CRNN论文阅读笔记
文章目录
目录
前言
一、摘要
二、使用步骤
1.引入库
2.读入数据
总结
- 前言
- 一、pandas是什么?
- 二、使用步骤
- 1.引入库
- 2.读入数据
- 总结
前言
因项目需求,最近在学习OCR相关的深度学习模型,之前虽然看过CRNN相关的一些文章,熟悉大体的模型框架,但还没有阅读过原论文,今天抽时间看了下,因此这里做下阅读笔记。
CRNN论文标题: An End-to-End Trainabel Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition.
Abstract
论文指出,基于图像的字符序列识别是计算机视觉方面的具有代表性的研究方向。论文探索了自然场景文本识别问题,这是基于图像的字符序列识别中一个及其重要以及很有挑战性的任务。论文提出了一个新颖的网络架构,它集成了特征提取层(CNN),序列识别层(RNN),转录层(CTC)。
和之前的自然场景文本识别系统相比,本文提出的网络架构有4个特点:
1. 它是训练过程是端到端的,即end-to-end.
2. 它可以识别任意长度的文本序列;
3. 没有预定义文本字典的限制;
4. 生成一个有效且更小的网络模型。
论文在IIIT-5K, Street View Text 和 ICDAR 这些数据集进行了benchmark, 证实本论文提出的网络模型超过了当时已存在的其它模型。
1. Introduction
论文聚焦于计算机视觉的一个经典问题:基于图像的文本序列识别。
在现实世界中,像场景文本,手写字体以及乐谱这些目标,通常是以序列,而不是独自出现。不像一般的目标识别,识别这种序列目标通常需要系统预测一串目标label,而不是单一的。因此,识别这种目标可以转换为序列识别问题。另外,序列识别的一个独特特性是目标的长度是任意的。论文中的例子:英文单词可以是2个字符组成,e.g. "OK", 也可以是15个字符组成,e.g. "congratulations"。但是,深度卷积网络(Deep Convolution Neural Network, DCNN)只能用于解决固定输入与输出维度的问题,因此不适用于本文基于图像的可变长度的序列识别问题。
循环神经网络(Recurrent neural networks, RNN)就是为解决序列识别问题而设计的。RNN的优势之一就是:不论在训练还是测试阶段,RNN都不需要知道图像中序列每一元素的位置。但是,预处理过程是极其重要的:将输入的目标图像转换为图像特征序列。这一预处理过程只是现有基于RNN实现的系统流水线上的一个组成部分,因此不是end-to-end。
论文也介绍了几个基于传统方法进行场景文本识别的方法,但是识别结果是比基于神经网络方法要差的。
论文提出的新颖的网络模型,即卷积循环神经网络(Convolutional Recurrent Netural Network, CRNN)就是为识别图像中文本序列而设计的。对比DCNN, CRNN有如下几方面的优势:
1. 可以直接对文本序列labels(e.g. words 单词) 进行学习,不需要详细的注解(e.g. characters 组成单词的每一字符);
2. 具有DCNN的特性:可以直接从图像中学习特征表示;
3. 具有RNN的特性:能够生成labels序列;
4. 对序列目标的长度没有限制,但是在训练和测试阶段要统一识别图像的高度;
5. 实现了场景文本识别的最优;
6. 模型具有比DCNN更少的参数,消耗更少的存储空间。
2. The Proposed Network Architecture

Figure 1图示了CRNN的网络结构。CRNN由三部分组成,从下往上依次为:卷积层(Convolutional Layers),循环层(Recurrent Layers),转录层(Transcription Layers)。
卷积层用于从输入图像中提取特征序列;卷积层的输出作为循环层的输入,然后循环层为每一特征序列做预测,输出预测的标签序列;循环层的输出作为转录层的输入,最后转录层将循环层的输出标签序列转换为最终的标签序列,即去除冗余字符。
虽然CRNN包含CNN和RNN两种不同的网络结构,但是可被一个损失函数训练(CTCLoss).
2.1 特征提取网络(CNN)
在CRNN中,卷积层由convolutional和max-pooling组成,但是移除了fully-connected部分。对于输入CNN的图片要进行缩放,保证所有的输入图片由相同的高度。Recurrent层的输入是特征向量序列,它是从卷积层的输出, 即feature maps中提取。序列中每一特征向量是feature maps按列从左向右生成的,即第 个特征向量是由所有feature maps中第列拼接而成。每一列的宽度固定为1 pixel。
个特征向量是由所有feature maps中第列拼接而成。每一列的宽度固定为1 pixel。
CNN输出的feature maps中每一列和输入图像的一个矩形区域,即感受野相关,输入图像上矩形区域的顺序和feature maps上相对应的从左到右的列的顺序一样,如同Fig.2 图所示。可把特征序列中的每一特征向量视为输入图像相应矩形区域的图像描述符。

CRNN正是将CNN这种深层输出特征 (feature maps) 转换为序列式的表达来保持不变性以应对序列目标长度的变化。(将CNN的输出feature maps转换为向量特征序列作为RNN的输入,RNN可以训练变长特征输入。)
2.2 序列标签化(Sequence Labeling)
CRNN的循环层是一个双向RNN,连接卷积层的输出。循环层对卷积层输出的特征序列![]() 每一个特征向量
每一个特征向量 进行预测,输出
进行预测,输出 即label。
即label。
循环层的优势有三点:
1. RNN有一个强大的能力:捕获序列的上下文信息。拿场景文本识别为例,宽的字符可能要几个特征向量来描述,如Fig.2所示。除此之外,一些歧义字符可以通过上下文信息被被简单地区分,比如“i”,"l"与单独识别这两个字符相比,通过对比字符高度可以更简单的区分它们。
2. RNN 可以反向传播误差到输入,CRNN可以联合训练循环层和卷积层;
3. RNN 可以训练任意长度的序列;
传统的RNN如下图所示:

传统RNN在输入层和输出层间有一个自连接的隐藏层。它每次接受特征序列中的一个特征向量,使用非线性函数,将当前输入和过去的状态 作为输入更新内部状态
作为输入更新内部状态 :
:![]() 。基于生成。然而,传统的RNN有一个缺点:容易发生梯度爆炸问题,这个问题限制了RNN可以保存的上下文范围,因而增加了训练过程的负担。
。基于生成。然而,传统的RNN有一个缺点:容易发生梯度爆炸问题,这个问题限制了RNN可以保存的上下文范围,因而增加了训练过程的负担。
长短期记忆(Long Short Term Memory, LSTM)也是RNN的一种,它解决了传统RNN的梯度爆炸问题,如下图Figure.3(a)所示:
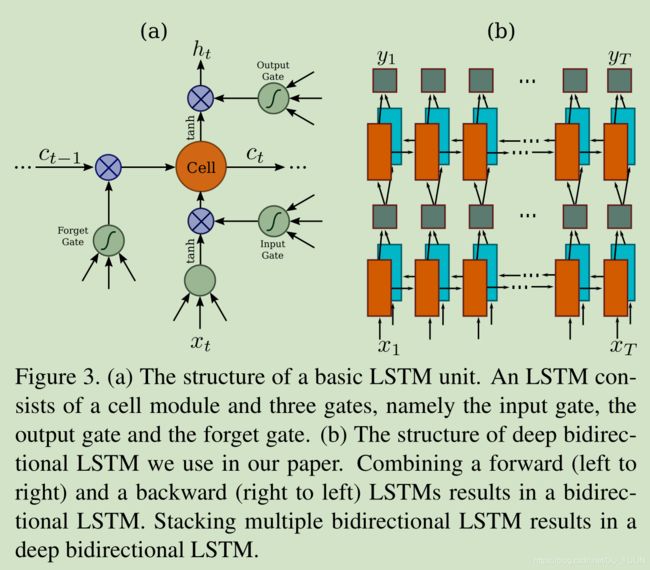
LSTM有一个记忆cell和三个Gate组成,分别为Input Gate, Output Gate和Forget Gate。记忆Cell负责保存过去的上下文信息,Input Gate 和 Output Gate保证Memory Cell可以保存长期的上下文信息, Forget Gate负责清空Memory Cell中的上下文信息。
LSTM是有方向的,它只能使用过去的上下文信息。但是基于图像的序列中,两个方向的上下文信息都是有用并且重要的。因此,CRNN使用了双向LSTM,前向和后向, 可以堆叠多个双向LSTM, 如图Figure.3(b)所示。这种深层的LSTM结构可以获得更高级别的抽象特征,在语音识别任务上获得了显著的性能提升。
在循环层,误差传播的方向是和Fig.3(b)图像中箭头方向相反。论文在实现时,创造了一个特别的网络层作为CRNN的卷积层和循环层的桥梁,被称作“Map-to-Sequence”。
2.3 转录(Transcription)
转录是这样一个过程:将循环层输出的预测labels序列转化为最终的标签序列(祛除了RNN中冗余的标签)。从数学角度来讲,转录是在循环层输出的每一预测labels中查找使条件概率最高的label序列。有两种转录方式:基于受限词典的(lexicon-based)、基于自由词典的(lexicon-free)。词典(lexicon)是labels 序列的集合,基于词典的预测是受限的,比如,拼写检查词典。而基于自由词典表示预测是不受词典限制的,即没有词典。基于受限词典的转录方法,通过选择最高概率的label序列作为转录层的输出序列。
2.3.1 label序列的概率计算
论文使用了在Connectionist Temporal Classification(CTC)中定义的条件概率,即在转录层输出的预测label序列![]() 的条件下,计算ground truth label序列的概率。论文使用概率的对数似然作为目标来训练网络,仅需要预测图片和相应的ground truth label序列,节省了定位每一单独字符精确位置的人力。
的条件下,计算ground truth label序列的概率。论文使用概率的对数似然作为目标来训练网络,仅需要预测图片和相应的ground truth label序列,节省了定位每一单独字符精确位置的人力。
条件概率公式如下所示:

 表示一个可能label序列,
表示一个可能label序列,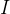 表示ground truth label序列,
表示ground truth label序列, ![]() 表示将一个可能的label序列映射为ground truth label序列,
表示将一个可能的label序列映射为ground truth label序列,![]() 表示映射函数,它用于去除冗余字符以及‘-’ blank字符。
表示映射函数,它用于去除冗余字符以及‘-’ blank字符。
![]() ,其中
,其中![]() 表示t时刻预测标签为
表示t时刻预测标签为![]() 的概率
的概率
2.3.2 自由词典转录(lexicon-free)
在lexicon-free 模式下,序列![]() 定义为Eq.(1)有最高概率值。论文中说没有可用的算法可以精确找到Eq.(1)的最高概率值的序列。论文使用了近似算法求得序列
定义为Eq.(1)有最高概率值。论文中说没有可用的算法可以精确找到Eq.(1)的最高概率值的序列。论文使用了近似算法求得序列 ![]() ,比如在时刻
,比如在时刻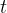 获得最大概率的label
获得最大概率的label ![]() ,然后通过映射函数将label序列映射为
,然后通过映射函数将label序列映射为![]() 。
。
2.3.3 基于词典的转录(lexicon-based)
在lexicon-based模式下,每一个测试用例都和词典相关。基本上,识别label序列可通过在词典中挑选最高条件概率的序列来实现。但是,词典一般都是比较大的,比如50k-words Hunspell spell-checking 词典,在这个词典上进行完全查找将耗费很长的时间。论文方法采用lexicon-free的方法来转录预测的label序列通常是更接近ground truth label序列的(在距离度量标准)。这允许仅在最近邻候选中查找,即![]() 。这里
。这里 论文中说是最大的度量距离(个人理解为threshold, 查找的label序列与ground truth label序列的距离应该小于或等于这个threshold。)
论文中说是最大的度量距离(个人理解为threshold, 查找的label序列与ground truth label序列的距离应该小于或等于这个threshold。)

论文提到![]() 可通过BK-Tree这种数据结构来高效查找。论文提到,每一词典的BK-tree被offline生成,然后应用这个BK-tree进行online 查找,查找的序列和ground truth label 序列的距离应该小于或等于。
可通过BK-Tree这种数据结构来高效查找。论文提到,每一词典的BK-tree被offline生成,然后应用这个BK-tree进行online 查找,查找的序列和ground truth label 序列的距离应该小于或等于。
2.4 网络训练
训练数据集表示为![]() ,
, ![]() 为训练图像,
为训练图像,![]() 为ground truth label序列。网络训练的目标是最小化ground truth条件概率的负对数似然的,如下式:
为ground truth label序列。网络训练的目标是最小化ground truth条件概率的负对数似然的,如下式:

Eq.(3)中 表示循环层输出的label序列,这个函数用于计算输入图像和ground truth label序列的损失值。因此,这个网络是在输入为图像和ground truth 序列的end-to-end训练网络,消除了手动标注输入图像的每一个字符的过程。
表示循环层输出的label序列,这个函数用于计算输入图像和ground truth label序列的损失值。因此,这个网络是在输入为图像和ground truth 序列的end-to-end训练网络,消除了手动标注输入图像的每一个字符的过程。
训练网络应用随机梯度下降的优化算法(stochastic gradient descent, SGD),应用ADADELTA更新学习率。ADADELTA不需要手动设置学习率,而且比动量方法(momentum)更快。
3. 实验
论文为场景文字识别和乐谱识别进行了benchmark实验。
3.1 数据集
CRNN网络在合成数据集上训练一次,然后再真实环境进行测试(没有进行任何微调操作)。
论文使用了4个流行的benchmark数据集:ICDAR2003(IC03), ICDAR2013(IC13), IIT 5k-word(IIT5k), Street View Text(SVT)。
3.2 CRNN网络详细结构

为了匹配英文文本的识别,在3rd 和4th max pooling层,采用1x2 大小的矩形窗口(取代方形pooling窗口),这样可以输出的feature maps更宽,使提取的特征序列更长,比如,对于包含10个字符的100x32的图像,可以生成一个长度为25的特征序列,这个长度超过了大部分的英文单词的长度。矩形pooling 窗口可以生成矩形感受野(如图Fig.2所示),这对于识别一些比较窄的字符很有益,比如‘i’和‘I’。
论文发现batch normalization对于训练深层网络特别有用。论文中在5th和6th卷积层分别添加了batch normalization层,加速网络的训练。
总结
CRNN这篇论文就介绍到这里, 后面会进行网络训练,如果有时间,会对CRNN的训练进行介绍。另外对于论文实验部分没有详细介绍,如果大家感兴趣,可以自行阅读, 谢谢!