我用飞桨做了一个可回收垃圾材料分类机


随着社会生产力的发展,工业化、城镇化的兴起和人口增加,人类社会产生的垃圾与日俱增,加剧了全球范围内的资源短缺和环境污染,对自然环境和人体健康带来了巨大的挑战。
从中国新能源网和中国再生资源回收利用协会的“2018 年城市垃圾处置报告”中了解到,城市生活垃圾中的可再生资源的价值非常可观。在德国、比利时、法国、荷兰等发达国家使用机械化垃圾分类,可回收垃圾利用率较高,废旧玻璃回收率高达85%以上,而目前我国废旧玻璃的回收率不足30%,多数地区回收率只有15%。
近年来,深度学习在图像分类和目标识别领域取得了突破性进展。因此,该项技术也在垃圾处理中进行了研究和应用,也诞生了垃圾分类手机APP和嵌入式边缘设备。但是,这些研究都是针对单一的可回收垃圾数据集进行的图像分类,模型缺少对于新的、较为复杂环境的垃圾数据的分类检验,也没有进行多目标垃圾识别的研究。本文运用百度飞桨深度学习框架,分别构建了ResNet50和以MobileNetv1 为骨架的SSD深度神经网络的可回收垃圾分类及检测模型,对可回收垃圾的图像进行分类和目标识别,图像分类识别准确度可以达到95%,目标识别mAP可以达到63%。
图像分类及目标识别模型架构,详见百度飞桨官方Github:
ResNet50:
https://github.com/PaddlePaddle/models/tree/release/1.7/PaddleCV/image_classification
以MobileNetv1为骨架的 SSD:
https://github.com/PaddlePaddle/PaddleDetection
在下文中,我们将为大家解析可回收垃圾材料分类机图像分类和目标识别的过程。
图像分类
01
数据采集与预处理
本设计研究的对象为可回收垃圾材料,使用的数据来源于斯坦福大学的可回收垃圾集和自行调查拍摄增补的可回收垃圾材料集,包含纸、金属、玻璃、塑料这4类可回收垃圾材料,共1987张垃圾图像,每一类均有500张左右的照片。

图 1 数据集样图
应用留出法,将80%的样本设置为训练集,20%的样本设置为测试集。为了增加训练集的数据量,提高模型的泛化能力,对训练集进行数据增强处理,应用数据增强技术,对已有图片做缩放、随机旋转、随机裁剪、对比度调整、色调调整以及饱和度调整,使得总训练样本量达到13909张,数据增强后,大幅提升了训练样本数量。
02
迁移学习
在本研究中,针对目前可回收垃圾数据集资源较少的问题,为保证模型的鲁棒性及泛化能力,采取Fine Tune迁移学习策略。该学习策略采用两步化方案:第一步是预训练过程,首先,让卷积神经网络载入预训练参数,并且冻结网络的隐藏层,阻止全连接层进行反向传播,接着,以较小的学习率与训练数据规模,对新数据集的训练集进行训练,最终获得一个新的全连接层;第二步是解除隐藏层的冻结,允许预训练得到的全连接层进行反向传播,对隐藏层的权重进行优化并微调(Fine Tune)。

图 2 Fine Tune迁移学习示意图
以上述的数据集作为迁移学习的训练集,以飞桨开放的ImageNet预训练参数作为迁移学习源。构建卷积神经网络,去除最后一层全连接层(分类器),将预训练参数载入卷积神经网络(特征提取器),同时冻结整个整个卷积神经网络,阻止其在预训练过程中进行反向传播。在完成预训练后,保存新的分类器参数。
接着,开放分类器上层的卷积神经网络部分,允许训练过程中从全连接层到网络浅层的反向传播,并且使用新的全连接层对特征提取器进行微调,使得模型更好的应用于新的数据集。
03
模型性能比较
针对垃圾图像数据集,在没有使用Fine Tune迁移学习时,SE_ResNeXt-50在测试集上的准确率为93%;使用迁移学习方案后, SE_ResNeXt-50在测试集上的准确率95%,不仅如此,使用迁移学习后,模型的训练次数减少了原本的50%以上,大幅缩短了训练时间,同时也提升了模型的性能。
表 1 Fine Tune迁移学习对模型性能比较
模型 |
测试准确率 |
是否迁移学习 |
SE_ResNeXt-50 |
93% |
否 |
SE_ResNeXt-50 |
95% |
是 |

图 3 SE_ResNeXt-50训练损失值以及训练正确率

图 4 SE_ResNeXt-50 测试混淆矩阵
结合上述研究,SE_ResNeXt-50在测试集中的表现效果较好,但从其混淆矩阵中发现,对于金属与玻璃两种可回收垃圾的分类仍存在误差,在未来的研究中,希望引入物体光谱的数据集来缓解这一问题。
04
基于Web服务器分类系统设计
为实现可回收垃圾材料分类机的落地实现,我们设计了一个原型机。原型机设计包括服务器端代码模块、树莓派舵机套件组装及嵌入式系统代码模块。

图 5 垃圾材料分类器系统设计图
在服务器端部署在线推理引擎。我们将Base64图像解码模块和飞桨预测模型内嵌在一个基于Flask的Python Web框架中,用于接收热数据并进行实时的垃圾图像预测分类。
Flask与飞桨预测模型的执行是完全同步的,即按照接收客户端请求的顺序,顺序地处理并将分类结果返回至客户端。
边缘端是基于树莓派配合摄像头和垃圾桶套件实现的。在树莓派上配置Python脚本,控制摄像头进行延迟拍摄并将图片保存至本地;将图片转为Base64编码,以Post方式发送给服务器端,服务器端处理后以二进制形式将结果返回给树莓派;树莓派接收结果后,脚本调用指定的GPIO端口,控制舵机运作。

图 6 垃圾材料分类器
目标识别
01
数据准备与数据预处理
在本研究中,研究对象为可回收垃圾,我们将可回收垃圾材料分为四类,分别是玻璃、塑料、金属、纸张,将斯坦福大学的可回收垃圾图像数据集(TrashNet dataset)[1]的1987张可回收垃圾图像数据和自行采集的253张多目标可回收垃圾图像进行打标签,每一个样本的尺寸均为512 x 384 px。
图 7 数据集样例
为了进行可回收垃圾的目标识别,使用图像标注软件Labelimg1.3.3标注每一幅图像中可回收垃圾的坐标和类别,生成xml格式的标签文件,再转换为coco格式的不同背景下可回收垃圾图像(图8)。

图 8 使用软件Labelimg 1.3.3标注数据集
将斯坦福大学的可回收垃圾和自行采集的数据集融合并标注完成,我们使用留出法将80%的样本设置为训练集,20%的样本设置为测试集。为了增加训练集的数据量,提高模型的泛化能力,对训练集进行数据增强处理,应用数据增强技术,对已有图片进行缩放、随机旋转、随机裁剪、对比度调整、色调调整以及饱和度调整等数据增强操作,其中表2描述了多目标识别数据集中每类可回收垃圾的数量。
表2 可回收垃圾材料类别数量

02
MobileNetv1-SSD目标识别的优势
Single Shot MultiBox Detector (SSD) 是一种单阶段的目标检测器。与两阶段的检测方法不同,单阶段目标检测并不进行区域推荐,而是直接从特征图回归出目标的边界框和分类概率。SSD 运用了这种单阶段检测的思想,并且对其进行改进:在不同尺度的特征图上检测对应尺度的目标。如下图所示,SSD在六个尺度的特征图上进行了不同层级的预测。每个层级由两个3x3卷积分别对目标类别和边界框偏移进行回归。SSD可以方便地插入到任何一种标准卷积网络中,比如 VGG、ResNet 或者 MobileNetv1,这些网络被称作检测器的基网络。这里我们使用轻量级的MobileNetv1作为检测器的基网络。

图9 MobileNetv1 SSD 体系架构
SSD[2]方法基于一个前向卷积网络,该网络生成一个固定大小的边界框集合,并根据这些框中物体的包含程度进行评分,然后执行要给非最大抑制步骤,产生最后的检测结果。

图10目标识别边界框集合
MobileNetv1[3]是一种针对资源受限环境的网络结构,能够轻松部署运算能力较弱的设备,由深度可分离卷积代替标准卷积建立的,深度可分离卷积是把标准卷积分解成深度卷积和逐点卷积,这样可以大幅度降低参数量和计算量。
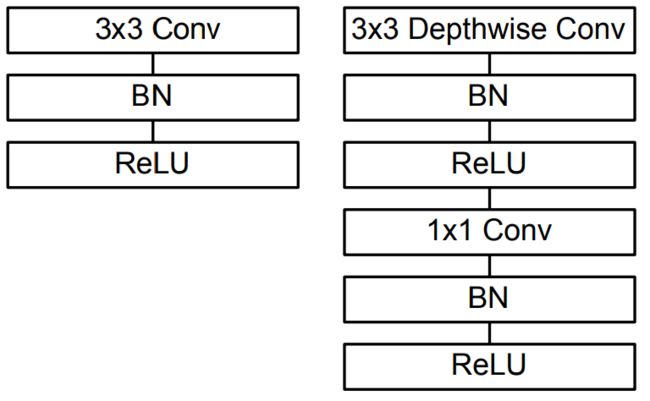
图11 左图为标准卷积,右图为深度可分离卷积
MobileNetv1完整结构如下表所示:

03
实验过程及实验结果
由于我们团队比较缺乏算力,因此使用了AI Studio平台免费提供的高级版(GPU:Tesla V100,Video Mem:16GB;CPU:8Cores,RAM:32GB, Disk:100GB)。
训练过程首先定义GPU计算场所,创建一个executor,对program进行参数初始化。设置迭代次数,用训练集进行训练。在训练过程中,模型每完成1次迭代 ,保存模型并输出pass_id, loss, mAP,损失率逐渐下降,mAP逐渐提高,模型逐渐优化。保存参数模型,生成预测模型,评估模型。在训练过程中,每完整地训练10个epoch后,将输出当轮的参数模型,方便从中间节点重新训练模型。完成训练后,将输出预测模型。利用测试集对训练的网络进行评估,输出mAP 63%,实验结果如下。

图12目标识别测试结果
然后,尝试使用树莓派模拟可回收垃圾材料分类机的落地实现,服务器端使用飞桨深度学习框架训练MobileNetv1 SSD 目标识别模型,利用Paddle Lite提供的工具编译模型,将模型部署在树莓派等边缘设备,树莓派获取摄像头照片并执行编译后的模型,输出结果,控制舵机,在树莓派上的实验结果如图14。

图 13 边缘端设备执行模型过程

图 14 边缘端设备执行结果
Paddle Lite详解及使用,详见百度飞桨官方Github:
https://github.com/PaddlePaddle/Paddle-Lite
https://github.com/PaddlePaddle/Paddle-Lite-Demo
总结与展望
经过实验和分析,该原型机设计基本达到了设计目标,实现了在小区垃圾回收站的可回收垃圾自动分类的效果,单目标垃圾分类准确率为95%,多目标垃圾识别准确率达63%,说明基于飞桨框架的垃圾图像分类具有较好的应用效果。
增加可回收垃圾的数据集、提高可回收垃圾模型的识别率进而达到模型落地应用的程度是该项目后期需要努力的方向。根据可回收垃圾处理方式的不同,精细化垃圾的种类,将识别模型运用于:瓶子的瓶盖是否已经打开;原纸印刷品、牛奶盒、鸡蛋盒、再生纸等更加精细的分类;对于不同颜色玻璃的分类,对于不同金属颜色的分类等。
在智能垃圾箱的设计中,配合积分奖励制度及实名制度,鼓励用户对可回收垃圾分类事业作出努力与贡献,那么从可回收垃圾的源头就可以实现粗分类,有效缓解可回收垃圾在源头上进行分类,提高再生资源回收率;多目标垃圾识别的可行性仅在高性能PC端得到验证,具体的模型提升和机械设计仍需进一步努力实现。
最终,将深度学习模型与机械自动化技术融合,将其运用于真正的再生资源全品类分类处理的第一线,实现基于目标识别和图像分类的可回收垃圾材料分类机的完整系统,提高我国垃圾处理的自动化设备率和可回收垃圾的利用率。
参考文献
[1]. Gary Thung, Mindy Yang. Classification of Trash for Recyclability Status.
[2]. Wei Liu1, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy,Scott Reed, Cheng-Yang Fu, and Alexander C. Berg. SSD: Single Shot MultiBox Detector
[3]. Andrew G. Howard Menglong Zhu Bo Chen Dmitry Kalenichenko Weijun Wang Tobias Weyand Marco Andreetto Hartwig Adam.MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications.arXiv:1704.04861v1 [cs.CV] 17 Apr 2017
如果想与更多深度学习同学交流,欢迎加入飞桨官方QQ群:703252161
如果在端侧部署中遇到问题,欢迎加入Paddle Lite官方QQ群与开发人员进行技术交流及问题反馈:696965088
END
