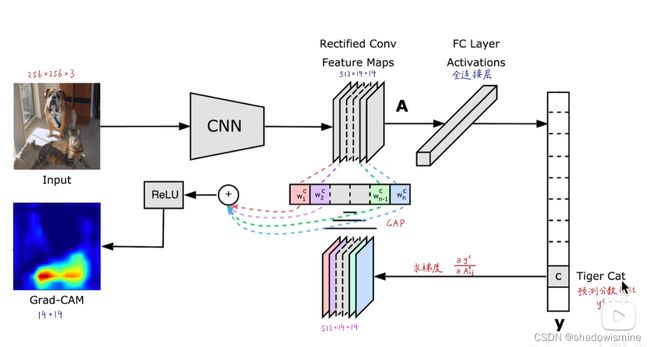
注意这里和CAM的另一个区别是,Grad-CAM对最终的加权和加了一个ReLU,加这么一层ReLU的原因在于我们只关心对类别c有正影响的那些像素点,如果不加ReLU层,最终可能会带入一些属于其它类别的像素,从而影响解释的效果。使用Grad-CAM对分类结果进行解释的效果如下图所示:

除了直接生成热力图对分类结果进行解释,Grad-CAM还可以与其他经典的模型解释方法如导向反向传播相结合,得到更细致的解释。
这样就很好的解决了反卷积和导向反向传播对类别不敏感的问题。当然,Grad-CAM的神奇之处还不仅仅局限在对图片分类的解释上,任何与图像相关的深度学习任务,只要用到了CNN,就可以用Grad-CAM进行解释,如图像描述(Image Captioning),视觉问答(Visual Question Answering)等,所需要做的只不过是把y^c换为对应模型中的那个值即可。限于篇幅,本文就不展开了,更多细节,强烈建议大家去读读论文(https://arxiv.org/abs/1610.02391),包括Grad-CAM与CAM权重等价的证明也在论文中。如果你只是想在自己的模型中使用Grad-CAM,可以参考这个链接(https://github.com/Ankush96/grad-cam.tensorflow),熟悉tensorflow的话实现起来真的非常简单,一看就明白。
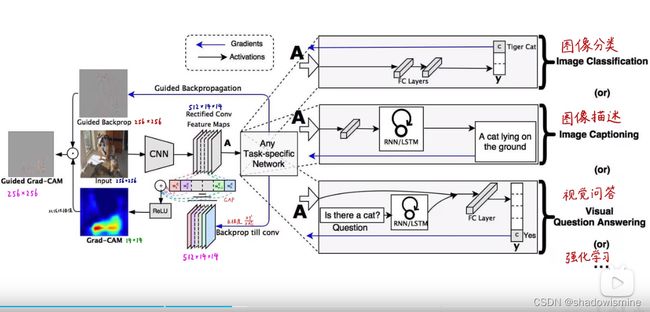
在文字描述生成任务中:就是说根据一张图生成文字描述,如下图所示,使用GradCAM,不仅可以生成文字,还有生成该文字所依赖的特征。

Grad-CAM的缺点
1.图像上有多个同类物体时,只能画出一块热力图,比方说图中有三值猫,但只能画出一只猫,
2.不同位置的梯度,GAP平局之后,影响相同,但一般来讲图片边缘的影响应该小于图像中心。
3.梯度饱和、梯度消失、梯度噪声
4.权重大的channel,不一定对类别预测分数贡献大
5.只考虑从后往前的反向传播梯度,没考虑前向预测的影响
6.深层生成的粗粒度热力图和浅层生成的细粒度热力图都不够精确
7.CAM中只能分析最后一层,GradCAM可以分析中间层,但发现在浅层中,分析效果很差,基于这个有了layer CAM
3. Grad CAM++
解决Grad CAM两个问题:
1.图像上有多个同类物体时,只能画出一块热力图,比方说图中有三值猫,但只能画出一只猫,
2.不同位置的梯度,GAP平局之后,影响相同,但一般来讲图片边缘的影响应该小于图像中心。
对于第一个问题简单理解:从下图看假设intput image输入的图片包含三个猫(分别对应灰色区域),经过卷积之后,这三个区域分别出现在不同的特征图之中,经过Grad CAM处理之后只能激活其中一个猫的特征图,在Grad CAM++中, 可以同时激活三个猫的特征图。
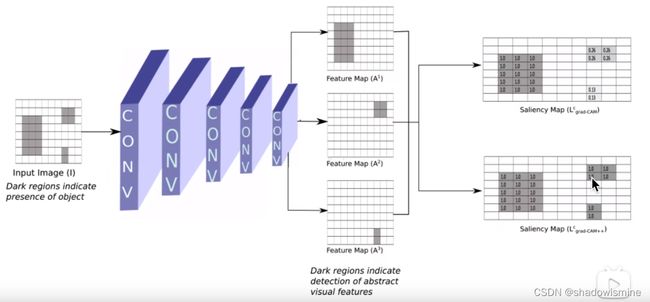
对于第二个问题简单理解:就是对梯度加了权重,来区别不同位置梯度的影响。
4. Score CAM
解决Grad CAM三个问题:
3.梯度饱和、梯度消失、梯度噪声
4.权重大的channel,不一定对类别预测分数贡献大
5.只考虑从后往前的反向传播梯度,没考虑前向预测的影响
做个对比:如下图所示,明显Score CAM热力图对应的位置更加聚焦。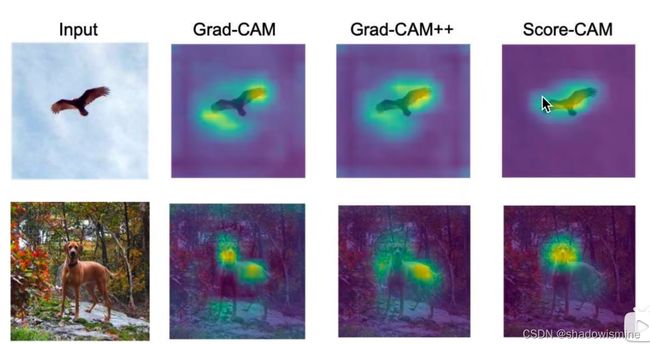
思路:
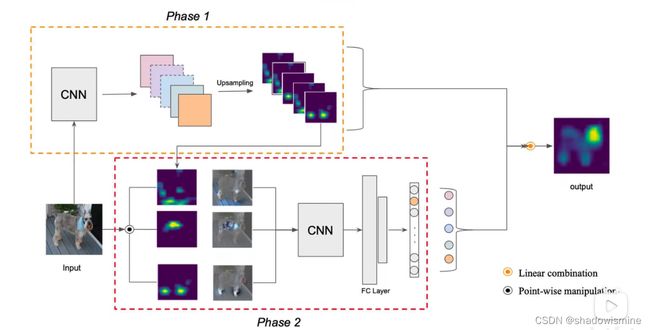
首先用Phase1(第一个网络),经过Upsampling之后得到14×14×256个特征图,将这些特征图和原图input的小狗分别相乘我们会得到,将每个特征图在原图中对应的位置高亮显示,进一步得到每一个特征图对应他权重,最后Phase2输出这些权重和Phase1中对应的每一个特征图相乘得到Score CAM的结果。
5. layer CAM
解决Grad CAM2个问题:
6.深层生成的粗粒度热力图和浅层生成的细粒度热力图都不够精确
7.CAM中只能分析最后一层,GradCAM可以分析中间层,但发现在浅层中,分析效果很差,基于这个有了layer CAM
应用:工业检测很合适。
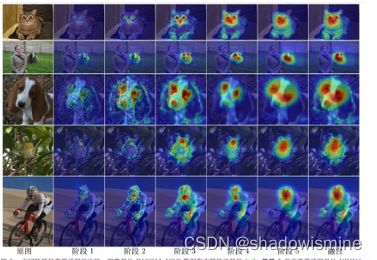
做个对比:如下图左所示,第一行为Grad CAM的特征结果,第二行为layer CAM的特征结果,很明显Grad CAM噪声过多。如下图右所示,即使在浅层中也能聚焦较好的特征。
参考资料:
https://blog.csdn.net/herr_kun/article/details/106997646
https://blog.csdn.net/weixin_48878618/article/details/132111587
凭什么相信你,我的CNN模型?关于CNN模型可解释性的思考